织梦如何做网站wordpress如何换图片不显示不出来
1. Qwen3介绍
节前qwen团队开源了qwen3,带来了性能更强的模型【1】:
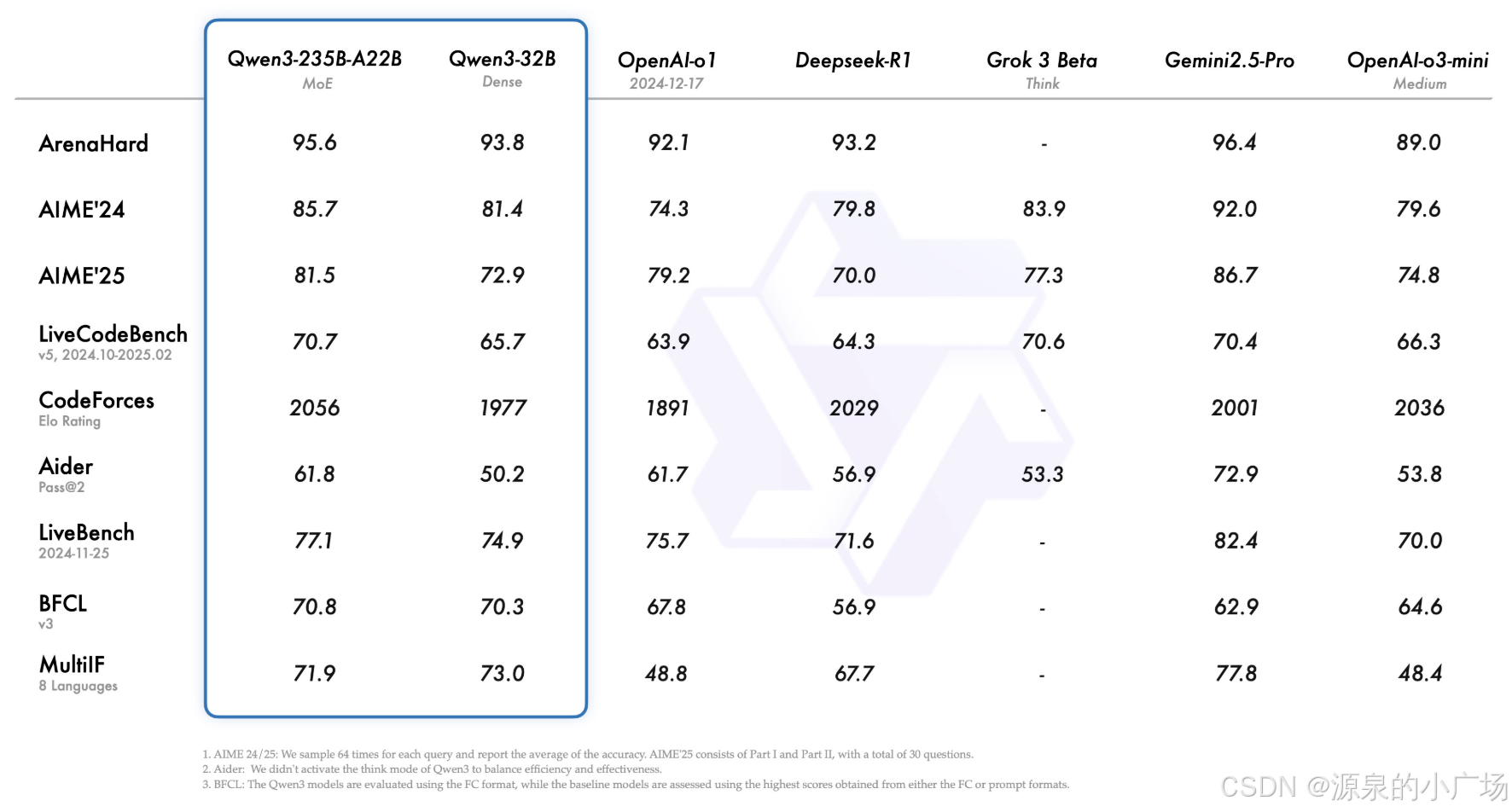
并且一口气开源了8款不同尺寸的版本,分别是Qwen3-32B, Qwen3-14B, Qwen3-8B, Qwen3-4B, Qwen3-1.7B, and Qwen3-0.6B。
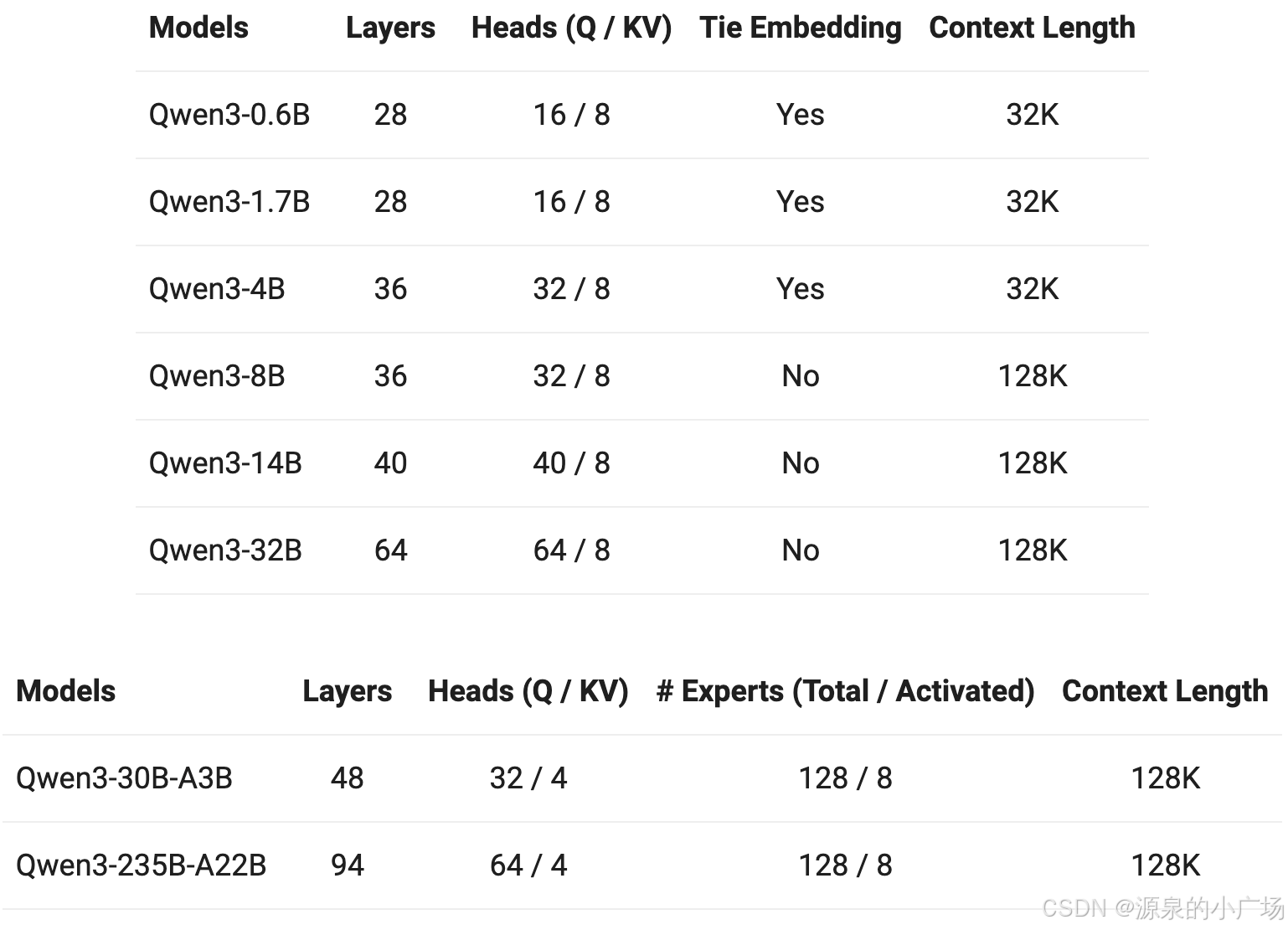
Qwen3提到了几个关键feature,包括混合思考、MCP支持,我们稍后会在第三部分针对混合思考做一些讨论。
另外qwen团队构建了四阶段训练框架,具体包括:(1)长思维链(CoT)冷启动;(2)基于推理的强化学习(RL);(3)思维模式融合;(4)通用强化学习。
这个模式其实还是沿用了DeepSeek的路线,参考《DeepSeek-R1与O1复现的技术路线对比及R1展现出OpenAI Moment的价值探讨》,大厂追求的还是稳,创新还得交给openai、deepseek这类公司去探索,也许R2推出会带来新的训练范式。
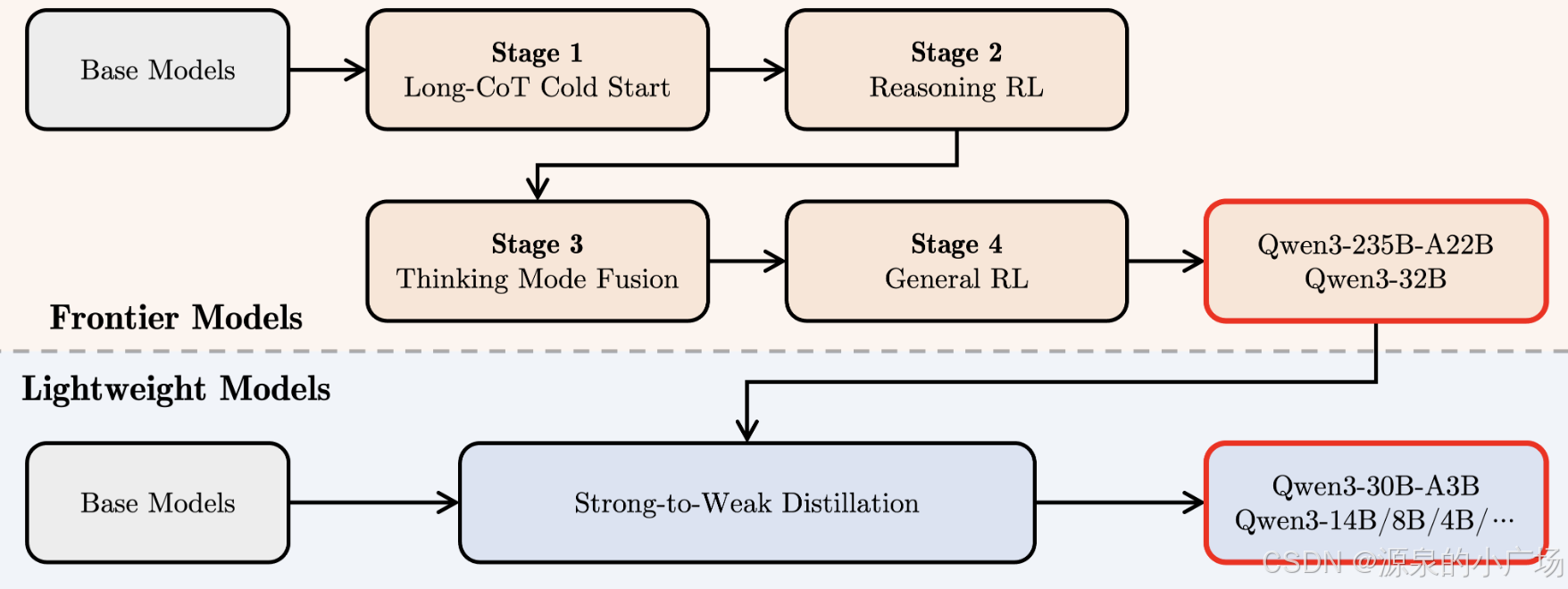
在第一阶段,采用跨领域的长思维链数据(涵盖数学、编程、逻辑推理及STEM问题等)对模型进行微调,培养基础推理能力。第二阶段通过扩大计算资源投入,利用基于规则的奖励机制,系统性提升模型的探索与决策能力。
第三阶段将"非思考"能力整合至思考模型:使用第二阶段增强版思考模型生成的数据,混合长思维链与常规指令微调数据进行联合训练,实现两种模式的无缝融合。最终在第四阶段,在超过20项通用任务(包括指令遵循、格式规范、智能体能力等)上实施强化学习,进一步巩固模型通用能力并修正不良行为模式。
