自己开通一个网站需要多少钱淘宝指数查询官网手机版
当助教时需要统计同学提交作业情况,邮箱接收压缩包。统计完成情况,故搞了个python脚本帮助统计。(根据文件名需要微调)
import os
import pandas as pd
import redef check_persons_in_filenames(excel_path, folder_path, output_path=None):"""检查压缩文件名中是否包含Excel表格中的人员名字,并标记已出现的人员参数:excel_path: 包含人员名单的Excel文件路径folder_path: 包含压缩文件的文件夹路径output_path: 输出Excel文件的路径,默认为原文件名_processed.xlsx"""# 读取人员名单Excel文件try:df = pd.read_excel(excel_path)print(f"成功读取Excel文件: {excel_path}")print(f"Excel文件包含 {len(df)} 行数据")except Exception as e:print(f"读取Excel文件时出错: {e}")return# 确保DataFrame中有名字列if '姓名' in df.columns:person_column = '姓名'elif '人员' in df.columns:person_column = '人员'elif '名字' in df.columns:person_column = '名字'else:# 假设第一列是人员名称person_column = df.columns[0]print(f"未找到明确的人员名称列,使用第一列 '{person_column}' 作为人员名称")# 获取所有压缩文件名compressed_extensions = ['.zip', '.rar', '.7z', '.tar', '.gz']files = []try:for file in os.listdir(folder_path):file_lower = file.lower()if any(file_lower.endswith(ext) for ext in compressed_extensions):files.append(file)# 打印找到的每个文件,方便调试print(f"发现文件: {file}")print(f"共找到 {len(files)} 个压缩文件")# 如果没有找到文件,给出警告if not files:print("警告: 未在指定文件夹中找到任何压缩文件。请确认路径和文件扩展名是否正确。")except Exception as e:print(f"读取文件夹时出错: {e}")return# 为每个人员检查文件名中是否包含其名字result_column = '提交情况'df[result_column] = ''NumOfSub = 0# 预先编译中文名字的正则表达式模式chinese_pattern = re.compile(r'[\u4e00-\u9fa5]{2,}')for index, row in df.iterrows():person_name = str(row[person_column]).strip()if not person_name or pd.isna(person_name):continue# 在文件名中查找人员名字matches = []for file in files:# 处理方法1:直接查找姓名direct_match = re.search(f'(^|[^\\w]){re.escape(person_name)}([^\\w]|$)', file)# 处理方法2:查找学号后面紧跟的中文名字# 从文件名中提取所有可能的中文名字chinese_names = chinese_pattern.findall(file)# 检查每个提取出的中文名字是否与人员名单中的名字匹配name_match = any(name.strip() == person_name for name in chinese_names)# 处理方法3:考虑名字与学号之间可能有空格的情况student_id_pattern = r'\d{10,}[\s]*' + re.escape(person_name)id_match = re.search(student_id_pattern, file)if direct_match or name_match or id_match:matches.append(file)# 如果找到匹配,则标记该人员if matches:NumOfSub += 1df.at[index, result_column] = "已提交"# 设置默认输出路径if output_path is None:base_name = os.path.splitext(excel_path)[0]output_path = f"{base_name}_processed.xlsx"# 保存处理后的Exceltry:df.to_excel(output_path, index=False)print(f"提交人数: {NumOfSub}")print(f"处理完成,结果已保存至: {output_path}")except Exception as e:print(f"保存Excel文件时出错: {e}")def extract_names_from_filenames(files):"""从文件名中提取可能的中文姓名,用于调试"""chinese_pattern = re.compile(r'[\u4e00-\u9fa5]{2,}')extracted_names = {}for file in files:names = chinese_pattern.findall(file)if names:extracted_names[file] = namesreturn extracted_namesif __name__ == "__main__":# 用户输入excel_path = input("请输入人员名单Excel文件的路径: ")folder_path = input("请输入包含压缩文件的文件夹路径: ")output_path = input("请输入输出Excel文件的路径(可选,直接回车使用默认路径): ")if not output_path:output_path = None# 检查路径是否存在if not os.path.exists(excel_path):print(f"错误: Excel文件路径不存在: {excel_path}")elif not os.path.exists(folder_path):print(f"错误: 文件夹路径不存在: {folder_path}")else:# # 添加调试选项# debug = input("是否需要调试模式? (y/n, 默认n): ").lower().startswith('y')# if debug:# try:# files = [f for f in os.listdir(folder_path) if any(f.lower().endswith(ext) for ext in ['.zip', '.rar', '.7z', '.tar', '.gz'])]# print("\n===== 调试信息 =====")# print(f"发现的文件: {files}")# # 从Excel读取人员名单# df = pd.read_excel(excel_path)# person_column = None# for col in ['姓名', '人员', '名字']:# if col in df.columns:# person_column = col# break# if not person_column and len(df.columns) > 0:# person_column = df.columns[0]# if person_column:# print(f"\nExcel中的人员名单 (列: {person_column}):")# for name in df[person_column].dropna().tolist():# print(f" - {name}")# # 提取文件名中的中文姓名# names_in_files = extract_names_from_filenames(files)# if names_in_files:# print("\n文件名中提取的可能姓名:")# for file, names in names_in_files.items():# print(f" 文件: {file}")# print(f" 提取的名字: {', '.join(names)}")# print("===== 调试结束 =====\n")# proceed = input("是否继续处理? (y/n, 默认y): ")# if proceed.lower().startswith('n'):# print("已取消处理")# exit()# except Exception as e:# print(f"调试过程中出错: {e}")check_persons_in_filenames(excel_path, folder_path, output_path)输入示例:
包含压缩包的文件夹:
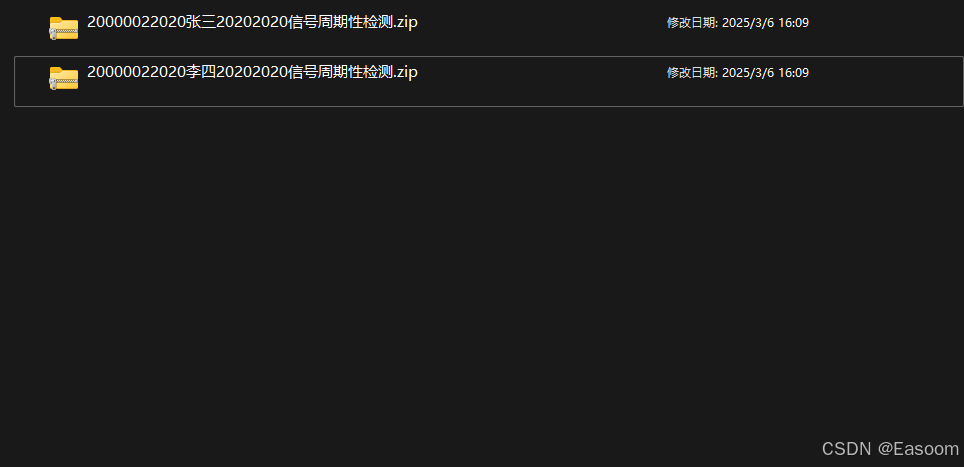
输入excel:

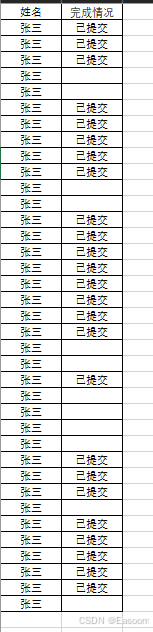
输出示例:
输出excel: