制作网页的网站费用属于资本性支出吗会展平面设计主要做什么
目录
安装模式介绍
下载Spark
安装Local模式
前提条件
解压安装包
简单使用
安装Standalone模式
前提条件
集群规划
解压安装包
配置Spark
配置Spark-env.sh
配置workers
分发到其他机器
启动集群
简单使用
关闭集群
安装YARN模式
前提条件
解压安装包
配置Spark
配置spark-env.sh
配置历史服务器
配置spark-env.sh
启动服务
简单使用
关闭服务
安装模式介绍
Spark常见的部署模式
(1)Local模式:在本地部署单个Spark服务,使用本地资源调度。(测试用)
(2)Standalone模式:构建一个由Master + Worker构成的Spark集群,使用Spark自带的资源调度执行任务,不需要借助Yarn或Mesos等其他框架资源。(不常用)
(3)YARN模式:Spark作为客户端,Spark直接使用Hadoop的YARN组件进行资源与任务调度。(常用)
(4)Mesos模式:和YARN模式类似。Spark直接使用Mesos进行资源与任务调度。
(5)K8S模式:和YARN模式类似。Spark直接使用K8S进行资源与任务调度。
这里介绍前面三种模式,安装模式对比如下
| 模式 | Spark安装机器数 | 需启动的进程 |
|---|---|---|
| Local模式 | 1 | 无 |
| Standalone模式 | 3 | Master、Worker |
| YARN模式 | 1 | YARN、HDFS |
下载Spark
下载Spark
https://archive.apache.org/dist/spark/spark-3.3.1/spark-3.3.1-bin-hadoop3.tgz
上传安装包到Linux /opt/software目录下
安装Local模式
解压安装包就完成Local模式安装,不需要任何配置,也不需要启动任何进程。
在node2机器操作。
前提条件
Linux机器安装好Java,可参考:openEuler24.03 LTS下安装Hadoop3完全分布式-安装Java
解压安装包
[liang@node2 ~]$ cd /opt/software