2. Qwen3部署和实测
我们从modelscope上下载Qwen3 32B的稠密模型版本,模型参数大小为62G,采用A800 4卡部署推理:
基于vllm推理框架:
CUDA_VISIBLE_DEVICES=0,1,2,3 \
vllm serve /data/Qwen3 \
--served-model-name Qwen3-32B \
--tensor-parallel-size 4 \
--gpu-memory-utilization 0.8 \
--max-num-seqs 8 \
--enable-reasoning \
--reasoning-parser deepseek_r1 \
--port 40928注意:这里需要根据实际的资源设置gpu的利用占比,很容易出现out-of-memory,单张卡占用别太高。
测试脚本:
from openai import OpenAIopenai_api_key = "EMPTY"
openai_api_base = "xxx/v1"client = OpenAI(api_key=openai_api_key,base_url=openai_api_base,
)chat_response = client.chat.completions.create(model = "Qwen3-32B",messages=[{"role": "user", "content": "写个作文,一万字"}],temperature=0,top_p=0.8,extra_body={"repetition_penalty": 1.05,},
)
print(chat_response.choices[0].message.content)执行日志:每秒约40tokens的生成速度也还不错
NFO 05-02 09:50:50 chat_utils.py:332] Detected the chat template content format to be 'string'. You can set `--chat-template-content-format` to override this.
INFO 05-02 09:50:50 logger.py:39] Received request chatcmpl-e1dd7a18e3d54ea7bc083936e85f9e74: prompt: '<|im_start|>user\n写个作文,一万字<|im_end|>\n<|im_start|>assistant\n', params: SamplingParams(n=1, presence_penalty=0.0, frequency_penalty=0.0, repetition_penalty=1.05, temperature=0.0, top_p=1.0, top_k=-1, min_p=0.0, seed=None, stop=[], stop_token_ids=[], bad_words=[], include_stop_str_in_output=False, ignore_eos=False, max_tokens=2048, min_tokens=0, logprobs=None, prompt_logprobs=None, skip_special_tokens=True, spaces_between_special_tokens=True, truncate_prompt_tokens=None, guided_decoding=None), prompt_token_ids: None, lora_request: None, prompt_adapter_request: None.
INFO 05-02 09:50:50 engine.py:275] Added request chatcmpl-e1dd7a18e3d54ea7bc083936e85f9e74.
INFO 05-02 09:50:50 metrics.py:455] Avg prompt throughput: 1.6 tokens/s, Avg generation throughput: 0.1 tokens/s, Running: 1 reqs, Swapped: 0 reqs, Pending: 0 reqs, GPU KV cache usage: 0.0%, CPU KV cache usage: 0.0%.
INFO 05-02 09:50:55 metrics.py:455] Avg prompt throughput: 0.0 tokens/s, Avg generation throughput: 41.6 tokens/s, Running: 1 reqs, Swapped: 0 reqs, Pending: 0 reqs, GPU KV cache usage: 0.0%, CPU KV cache usage: 0.0%.
INFO 05-02 09:51:00 metrics.py:455] Avg prompt throughput: 0.0 tokens/s, Avg generation throughput: 41.6 tokens/s, Running: 1 reqs, Swapped: 0 reqs, Pending: 0 reqs, GPU KV cache usage: 0.1%, CPU KV cache usage: 0.0%.
