网站重要组成部分seo在线优化工具
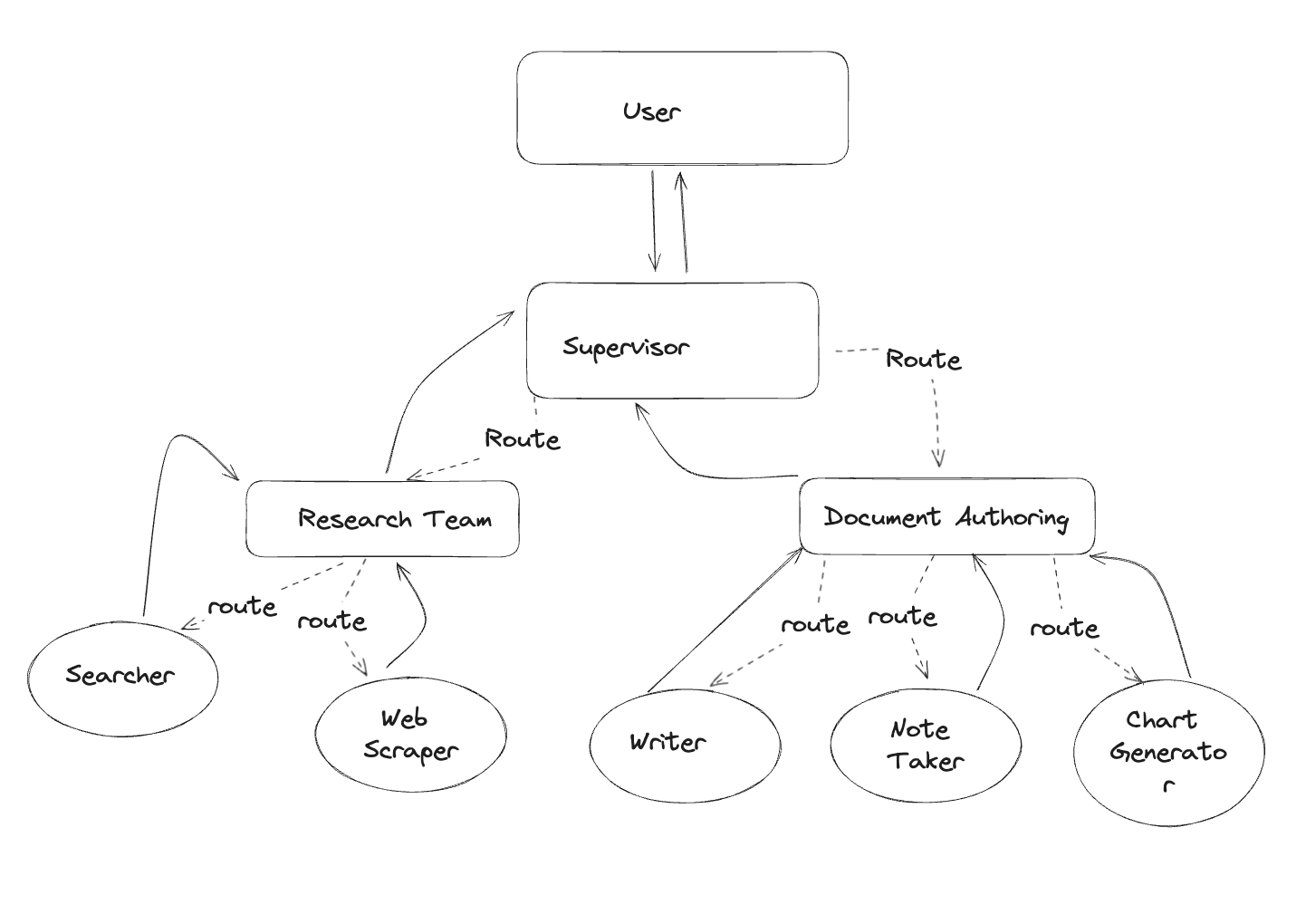
代理监督者中单个监督节点用于在不同工作节点之间路由任务。但如果单个工作节点的任务变得过于复杂、工作节点的数量变得过多,对于某些应用场景,若以分层方式分配任务,系统可能会更高效。可以通过组合不同的子图,并创建一个顶级监督者和多个中级监督者来实现这一点。
1. 设置
pip install -U langgraph langchain_community langchain_anthropic langchain_experimental
import getpass
import osdef _set_if_undefined(var: str):if not os.environ.get(var):os.environ[var] = getpass.getpass(f"Please provide your {var}")_set_if_undefined("OPENAI_API_KEY")
_set_if_undefined("TAVILY_API_KEY")2. 创建工具
每个团队将由一个或多个Agent组成,每个Agent都有一个或多个工具。下面,定义不同团队使用的所有工具。
from typing import Annotated, Listfrom langchain_community.document_loaders import WebBaseLoader
from langchain_community.tools.tavily_search import TavilySearchResults
from langchain_core.tools import tool
'''
创建一个 Tavily 搜索工具实例
max_results=5表示每次搜索最多返回 5 个结果
'''
tavily_tool = TavilySearchResults(max_results=5)'''
函数功能:从给定的 URL 列表中抓取网页内容
参数:urls - 要抓取的网页 URL 列表
返回值:格式化后的网页内容字符串
'''
@tool
def scrape_webpages(urls: List[str]) -> str:"""Use requests and bs4 to scrape the provided web pages for detailed information."""loader = WebBaseLoader(urls)docs = loader.load()return "\n\n".join([f'<Document name="{doc.metadata.get("title", "")}">\n{doc.page_content}\n</Document>'for doc in docs])tool装饰器:用于将函数转换为 LangChain 可用的工具
3. 文档访问团队工具
from pathlib import Path
from tempfile import TemporaryDirectory
from typing import Dict, Optionalfrom langchain_experimental.utilities import PythonREPL
from typing_extensions import TypedDict
#创建临时工作目录,所有文件操作都在此目录中进行。程序退出时,临时目录会自动删除,确保安全性。
_TEMP_DIRECTORY = TemporaryDirectory()
WORKING_DIRECTORY = Path(_TEMP_DIRECTORY.name)'''
创建带编号的大纲并保存为文件。
'''
@tool
def create_outline(points: Annotated[List[str], "List of main points or sections."],file_name: Annotated[str, "File path to save the outline."],
) -> Annotated[str, "Path of the saved outline file."]:"""Create and save an outline."""with (WORKING_DIRECTORY / file_name).open("w") as file:for i, point in enumerate(points):file.write(f"{i + 1}. {point}\n")return f"Outline saved to {file_name}"'''
读取文件内容,支持指定起始行和结束行(默认为全文)。
'''
@tool
def read_document(file_name: Annotated[str, "File path to read the document from."],start: Annotated[Optional[int], "The start line. Default is 0"] = None,end: Annotated[Optional[int], "The end line. Default is None"] = None,
) -> str:"""Read the specified document."""with (WORKING_DIRECTORY / file_name).open("r") as file:lines = file.readlines()if start is None:start = 0return "\n".join(lines[start:end])'''
将文本内容写入文件。
'''
@tool
def write_document(content: Annotated[str, "Text content to be written into the document."],file_name: Annotated[str, "File path to save the document."],
) -> Annotated[str, "Path of the saved document file."]:"""Create and save a text document."""with (WORKING_DIRECTORY / file_name).open("w") as file:file.write(content)return f"Document saved to {file_name}"'''
在指定行插入文本(行号为 1-indexed)。
'''
@tool
def edit_document(file_name: Annotated[str, "Path of the document to be edited."],inserts: Annotated[Dict[int, str],"Dictionary where key is the line number (1-indexed) and value is the text to be inserted at that line.",],