[liang@node2 sorfware]$ tar -zxvf spark-3.3.1-bin-hadoop3.tgz -C /opt/module
[liang@node2 sorfware]$ cd /opt/module
[liang@node2 sorfware]$ mv spark-3.3.1-bin-hadoop3 spark-local简单使用
使用Local模式计算pi
$ cd spark-local$ bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master local[2] \
./examples/jars/spark-examples_2.12-3.3.1.jar \
10命令参数介绍
--class 表示要执行程序的主类 --master 表示使用本地的多少核线程来计算 xxx.jar 表示程序所在的jar包 10 表示程序计算的次数
命令行查看结果
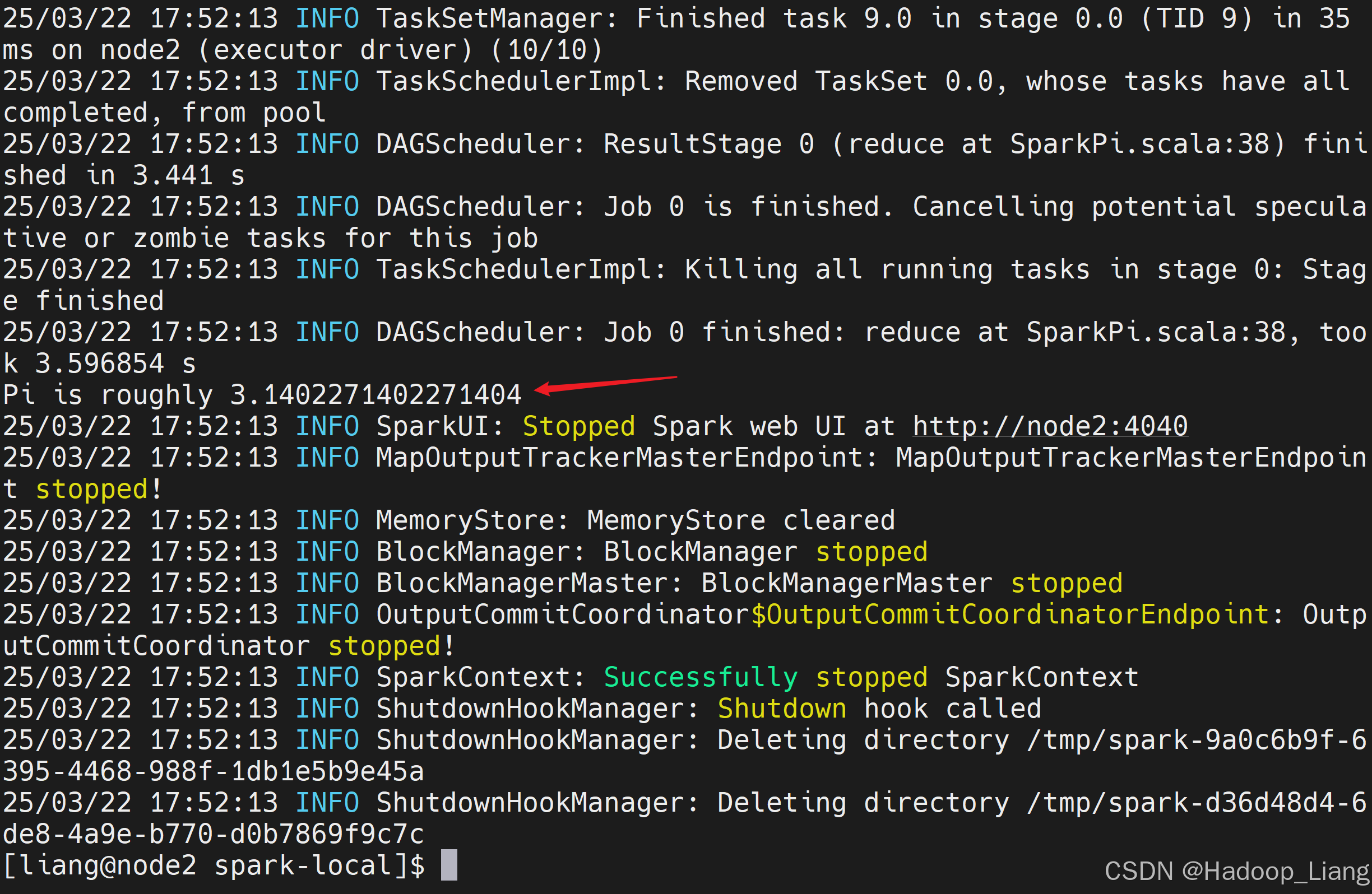
Web UI监控执行过程,浏览器访问如下地址
node2:4040
如果Web UI看不到,调大计算次数,再次查看Web UI
$ bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master local[2] \
./examples/jars/spark-examples_2.12-3.3.1.jar \
100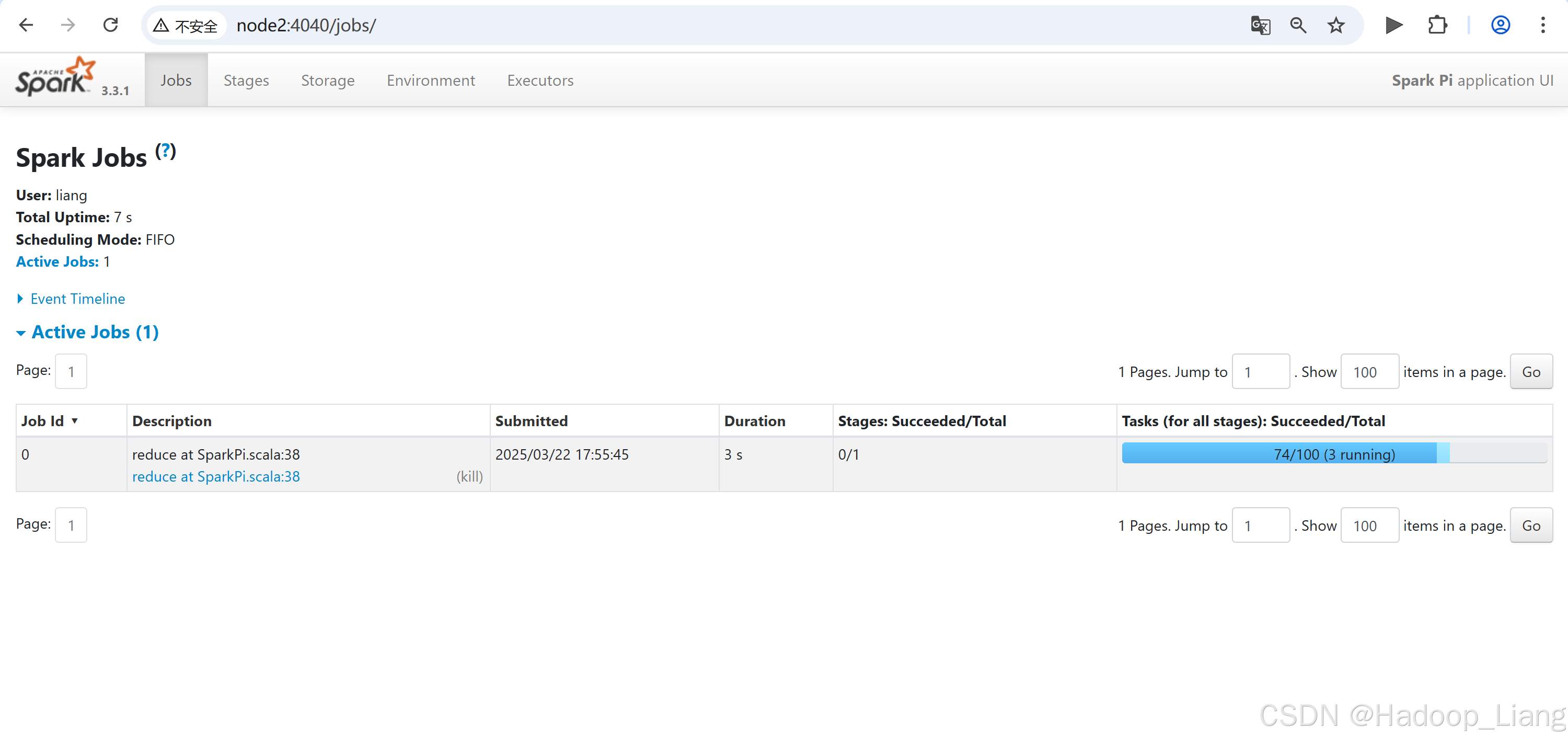
安装Standalone模式
前提条件
有三台Linux机器,都安装好Java,可参考:openEuler24.03 LTS下安装Hadoop3完全分布式-安装Java
集群规划
Spark Standalone集群规划
| node2 | node3 | node4 |
|---|---|---|
| Master | ||
| Woker | Worker | Worker |
解压安装包
解压安装包及重命名
[liang@node2 sorfware]$ cd /opt/software
