有啦域名网站怎么做wordpress图片快速主题
常见的特征筛选算法
1. 方差筛选
- 原理 :方差衡量的是数据的离散程度。在特征筛选中,如果某个特征的方差很小,说明该特征在不同样本上的值差异不大,那么它对模型的区分能力可能很弱。方差筛选就是通过设定一个方差阈值,将方差小于该阈值的特征剔除。
- 优点 :计算简单,速度快,不需要依赖模型。
- 缺点 :只考虑了单个特征自身的方差,没有考虑特征与目标变量之间的关系,可能会误删一些有用的特征。
- 应用场景 :适用于快速初步筛选特征,减少数据维度。
2. 皮尔逊相关系数筛选
- 原理 :皮尔逊相关系数用于衡量两个变量之间的线性相关程度,取值范围在 -1 到 1 之间。在特征筛选中,通过计算每个特征与目标变量之间的皮尔逊相关系数,选择相关系数绝对值较大的特征,因为这些特征与目标变量的线性关系更紧密。
- 优点 :可以量化特征与目标变量之间的线性关系,简单易懂。
- 缺点 :只能检测线性关系,对于非线性关系的特征可能会失效。
- 应用场景 :适用于数据呈线性关系的场景。
3. Lasso 筛选
- 原理 :Lasso(Least Absolute Shrinkage and Selection Operator)是一种线性回归模型,在损失函数中加入了 L1 正则化项。L1 正则化会使得部分特征的系数变为 0,从而达到特征选择的目的。
- 优点 :可以同时进行特征选择和模型训练,能够处理高维数据。
- 缺点 :当特征之间存在高度相关性时,Lasso 可能只会选择其中一个特征,而忽略其他相关特征。
- 应用场景 :适用于高维数据和特征选择问题。
4. 树模型重要性
- 原理 :基于树的模型(如随机森林、梯度提升树等)在训练过程中可以计算每个特征的重要性。特征重要性通常根据特征在树的分裂过程中带来的信息增益或基尼系数的减少量来衡量。选择重要性较高的特征可以提高模型的性能。
- 优点 :能够处理非线性关系,不需要对数据进行预处理,并且可以自动考虑特征之间的交互作用。
- 缺点 :计算复杂度较高,不同的树模型可能会得到不同的特征重要性结果。
- 应用场景 :适用于各种类型的数据,特别是非线性数据。
5. SHAP 重要性
- 原理 :SHAP(SHapley Additive exPlanations)是一种用于解释机器学习模型预测结果的方法。SHAP 值衡量了每个特征对模型预测结果的贡献程度。通过计算每个特征的 SHAP 值的绝对值的均值,可以得到特征的重要性排序。
- 优点 :具有理论上的合理性,能够提供全局和局部的特征重要性解释,适用于各种类型的模型。
- 缺点 :计算复杂度较高,特别是对于大规模数据集和复杂模型。
- 应用场景 :适用于需要深入理解模型预测结果和特征重要性的场景。
6. 递归特征消除(RFE)
- 原理 :递归特征消除是一种迭代的特征选择方法。首先使用全部特征训练一个模型,然后根据模型的系数或特征重要性,剔除最不重要的特征。接着在剩余的特征上重新训练模型,重复这个过程,直到达到预设的特征数量。
- 优点 :可以利用模型的信息进行特征选择,能够找到最优的特征子集。
- 缺点 :计算复杂度较高,需要多次训练模型。
- 应用场景 :适用于对模型性能要求较高,并且有足够计算资源的场景。
下面是根据心脏病数据集来检测一下这几种特征筛选算法。
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression, Lasso
from sklearn.feature_selection import VarianceThreshold, SelectKBest, f_classif, RFE
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
import shap
import matplotlib.pyplot as plt# 加载数据
data = pd.read_csv('./csv/heart.csv')
X = data.drop('target', axis=1)
y = data['target']# 数据划分与标准化
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)# 定义逻辑回归模型
model = LogisticRegression(random_state=42)# 原始数据模型精度
model.fit(X_train_scaled, y_train)
y_pred = model.predict(X_test_scaled)
original_accuracy = accuracy_score(y_test, y_pred)
print(f"原始数据模型精度: {original_accuracy}")# 1. 方差筛选
selector_var = VarianceThreshold(threshold=0.1)
X_train_var = selector_var.fit_transform(X_train_scaled)
X_test_var = selector_var.transform(X_test_scaled)
model.fit(X_train_var, y_train)
y_pred_var = model.predict(X_test_var)
var_accuracy = accuracy_score(y_test, y_pred_var)
print(f"方差筛选后模型精度: {var_accuracy}")# 2. 皮尔逊相关系数筛选
selector_corr = SelectKBest(score_func=f_classif, k=5)