INFO 05-02 09:51:05 metrics.py:455] Avg prompt throughput: 0.0 tokens/s, Avg generation throughput: 41.9 tokens/s, Running: 1 reqs, Swapped: 0 reqs, Pending: 0 reqs, GPU KV cache usage: 0.1%, CPU KV cache usage: 0.0%.
INFO 05-02 09:51:10 metrics.py:455] Avg prompt throughput: 0.0 tokens/s, Avg generation throughput: 41.9 tokens/s, Running: 1 reqs, Swapped: 0 reqs, Pending: 0 reqs, GPU KV cache usage: 0.1%, CPU KV cache usage: 0.0%.
INFO 05-02 09:51:15 metrics.py:455] Avg prompt throughput: 0.0 tokens/s, Avg generation throughput: 41.8 tokens/s, Running: 1 reqs, Swapped: 0 reqs, Pending: 0 reqs, GPU KV cache usage: 0.1%, CPU KV cache usage: 0.0%.
INFO 05-02 09:51:20 metrics.py:455] Avg prompt throughput: 0.0 tokens/s, Avg generation throughput: 41.9 tokens/s, Running: 1 reqs, Swapped: 0 reqs, Pending: 0 reqs, GPU KV cache usage: 0.2%, CPU KV cache usage: 0.0%.
INFO 05-02 09:51:25 metrics.py:455] Avg prompt throughput: 0.0 tokens/s, Avg generation throughput: 42.4 tokens/s, Running: 1 reqs, Swapped: 0 reqs, Pending: 0 reqs, GPU KV cache usage: 0.2%, CPU KV cache usage: 0.0%.
INFO 05-02 09:51:30 metrics.py:455] Avg prompt throughput: 0.0 tokens/s, Avg generation throughput: 43.0 tokens/s, Running: 1 reqs, Swapped: 0 reqs, Pending: 0 reqs, GPU KV cache usage: 0.2%, CPU KV cache usage: 0.0%.
INFO 05-02 09:51:35 metrics.py:455] Avg prompt throughput: 0.0 tokens/s, Avg generation throughput: 42.9 tokens/s, Running: 1 reqs, Swapped: 0 reqs, Pending: 0 reqs, GPU KV cache usage: 0.3%, CPU KV cache usage: 0.0%.
INFO: 10.90.1.5:35308 - "POST /v1/chat/completions HTTP/1.0" 200 OK
3. 混合思考讨论
Qwen3模型采用了混合式问题解决策略,支持两种工作模式:
深思模式:该模式下模型会逐步推理后给出最终答案,适合需要深度思考的复杂问题
迅捷模式:提供近乎即时的快速响应,适用于更注重速度而非深度的简单提问
用户能根据任务需求调控模型的"思考强度":难题可启用扩展推理,简单问题则可直接快速响应。关键突破在于,双模式的有机融合显著提升了模型的"思维预算"控制能力。Qwen3展现出与计算推理预算正相关的、平滑可扩展的性能提升曲线。
这里qwen团队其实在PR文章中,很容易把用户的理解带偏,以为是qwen3能够自动分析query的难度来实现动态识别,但其实是有一个开关,在chat template中进行选择,具体如下:
from modelscope import AutoModelForCausalLM, AutoTokenizermodel_name = "Qwen/Qwen3-30B-A3B"# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name,torch_dtype="auto",device_map="auto"
)# prepare the model input
prompt = "Give me a short introduction to large language model."
messages = [{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True,enable_thinking=True # Switch between thinking and non-thinking modes. Default is True.
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)# conduct text completion
generated_ids = model.generate(**model_inputs,max_new_tokens=32768
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist() # parsing thinking content
try:# rindex finding 151668 (</think>)index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:index = 0thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")print("thinking content:", thinking_content)
print("content:", content)其中 enable_thinking参数:
text = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True,enable_thinking=False # True is the default value for enable_thinking.
