网站做可信认证多少钱百度信息流怎么投放
一、动机
不完美的检索器,检索的结果会影响LLM的生成结果
RAG的基本架构:
![]()
可以看出来,生成器和检索器式紧密耦合的,这样系统的容错能力很弱。这个就是本文的核心关注问题。
二、解决方法
针对检索器返回不准确结果的情景,提出了纠错检索增强生成,用于纠正检索器的结果。
设计一个轻量级的检索评估器,用来评估针对查询所检索文档的整体质量,评估器会输出一个置信度评分,基于这个评分,系统可以触发三种不同的知识检索操作:正确、错误、模糊。
对于错误:通过网页的搜索来拓展检索信息的广度
为了去除检索文档中那些冗余而无助于生成的上下文信息,设计了一个先分解在重组的算法,就是为了对检索信息进行优化提炼,强化关键要点的提取,最小化无关内容的干扰,以达到提升检索数据的有效利用。
三、模型推理概述
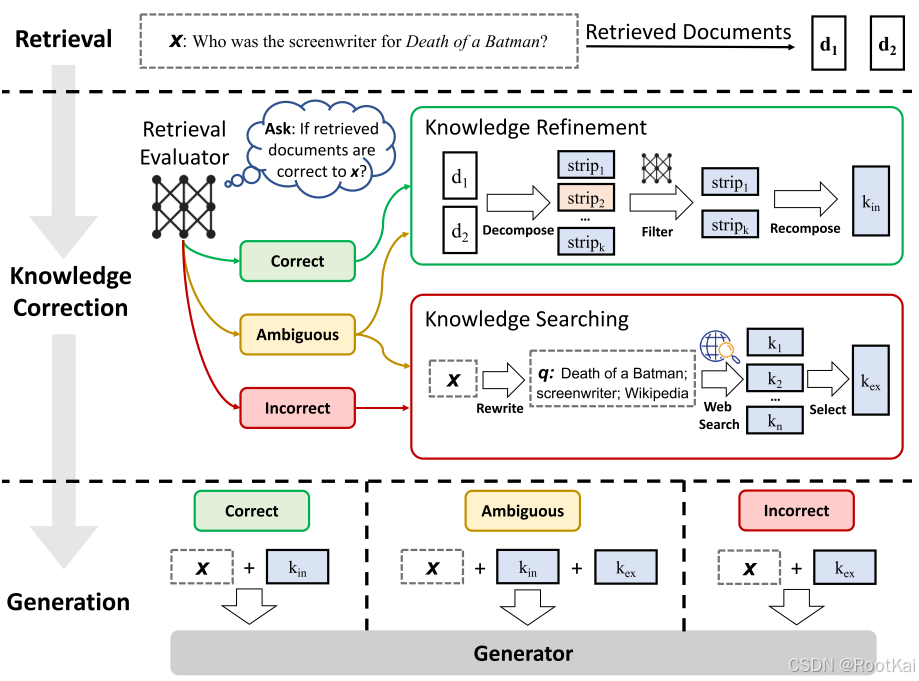
首先:给定的查询和来自任意检索器的检索文档
然后:构建一个检索评估器,用于评估检索文档与输入查询的相关性评分,相关性评分分为三个置信度等级,正确、错误、模糊
正确:检索到的文档将被精炼为更精确的知识条带。这一精炼操作包括知识分解、过滤和重组
错误:检索到的文档将被丢弃。相应地,系统会转向网页搜索,并将其视为补充的知识来源,用于纠正错误
模糊:结合前两者的优点
1.检索评估器
T5-lage模型架构:
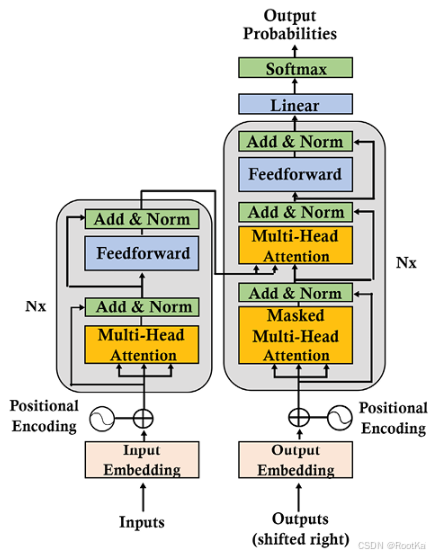
T5模型对Transformer进行了输入的改变,使其能够统一文本到文本的输入格式,通过加前缀的方式,之后就是针对不同的任务进行微调。
对T5-large进行微调,微调的数据集使用的数据集来自Self-RAG检索后的数据集(Contriever检检索器获得的):PopQA。
在PopQA中一共包含14000个样本,其中1399个用于测试,剩余的用于微调。这个微调的目的就是让T5-large能够更好的判断检索文档与输入问题的相关性。
微调的过程中:样本分为正样本和负样本,正样本标签为1,负样本标签为-1,推理的时候,评估器为每个文档计算一个相关性得分,范围为-1,1,然后通过实验这顶置信度值,不同数据集不同。
