订做网站和app建网站方法
目录
效果预览
微博api
工作流搭建
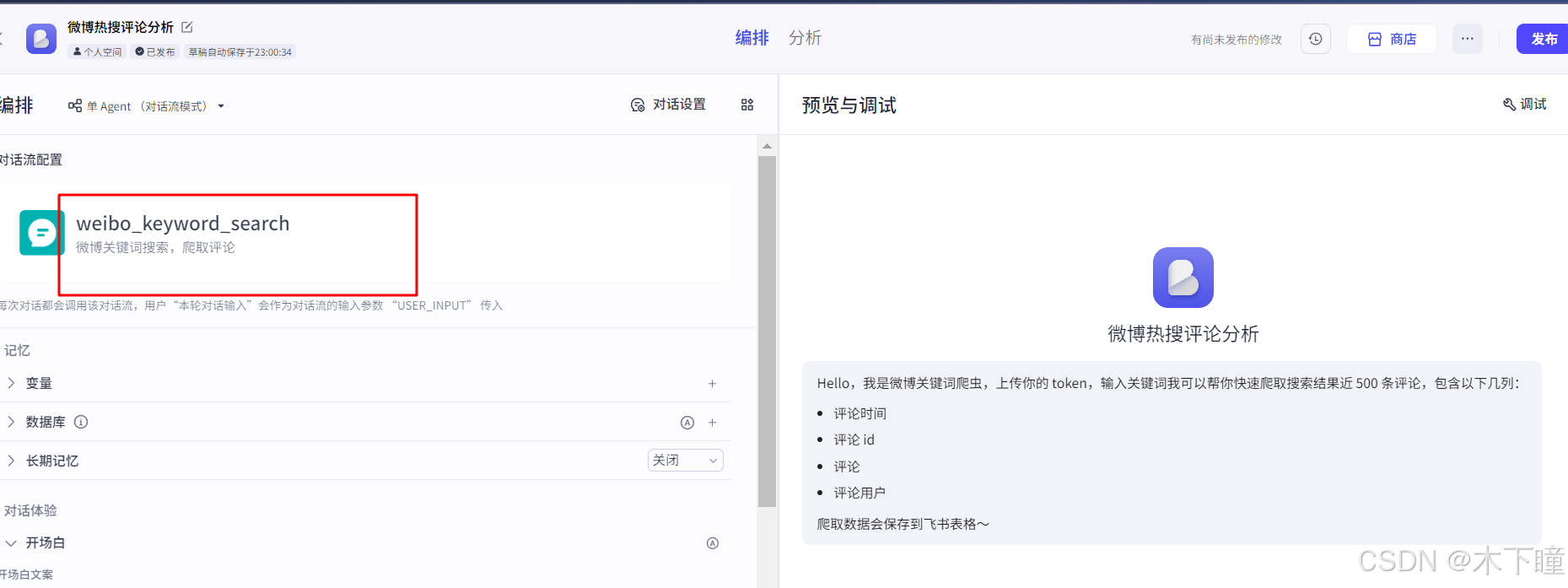
效果预览
用扣子平台通过工作流的方式搭建了微博关键词爬虫,通过对话方式,效果如下:
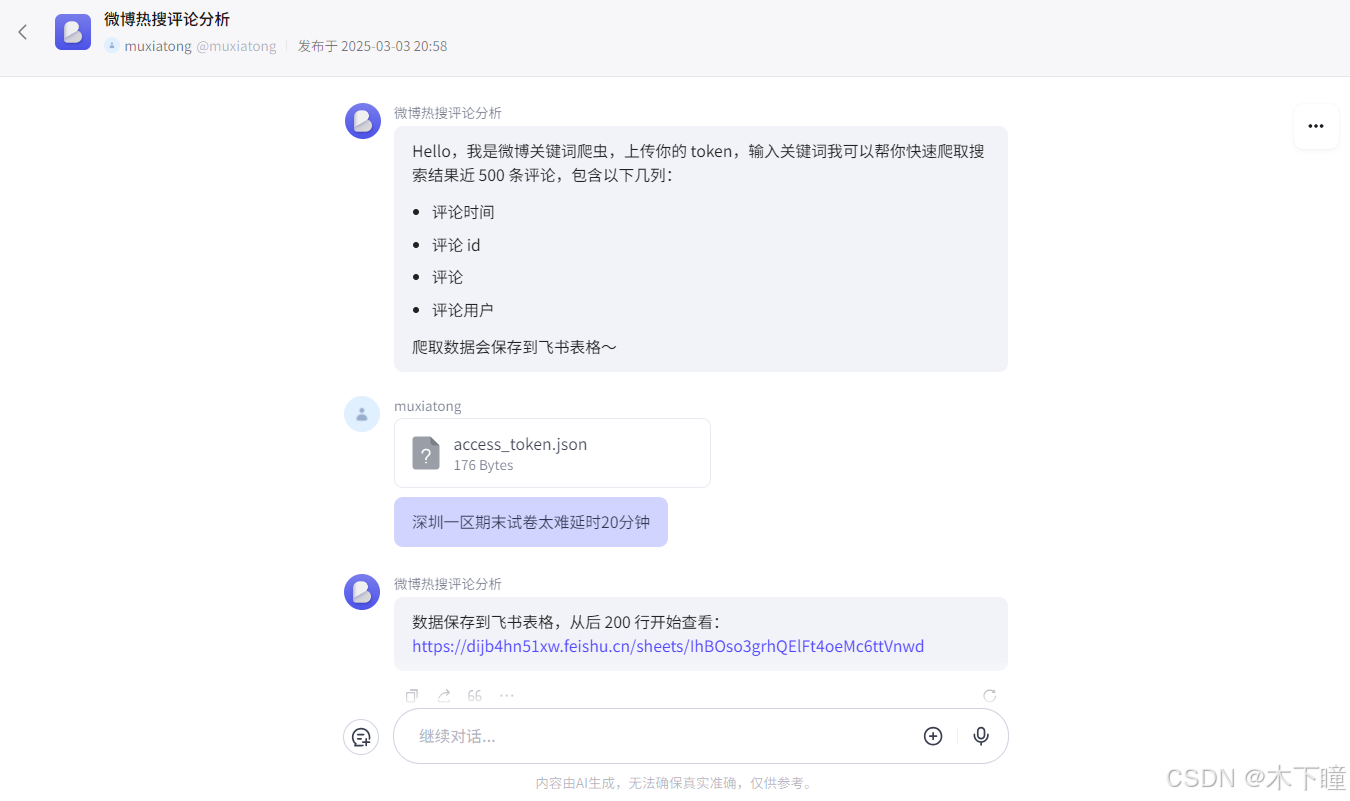
调用的是微博官方的 api 接口,有一定限制,不适合大量爬取,适合场景为想要快速根据词条获得一些评论数据进行分析的人使用。
所以可以通过工作流方式进行封装,主要是把爬虫代码封装进工作流。
微博api
API - 微博API
爬虫用到的 api,因为需要登录才能获得数据,且扣子不支持把以下代码封装,所以我们我们需要用自己微博账号注册一个应用获得 app key,app secret,参考链接:
爬取微博热搜评论生成词云
