电商购物网站模板下载广州网站建设吧
对其他的层有了一些了解
代码实现了Linear layer
Normalization Layers 正则化层
📌 什么是 Normalization Layers?
Normalization Layers 是一种 正则化手段,用于 加速神经网络训练、提高模型稳定性。它们的核心作用是——
👉 把输入特征分布“标准化”,让不同批次的数据分布更一致,训练更高效,收敛更快。
常见的归一化层包括:
| 名称 | 应用场景 | 特点 |
|---|---|---|
| BatchNorm | 图像分类、CNN | 对每个 batch 的特征维度做归一化 |
| LayerNorm | NLP、Transformer | 对单个样本的全部特征归一化 |
| InstanceNorm | 风格迁移 | 对每个样本、每个通道单独归一化 |
| GroupNorm | 小批量训练 | 按组归一化,解决小 batch 不稳定问题 |
| RMSNorm | Transformer 改进版 | 只标准化均方根值,不用均值 |
| WeightNorm | 特殊情况 | 对权重进行归一化,而不是特征 |
🎁 它们有啥用?
| ✅ 作用 | 💡 解释 |
|---|---|
| 加速收敛 | 减少特征分布的漂移(Internal Covariate Shift),模型训练更快 |
| 防止梯度爆炸/消失 | 保证特征分布稳定,梯度不容易失控 |
| 提高泛化能力 | 起到轻微正则化作用,减少过拟合风险 |
| 减少超参数敏感性 | 对学习率、初始化不那么敏感,训练更稳定 |
🎨 举个经典例子:BatchNorm 原理
公式:
:当前 batch 的均值和方差
:可训练的缩放和平移参数
:防止除零的小值
💡 简化理解:
标准化 → 分布变“正常”
拉伸平移 → 不限制模型能力
🎯 总结
什么时候用?
CNN、Transformer、RNN、GAN 都有用;
batch size 小就选 LayerNorm 或 GroupNorm;
想快点收敛,首选 BatchNorm。
本质作用?
加速训练 + 提升稳定性 + 抗过拟合。
recurrent layers 循环层
🧠 什么是 Recurrent Layers?
Recurrent Layers 是一种 循环神经网络(RNN) 的核心组件,专门用来处理有 时间关系 或 序列特征 的数据。
普通的全连接(Linear)或者卷积(Conv)层是 一次性吃掉所有输入;
循环层不一样,它是一口一口慢慢吃,有“记忆”,能把之前的信息记下来,影响后面的输出。
🔥 常见 Recurrent Layers 一览
| 名称 | 简单理解 | 特点 |
|---|---|---|
| RNN | 最基础的循环层 | 容易梯度爆炸/消失 |
| LSTM | 加了“记忆门控”的RNN | 能长期记忆,效果更稳 |
| GRU | 精简版 LSTM | 参数更少,速度更快 |
| BiRNN / BiLSTM | 双向RNN | 结合前后信息 |
| Attention(不严格属于RNN) | 可看做升级版 | 现在流行,逐渐替代传统RNN |
🏷️ 工作流程(以 LSTM 为例)
假设一个序列 [x1,x2,...,xT][x_1, x_2, ..., x_T][x1,x2,...,xT]:
每个时间步:
Input x_t + Hidden state h_{t-1} => 计算门控 => 输出 h_t, c_t
h_t:隐藏状态(短期记忆)
c_t:单元状态(长期记忆)
门控机制(输入门、遗忘门、输出门)动态决定信息“记住 or 忘记”。
🎁 Recurrent Layers 有啥用?
| ✅ 作用 | 💡 说明 |
|---|---|
| 处理序列数据 | 时间、文本、音频等按顺序分析 |
| 有“记忆”能力 | 能记住前面发生的事情 |
| 捕捉长期依赖 | 特别是 LSTM/GRU |
| 文本生成/翻译 | Seq2Seq、Chatbot 等常见应用 |
| 时间序列预测 | 股票预测、温度预测等 |
📌 PyTorch 示例:
import torch from torch
import nn
rnn = nn.LSTM(input_size=10, hidden_size=20, num_layers=2, batch_first=True) input = torch.randn(32, 5, 10) # batch_size=32, sequence_length=5, input_size=10 output, (h_n, c_n) = rnn(input)
print(output.shape) # (32, 5, 20)
解释:
batch_size=32:一次性处理32个样本
sequence_length=5:每个样本有5个时间步
input_size=10:每个时间步特征维度是10
hidden_size=20:隐藏层大小20
🎯 一句话总结:
Recurrent Layers 是序列大师,LSTM/GRU是实用级选手;长记忆短记忆一个不落,现在深度学习搞序列,基本离不开它们。📈
Transformer Layers
🚀 什么是 Transformer Layers?
Transformer 层 = 不用循环、不用卷积,全靠 Attention 搞定序列建模的架构。
最早是 2017 年《Attention is All You Need》 提出的,直接颠覆了传统 RNN/LSTM 的处理方式,成为 BERT、GPT、ViT、ChatGPT 背后的核心组件。
🏷️ Transformer 层的经典组成
每个 Transformer Layer 其实是:
输入 Embedding →
[LayerNorm + Multi-Head Attention + Residual] →
[LayerNorm + Feed Forward Network + Residual] →
输出
分模块拆开看:
| 模块 | 功能 | 用途 |
|---|---|---|
| Multi-Head Self-Attention | 看“全局信息” | 比 RNN 更强,能直接看到序列任意位置 |
| Feed Forward Network (FFN) | 非线性映射 | 提高表达能力 |
| Layer Normalization | 稳定训练 | 不容易梯度爆炸/消失 |
| Residual Connection | 残差连接 | 防止深层网络退化 |
| Position Encoding | 位置感知 | 因为没有循环,靠加 Positional Embedding 懂顺序 |
🎁 Transformer 的核心优势
| ✅ 优势 | 📌 解释 |
|---|---|
| 并行计算 | 不像 RNN 一步步算,Transformer 一次吞下整段序列 |
| 远程依赖捕捉 | Attention 能看全局关系,不怕长依赖问题 |
| 训练效率高 | GPU/TPU 很吃这一套,训练速度爆炸快 |
| 泛化性强 | NLP → CV → Audio → 多模态全能打 |
🎨 Transformer Layer 结构图(文字版)
输入 → 加位置编码 →
↓
[MHA] → Add & Norm →
[FFN] → Add & Norm →
输出
MHA:Multi-Head Attention
FFN:Feed Forward Network
Add & Norm:残差连接 + LayerNorm
🧱 PyTorch Transformer 层示例
import torch
from torch import nn
# 单个 Transformer 层
transformer_layer = nn.TransformerEncoderLayer(
d_model=512,
nhead=8,
dim_feedforward=2048
)
x = torch.randn(10, 32, 512) # [sequence_length, batch_size, embedding_dim] output = transformer_layer(x)
print(output.shape) # torch.Size([10, 32, 512])
💡 d_model=512:输入特征维度
💡 nhead=8:多头注意力头数
💡 dim_feedforward=2048:前馈层宽度
🎯 Transformer Layer 怎么用:
| 场景 | 用法 |
|---|---|
| NLP | 文本分类、机器翻译、对话生成(BERT、GPT、ChatGPT) |
| CV | 图像分类(ViT)、目标检测(DETR) |
| 音频 | 语音识别、音频分类 |
| 多模态 | 文本-图片理解(CLIP)、视频理解 |
🌟 总结:
Transformer Layers = Attention 驱动的超级表达模型,能理解 全局依赖关系,并且训练速度快,效果炸裂。现代深度学习主力选手。
Linear Layer(线性层,全连接层)
🧱 什么是 Linear Layer?
简单来说:
也叫 全连接层(Fully Connected Layer, FC Layer):
把输入特征乘一个 权重矩阵 W,加上一个 偏置 b,得到输出。
它的本质:
线性变换,把一个维度的特征“映射”到另一个维度。
📌 PyTorch 实际代码:
import torch
from torch import nn
linear = nn.Linear(in_features=10, out_features=5) # 输入10维,输出5维
x = torch.randn(3, 10) # batch_size=3,特征10维 output = linear(x) print(output.shape) # [3, 5]
💡 解释:
输入 shape = (3, 10)
输出 shape = (3, 5)
linear.weight.shape = (5, 10),linear.bias.shape = (5,)
🎁 Linear Layer 有啥用?