) -> Annotated[str, "Path of the edited document file."]:"""Edit a document by inserting text at specific line numbers."""with (WORKING_DIRECTORY / file_name).open("r") as file:lines = file.readlines()sorted_inserts = sorted(inserts.items())for line_number, text in sorted_inserts:if 1 <= line_number <= len(lines) + 1:lines.insert(line_number - 1, text + "\n")else:return f"Error: Line number {line_number} is out of range."with (WORKING_DIRECTORY / file_name).open("w") as file:file.writelines(lines)return f"Document edited and saved to {file_name}"#执行 Python 代码并返回结果
#直接执行用户提供的代码存在风险,需确保代码安全。
# Warning: This executes code locally, which can be unsafe when not sandboxedrepl = PythonREPL()@tool
def python_repl_tool(code: Annotated[str, "The python code to execute to generate your chart."],
):"""Use this to execute python code. If you want to see the output of a value,you should print it out with `print(...)`. This is visible to the user."""try:result = repl.run(code)except BaseException as e:return f"Failed to execute. Error: {repr(e)}"return f"Successfully executed:\n\`\`\`python\n{code}\n\`\`\`\nStdout: {result}"这些工具可作为工作节点,由监督节点协调调用:
- 顶级监督者:规划任务流程(如先创建大纲,再生成内容)。
- 中级监督者:处理子任务(如根据大纲生成章节内容)。
- 工作节点:执行具体工具(文件操作、代码执行)。
4. 助手工具
实现监督者节点
from typing import List, Optional, Literal
from langchain_core.language_models.chat_models import BaseChatModelfrom langgraph.graph import StateGraph, MessagesState, START, END
from langgraph.types import Command
from langchain_core.messages import HumanMessage, trim_messages'''
继承自MessagesState,包含对话历史。
next字段记录下一个要跳转的节点。
'''
class State(MessagesState):next: str'''
监督者节点生成函数
参数:
llm:基础聊天模型(如 GPT-4)。
members:可用工作节点列表(如["scrape_webpages", "create_outline"])。
系统提示词:告知 LLM 其角色是监督者,需根据用户请求选择下一个工作节点,或结束任务(FINISH)。
'''
def make_supervisor_node(llm: BaseChatModel, members: list[str]) -> str:options = ["FINISH"] + memberssystem_prompt = ("You are a supervisor tasked with managing a conversation between the"f" following workers: {members}. Given the following user request,"" respond with the worker to act next. Each worker will perform a"" task and respond with their results and status. When finished,"" respond with FINISH.")'''路由逻辑Router 类型:强制 LLM 输出固定选项(工作节点名称或FINISH)。'''class Router(TypedDict):"""Worker to route to next. If no workers needed, route to FINISH."""next: Literal[*options]'''将系统提示词和历史对话messages输入 LLM。使用with_structured_output约束 LLM 输出格式。根据 LLM 的输出决定跳转节点:若为FINISH,则跳转到END状态。否则跳转到指定工作节点。'''def supervisor_node(state: State) -> Command[Literal[*members, "__end__"]]:"""An LLM-based router."""messages = [{"role": "system", "content": system_prompt},] + state["messages"]response = llm.with_structured_output(Router).invoke(messages)goto = response["next"]if goto == "FINISH":goto = ENDreturn Command(goto=goto, update={"next": goto})return supervisor_node5. 定义Agent团队
基于之前的监督者节点框架,实现了一个具体的研究助手系统,包含搜索、网页抓取和监督者三个核心组件。
搜索
from langchain_core.messages import HumanMessage