获得后使用 python 运行以下代码,
client_key = '你的 app key',
client_secret = '你的 app secret'
记得替换为你自己的,其他不用任何修改
import json
import requests
import webbrowser
import timedef get_access_token():# 授权步骤# https://open.weibo.com/wiki/%E6%8E%88%E6%9D%83%E6%9C%BA%E5%88%B6%E8%AF%B4%E6%98%8E#.E5.BA.94.E7.94.A8.E5.9C.BA.E6.99.AF# 第一步 authorize 接口,请求用户授权code# https://open.weibo.com/wiki/Oauth2/authorizeclient_key = '你的 app key'redirect_uri = 'https://api.weibo.com/oauth2/default.html'url1 = 'https://api.weibo.com/oauth2/authorize'res_1 = requests.get(url1, params={'client_id': client_key, 'redirect_uri': redirect_uri})webbrowser.open_new(res_1.url)code = input('输入 code:')# 第二步 access_token 接口,用 code 换取授权 access_token# https://open.weibo.com/wiki/Oauth2/access_tokenclient_secret = '你的 app secret'url2 = 'https://api.weibo.com/oauth2/access_token'res_2 = requests.post(url2, data={'client_id': client_key, 'client_secret': client_secret, 'redirect_uri': redirect_uri,'grant_type': 'authorization_code', 'code': code})data = res_2.json()access_token = data['access_token']expires_in = data['expires_in']print(f'token:{access_token}, 