遥阳科技网站建设pc网站建设和推广
作业要求
以下操作在实验09-工单文本分类.ipynb的代码基础上来完成。
文本预处理
- 使用jieba的全模式对工单文本进行分词,并去除停用词。
- 去除文本中的数字、标点符号、特殊字符以及字母等。
- 去除包含“省”、“市”、“县”的词。
- 去除低频词,保留词频大于2的词。
词向量优化
当前Word2Vec使用默认参数训练,调整以下参数并分析影响:
- 窗口大小(window)设置为5/7
- 最小词频(min_count)设置为3/5
- 使用不同的训练算法(sg=0(CBOW)、sg=1(Skip-gram))
- 调整训练轮数(epochs)为50/100
文本分类模型优化
- 将词向量转换为句子向量,并使用句子向量进行分类。
- 思路:使用词向量平均的方式将词向量转换为句子向量。
- 使用贝叶斯分类器进行分类并评估
实验要求 - 每项实验需记录主要参数设置、训练过程中的损失变化、最终模型在验证集/测试集上的准确率。 - 对比分析不同设置下模型表现的异同,并给出结论。
代码部分
# 环境配置与基础包导入
import jieba
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import classification_report
from gensim.models import Word2Vec
import warnings
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from gensim import corpora, models
import pandas as pdwarnings.filterwarnings('ignore')# 配置参数类
data_path = '../data/telecom_orders.csv'
stopwords_path = '../data/stopwords.txt'
# 数据加载
def load_data():print("加载数据中...")# TODO: 从CSV文件加载数据# 提示:使用pandas的read_csv函数df = pd.read_csv(data_path)print(f"数据加载完成,共 {len(df)} 条记录")return dfdf = load_data()
# 加载停用词
def load_stopwords(path):# TODO: 读取停用词文件并返回停用词集合# 提示:# 1. 使用utf-8编码打开文件with open(path,'r', encoding='utf-8') as f:stopwords= set([line.strip() for line in f])# 2. 去除每行两端的空白return stopwordsstopwords = load_stopwords(stopwords_path)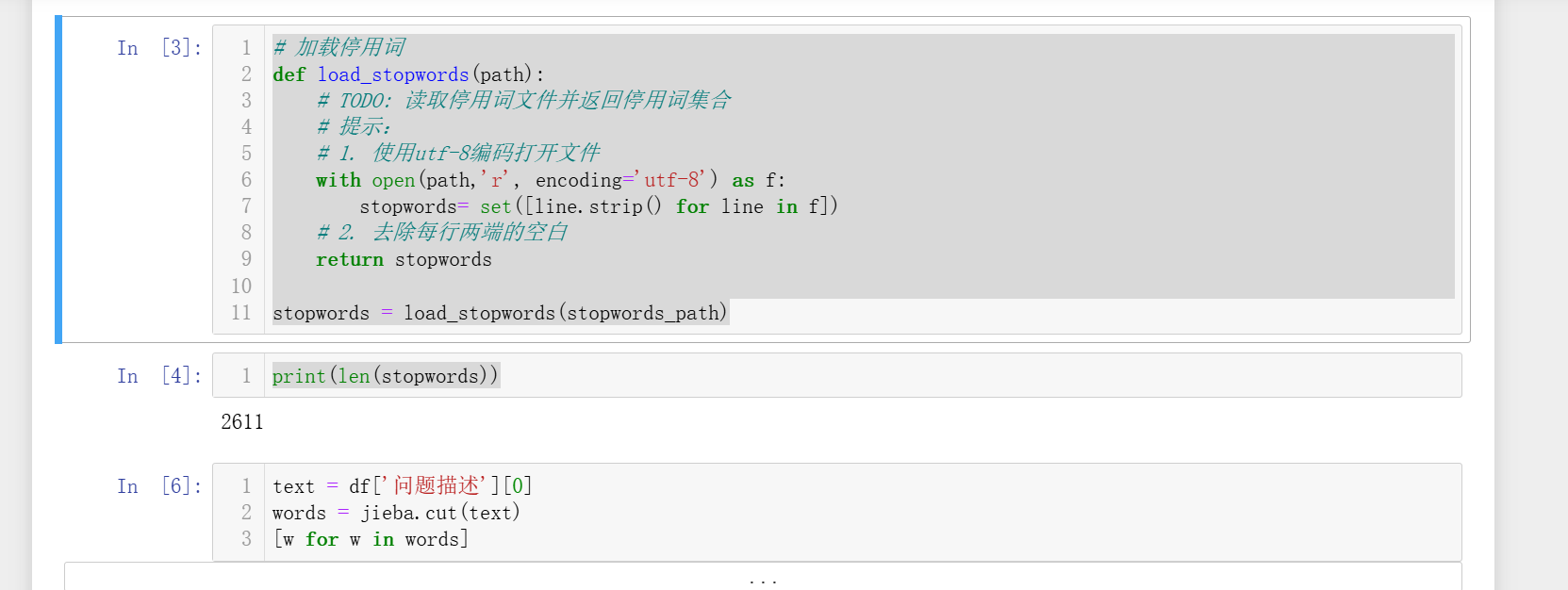
import re
from collections import Counter# 修改后的中文文本预处理函数
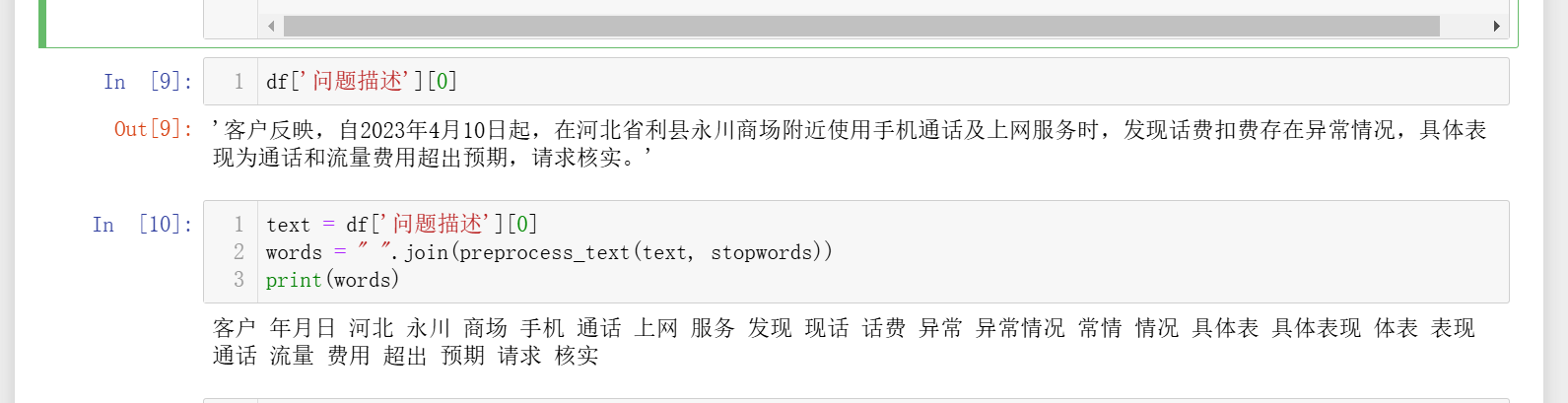