from langchain_openai import ChatOpenAI
from langgraph.prebuilt import create_react_agentllm = ChatOpenAI(model="gpt-4o")
#search_agent:使用 Tavily 搜索引擎进行信息检索。
search_agent = create_react_agent(llm, tools=[tavily_tool])def search_node(state: State) -> Command[Literal["supervisor"]]:result = search_agent.invoke(state)return Command(update={"messages": [HumanMessage(content=result["messages"][-1].content, name="search")]},# We want our workers to ALWAYS "report back" to the supervisor when donegoto="supervisor",)#web_scraper_agent:调用网页抓取工具获取详细内容。
web_scraper_agent = create_react_agent(llm, tools=[scrape_webpages])'''
搜索节点实现
执行搜索任务并将结果添加到对话历史。
调用search_agent执行搜索。
将搜索结果(作为HumanMessage)添加到状态中。
返回控制给监督者节点(goto="supervisor")。
'''
def web_scraper_node(state: State) -> Command[Literal["supervisor"]]:result = web_scraper_agent.invoke(state)return Command(update={"messages": [HumanMessage(content=result["messages"][-1].content, name="web_scraper")]},# We want our workers to ALWAYS "report back" to the supervisor when donegoto="supervisor",)'''
监督者节点
协调搜索和网页抓取两个工作节点。
根据用户请求决定调用search或web_scraper。
接收工作节点的结果后,决定继续下一步或结束任务。
'''
research_supervisor_node = make_supervisor_node(llm, ["search", "web_scraper"])- 顶级监督者:
research_supervisor_node,负责全局任务分配。 - 工作节点:
search_node和web_scraper_node,执行具体任务。 - 闭环控制:所有工作节点完成后返回结果给监督者,形成闭环。
基于前面定义的节点,构建并编译了一个完整的状态图(StateGraph),用于实现研究助手的自动化工作流程
StateGraph为一种有向图模型,用于定义多智能体系统中节点(状态)之间的跳转逻辑。
每个节点包含一个处理函数,决定状态转移和数据更新。
节点(Node):执行具体逻辑的函数(如监督者、搜索、网页抓取)。
边(Edge):定义状态跳转的路径(如从START到supervisor)。
状态(State):存储对话历史、中间结果等数据。
'''
初始化状态图
创建状态图构建器,指定状态类型为之前定义的State类(包含messages和next字段)。
'''
research_builder = StateGraph(State)
'''
添加三个节点:
supervisor:监督者节点,负责任务分配。
search:搜索节点,调用 Tavily 获取信息。
web_scraper:网页抓取节点,获取详细内容。
'''
research_builder.add_node("supervisor", research_supervisor_node)
research_builder.add_node("search", search_node)
research_builder.add_node("web_scraper", web_scraper_node)'''
定义边
设置从特殊节点START到supervisor的初始跳转。
意味着系统启动时首先进入监督者节点进行任务决策。
'''
research_builder.add_edge(START, "supervisor")
'''
编译状态图
将构建器中的定义转换为可执行的状态图对象research_graph。
编译后,图结构被固化,可用于执行具体任务。
'''
research_graph = research_builder.compile()通过 Mermaid 图表可视化构建的研究助手状态图(StateGraph)
from IPython.display import Image, display
#将状态图转换为 Mermaid 语法并生成 PNG 图像。
display(Image(research_graph.get_graph().draw_mermaid_png()))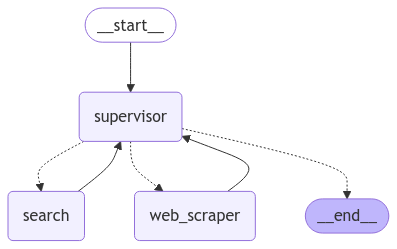
执行状态图
'''
按状态图定义的流程逐步执行,每次迭代处理一个状态节点。
返回一个生成器,每次生成当前状态的详细信息。
messages:初始对话历史,包含用户提问。
recursion_limit:最大迭代次数,防止无限循环。
'''
for s in research_graph.stream({"messages": [("user", "when is Taylor Swift's next tour?")]},{"recursion_limit": 100},
):print(s)print("---"){'supervisor': {'next': 'search'}}
---
{'search': {'messages': [HumanMessage(content="Taylor Swift's next tour is The Eras Tour, which includes both U.S. and international dates. She announced additional U.S. dates for 2024. You can find more details about the tour and ticket information on platforms like Ticketmaster and official announcements.", additional_kwargs={}, response_metadata={}, name='search', id='4df8687b-50a8-4342-aad5-680732c4a10f')]}}
---
{'supervisor': {'next': 'web_scraper'}}
---
{'web_scraper': {'messages': [HumanMessage(content='Taylor Swift\'s next tour is "The Eras Tour." Here are some of the upcoming international dates for 2024 that were listed on Ticketmaster:\n\n1. **Toronto, ON, Canada** at Rogers Centre\n - November 21, 2024\n - November 22, 2024\n - November 23, 2024\n\n2. **Vancouver, BC, Canada** at BC Place\n - December 6, 2024\n - December 7, 2024\n - December 8, 2024\n\nFor the most current information and additional dates, you can check platforms like Ticketmaster or Taylor Swift\'s [official website](https://www.taylorswift.com/events).', additional_kwargs={}, response_metadata={}, name='web_scraper', id='27524ebc-d179-4733-831d-ee10a58a2528')]}}
---
{'supervisor': {'next': '__end__'}}
---
文档编写
在研究助手的基础上,进一步扩展了文档处理功能,新增了文档写作、笔记记录和图表生成三个核心模块,并通过监督者节点协调它们的工作。
llm = ChatOpenAI(model="gpt-4o")
'''
文档写作代理
功能:基于大纲生成、编辑文档内容。
工具集:
write_document:创建新文档。
edit_document:按行插入内容。
read_document:读取已有文档。
提示词:限定代理仅根据大纲工作,不追问用户
'''
doc_writer_agent = create_react_agent(llm,tools=[write_document, edit_document, read_document],prompt=("You can read, write and edit documents based on note-taker's outlines. ""Don't ask follow-up questions."),
)'''
文档写作节点
调用文档写作代理处理内容,将结果添加到对话历史后返回监督者。
'''
def doc_writing_node(state: State) -> Command[Literal["supervisor"]]:result = doc_writer_agent.invoke(state)return Command(update={"messages": [HumanMessage(content=result["messages"][-1].content, name="doc_writer")]},# We want our workers to ALWAYS "report back" to the supervisor when donegoto="supervisor",)'''
笔记记录代理(note_taking_agent)
功能:分析文档内容并生成结构化大纲。
工具集:
create_outline:生成带编号的大纲。
read_document:读取文档内容。
提示词:明确其为文档写作提供大纲支持。
'''
note_taking_agent = create_react_agent(llm,tools=[create_outline, read_document],prompt=("You can read documents and create outlines for the document writer. ""Don't ask follow-up questions."),
)'''
笔记记录节点
生成大纲后将结果反馈给监督者。
'''
def note_taking_node(state: State) -> Command[Literal["supervisor"]]:result = note_taking_agent.invoke(state)return Command(update={"messages": [HumanMessage(content=result["messages"][-1].content, name="note_taker")]},# We want our workers to ALWAYS "report back" to the supervisor when donegoto="supervisor",)'''
图表生成代理
功能:基于文档数据生成可视化图表。
工具集:
read_document:获取数据内容。
python_repl_tool:执行 Python 绘图代码。
'''
chart_generating_agent = create_react_agent(llm, tools=[read_document, python_repl_tool]
)'''
图表生成节点
执行绘图代码后将结果(如图表路径或描述)返回监督者。
'''
def chart_generating_node(state: State) -> Command[Literal["supervisor"]]:result = chart_generating_agent.invoke(state)return Command(update={"messages": [HumanMessage(content=result["messages"][-1].content, name="chart_generator")]},# We want our workers to ALWAYS "report back" to the supervisor when donegoto="supervisor",)'''
文档写作监督者节点
协调三大模块的工作流程。
根据任务需求选择note_taker生成大纲。
调用doc_writer基于大纲写作。
如需可视化,指派chart_generator生成图表。
'''
doc_writing_supervisor_node = make_supervisor_node(llm, ["doc_writer", "note_taker", "chart_generator"]
)构建并编译状态图
# Create the graph here
'''创建基于State类的状态图构建器,State包含对话历史(messages)和下一个节点标识(next),用于存储和传递流程中的关键信息。'''
paper_writing_builder = StateGraph(State)
# 监督者节点:负责任务分配与流程控制
paper_writing_builder.add_node("supervisor", doc_writing_supervisor_node)
# 文档写作节点:执行文档撰写、编辑等操作
paper_writing_builder.add_node("doc_writer", doc_writing_node)
# 笔记记录节点:生成文档大纲
paper_writing_builder.add_node("note_taker", note_taking_node)
# 图表生成节点:生成数据可视化图表
paper_writing_builder.add_node("chart_generator", chart_generating_node)'''设定状态图的起始逻辑:从START节点直接跳转至supervisor节点,意味着流程启动后首先由监督者节点接收任务并规划下一步操作。'''
paper_writing_builder.add_edge(START, "supervisor")
#将构建器中定义的节点、边等逻辑转换为可执行的状态图对象。
paper_writing_graph = paper_writing_builder.compile()将前面构建的论文写作状态图(paper_writing_graph)以可视化的方式展示出来
#导入IPython的图像显示工具
from IPython.display import Image, display
# 生成并显示状态图的可视化图像
display(Image(paper_writing_graph.get_graph().draw_mermaid_png()))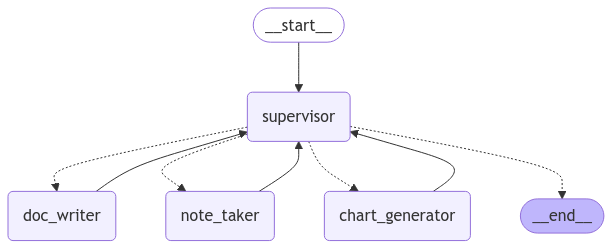
执行论文写作状态图
for s in paper_writing_graph.stream({"messages": [("user","Write an outline for poem about cats and then write the poem to disk.",)]},{"recursion_limit": 100},
):print(s)print("---"){'supervisor': {'next': 'note_taker'}}
---
{'note_taker': {'messages': [HumanMessage(content='The outline for the poem about cats has been created and saved as "cats_poem_outline.txt".', additional_kwargs={}, response_metadata={}, name='note_taker', id='14a5d8ca-9092-416f-96ee-ba16686e8658')]}}
---
{'supervisor': {'next': 'doc_writer'}}
---
{'doc_writer': {'messages': [HumanMessage(content='The poem about cats has been written and saved as "cats_poem.txt".', additional_kwargs={}, response_metadata={}, name='doc_writer', id='c4e31a94-63ae-4632-9e80-1166f3f138b2')]}}
---
{'supervisor': {'next': '__end__'}}
---6. 添加层
创建一个新的团队协作监督者节点(teams_supervisor_node),用于协调两个子团队:research_team(研究团队)和writing_team(写作团队)。
from langchain_core.messages import BaseMessagellm = ChatOpenAI(model="gpt-4o")
#members:可调度的团队列表(["research_team", "writing_team"])。
teams_supervisor_node = make_supervisor_node(llm, ["research_team", "writing_team"])通过定义call_research_team和call_paper_writing_team两个节点函数,将之前创建的research_graph(研究助手)和paper_writing_graph(论文写作)作为子图集成到一个更大的系统中。
def call_research_team(state: State) -> Command[Literal["supervisor"]]:response = research_graph.invoke({"messages": state["messages"][-1]})return Command(update={"messages": [HumanMessage(content=response["messages"][-1].content, name="research_team")]},goto="supervisor",)def call_paper_writing_team(state: State) -> Command[Literal["supervisor"]]:response = paper_writing_graph.invoke({"messages": state["messages"][-1]})return Command(update={"messages": [HumanMessage(content=response["messages"][-1].content, name="writing_team")]},goto="supervisor",)# Define the graph.
super_builder = StateGraph(State)
super_builder.add_node("supervisor", teams_supervisor_node)
super_builder.add_node("research_team", call_research_team)
super_builder.add_node("writing_team", call_paper_writing_team)super_builder.add_edge(START, "supervisor")