[liang@node2 sorfware]$ tar -zxvf spark-3.3.1-bin-hadoop3.tgz -C /opt/module
[liang@node2 sorfware]$ cd /opt/module
[liang@node2 sorfware]$ mv spark-3.3.1-bin-hadoop3 spark-standalone配置Spark
进入Spark配置目录
[liang@node2 conf]$ cd spark-standalone/conf
[liang@node2 conf]$ ls
fairscheduler.xml.template metrics.properties.template spark-env.sh.template
log4j2.properties.template spark-defaults.conf.template workers.template配置Spark-env.sh
$ mv spark-env.sh.template spark-env.sh
$ vim spark-env.sh添加以下内容
export SPARK_MASTER_HOST=node2配置workers
[liang@node2 conf]$ mv workers.template workers
[liang@node2 conf]$ vim workers删除原有localhost,添加如下内容
node2
node3
node4分发到其他机器
$ xsync /opt/module/spark-standalone启动集群
启动集群
[liang@node2 conf]$ cd /opt/module/spark-standalone
[liang@node2 spark-standalone]$ sbin/start-all.sh执行输出
[liang@node2 spark-standalone]$ sbin/start-all.sh starting org.apache.spark.deploy.master.Master, logging to /opt/module/spark-standalone/logs/spark-liang-org.apache.spark.deploy.master.Master-1-node2.out node2: starting org.apache.spark.deploy.worker.Worker, logging to /opt/module/spark-standalone/logs/spark-liang-org.apache.spark.deploy.worker.Worker-1-node2.out node3: starting org.apache.spark.deploy.worker.Worker, logging to /opt/module/spark-standalone/logs/spark-liang-org.apache.spark.deploy.worker.Worker-1-node3.out node4: starting org.apache.spark.deploy.worker.Worker, logging to /opt/module/spark-standalone/logs/spark-liang-org.apache.spark.deploy.worker.Worker-1-node4.out
jps查看进程
$ jpsall执行输出
[liang@node2 spark-standalone]$ jpsall =============== node2 =============== 2839 Worker 2921 Jps 2701 Master =============== node3 =============== 2092 Jps 2030 Worker =============== node4 =============== 2096 Jps 2034 Worker
简单使用
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://node2:7077 \
--deploy-mode client \
--driver-memory 1G \
--executor-memory 1G \
--total-executor-cores 2 \
--executor-cores 1 \
