服务网站建设企业前端 wordpress
一、项目背景
在互联网时代,流量数据是反映用户行为和业务状况的重要指标。通过对流量数据进行准确统计和分析,企业可以了解用户的访问习惯、业务的热门程度等,从而为决策提供有力支持。然而,原始的流量数据往往存在格式不规范、缺失值、异常值等问题,这就需要进行数据清洗工作。本文将介绍如何使用Spark进行流量统计项目中的数据清洗工作。
二、数据来源与数据样例
流量数据通常来源于服务器的日志文件,这些日志记录了用户的每一次访问请求,包括访问时间、用户IP、请求的页面、产生的流量大小等信息。 ### 数据样例 假设我们拿到的原始流量数据格式如下
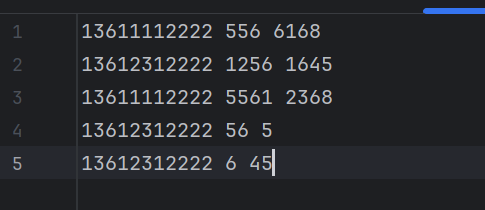
但实际数据中可能存在格式错误,比如时间格式不对,或者流量值为负数等异常情况。
三、项目完成思路
(一)数据读取
使用Spark的 `SparkSession` 来读取数据。
(二)数据清洗
1. **字段拆分** 原始数据是一行文本,需要将其拆分成对应的字段。可以使用 `split()` 函数来实现。这里将每一行数据按逗号拆分成不同字段,并为每个字段取别名,同时将流量大小字段转换为数值类型。
2. **处理缺失值** 检查数据中是否存在缺失值,并根据情况进行处理。可以使用 `drop()` 方法删除包含缺失值的行,或者使用 `fill()` 方法进行填充。
3. **处理异常值** 对于流量统计,比如流量大小不能为负数,可以过滤掉异常数据。同时,对于时间格式错误等情况,也可以通过正则表达式等方式进行校验和处理。
(三)流量统计
经过清洗后的数据,就可以进行流量统计相关操作了。
(四)结果输出
将统计结果输出到文件或者展示在控制台。如果要输出到文件
四、代码
设置依赖:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>org.example</groupId><artifactId>Flow</artifactId><version>1.0-SNAPSHOT</version><properties><maven.compiler.source>8</maven.compiler.source><maven.compiler.target>8</maven.compiler.target><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding></properties><!-- 添加hadoop-client 3.1.0的依赖 --><dependencies><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>3.1.0</version></dependency></dependencies></project>FlowBean
package com.example.flow;import org.apache.hadoop.io.Writable;import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;// hadoop序列化
// 三个属性:手机号,上行流量,下行流量
public class FlowBean implements Writable {private String phone;private Long upFlow;private Long downFlow;public FlowBean(String phone, Long upFlow, Long downFlow) {this.phone = phone;this.upFlow = upFlow;this.downFlow = downFlow;}// 定义get/set方法public String getPhone() {return phone;}public void setPhone(String phone) {this.phone = phone;}public Long getUpFlow() {return upFlow;}public void setUpFlow(Long upFlow) {this.upFlow = upFlow;}public Long getDownFlow() {return downFlow;}public void setDownFlow(Long downFlow) {this.downFlow = downFlow;}// 定义无参构造public FlowBean() {}// 定义一个获取总流量的方法public Long getTotalFlow() {return upFlow + downFlow;}@Overridepublic void write(DataOutput dataOutput) throws IOException {dataOutput.writeUTF(phone);dataOutput.writeLong(upFlow);dataOutput.writeLong(downFlow);}@Overridepublic void readFields(DataInput dataInput) throws IOException {phone = dataInput.readUTF();upFlow = dataInput.readLong();downFlow = dataInput.readLong();}
}FlowMapper
package com.example.flow;import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;// 1.继承Mapper
// 2.重写map函数
public class FlowMapper extends Mapper<LongWritable, Text, Text, FlowBean> {@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {// 1.获取一行数据,使用空格拆分// 手机号就是第一个元素// 上行留了就是第二个元素// 下行留了就是第三个元素String[] split = value.toString().split(" ");System.out.printf("%s\t%s\t%s\n", split[0], split[1], split[2]);String phone = split[0];Long upFlow = Long.parseLong(split[1]);Long downFlow = Long.parseLong(split[2]);// 2.封装对象FlowBean flowBean = new FlowBean(phone, upFlow, downFlow);// 3.写入 手机号为key,值就是这个对象context.write(new Text(phone), flowBean);}
}FlowReducer
package com.example.flow;import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;// 1.继承Reducer
// 2.重写reduce方法
public class FlowReducer extends Reducer<Text, FlowBean, Text, Text> {@Overrideprotected void reduce(Text key, Iterable<FlowBean> values, Context context) throws IOException, InterruptedException {//1. 遍历集合,取出每一个元素,计算上行流量和下行流量的汇总long upFlowSum = 0L;long downFlowSum = 0L;for (FlowBean flowBean : values) {upFlowSum += flowBean.getUpFlow();downFlowSum += flowBean.getDownFlow();}// 2. 计算总的汇总long sumFlow = upFlowSum + downFlowSum;String flowDesc = String.format("总的上行流量是:%d,总下行流量是:%d,总流量是:%d", upFlowSum, downFlowSum, sumFlow);context.write(key, new Text(flowDesc));}
}FlowDriver
package com.example.flow;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;// 提交job的类,一共做七件事
public class FlowDriver {public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {// 1. 获取配置,得到job对象Configuration conf = new Configuration();Job job = Job.getInstance(conf);// 2. 设置jar包路径job.setJarByClass(FlowDriver.class);//3.关联Mapper和Reducer的输出类型job.setMapperClass(FlowMapper.class);job.setReducerClass(FlowReducer.class);// 4. 设置Mapper和Reducer的输出类型job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(FlowBean.class);// 5. 设置reducer输出类型job.setOutputKeyClass(Text.class);job.setOutputValueClass(Text.class);// 6. 设置输入和输出路径FileInputFormat.setInputPaths(job, new Path("data"));FileOutputFormat.setOutputPath(job, new Path("output"));// 7.提交job,根据返回值设置程序退出codeboolean result = job.waitForCompletion(true);System.exit(result ? 0 : 1);}
}
五、总结
通过使用Spark进行数据清洗和流量统计,我们能够从原始的、杂乱的流量数据中提取出有价值的信息。在实际项目中,数据清洗的规则和方法可能会因数据的具体情况而有所不同,需要根据实际场景灵活调整。同时,Spark强大的分布式计算能力使得处理大规模流量数据变得高效可行,为后续的数据分析和挖掘工作奠定了良好的基础。希望本文能对大家在Spark数据清洗和流量统计项目上有所帮助。 以上博客内容供你参考,你可以根据实际项目细节和需求对代码示例、描述等进行进一步调整和完善。