X_train_corr = selector_corr.fit_transform(X_train_scaled, y_train)
X_test_corr = selector_corr.transform(X_test_scaled)
model.fit(X_train_corr, y_train)
y_pred_corr = model.predict(X_test_corr)
corr_accuracy = accuracy_score(y_test, y_pred_corr)
print(f"皮尔逊相关系数筛选后模型精度: {corr_accuracy}")# 3. Lasso 筛选
lasso = Lasso(alpha=0.01)
lasso.fit(X_train_scaled, y_train)
non_zero_indices = np.where(lasso.coef_ != 0)[0]
X_train_lasso = X_train_scaled[:, non_zero_indices]
X_test_lasso = X_test_scaled[:, non_zero_indices]
model.fit(X_train_lasso, y_train)
y_pred_lasso = model.predict(X_test_lasso)
lasso_accuracy = accuracy_score(y_test, y_pred_lasso)
print(f"Lasso 筛选后模型精度: {lasso_accuracy}")# 4. 树模型重要性筛选
rf = RandomForestClassifier(random_state=42)
rf.fit(X_train_scaled, y_train)
importances = rf.feature_importances_
indices = np.argsort(importances)[::-1]
top_features = indices[:5]
X_train_tree = X_train_scaled[:, top_features]
X_test_tree = X_test_scaled[:, top_features]
model.fit(X_train_tree, y_train)
y_pred_tree = model.predict(X_test_tree)
tree_accuracy = accuracy_score(y_test, y_pred_tree)
print(f"树模型重要性筛选后模型精度: {tree_accuracy}")# 5. SHAP 重要性筛选
explainer = shap.Explainer(rf)
shap_values = explainer(X_train_scaled)
shap_importance = np.abs(shap_values.values).mean(0)
shap_indices = np.argsort(shap_importance)[::-1]
shap_top_features = shap_indices[:5]
X_train_shap = X_train_scaled[:, shap_top_features]
X_test_shap = X_test_scaled[:, shap_top_features]
model.fit(X_train_shap, y_train)
y_pred_shap = model.predict(X_test_shap)
shap_accuracy = accuracy_score(y_test, y_pred_shap)
print(f"SHAP 重要性筛选后模型精度: {shap_accuracy}")# 6. 递归特征消除(RFE)
rfe = RFE(estimator=model, n_features_to_select=5)
X_train_rfe = rfe.fit_transform(X_train_scaled, y_train)
X_test_rfe = rfe.transform(X_test_scaled)
model.fit(X_train_rfe, y_train)
y_pred_rfe = model.predict(X_test_rfe)
rfe_accuracy = accuracy_score(y_test, y_pred_rfe)
print(f"递归特征消除(RFE)筛选后模型精度: {rfe_accuracy}")# 可视化结果
methods = ['Original', 'Variance', 'Correlation', 'Lasso', 'Tree', 'SHAP', 'RFE']
accuracies = [original_accuracy, var_accuracy, corr_accuracy, lasso_accuracy, tree_accuracy, shap_accuracy, rfe_accuracy]plt.bar(methods, accuracies)
plt.xlabel('Feature Selection Methods')
plt.ylabel('Accuracy')
plt.title('Comparison of Model Accuracies after Feature Selection')
plt.xticks(rotation=45)
plt.show()
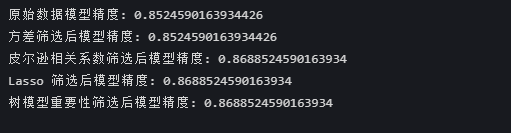
总结
可以看到其实这几种算法精度都差不多,后三者的特征筛选后精度略高一点。