./examples/jars/spark-examples_2.12-3.3.1.jar \
10查看Web UI
node2:8080
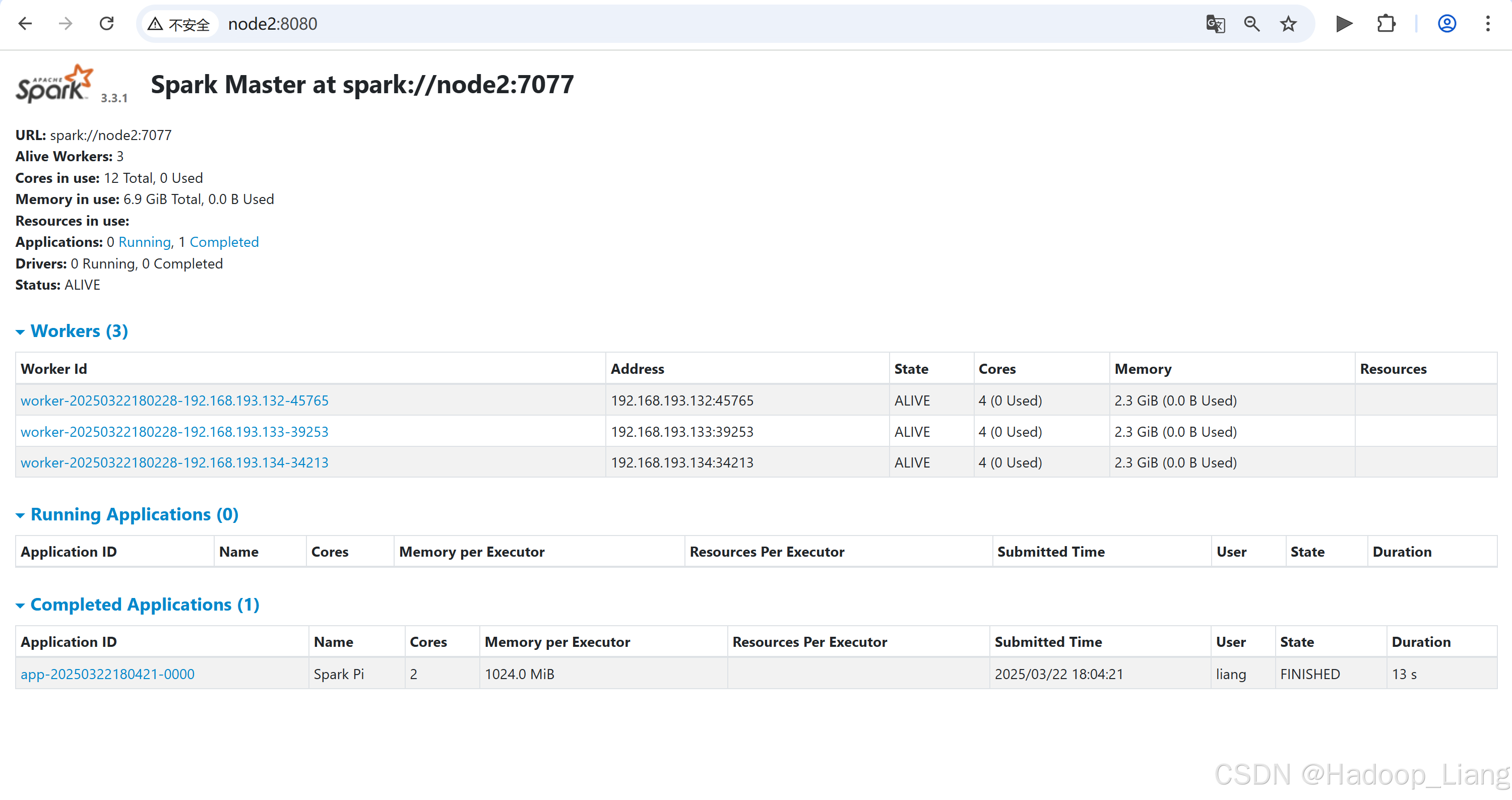
delploy-mode 为client运行,结果直接在客户端显示

deploy-mode 可以改为 cluster ,测试看看效果,运行结果需要登录Web页面的driver 日志查看。
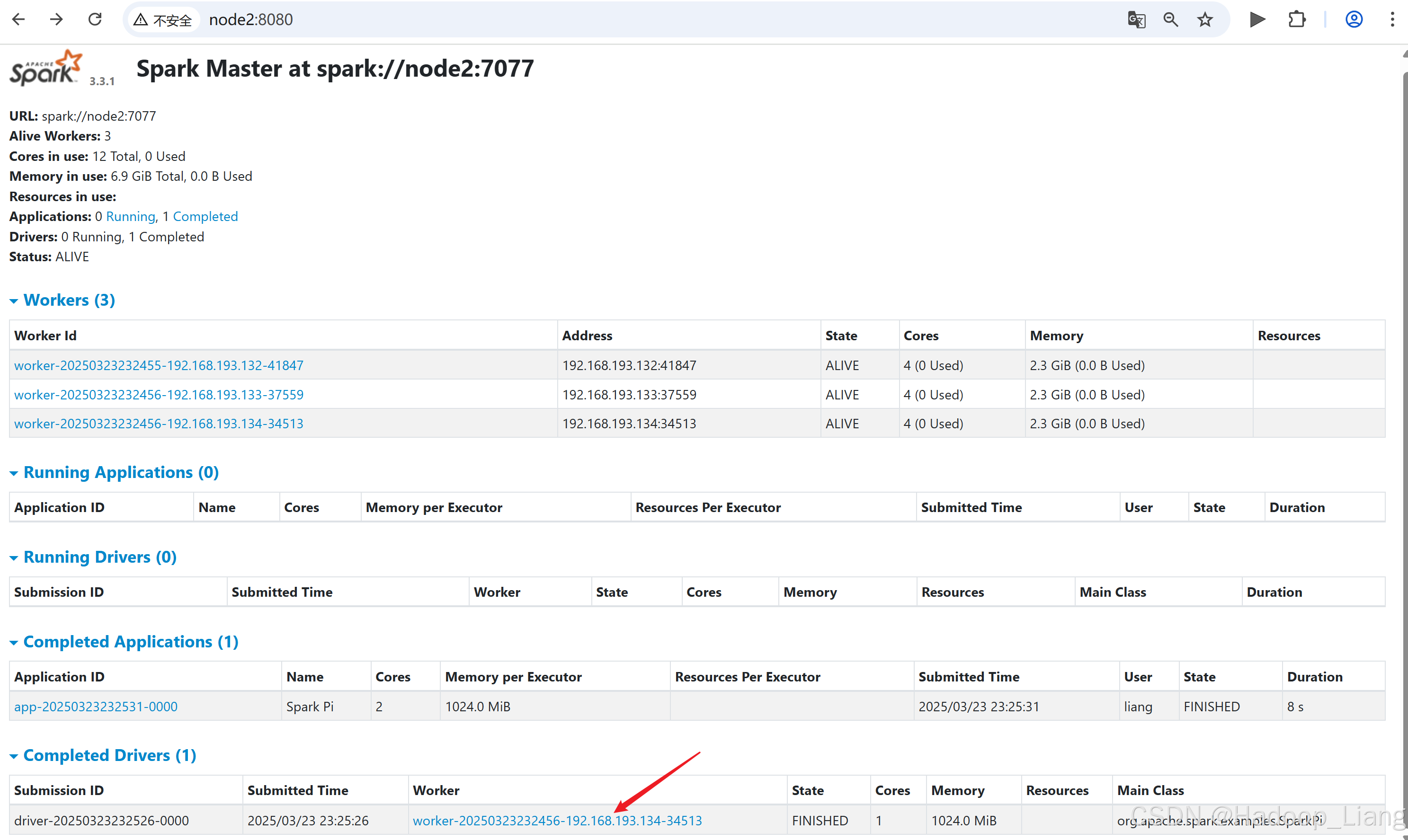
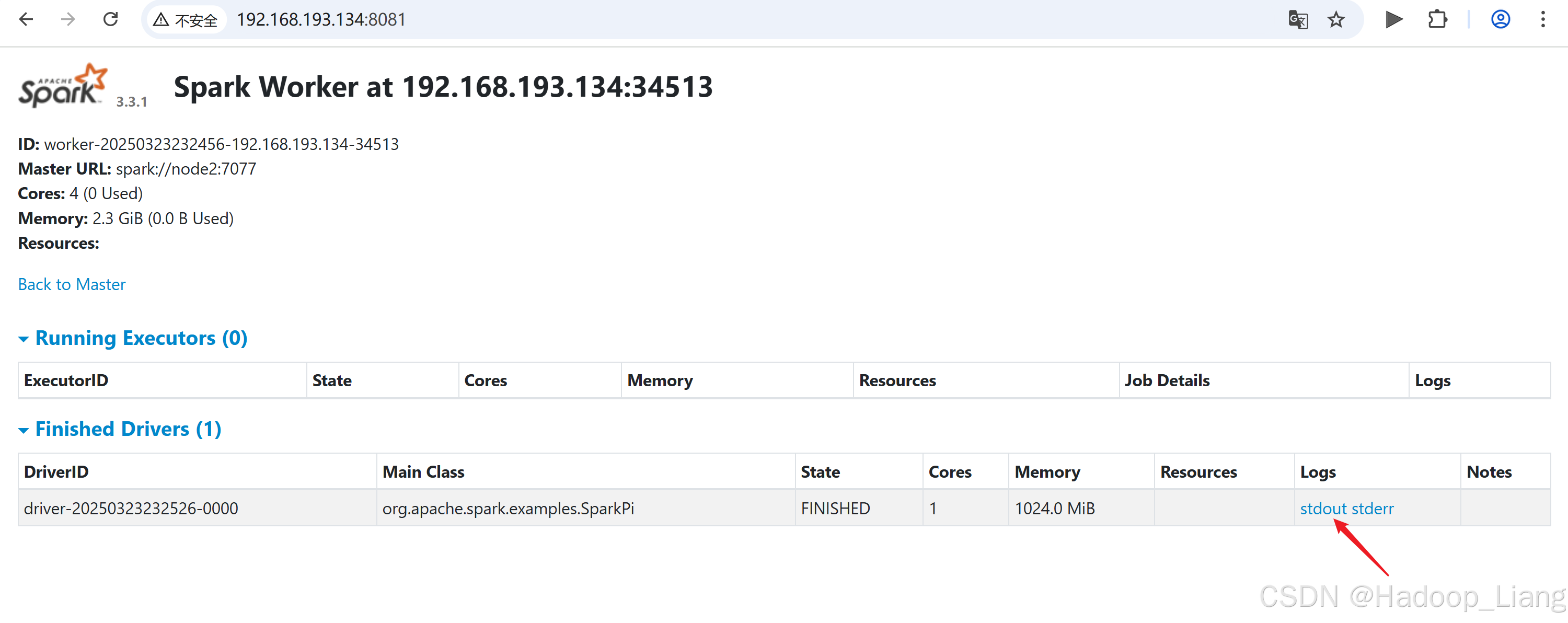
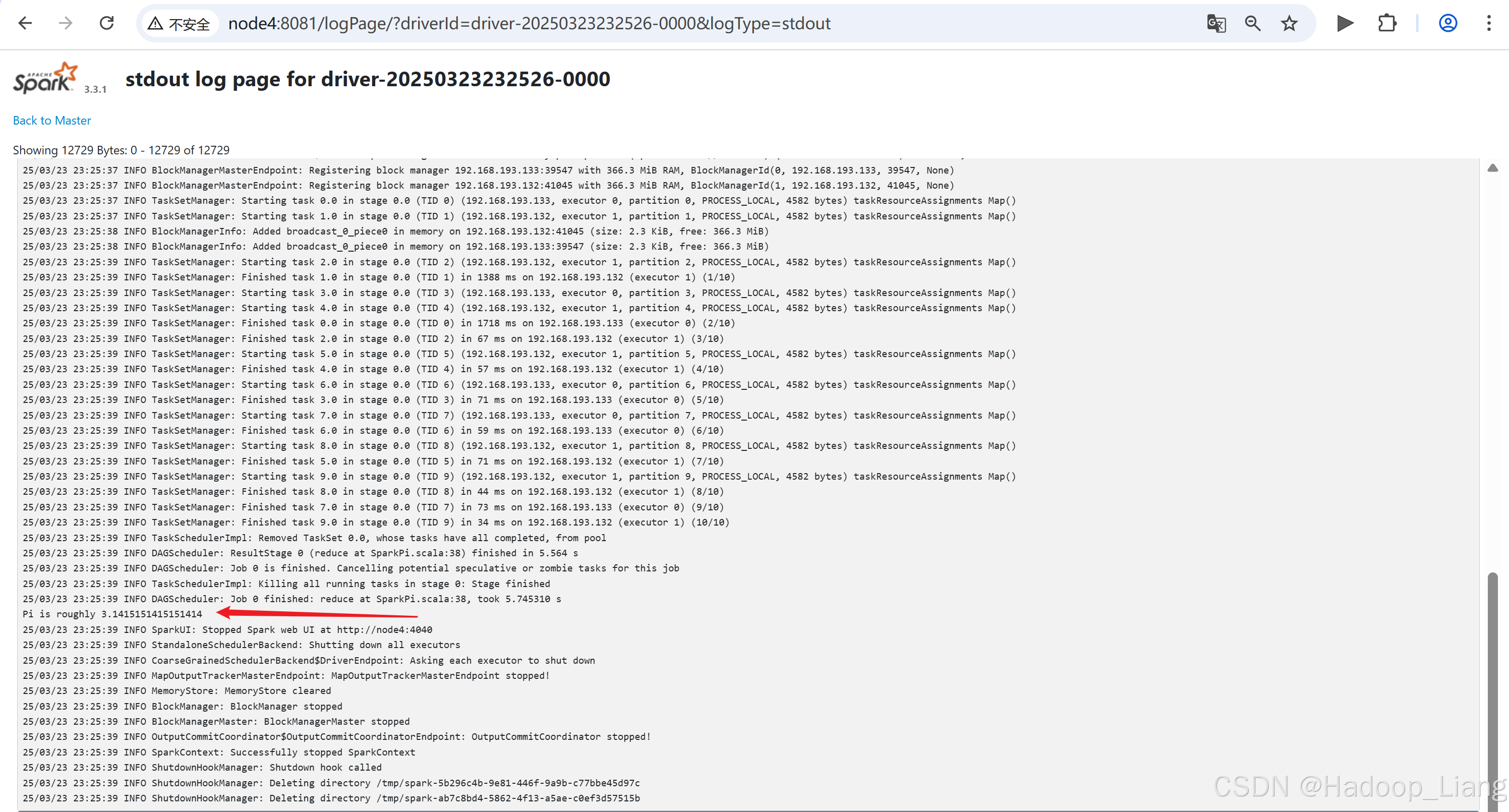
[liang@node2 spark-standalone]$ bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://node2:7077 --deploy-mode cluster --driver-memory 1G --executor-memory 1G --total-executor-cores 2 --executor-cores 1 ./examples/jars/spark-examples_2.12-3.3.1.jar 10如果访问速度较块,可以看到并点击Running Drivers下Worker的超链接
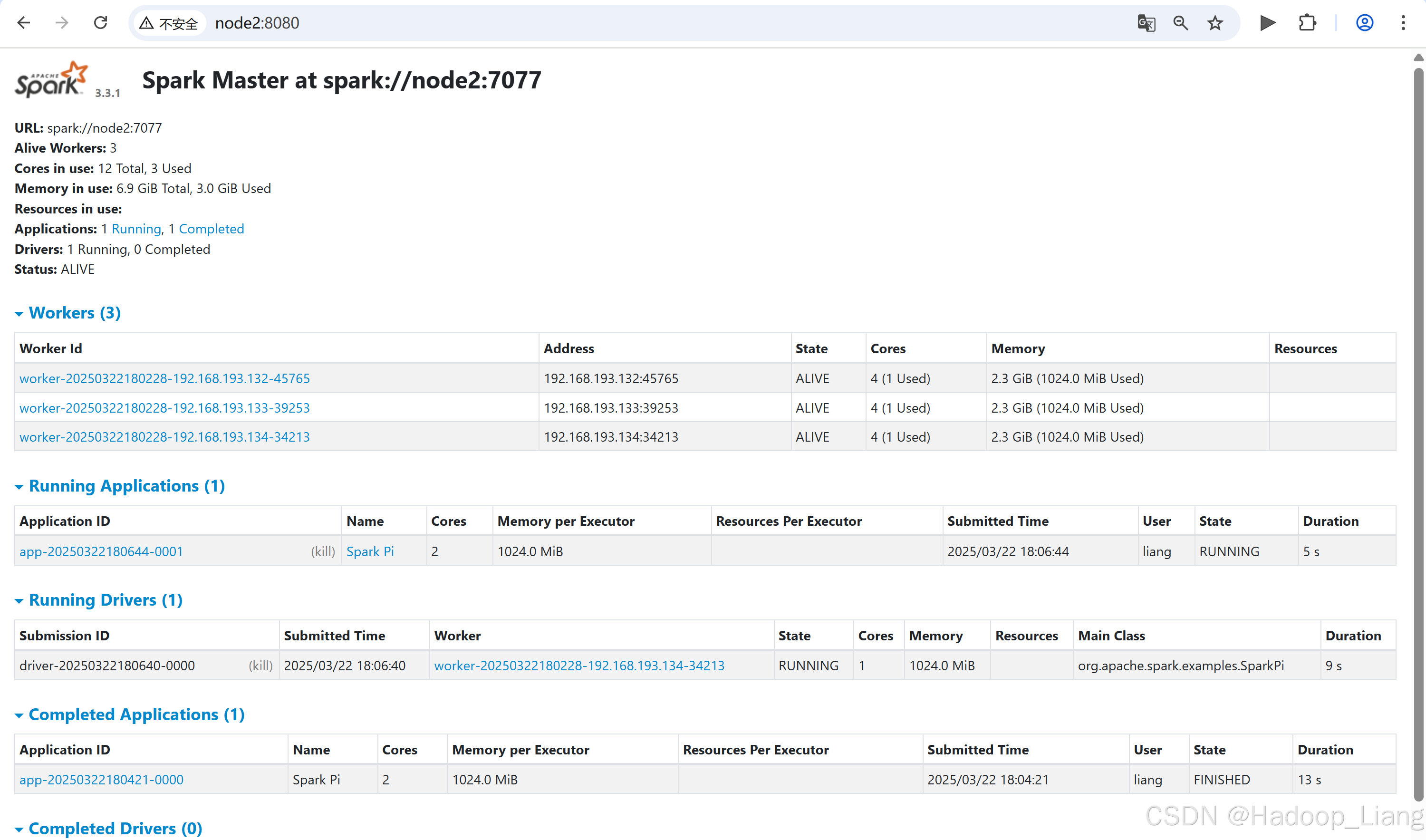


如果运行完成,过一定的时间后,可以在Completed Drivers的Worker去找结果
关闭集群
关闭集群
./sbin/stop-all.shjps查看进程
jpsall操作过程
[liang@node2 spark-standalone]$ sbin/stop-all.sh node3: stopping org.apache.spark.deploy.worker.Worker node2: stopping org.apache.spark.deploy.worker.Worker node4: stopping org.apache.spark.deploy.worker.Worker