php网站开发报告如何在网站做宣传
本文介绍hadoop中的MapReduce技术的应用,使用java API。操作系统:Ubuntu24.04。
MapReduce概述
MapReduce概念
MapReduce是一个分布式运算程序的编程框架,核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个Hadoop集群上。
MapReduce核心思想
分布式的运算程序往往需要分成至少2个阶段。
第一个阶段的MapTask并发实例,完全并行运行,互不相干。
第二个阶段的ReduceTask并发实例互不相干,但是他们的数据依赖于上一个阶段的所有MapTask并发实例的输出。
MapReduce编程模型只能包含一个Map阶段和一个Reduce阶段,如果用户的业务逻辑非常复杂,那就只能多个MapReduce程序,串行运行。
MapReduce 进程
MrAppMaster:负责整个程序的过程调度及状态调度
MapTask:负责 Map 阶段的整个数据处理流程
ReduceTask:负责 Reduce 阶段的整个数据处理流程
创建软件包
新建一个MapReduce软件包
编写Mapper类
Mapper类将单词文本进行切割,切割成一个个的单词,写入到上下文中
(1)按行读取,通过split函数进行切割,将切割出来的一个个单词放到数组words中
(2)遍历数组words,将存在的单词数据存储到word中,然后将word写入到context上下文(使Redcue程序能访问到数据)
核心代码:
package MapReduce;import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {// 输出Text k = new Text();IntWritable v = new IntWritable(1);@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {// 1 获取一行String line = value.toString();// 2 切割String[] words = line.split(" ");// 3 输出for (String word : words) {k.set(word);context.write(k, v);}}
}
编写Reducer类
Reducer类
(1)将每个单词统计次数结果进行求和合并
(2)把统计结果依次写入到context上下文中
核心代码:
package MapReduce;import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;public class WordCountReducer extends Reducer<Text, IntWritable, Text, LongWritable> {@Overrideprotected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {// 声明变量 用于存储聚合完的结果long count = 0;// 遍历相同的 key 获取对应的所有 valuefor (IntWritable value : values) {count += value.get();}// 将聚合完的结果写到 MapReduce 框架context.write(key, new LongWritable(count));}
}
编写Driver类
Driver类中,需要进行以下操作:
获取job 设置jar包路径
关联Mapper、Reducer
设置map输出的k,v类型
最终输出的k,v类型
设置输入路径和输出路径
提交job
核心代码:
package MapReduce;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;public class WordCountDriver {public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {// 0. 自定义配置对象Configuration conf = new Configuration();// 1. 创建 Job 对象,参数可取消Job job = Job.getInstance(conf);// 2. 给 Job 对象添加 Mapper 类的 Classjob.setMapperClass(WordCountMapper.class);// 3. 给 Job 对象添加 Reduce 类的 Classjob.setReducerClass(WordCountReducer.class);// 4. 给 Job 对象添加 Driver 类的 Classjob.setJarByClass(WordCountDriver.class);// 5. 设置 Mapper 输出的数据的 key 类型job.setMapOutputKeyClass(Text.class);// 6. 设置 Mapper 输出的数据的 value 类型job.setMapOutputValueClass(IntWritable.class);// 7. 设置 Reduce 输出的数据的 key 类型job.setOutputKeyClass(Text.class);// 8. 设置 Reduce 输出的数据的 value 类型job.setOutputValueClass(LongWritable.class);// 定义uri字符串// String uri = "hdfs://master:9000";// 9. 设置 MapReduce 任务的输入路径FileInputFormat.setInputPaths(job, new Path(args[0]));// 10.设置 MapReduce 任务的输出路径FileOutputFormat.setOutputPath(job, new Path(args[1]));// 11.提交任务boolean result = job.waitForCompletion(true);// 12.退出返回System.exit(result ? 0 : 1);}
}
打包
在IDEA中,选择最右边的“Maven”选项卡,展开旁边的” Lifecycle → package”,双击,在最左边的Project面板中,找到” src → target”,就能发现生成了一个jar文件,我这里是“Spark-1.0-SNAPSHOT.jar”。
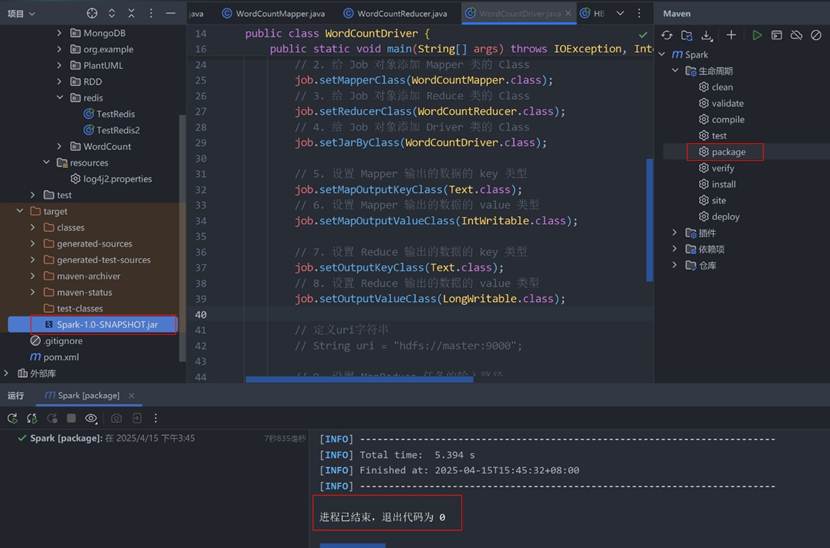
找到这个文件,在文件资源管理器打开,上传这个文件。可以修改成一个简单的名字,如“mr.jar”,然后放到一个你容易找到的地方,例如桌面上。利用XShell把这个文件上传到hadoop集群中
在hadoop集群中执行MapReduce程序
先准备好需要统计词频的文件,用浏览器打开hadoop的Web UI,输入地址:
http://hadoop101:9870/
然后选择“Utilities”菜单下的“Browser the file system”,我创建了一个文件夹“wordcount”
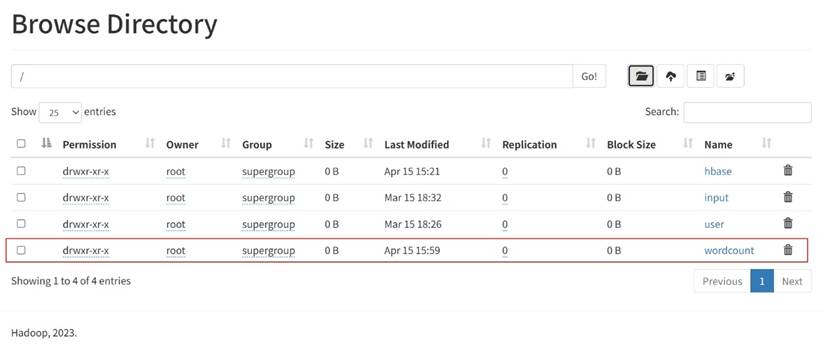
进入“wordcount”文件夹,我继续创建了一个文件夹“input”。继续进入“input”文件夹,我上传了两个文件“”file01.txt 和“file02.txt”,内容分别为:
Hello MapReduce Bye MapReduceHello Hadoop Goodbye Hadoop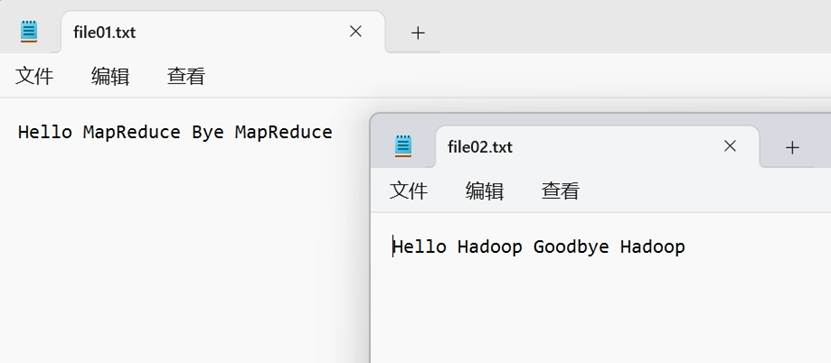
进入主机master,打开命令行窗口,输入下列命令来执行上传的MapReduce程序:
cd /home/youka
hadoop jar mr.jar mr.WordCountDriver /wordcount/input /wordcount/output
系统执行后,报错了
Could not find or load main class org.apache.hadoop.mapreduce.v2.app.MRAppMaster:

这里给出的报错信息非常明确,就是mapreduce配置文件没有配好,先打开hadoop中mapreduce配置文件:
vim /usr/local/hadoop/etc/hadoop/mapred-site.xml
在configuration中增加一下配置:
<property><name>yarn.app.mapreduce.am.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property><name>mapreduce.map.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property><name>mapreduce.reduce.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>

重新执行,成功
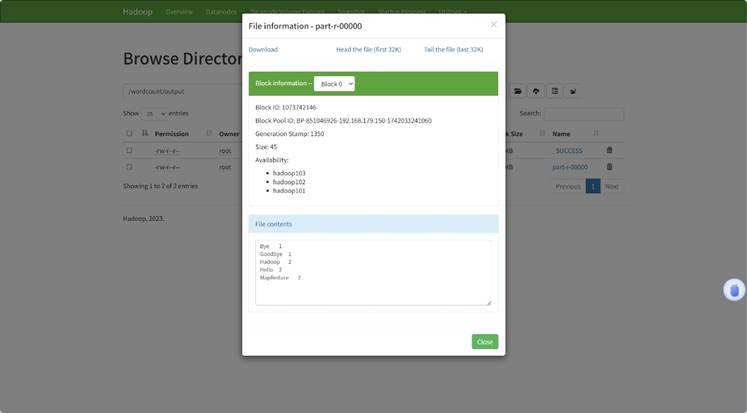
在“wordcount”中增加了一个”output”文件夹
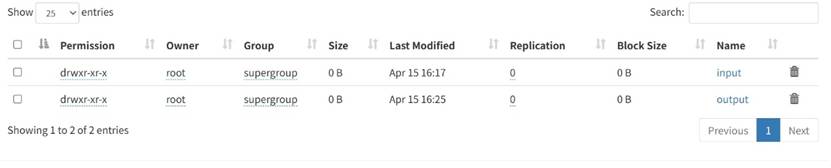
打开后多了两个文件

“part-r-00000”文件显示了统计结果