)我们来看下,当enable_thinking设置为False时,会产生什么作用,来看下tokenizer_config.json中的chat_template参数:
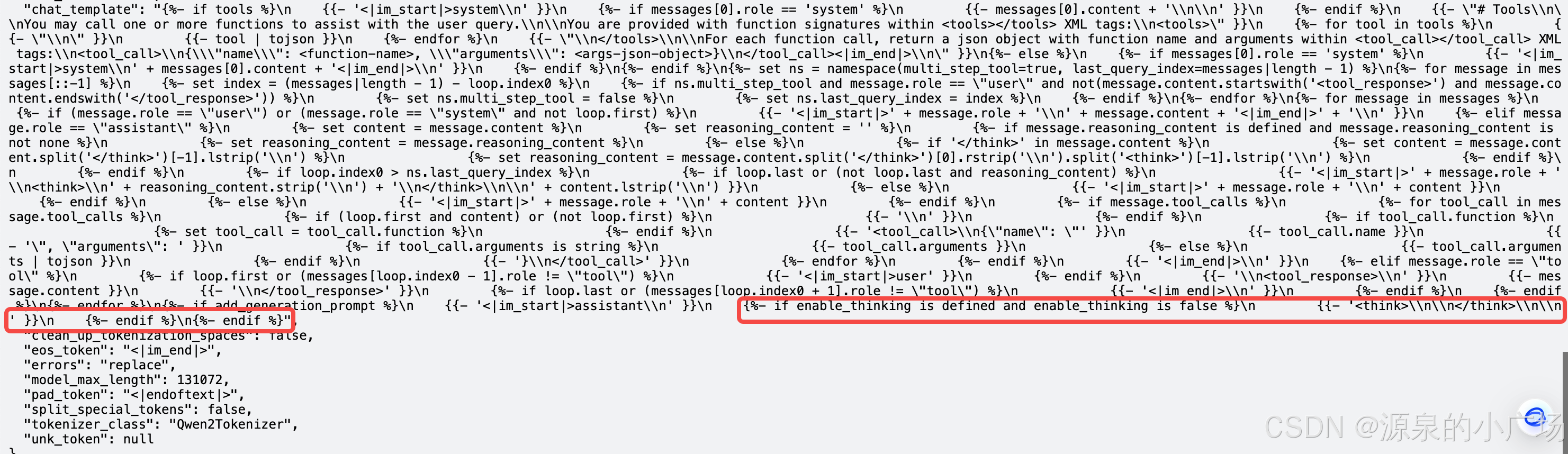
可以看到当enable_thinking设置为False,chat模版会自动设置<think>\n\n</think>使得Qwen3模型自动跳过思考。其实我们在QwQ32B的实测中,已经采用了这种方案,所以这种模式能力并不是Qwen3才具备的。只不过qwen团队放到了qwen3来做PR。
另外,这种操作,也并不是qwen团队的首创,前段时间伯克利发表的一篇论文《Reasoning Models Can Be Effective Without Thinking》中提及,不让大模型做深度思考,只是提及“我已经完成思考”,输出的效果就可以与深度思考匹敌。当然实际测试下来,thinking的可靠性肯定还是优于no thinking的,不过这篇文章带来了启发。 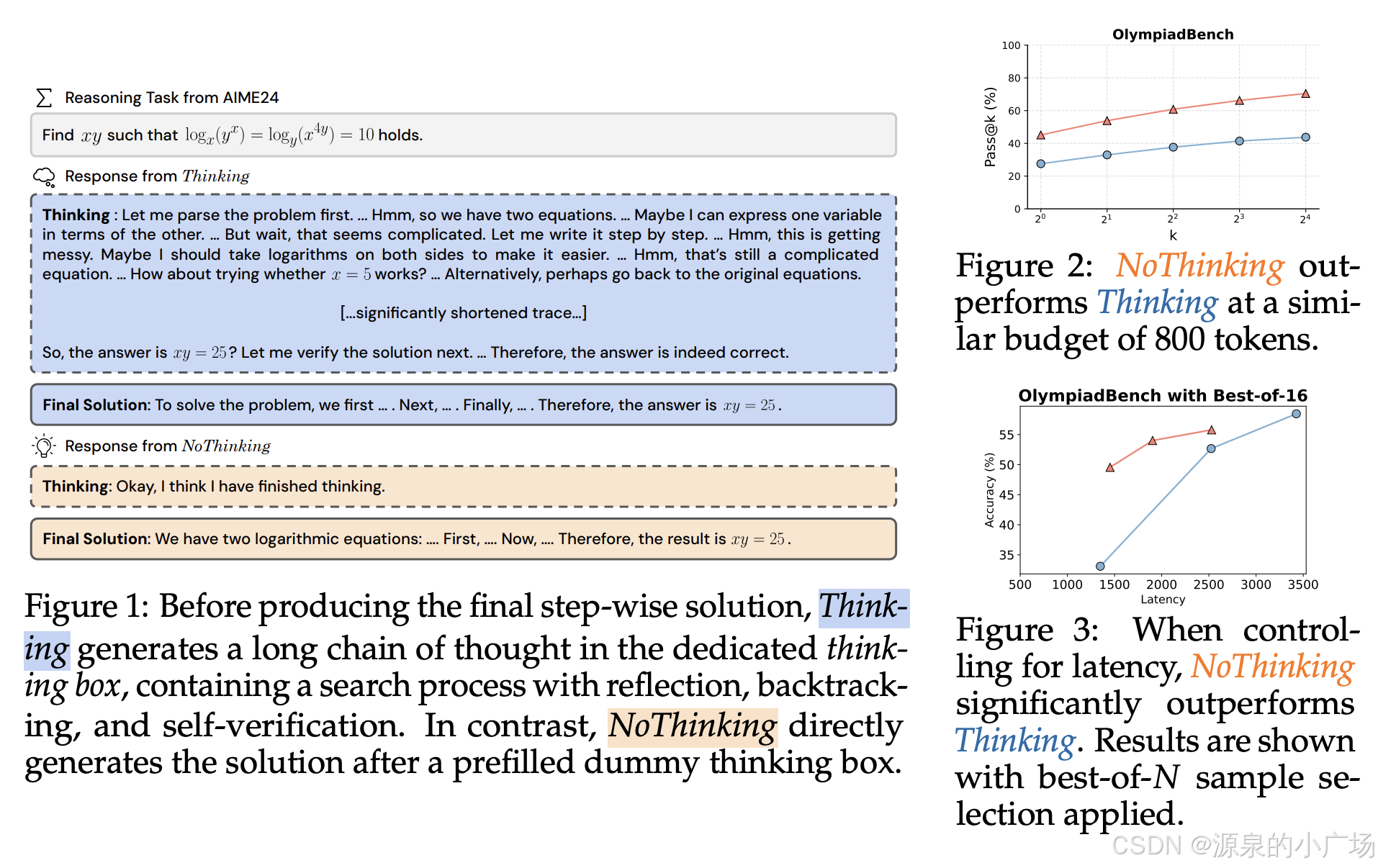 no thinking的设置方式:
no thinking的设置方式:
 示例代码:
示例代码:
chat_response = client.chat.completions.create(model="QwQ-32B-int8",messages=[{"role": "system", "content": "你是官方客服小深。"},{"role": "user", "content": "我想买一款防水耳机"}],temperature=0,top_p=0.8,max_tokens=2048,extra_body={"chat_template": """
{% for m in messages %}
<|im_start|>{{ m.role }}
{{ m.content }}<|im_end|>
{% endfor %}
{% if add_generation_prompt and messages[-1].role != 'assistant' %}
<|im_start|>assistant
<think>
Okay I have finished thinking.
</think>
{% endif %}
""","chat_template_kwargs": {"add_generation_prompt": True},"repetition_penalty": 1.05,},
)4. 参考材料
【1】Qwen3: Think Deeper, Act Faster | Qwen
【2】Reasoning Models Can Be Effective Without Thinking