stopping org.apache.spark.deploy.master.Master [liang@node2 spark-standalone]$ jpsall =============== node2 =============== 3404 Jps =============== node3 =============== 2365 Jps =============== node4 =============== 2371 Jps
安装YARN模式
在node2机器操作
前提条件
安装好Hadoop完全分布式集群, 可参考:openEuler24.03 LTS下安装Hadoop3完全分布式
解压安装包
[liang@node2 ~]$ cd /opt/software
[liang@node2 sorfware]$ tar -zxvf spark-3.3.1-bin-hadoop3.tgz -C /opt/module
[liang@node2 sorfware]$ cd /opt/module
[liang@node2 sorfware]$ mv spark-3.3.1-bin-hadoop3 spark-yarn配置Spark
进入Spark配置目录
[liang@node2 conf]$ cd spark-yarn/conf
[liang@node2 conf]$ ls
fairscheduler.xml.template metrics.properties.template spark-env.sh.template
log4j2.properties.template spark-defaults.conf.template workers.template配置spark-env.sh
$ mv spark-env.sh.template spark-env.sh
$ vim spark-env.sh添加如下内容
YARN_CONF_DIR=/opt/module/hadoop-3.3.4/etc/hadoop配置含义:告诉Spark yarn的配置哪里,yarn-site.xml配置了yarn相关信息。
配置历史服务器
