官方购物网站正品国家建筑工程信息平台
目录
KV Cache 在自回归生成中的作用及显存优化
1. 什么是 KV Cache?
2. KV Cache 在自回归生成中的作用
(1) 提高生成效率
(2) 减少计算冗余
(3) 降低显存占用
3. KV Cache 的显存占用分析
(1) 显存占用的计算
4. KV Cache 示例代码
(1) 在 Hugging Face Transformers 中使用 KV Cache
(2) KV Cache 显存优化技巧
✅ 1. 使用 FP16 或 INT8 量化减少显存占用
✅ 2. 控制 max_length 以避免上下文溢出
✅ 3. 使用 Flash Attention 进一步优化计算
5. 总结
KV Cache 在自回归生成中的作用及显存优化
1. 什么是 KV Cache?
在大语言模型(LLM)进行自回归(autoregressive)文本生成时,每次生成新 token,都需要基于过去的上下文重新计算 self-attention 机制中的Key(K)和值(V)。
KV Cache(键值缓存)是一种优化策略,它缓存先前计算的 K/V 张量,避免重复计算,从而提高生成速度并降低计算成本。
2. KV Cache 在自回归生成中的作用
(1) 提高生成效率
- 在 Transformer 结构中,每个 token 都需要计算与前面所有 token 的注意力。
- 如果不使用 KV Cache,每次生成新 token 都要重复计算之前所有 token 的 K/V。
- 使用 KV Cache 后,只需计算新 token 的 K/V,并与缓存的值进行注意力计算。
(2) 减少计算冗余
- 无 KV Cache:生成 N 个 token 需要 O(N²) 计算。
- 有 KV Cache:只需计算新 token,与已有缓存 O(N) 计算,复杂度降低。
(3) 降低显存占用
- 不缓存:每次都需要存储所有 past K/V 张量,显存需求大。
- 使用 KV Cache:仅存储必要的 past K/V,减少显存占用。
3. KV Cache 的显存占用分析
(1) 显存占用的计算
KV Cache 主要存储 K/V 矩阵,其大小计算如下:
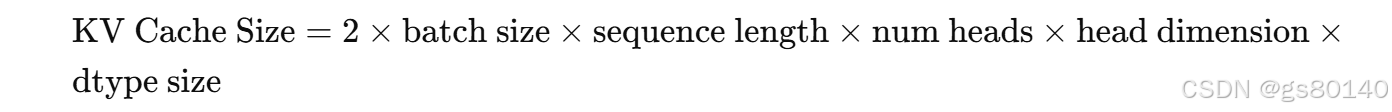
- batch size:每次生成的样本数。
- sequence length:当前输入的 token 长度。
- num heads:多头注意力的头数。
- head dimension:每个头的维度(如 64)。
- dtype size:如
float16为 2 字节,float32为 4 字节。
例如,一个 batch_size=1,sequence_length=2048,num_heads=32,head_dim=64 的 Transformer,如果使用 float16,KV Cache 占用:
2×1×2048×32×64×2≈16MB
这意味着,较长的上下文会显著增加显存需求。
4. KV Cache 示例代码
(1) 在 Hugging Face Transformers 中使用 KV Cache
Hugging Face 的 transformers 库已经支持 KV Cache 机制。
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch# 加载模型和 tokenizer
model_name = "gpt2"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name).half().cuda()# 输入文本
input_text = "人工智能正在"
input_ids = tokenizer(input_text, return_tensors="pt").input_ids.cuda()# 初始化 KV Cache
past_key_values = None# 逐步生成文本
max_new_tokens = 20
for _ in range(max_new_tokens):with torch.no_grad():outputs = model(input_ids, past_key_values=past_key_values, use_cache=True)# 获取新生成的 tokennext_token = outputs.logits[:, -1, :].argmax(dim=-1, keepdim=True)input_ids = torch.cat([input_ids, next_token], dim=-1)past_key_values = outputs.past_key_values # 更新 KV Cache# 解码最终输出
generated_text = tokenizer.decode(input_ids[0], skip_special_tokens=True)
print("生成文本:", generated_text)
(2) KV Cache 显存优化技巧
✅ 1. 使用 FP16 或 INT8 量化减少显存占用
model = model.half() # FP16
✅ 2. 控制 max_length 以避免上下文溢出
input_ids = input_ids[:, -1024:] # 仅保留最近 1024 个 token
✅ 3. 使用 Flash Attention 进一步优化计算
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.float16, use_flash_attention_2=True).cuda()
5. 总结
- KV Cache 通过缓存历史 K/V 值,提高了自回归生成的效率,降低计算复杂度。
- 使用 KV Cache 可减少计算冗余,但会增加显存占用,尤其在长序列生成时需要优化。
- 通过 FP16 量化、截断输入、Flash Attention 可以优化显存利用。
希望本文的 KV Cache 介绍和代码示例能帮助你更高效地使用大语言模型!