| ✅ 作用 | 💡 说明 |
|---|---|
| 特征投影 | 把高维特征降维,或者低维升维 |
| 分类决策层 | 最后一层通常是 Linear 层接 Softmax |
| 输入特征融合 | 融合不同特征的加权信息 |
| Transformer FFN 核心 | Transformer 里 FeedForward 全靠它 |
| 万能适配层 | 任意维度变换,随用随调 |
🎨 常见场景
| 场景 | 使用方式 |
|---|---|
| 图像分类 | Conv → Flatten → Linear → 输出分类 |
| Transformer | MHA → Linear → 输出维度不变 |
| 强化学习 | 状态 → Linear → 动作概率或值函数 |
| 回归任务 | Linear → 直接输出连续值 |
🔥 一句话总结
Linear Layer = 最简单、最高频率使用的“特征映射”工具,深度学习的打工人,不起眼但必不可少。
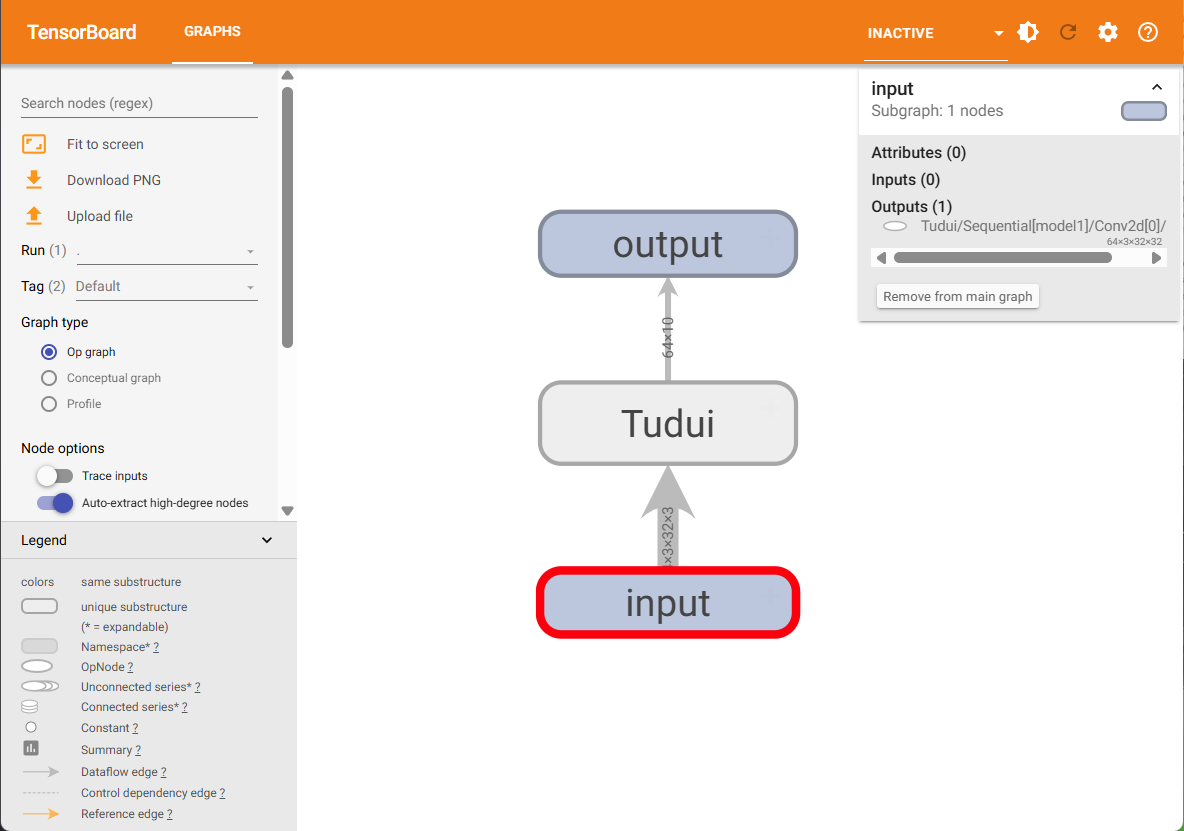
nn.Sequential 相当于一个容器,这样更方便阅读
import torch
from torch import nn
from torch.nn import Conv2d
from torch.utils.tensorboard import SummaryWriterclass Tudui(nn.Module):def __init__(self):super().__init__()self.conv1 = nn.Conv2d(in_channels=3, out_channels=32, kernel_size=5, padding=2)self.maxpool1 = nn.MaxPool2d(kernel_size=2)self.conv2 = nn.Conv2d(in_channels=32, out_channels=32, kernel_size=5, padding=2)self.maxpool2 = nn.MaxPool2d(kernel_size=2)self.conv3 = nn.Conv2d(in_channels=32, out_channels=64, kernel_size=5, padding=2)self.maxpool3 = nn.MaxPool2d(kernel_size=2)self.flatten = nn.Flatten()self.linear1 = nn.Linear(in_features=1024, out_features=64)self.linear2 = nn.Linear(in_features=64, out_features=10)self.model1 = nn.Sequential(Conv2d(in_channels=3, out_channels=32, kernel_size=5, padding=2),nn.MaxPool2d(kernel_size=2),nn.Conv2d(in_channels=32, out_channels=32, kernel_size=5, padding=2),nn.MaxPool2d(kernel_size=2),nn.Conv2d(in_channels=32, out_channels=64, kernel_size=5, padding=2),nn.MaxPool2d(kernel_size=2),nn.Flatten(),nn.Linear(in_features=1024, out_features=64),nn.Linear(in_features=64, out_features=10))def forward(self, x):# x = self.conv1(x)# x = self.maxpool1(x)# x = self.conv2(x)# x = self.maxpool2(x)# x = self.conv3(x)# x = self.maxpool3(x)# x = self.flatten(x)# x = self.linear1(x)# x = self.linear2(x)x = self.model1(x)return xtudui = Tudui()writer = SummaryWriter("./logs_seq")
input = torch.ones(64, 3, 32, 32)
output = tudui(input)
print(output.shape)
writer.add_graph(tudui, input)
writer.close()