配置spark-defaults.conf
$ mv spark-defaults.conf.template spark-defaults.conf
$ vim spark-defaults.conf末尾添加如下内容
# 打开记录事件日志
spark.eventLog.enabled true
# 事件记录保存地址,需要提前手动创建
spark.eventLog.dir hdfs://node2:8020/spark-evenlog-directory
# yarn关联跳转到spark历史服务器地址
spark.yarn.historyServer.address=node2:18080
# spark历史服务器地址
spark.history.ui.port=18080配置spark-env.sh
$ vim spark-env.sh添加如下内容
export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.fs.logDirectory=hdfs://node2:8020/spark-evenlog-directory
-Dspark.history.retainedApplications=30"启动服务
启动Hadoop
$ hdp.sh start创建历史服务的存储目录
$ hdfs dfs -mkdir /spark-evenlog-directory启动Spark历史服务
$ cd ../
$ sbin/start-history-server.sh jps查看进程
[liang@node2 spark-yarn]$ jpsall =============== node2 =============== 4706 NameNode 5650 JobHistoryServer 4916 DataNode 5349 NodeManager 6070 Jps 5997 HistoryServer =============== node3 =============== 3888 Jps 3016 DataNode 3275 ResourceManager 3420 NodeManager =============== node4 =============== 3203 SecondaryNameNode 3654 Jps 3415 NodeManager 3032 DataNode