正负样本的构成:正样本:通常是维基百科上与该问题相关的条目标题。这些条目可以看作是正样本的一个来源。
使用PopQA训练好的模型还迁移到了Bio、Pub、ARC数据集上。负样本的获取:这些负样本通过随机从检索结果中采样来获得。换句话说,检索系统可能返回了一些看起来很接近查询的问题或内容,但其实它们与输入的查询并无实质性联系。
对于每个问题,通常会检索到 10 篇文档。问题会与每个文档单独拼接作为输入,评估器会为每个问题-文档对单独预测相关性评分。
2.执行动作
1.正确
当至少一个检索文档的自信度得分高于上阈值时,检索的结果就被认为是正确的,这就意味着从检索的结果中获取知识应该更加可靠和准确,虽然找到了相关的文档,但是这些相关的文档里面包含着噪声片段,进行进一步知识精炼
2.错误
检索的文档的置信度得分都低于阈值的时候,就认为检索的文档是不相关的,这个时候就在网络上搜索一信息,进行补充。
3.模糊
当得分是一个中间值得时候,说明评估器没有信心判断是不是好的,这个时候就把正确和不正确的结合在一起。
模糊的设置可以减轻对检索评估器准确性的依赖
精炼:
方法就是分解-组合,进一步提取其中最关键的知识片段。先将检索的结果拆分较小的单元,这些小单元通常就包含一两句话,每个单元假设包含独立的新兴信息 ,在对这些单元进行检索评估,删掉不相关的单元,将相关的片段按顺序从新组合。
四、实验
我们的实验展示了CRAG对基于RAG方法的适应性,以及在短文本和长文本生成任务中的泛化能力。
1.任务
数据集:PopAQ(短文本生成)、Biography(长文本生成)、PubHealth(真假问题)、Arc-Challenge(多项选择题)
评估指标:PopQA、PubHealth、Arc-Challenge采用准确率
Biography采用FactScore
准确率:
Factscore:


2.基线
CRAG对比的方法:带检索的、不带检索的(标准RAG、高级RAG)
无检索的基准:评估了开源的LLaMA2-7B、13B、指令微调模型Alpaca-7B、CoVE65B、一些闭源的:LLaMA2-chat13B、chatgpt