super_graph = super_builder.compile()通过 Mermaid 图表可视化了之前构建的顶级状态图
from IPython.display import Image, displaydisplay(Image(super_graph.get_graph().draw_mermaid_png()))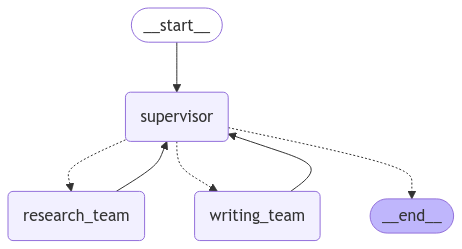
for s in super_graph.stream({"messages": [("user", "Research AI agents and write a brief report about them.")],},{"recursion_limit": 150},
):print(s)print("---"){'supervisor': {'next': 'research_team'}}
---
{'research_team': {'messages': [HumanMessage(content="**AI Agents Overview 2023**\n\nAI agents are sophisticated technologies that automate and enhance various processes across industries, becoming increasingly integral to business operations. In 2023, these agents are notable for their advanced capabilities in communication, data visualization, and language processing.\n\n**Popular AI Agents in 2023:**\n1. **Auto GPT**: This agent is renowned for its seamless integration abilities, significantly impacting industries by improving communication and operational workflows.\n2. **ChartGPT**: Specializing in data visualization, ChartGPT enables users to interact with data innovatively, providing deeper insights and comprehension.\n3. **LLMops**: With advanced language capabilities, LLMops is a versatile tool seeing widespread use across multiple sectors.\n\n**Market Trends:**\nThe AI agents market is experiencing rapid growth, with significant advancements anticipated by 2030. There's a growing demand for AI agents in personalized interactions, particularly within customer service, healthcare, and marketing sectors. This trend is fueled by the need for more efficient and tailored customer experiences.\n\n**Key Players:**\nLeading companies such as Microsoft, IBM, Google, Oracle, and AWS are key players in the AI agents market, highlighting the widespread adoption and investment in these technologies.\n\n**Technological Innovations:**\nAI agents are being developed alongside simulation technologies for robust testing and deployment environments. Innovations in generative AI are accelerating, supported by advancements in large language models and platforms like ChatGPT.\n\n**Applications in Healthcare:**\nIn healthcare, AI agents are automating routine tasks, allowing medical professionals to focus more on patient care. They're poised to significantly enhance healthcare delivery and efficiency.\n\n**Future Prospects:**\nThe future of AI agents is promising, with continued evolution and integration into various platforms and ecosystems, offering more seamless and intelligent interactions. As these technologies advance, they are expected to redefine business operations and customer interactions.", additional_kwargs={}, response_metadata={}, name='research_team', id='5f6606e0-838c-406c-b50d-9f9f6a076322')]}}
---
{'supervisor': {'next': 'writing_team'}}
---