有效时间:{expires_in}s')# 获取当前时间戳(以秒为单位)current_timestamp = int(time.time())# 计算过期时间戳expiration_timestamp = current_timestamp + expires_in# 保存data['expiration_timestamp'] = expiration_timestampwith open('access_token.json', 'w') as f:f.write(json.dumps(data, ensure_ascii=False))return access_tokenprint(get_access_token())运行后会在打开浏览器,你需要用微博扫码登录后会变成以下页面,输入这个 code 会得到结果 json 文件:
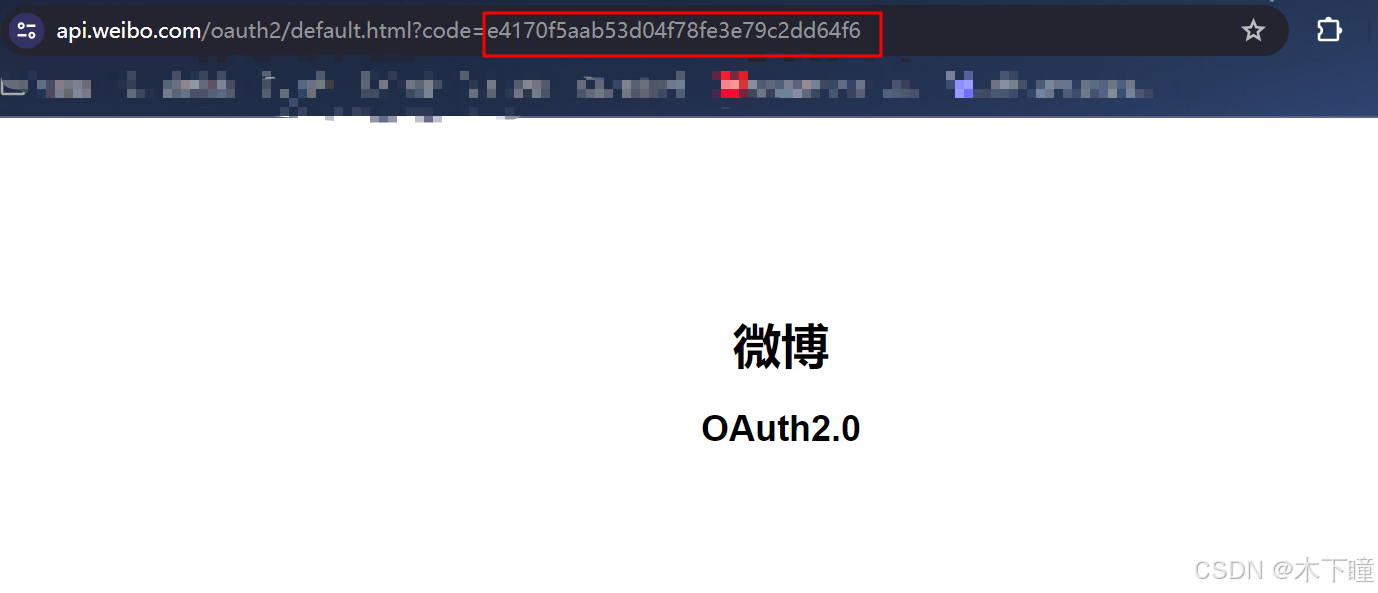
代码同目录获得 access_token.json 文件:
![]()
这是我们需要上传到工作流的凭证。
工作流搭建
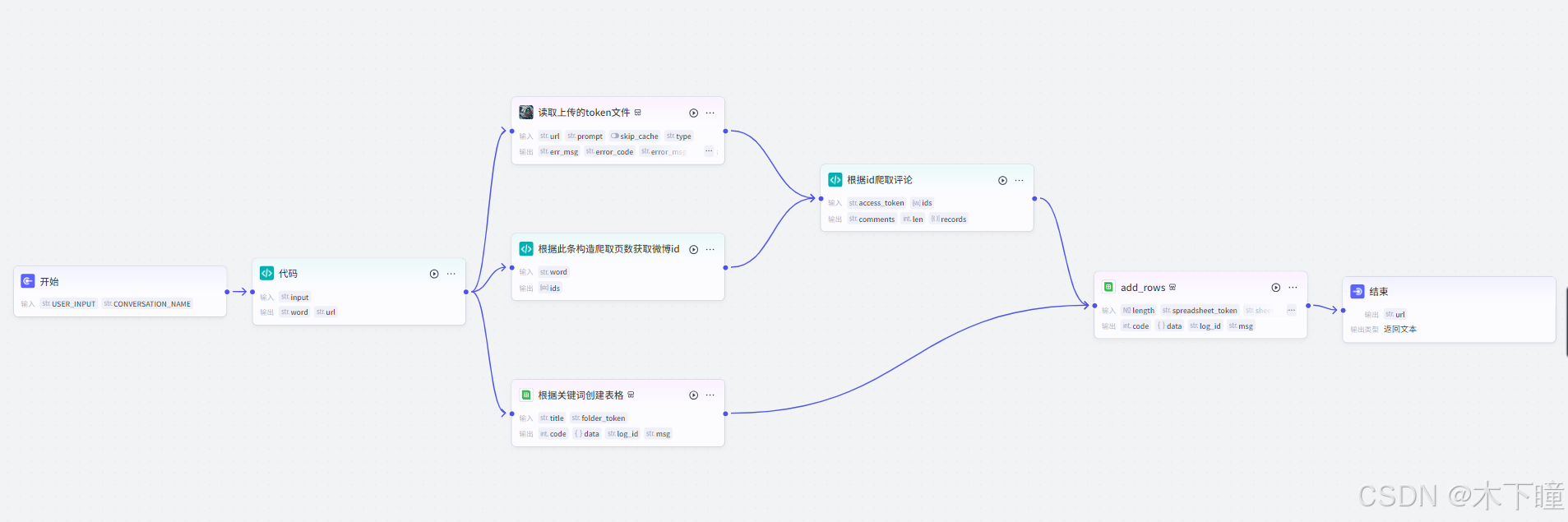
打开扣子,新建项目,选择对话流模式,设置开场白:
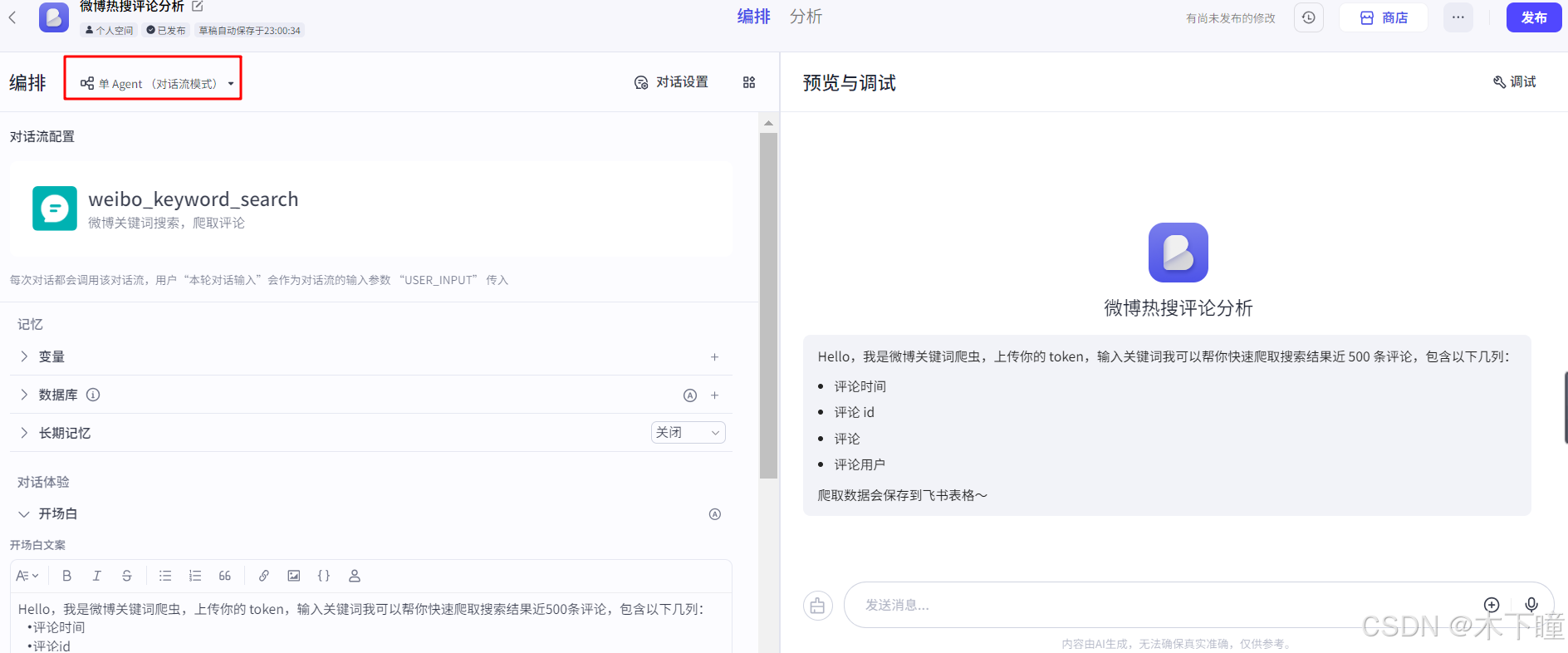
添加对话流,即新建对话流,开始节点不用动,添加一个代码节点,用来分割用户输入的关键词及 token 文件链接,输入引用用户的输入,输出添加 ret 变量中的字段:
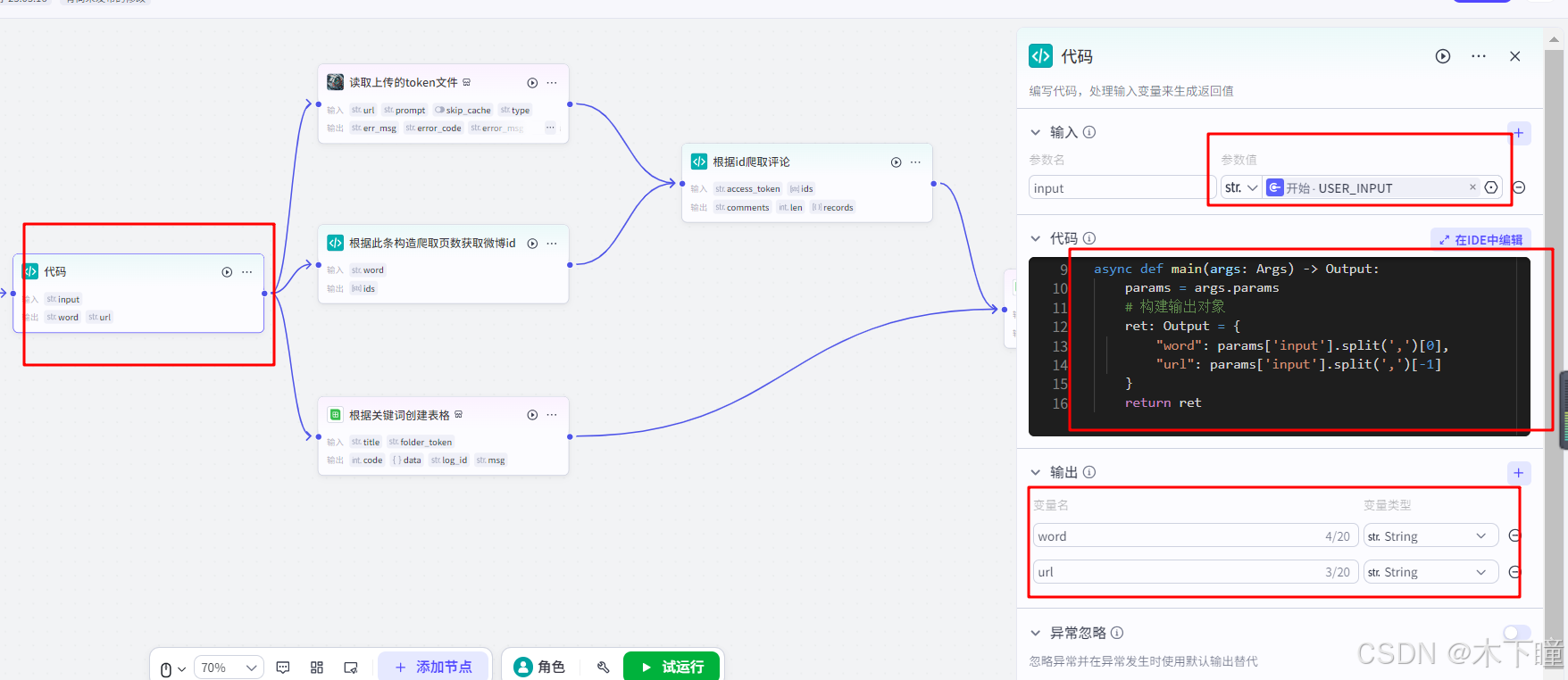