def preprocess_text(text, stopwords):# 去除数字、标点符号、特殊字符和字母text = re.sub(r'[a-zA-Z0-9\s+\.\!\/_,$%^*()?;;:-【】+\"\']+|[+——!,;:。?、~@#¥%……&*()]+', '', text)# 使用jieba全模式分词words = jieba.cut(text, cut_all=True)# 过滤条件words = [w for w in words #过滤单字词if len(w) > 1 #排除停用词and w not in stopwords #去除文本中的数字、标点符号、特殊字符以及字母等and not re.match(r'^[a-zA-Z0-9]+$', w)#去除包含“省”、“市”、“县”的词and '省' not in w and '市' not in w and '县' not in w]return words
# 计算词频并过滤低频词
def filter_low_freq_words(texts, min_count=3):all_words = []for text in texts:all_words.extend(text)word_counts = Counter(all_words)filtered_words = {word for word, count in word_counts.items() if count > min_count}return [[word for word in text if word in filtered_words] for text in texts]
# 修改后的预处理流程
def preprocess_data(df, min_count=3):print("数据预处理中...")texts = df['问题描述'].valueslabels = df['故障类型'].valuesle_encoder = LabelEncoder()encoded_labels = le_encoder.fit_transform(labels)num_classes = len(le_encoder.classes_)# 文本预处理processed_texts = [preprocess_text(text, stopwords) for text in texts]# 过滤低频词processed_texts = filter_low_freq_words(processed_texts, min_count)# 将分词结果转换为空格连接的字符串texts = [" ".join(text) for text in processed_texts]X_train, X_test, y_train, y_test = train_test_split(texts, encoded_labels, test_size=0.2,stratify=encoded_labels)print(f"训练集: {len(X_train)} 样本, 测试集: {len(X_test)} 样本")print(f"分类类别数: {num_classes}")return X_train, X_test, y_train, y_test, le_encoder, num_classes, processed_texts
# 重新加载数据并进行预处理
df = load_data()
X_train, X_test, y_train, y_test, label_encoder, num_classes, processed_texts = preprocess_data(df, min_count=3)
from gensim.models import Word2Vec
import time
# 准备Word2Vec训练数据
train_texts = [text.split() for text in X_train]
