上海知名装修公司排行贵州网站seo
Double DQN 模型详解
背景
-
Q-learning 的局限性:
传统 Q-learning 在计算目标 Q 值时使用贪婪策略(max操作),导致对真实 Q 值的系统性高估(过估计 overestimation)。这种高估源于环境随机性、函数近似误差或噪声,通过max操作被放大,进而影响策略稳定性。 -
DQN 的改进与遗留问题:
DQN(Deep Q-Network)通过经验回放(缓解数据相关性)和目标网络(固定参数,稳定训练)解决了高维状态空间下的 Q-learning 问题。然而,DQN 仍沿用传统 Q-learning 的目标值计算方式,未解决过估计问题。 -
Double Q-learning 的启发:
Hado van Hasselt 在 2010 年提出 Double Q-learning,通过解耦动作选择与价值评估,使用两个独立的 Q 函数交替更新,减少过估计。Double DQN 将这一思想与 DQN 结合,形成了更鲁棒的算法。
原理
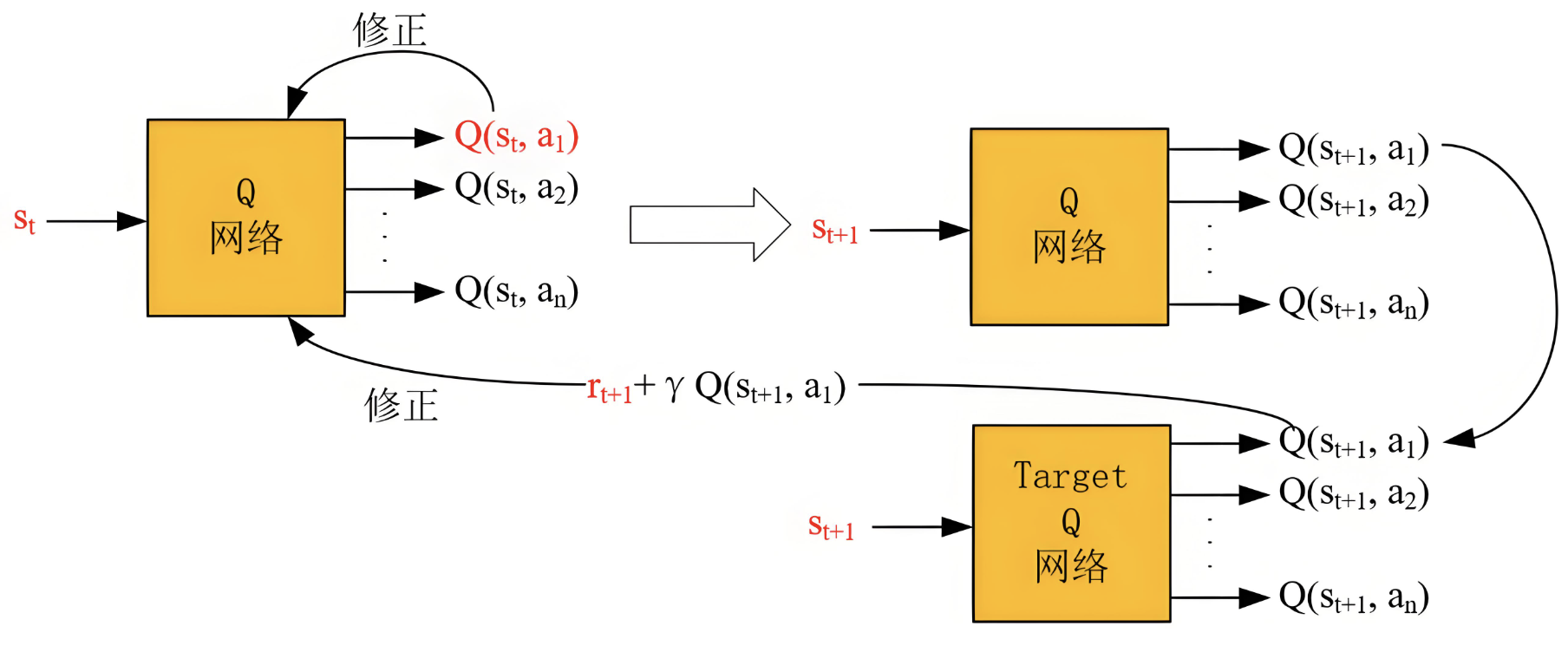
- 目标 Q 值的计算方式
-
传统 DQN:
Y DQN = r + γ ⋅ max a ′ Q target ( s ′ , a ′ ) Y^{\text{DQN}} = r + \gamma \cdot \max_{a'} Q_{\text{target}}(s', a') YDQN=r+γ⋅a′maxQtarget(s′,a′)
使用目标网络直接选择并评估动作,导致同一网络参数同时影响选择和评估,加剧过估计。 -
Double DQN:
Y DoubleDQN = r + γ ⋅ Q target ( s ′ , arg max a ′ Q current ( s ′ , a ′ ) ) Y^{\text{DoubleDQN}} = r + \gamma \cdot Q_{\text{target}}\left(s', \arg\max_{a'} Q_{\text{current}}(s', a')\right) YDoubleDQN=r+γ⋅Qtarget(s′,arga′maxQcurrent(s′,a′))- 动作选择:由当前网络 Q current Q_{\text{current}} Qcurrent 决定最优动作 a ′ a' a′(即 arg max \arg\max argmax)。
- 价值评估:目标网络 Q target Q_{\text{target}} Qtarget 计算所选动作 a ′ a' a′ 的 Q 值。
- 核心思想:分离选择与评估,避免单一网络的偏差被放大。
- 网络结构与训练流程
- 沿用 DQN 的双网络结构(当前网络 + 目标网络),无需新增网络。
