字体设计网站大全网站建设关键的问题是

自动求导机制
本章节介绍 PyTorch 的自动求导机制,包括计算图、反向传播和梯度计算的原理及实现。
1. 计算图原理
计算图是深度学习框架中的一个核心概念,它描述了计算过程中各个操作之间的依赖关系。
计算图由节点(节点)和边(边)组成,节点表示操作(如加减乘除),边表示数据的流动。
1.1 动态计算图
PyTorch使用动态计算图,其特点:
- 即时构建:随着代码执行动态创建
- 自动微分:基于链式法则自动计算梯度
- 节点组成:
- 叶子节点:用户创建的张量(
requires_grad=True) - 中间节点:操作结果张量
- 边:张量间的依赖关系
- 叶子节点:用户创建的张量(
import torch# 创建叶子节点(数学符号:x, y ∈ ℝ)
x = torch.tensor(2.0, requires_grad=True) # dx/dx = 1
y = torch.tensor(3.0, requires_grad=True) # dy/dy = 1# 构建计算图(数学表达式:z = x·y, w = z + x)
z = x * y # 中间节点 z = 6.0
w = z + x # 中间节点 w = 8.0print("计算图节点元数据:")
print(f"w.grad_fn: {w.grad_fn}") # AddBackward
print(f"z.grad_fn: {z.grad_fn}") # MulBackward
print(f"x.is_leaf: {x.is_leaf}") # True
1.2 计算图可视化
使用torchviz生成计算图(需先安装):
pip install torchviz graphviz
from torchviz import make_dot# 可视化前向传播计算图
make_dot(w, params={'x': x, 'y': y}).render("compute_graph", format="png")
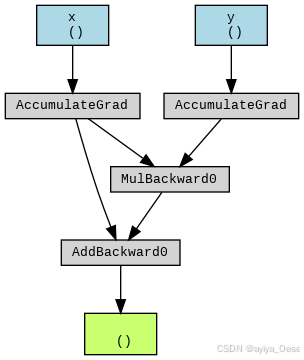
说明:图中展示了从叶子节点 x, y 到最终输出 w 的计算路径
2. 反向传播数学原理
2.1 链式法则
对于计算图输出 L L L ,其关于输入变量 x x x 的梯度计算遵循链式法则:
∂ L ∂ x = ∑ p ∈ paths ∏ ( i , j ) ∈ p ∂ j ∂ i \frac{\partial L}{\partial x} = \sum_{p \in \text{paths}} \prod_{(i,j) \in p} \frac{\partial j}{\partial i} ∂x∂L=p∈paths∑(i,j)∈p∏∂i∂j
示例计算:
给定计算流程:
z = x 2 y = z 3 L = ln ( y ) \begin{aligned} z &= x^2 \\ y &= z^3 \\ L &= \ln(y) \end{aligned} zyL=x2=z3=ln(y)
梯度计算:
∂ L ∂ x = 1 y ⋅ 3 z 2 ⋅ 2 x = 6 x 5 x 6 = 6 x \frac{\partial L}{\partial x} = \frac{1}{y} \cdot 3z^2 \cdot 2x = \frac{6x^5}{x^6} = \frac{6}{x} ∂x∂L=y1⋅3z2⋅2x=x66x5=x6
x = torch.tensor(2.0, requires_grad=True)
z = x**2 # z=4.0
y = z**3 # y=64.0
L = torch.log(y) # L=4.1589L.backward()
print(f"理论值 6/x: {6/x.item():.3f}")
print(f"实际梯度: {x.grad.item():.3f}") # 6/2=3.0
2.2 多变量反向传播
对于多变量系统,PyTorch自动计算雅可比矩阵的乘积:
# 创建多变量计算图
x = torch.tensor([1., 2.], requires_grad=True)
y = torch.tensor([3., 4.], requires_grad=True)
z = x**2 + y**3 # z = [1+27=28, 4+64=68]# 反向传播需指定梯度权重(假设L = sum(z))
z.sum().backward() print(f"x.grad: {x.grad}") # [2*1=2, 2*2=4]
print(f"y.grad: {y.grad}") # [3*3²=27, 3*4²=48]
3. 梯度管理
3.1 梯度累积与清零
PyTorch梯度会累积在.grad属性中,训练时需手动清零:
w = torch.randn(3, requires_grad=True)for _ in range(3):y = w.sum() # 前向传播y.backward() # 反向传播print(f"当前梯度: {w.grad}")w.grad.zero_() # 梯度清零print(f"清零后的梯度: {w.grad}")
3.2 梯度控制方法
| 方法 | 作用 | 使用场景 |
|---|---|---|
torch.no_grad() | 禁用梯度计算 | 模型推理、参数更新 |
detach() | 创建无梯度关联的新张量 | 冻结部分网络 |
retain_graph=True | 保留计算图以供多次反向传播 | 复杂梯度计算 |
# 对比不同控制方法
x = torch.tensor(2.0, requires_grad=True)with torch.no_grad(): # 上下文内不追踪梯度y = x * 3 # y.requires_grad = Falsez = x.detach() # 创建与x值相同但无梯度的张量
z.requires_grad = True # 可重新启用梯度追踪
4. 实际应用
4.1 自定义自动微分
实现简单函数的自定义梯度计算:
class MyReLU(torch.autograd.Function):@staticmethoddef forward(ctx, input):ctx.save_for_backward(input)return input.clamp(min=0)@staticmethoddef backward(ctx, grad_output):input, = ctx.saved_tensorsgrad_input = grad_output.clone()grad_input[input < 0] = 0 # ReLU的导数为分段函数return grad_input# 使用自定义函数
x = torch.randn(4, requires_grad=True)
y = MyReLU.apply(x)
y.sum().backward()
print(f"输入梯度:\n{x.grad}")
4.2 梯度裁剪实践
防止梯度爆炸的两种方法:
# 方法1:按值裁剪
utils.clip_grad_value_(model.parameters(), clip_value=0.5)# 方法2:按范数裁剪
utils.clip_grad_norm_(model.parameters(), max_norm=1.0)# 梯度监控
total_norm = 0
for p in model.parameters():param_norm = p.grad.data.norm(2)total_norm += param_norm.item() ** 2
total_norm = total_norm ** 0.5
print(f"梯度范数: {total_norm:.2f}")
5. 神经网络训练最佳实践
5.1 标准训练流程
model = nn.Sequential(nn.Linear(2, 4),nn.ReLU(),nn.Linear(4, 1),nn.Sigmoid()
)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)for epoch in range(100):# 训练模式model.train() optimizer.zero_grad()outputs = model(X_train)loss = F.binary_cross_entropy(outputs, y_train)loss.backward()# 梯度裁剪torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)optimizer.step()# 评估模式model.eval()with torch.no_grad():val_loss = F.binary_cross_entropy(model(X_val), y_val)
5.2 梯度检查技巧
# 检查梯度是否存在
for name, param in model.named_parameters():if param.grad is None:print(f"警告: 参数 {name} 无梯度!")# 可视化梯度分布
import matplotlib.pyplot as plt
gradients = [p.grad.abs().mean() for p in model.parameters()]
plt.bar(range(len(gradients)), gradients)
plt.title("Average Gradient Magnitude")
plt.show()
通过深入理解计算图原理、链式法则、梯度管理和实际应用,我们可以更好地利用 PyTorch 的自动求导机制来构建和训练神经网络模型。