# 词向量训练函数
def train_word2vec(texts, window=5, min_count=5, sg=0, epochs=10):start_time = time.time()model = Word2Vec(sentences=texts,vector_size=100,window=window,min_count=min_count,sg=sg,epochs=epochs,workers=4,compute_loss=True, # 启用损失计算)# 获取最终训练损失training_loss = model.get_latest_training_loss()print(f"训练完成,耗时: {time.time()-start_time:.2f}秒,最终损失: {training_loss:.4f}")return model
# 实验不同参数组合
param_combinations = [{'window':5, 'min_count':3, 'sg':0, 'epochs':50},{'window':5, 'min_count':3, 'sg':1, 'epochs':50},{'window':7, 'min_count':3, 'sg':0, 'epochs':50},{'window':7, 'min_count':3, 'sg':1, 'epochs':50},{'window':5, 'min_count':5, 'sg':0, 'epochs':100},{'window':5, 'min_count':5, 'sg':1, 'epochs':100},{'window':7, 'min_count':5, 'sg':0, 'epochs':100},{'window':7, 'min_count':5, 'sg':1, 'epochs':100},
]word2vec_models = {}
for i, params in enumerate(param_combinations):print(f"\n训练Word2Vec模型 {i+1}/{len(param_combinations)}")print(f"参数: {params}")model = train_word2vec(train_texts, **params)word2vec_models[f"model_{i+1}"] = (model, params)
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import accuracy_score
import numpy as np # 添加这行导入语句# 将词向量转换为句子向量(平均)
def text_to_vector(text, model):words = text.split()word_vectors = [model.wv[word] for word in words if word in model.wv]if len(word_vectors) == 0:return np.zeros(model.vector_size)return np.mean(word_vectors, axis=0)# 评估函数
def evaluate_model(model_params_pair, X_train, X_test, y_train, y_test):model, params = model_params_pairprint(f"\n评估模型 (参数: {params})")# 转换训练集和测试集X_train_vec = np.array([text_to_vector(text, model) for text in X_train])X_test_vec = np.array([text_to_vector(text, model) for text in X_test])# 训练分类器nb_clf = GaussianNB()nb_clf.fit(X_train_vec, y_train)# 预测并评估y_pred = nb_clf.predict(X_test_vec)acc = accuracy_score(y_test, y_pred)print(f"测试集准确率: {acc:.4f}")print(classification_report(y_test, y_pred))return acc# 评估所有模型
results = {}
for name, model_pair in word2vec_models.items():acc = evaluate_model(model_pair, X_train, X_test, y_train, y_test)results[name] = {'accuracy': acc,'params': model_pair[1]}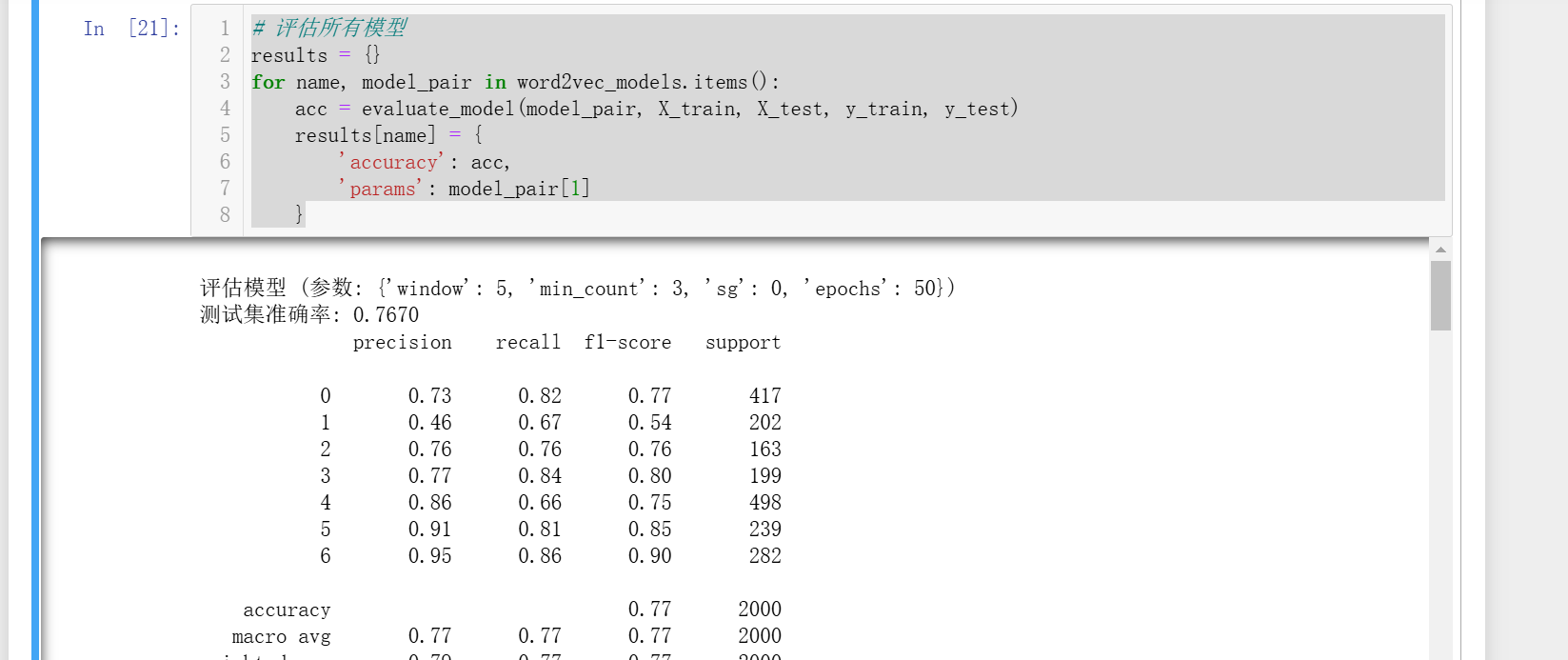
# 结果分析
print("\n不同参数组合下的模型表现对比:")
for name, result in results.items():print(f"\n模型 {name}:")print(f"参数: {result['params']}")print(f"准确率: {result['accuracy']:.4f}")# 找出最佳模型
best_model_name = max(results, key=lambda x: results[x]['accuracy'])
best_result = results[best_model_name]
print(f"\n最佳模型是 {best_model_name}:")
print(f"参数: {best_result['params']}")
print(f"准确率: {best_result['accuracy']:.4f}")# 参数影响分析
print("\n参数影响分析:")
param_effects = {'window': {},'min_count': {},'sg': {},'epochs': {}
}for name, result in results.items():params = result['params']for param in param_effects:if params[param] not in param_effects[param]:param_effects[param][params[param]] = []param_effects[param][params[param]].append(result['accuracy'])for param, values in param_effects.items():print(f"\n参数 {param} 的影响:")for value, accs in values.items():print(f"{value}: 平均准确率 {np.mean(accs):.4f} (范围: {min(accs):.4f}-{max(accs):.4f})")