- 经验回放:存储转移样本 ( s , a , r , s ′ ) (s, a, r, s') (s,a,r,s′),随机采样以打破相关性。
- 目标网络更新:定期将当前网络参数复制到目标网络(软更新或硬更新)。
- 损失函数:均方误差(MSE)损失,优化当前网络:
L = E [ ( Y DoubleDQN − Q current ( s , a ) ) 2 ] \mathcal{L} = \mathbb{E}\left[\left(Y^{\text{DoubleDQN}} - Q_{\text{current}}(s, a)\right)^2\right] L=E[(YDoubleDQN−Qcurrent(s,a))2]
优势
-
减少过估计:
通过解耦动作选择与评估,显著降低 Q 值的高估程度,实验证明在 Atari 等环境中平均 Q 值更接近真实值。 -
提升策略稳定性:
过估计的减少使得策略更新更可靠,尤其在动作空间复杂或奖励稀疏的任务中表现更优。 -
实现成本低:
仅需修改目标值计算方式,无需增加网络参数或显著改变训练流程,易于与 DQN 的其他改进(如 Prioritized Experience Replay)结合。 -
实验性能优越:
在 Atari 2600 基准测试中,Double DQN 在多数游戏上超越 DQN,尤其在《Seaquest》《Space Invaders》等复杂环境中得分提升显著。
劣势
-
未完全消除过估计:
虽然缓解了问题,但目标网络仍可能存在低估或高估,尤其在训练初期网络未收敛时。 -
依赖当前网络的选择质量:
若当前网络 Q current Q_{\text{current}} Qcurrent 对动作的选择不准确(如探索不足),目标网络评估的 Q 值可能偏离真实值。 -
不解决所有偏差问题:
环境随机性、函数近似误差等仍可能导致其他形式的估计偏差,需结合其他技术(如 Dueling 架构)进一步优化。
总结
Double DQN 是 DQN 的重要改进,通过解耦动作选择与价值评估,在几乎不增加计算开销的前提下有效缓解过估计问题,提升了算法的稳定性和最终性能。尽管存在局限性,但其简洁高效的实现使其成为深度强化学习中的基础组件,常与其他技术(如 Prioritized Replay、Dueling DQN)结合,形成更强大的算法(如 Rainbow DQN)。
参考文献:
- Van Hasselt, H., Guez, A., & Silver, D. (2016). Deep Reinforcement Learning with Double Q-learning. AAAI.
- Mnih, V., et al. (2015). Human-level control through deep reinforcement learning. Nature.