在node2能看到Spark的HistoryServer进程
简单使用
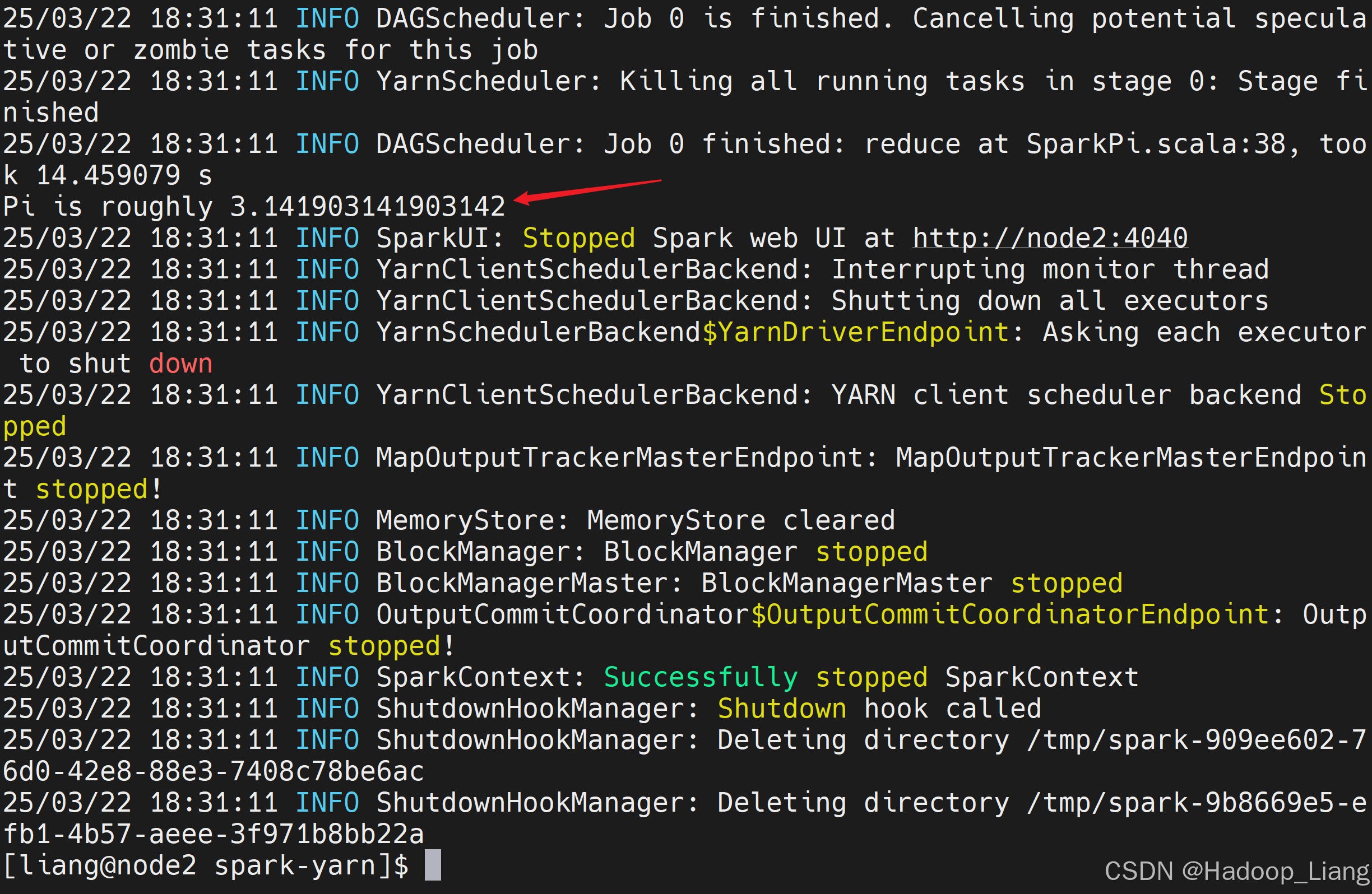
使用Spark YARN模式计算pi
$ bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
./examples/jars/spark-examples_2.12-3.3.1.jar \
10计算完成后,控制台结果如下
Web UI查看日志
node3:8088
点击具体作业的History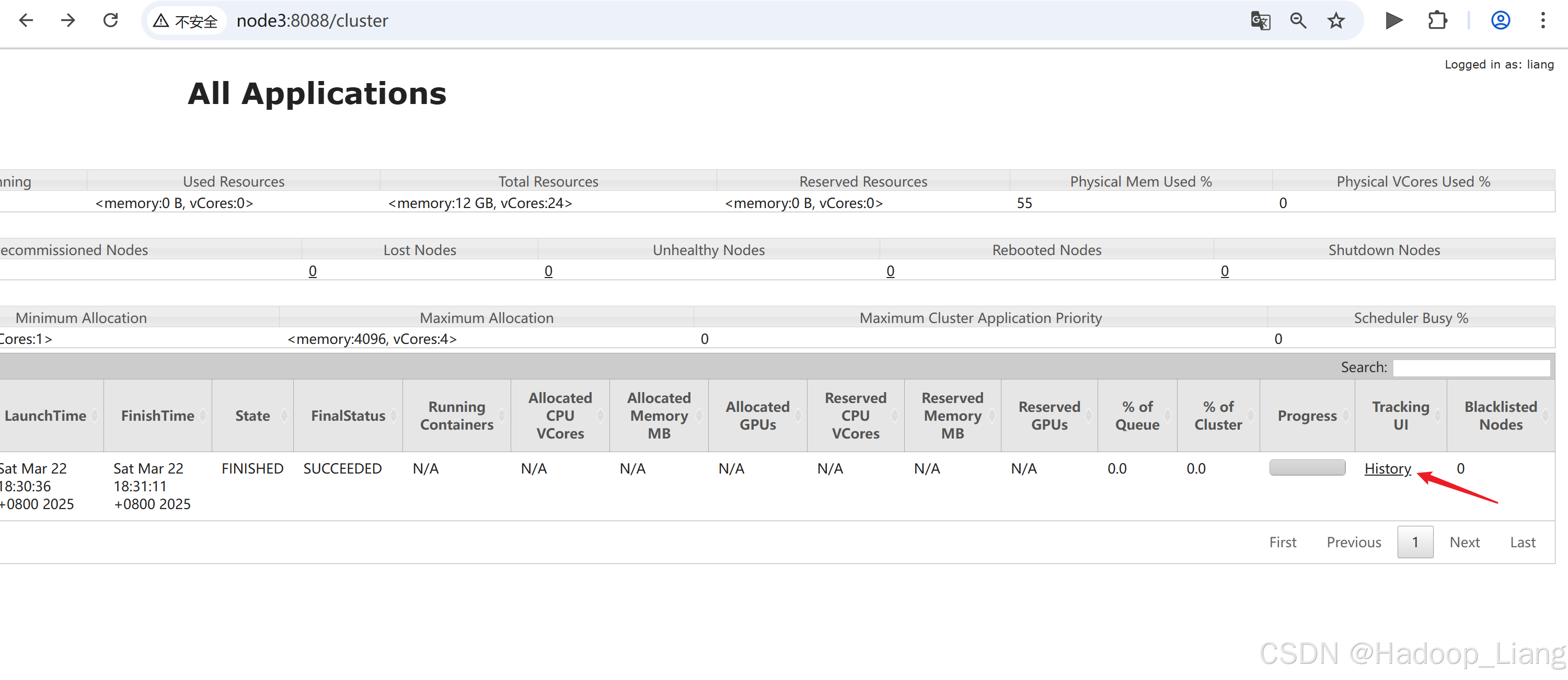 跳转到了Spark的历史服务
跳转到了Spark的历史服务node2:18080

点击Description下的链接
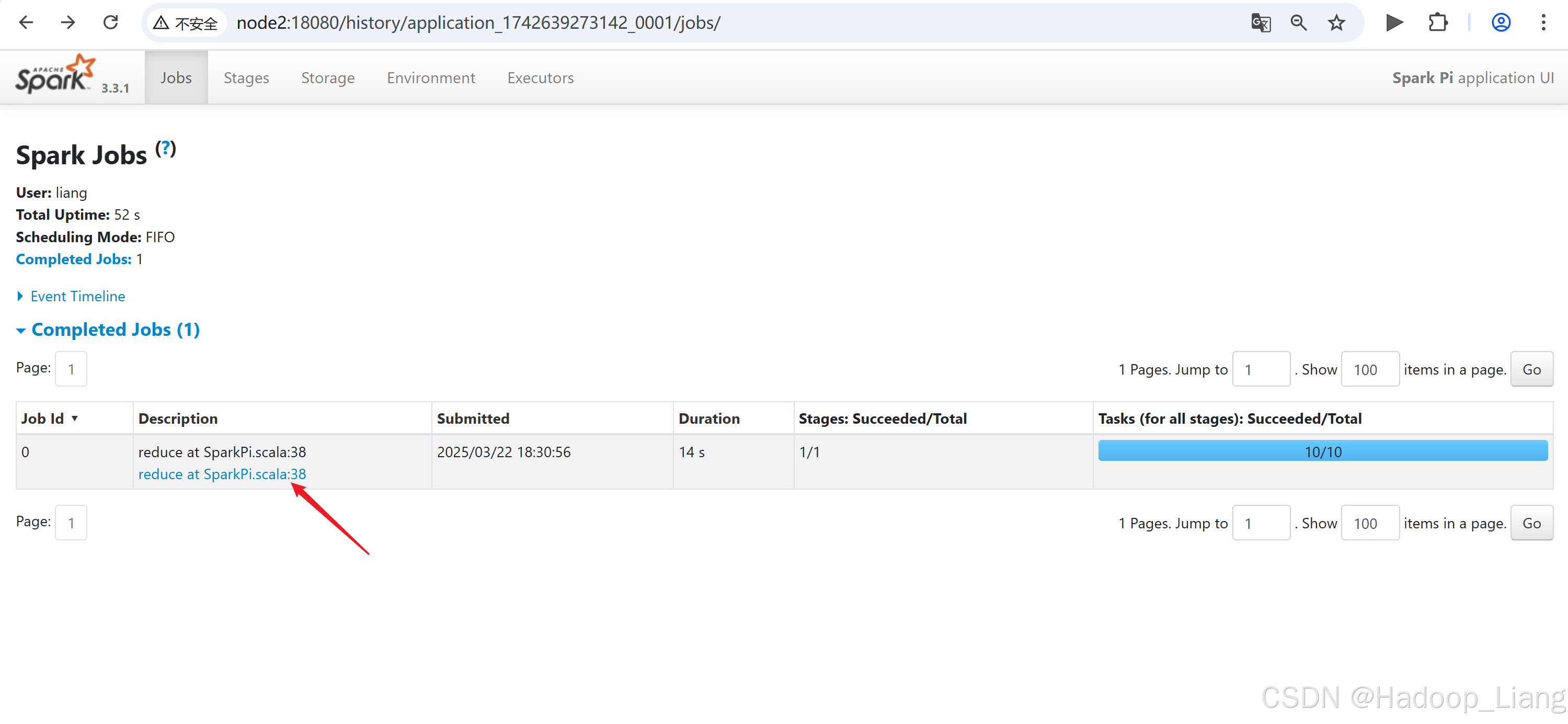
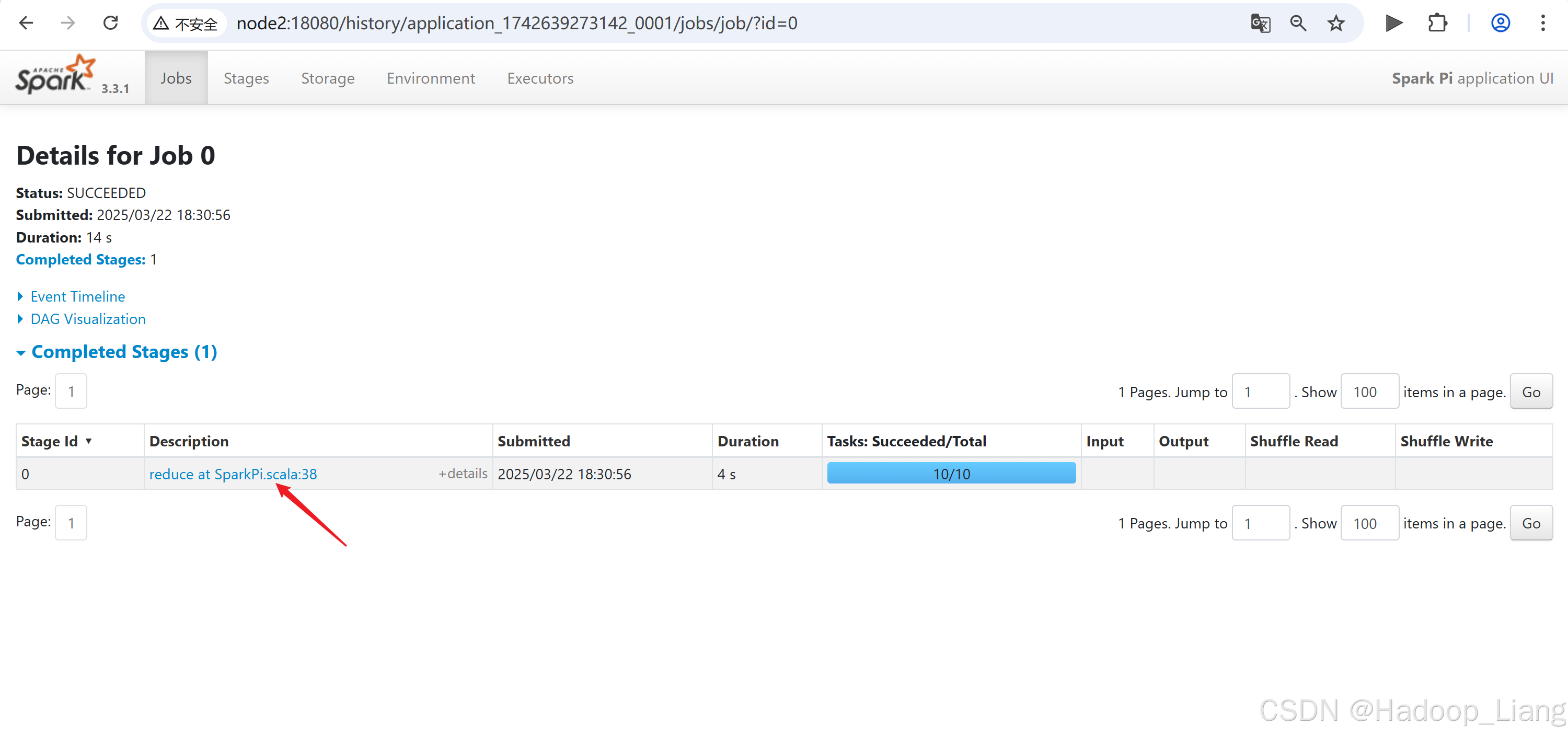
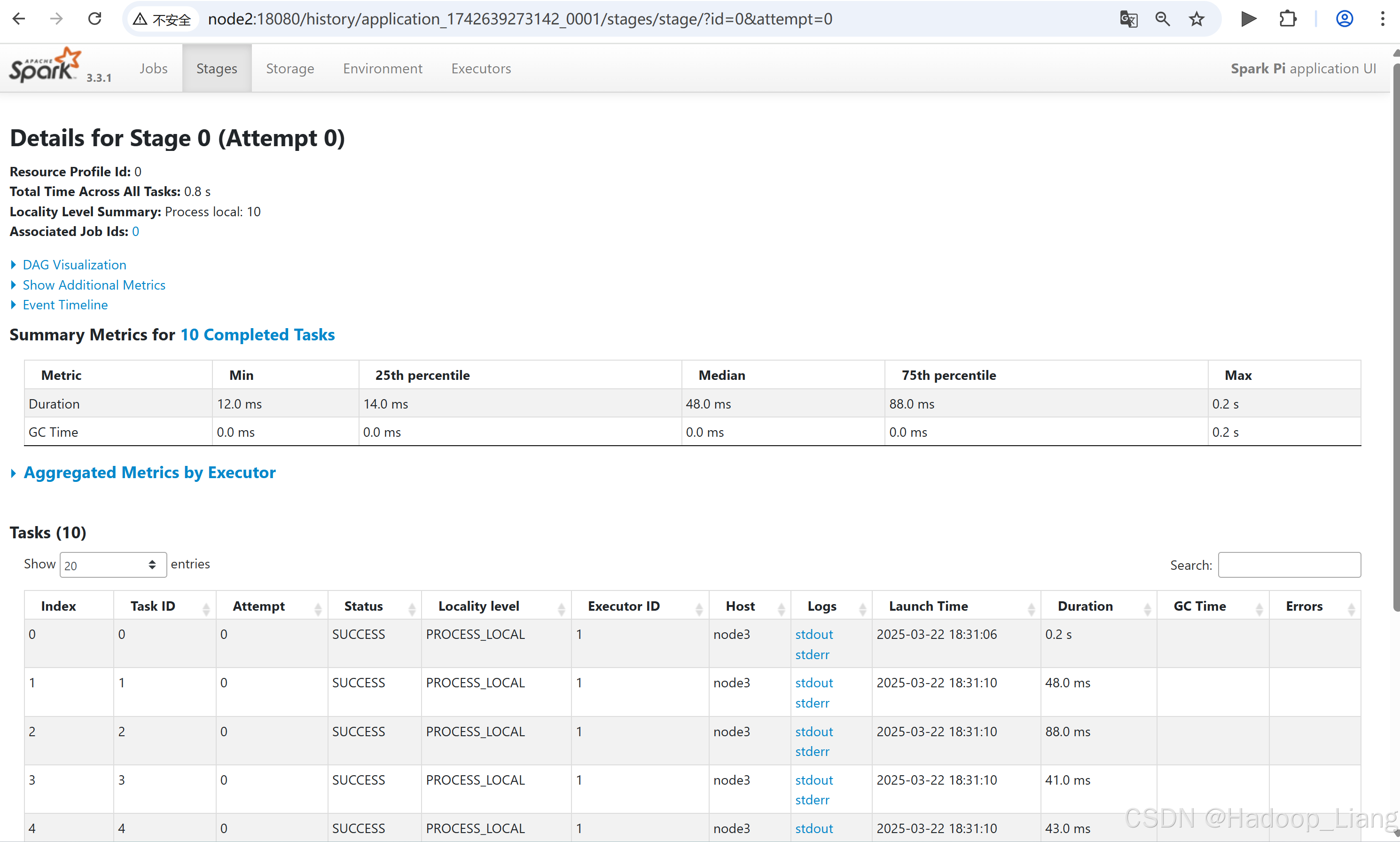
点击需要查看的日志,例如:查看最后一次Index的stdout日志
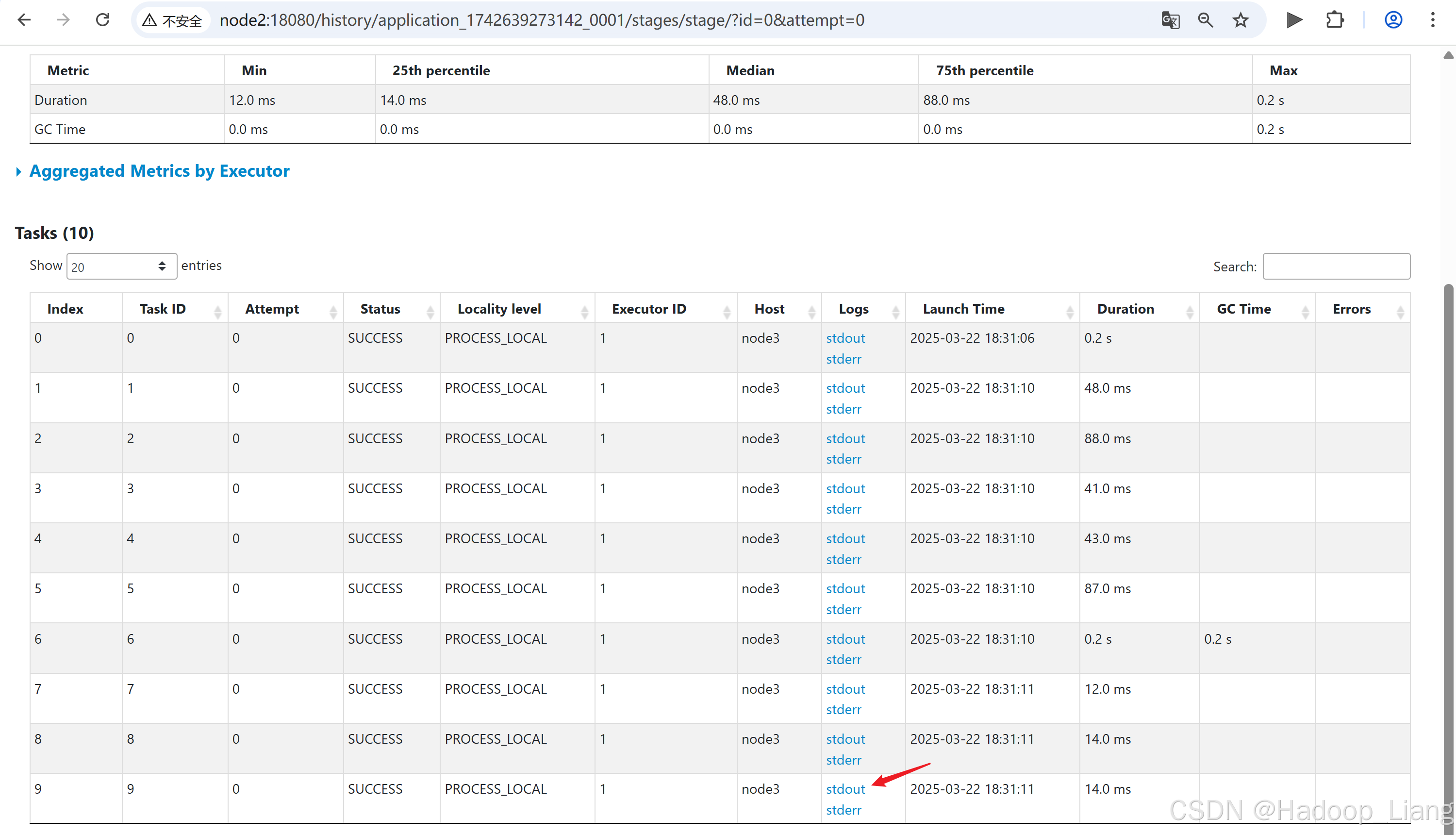
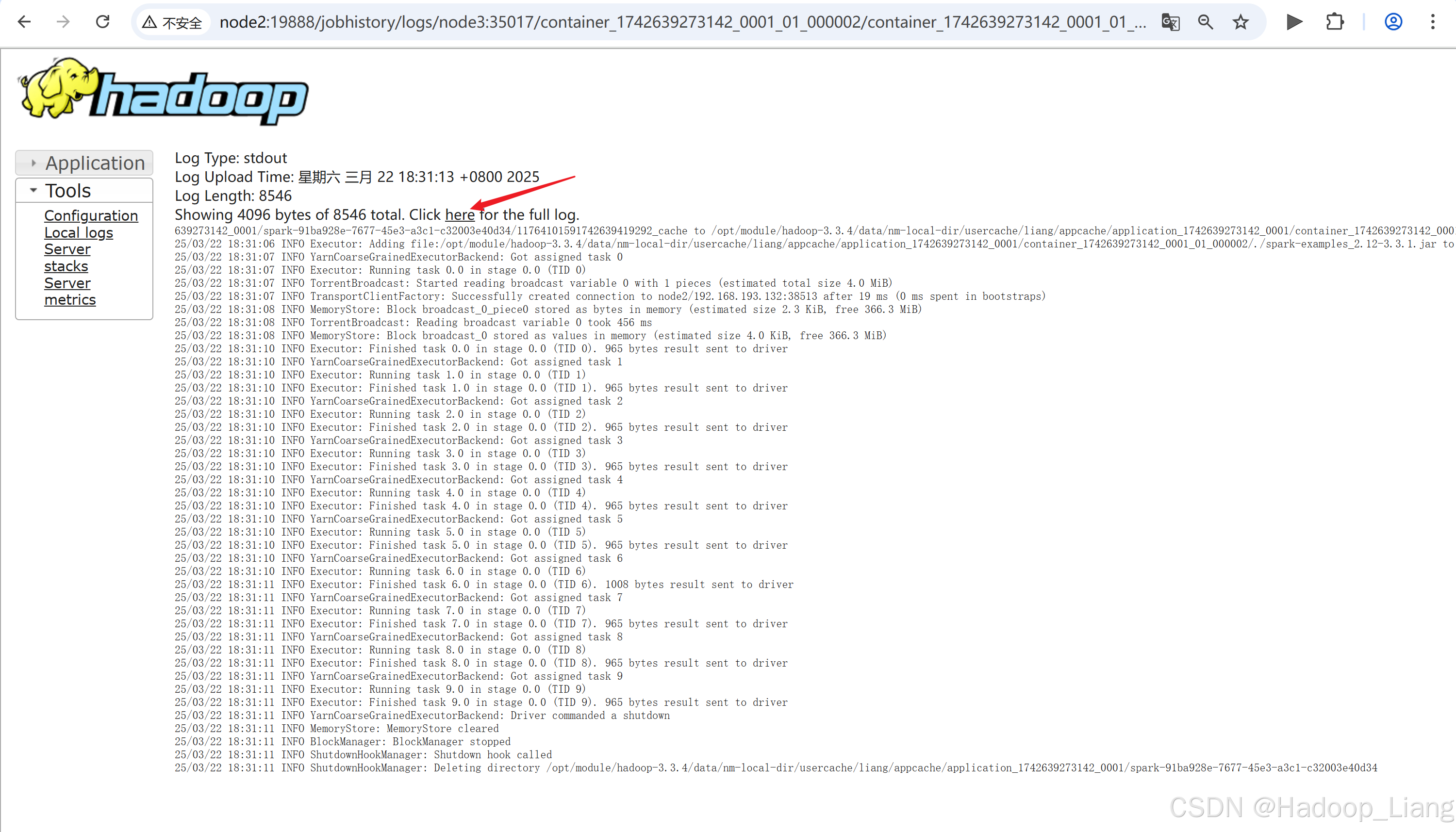
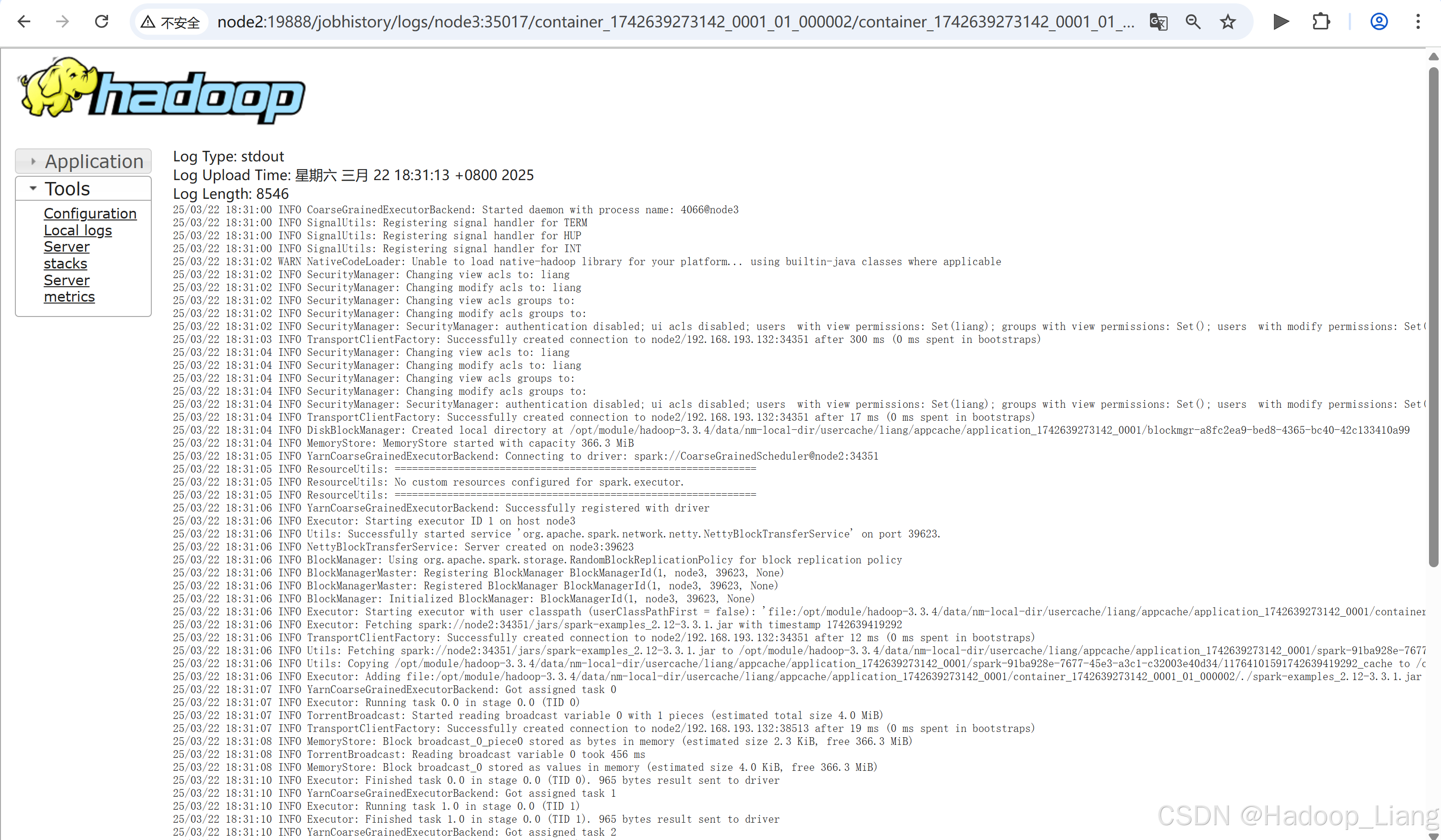
关闭服务
$ sbin/stop-history-server.sh
$ hdp.sh stopjps查看进程
[liang@node2 spark-yarn]$ jpsall =============== node2 =============== 24703 Jps =============== node3 =============== 16513 Jps =============== node4 =============== 14598 Jps
如有需要,可点击查看:配套视频教程
完成!enjoy it!