{'writing_team': {'messages': [HumanMessage(content="Here are the contents of the documents:\n\n### AI Agents Overview 2023\n\n**AI Agents Overview 2023**\n\nAI agents are sophisticated technologies that automate and enhance various processes across industries, becoming increasingly integral to business operations. In 2023, these agents are notable for their advanced capabilities in communication, data visualization, and language processing.\n\n**Popular AI Agents in 2023:**\n1. **Auto GPT**: This agent is renowned for its seamless integration abilities, significantly impacting industries by improving communication and operational workflows.\n2. **ChartGPT**: Specializing in data visualization, ChartGPT enables users to interact with data innovatively, providing deeper insights and comprehension.\n3. **LLMops**: With advanced language capabilities, LLMops is a versatile tool seeing widespread use across multiple sectors.\n\n**Market Trends:**\nThe AI agents market is experiencing rapid growth, with significant advancements anticipated by 2030. There's a growing demand for AI agents in personalized interactions, particularly within customer service, healthcare, and marketing sectors. This trend is fueled by the need for more efficient and tailored customer experiences.\n\n**Key Players:**\nLeading companies such as Microsoft, IBM, Google, Oracle, and AWS are key players in the AI agents market, highlighting the widespread adoption and investment in these technologies.\n\n**Technological Innovations:**\nAI agents are being developed alongside simulation technologies for robust testing and deployment environments. Innovations in generative AI are accelerating, supported by advancements in large language models and platforms like ChatGPT.\n\n**Applications in Healthcare:**\nIn healthcare, AI agents are automating routine tasks, allowing medical professionals to focus more on patient care. They're poised to significantly enhance healthcare delivery and efficiency.\n\n**Future Prospects:**\nThe future of AI agents is promising, with continued evolution and integration into various platforms and ecosystems, offering more seamless and intelligent interactions. As these technologies advance, they are expected to redefine business operations and customer interactions.\n\n### AI_Agents_Overview_2023_Outline\n\n1. Introduction to AI Agents in 2023\n2. Popular AI Agents: Auto GPT, ChartGPT, LLMops\n3. Market Trends and Growth\n4. Key Players in the AI Agents Market\n5. Technological Innovations: Simulation and Generative AI\n6. Applications of AI Agents in Healthcare\n7. Future Prospects of AI Agents", additional_kwargs={}, response_metadata={}, name='writing_team', id='851bd8a6-740e-488c-8928-1f9e05e96ea0')]}}
---
{'supervisor': {'next': 'writing_team'}}
---
{'writing_team': {'messages': [HumanMessage(content='The documents have been successfully created and saved:\n\n1. **AI_Agents_Overview_2023.txt** - Contains the detailed overview of AI agents in 2023.\n2. **AI_Agents_Overview_2023_Outline.txt** - Contains the outline of the document.', additional_kwargs={}, response_metadata={}, name='writing_team', id='c87c0778-a085-4a8e-8ee1-9b43b9b0b143')]}}
---
{'supervisor': {'next': '__end__'}}
---