标准 RAG:使用与我们实验相同的检索器检索的段落,进行生成输出,并采用了几种公共指令微调的 LLM,包括 LLaMA2-7B、13B、Alpaca-7B、13B,以及在 Self-RAG中指令微调的 LLaMA2-7B
高级RAG:
SAIL:该方法在 Alpaca 指令微调数据上对语言模型进行了指令微调,并在指令前插入了检索到的文档
Self-RAG:该方法对 LLaMA2 进行了指令微调,使用了包含多个反射标记集的数据,这些标记由 GPT-4(OpenAI,2023)标注
实验结果:
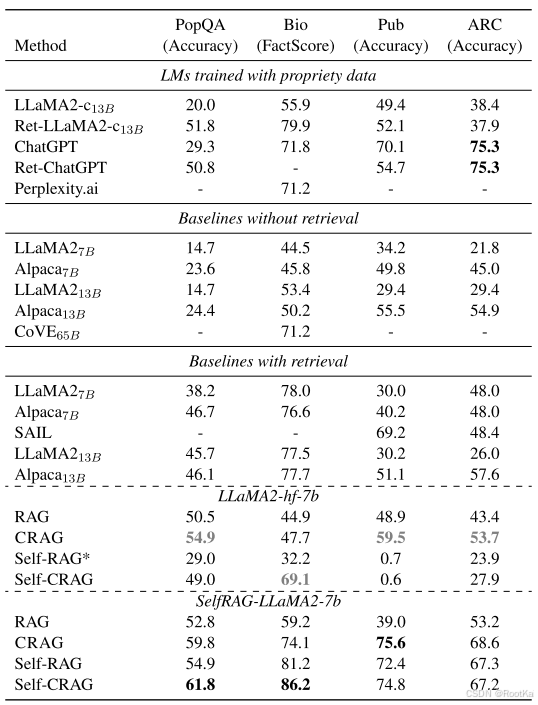
结果分析:
将C与标准的RAG结合,以及和self-RAG结合。显著提升了RAG和Self-RAG的性能,
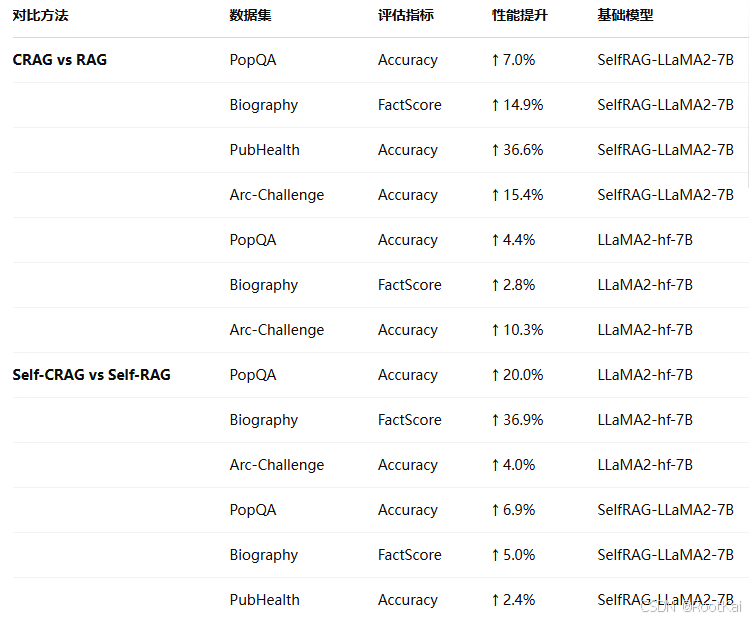
说明了CRAG的适应性强
CRAG 就像一个不挑车的发动机,放在哪辆车上都能跑得不错。而 Self-RAG 是个定制发动机,必须装在专门设计的车上才能发挥最大效力。
消融实验:
在PopQA上的消融实验:分别移除每个单一动作后的准确率对比分析。
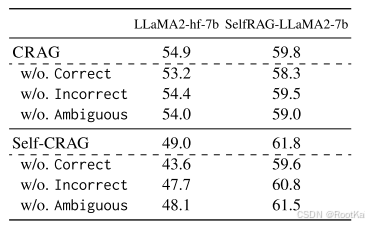
在 PopQA 数据集上进行消融实验,分别移除每个知识利用操作后的准确率对比分析。
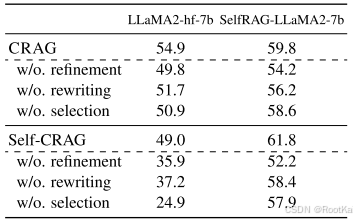
这些消融实验,验证了触发动作在检索评估器中的有效性和对性能的贡献。
检索评估器的实验结果:

为了进一步验证所提方法对检索性能的鲁棒性,我们研究了在不同检索性能下生成性能的变化。为了模拟低质量的检索器,我们故意随机移除了部分准确的检索结果,并评估性能变化。
下图展示了在 PopQA 数据集上 Self-RAG 和 Self-CRAG 的性能变化。可以看到,随着检索性能的下降,Self-RAG 和 Self-CRAG 的生成性能也有所下降,这表明生成器在很大程度上依赖于检索器的质量。此外,随着检索性能的下降,Self-CRAG 的生成性能下降的幅度比 Self-RAG 略小。这些结果表明,Self-CRAG 在增强对检索性能鲁棒性方面优于 Self-RAG。