async def main(args: Args) -> Output:params = args.params# 构建输出对象ret: Output = {"word": params['input'].split(',')[0],"url": params['input'].split(',')[-1]}return ret添加插件节点“读取上传的token文件”,输入引用代码分割后的 url,此 url 是用户上传后 token 的 url,也就是读取文件内容的插件,这里读 token
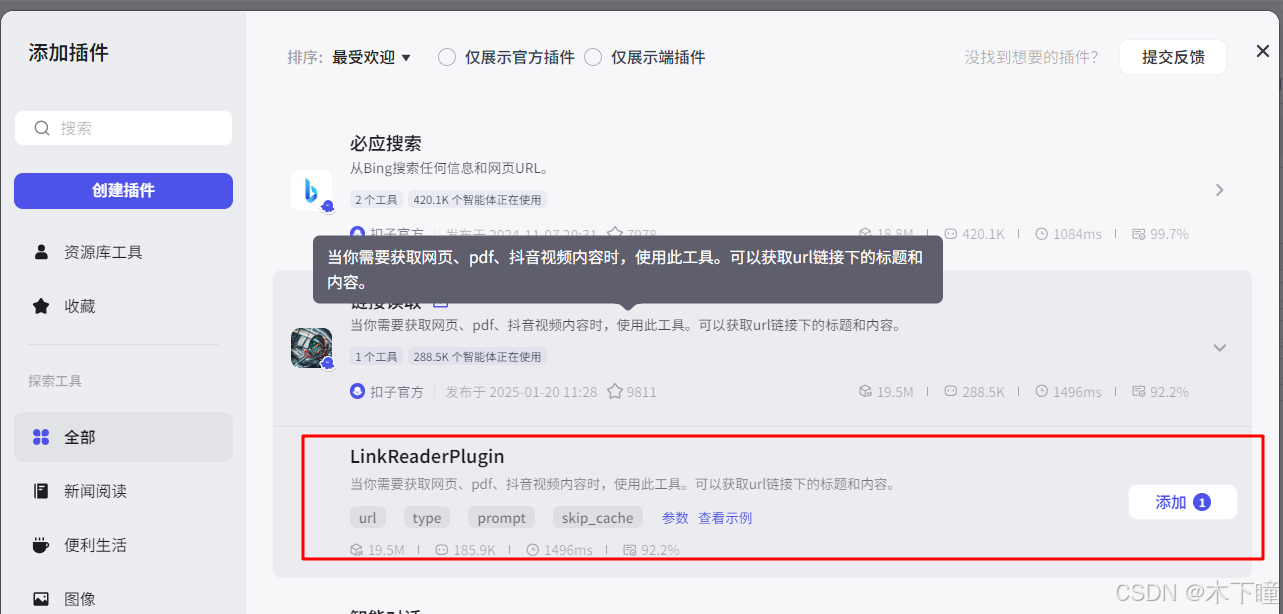
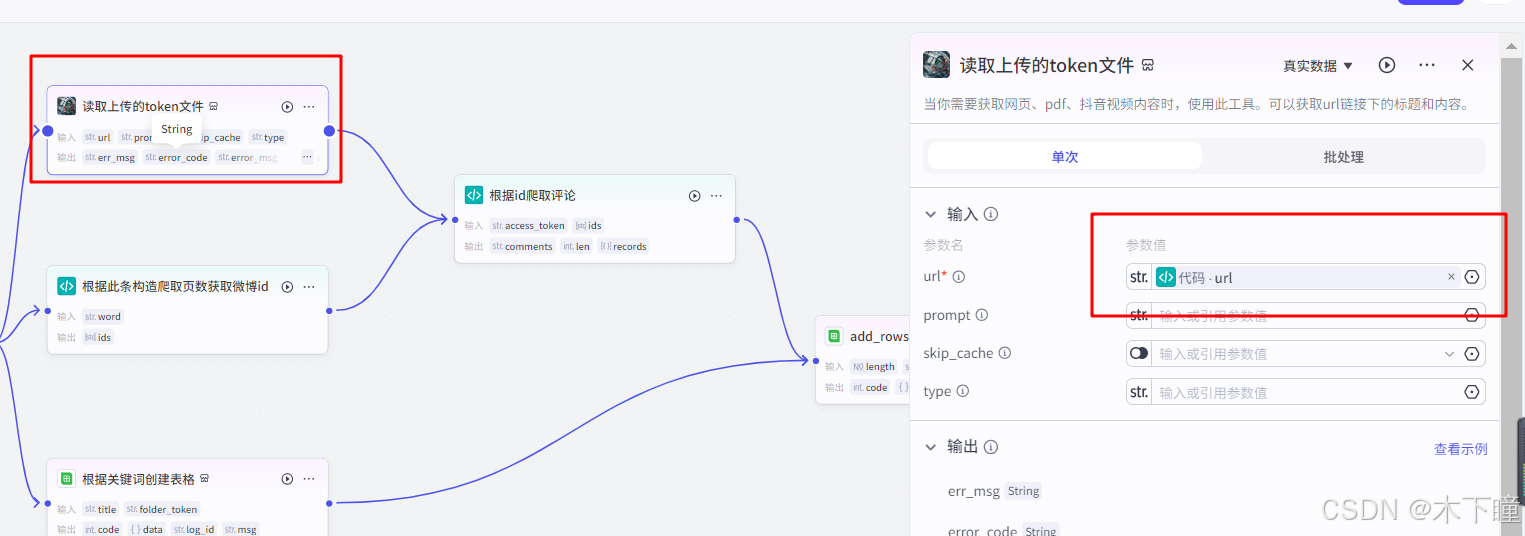
根据此条构造爬取页数获取微博id,也是一个代码节点,爬虫代码的一部分,输入引用代码分割后得到的词条,输出爬取得到微博 ids:
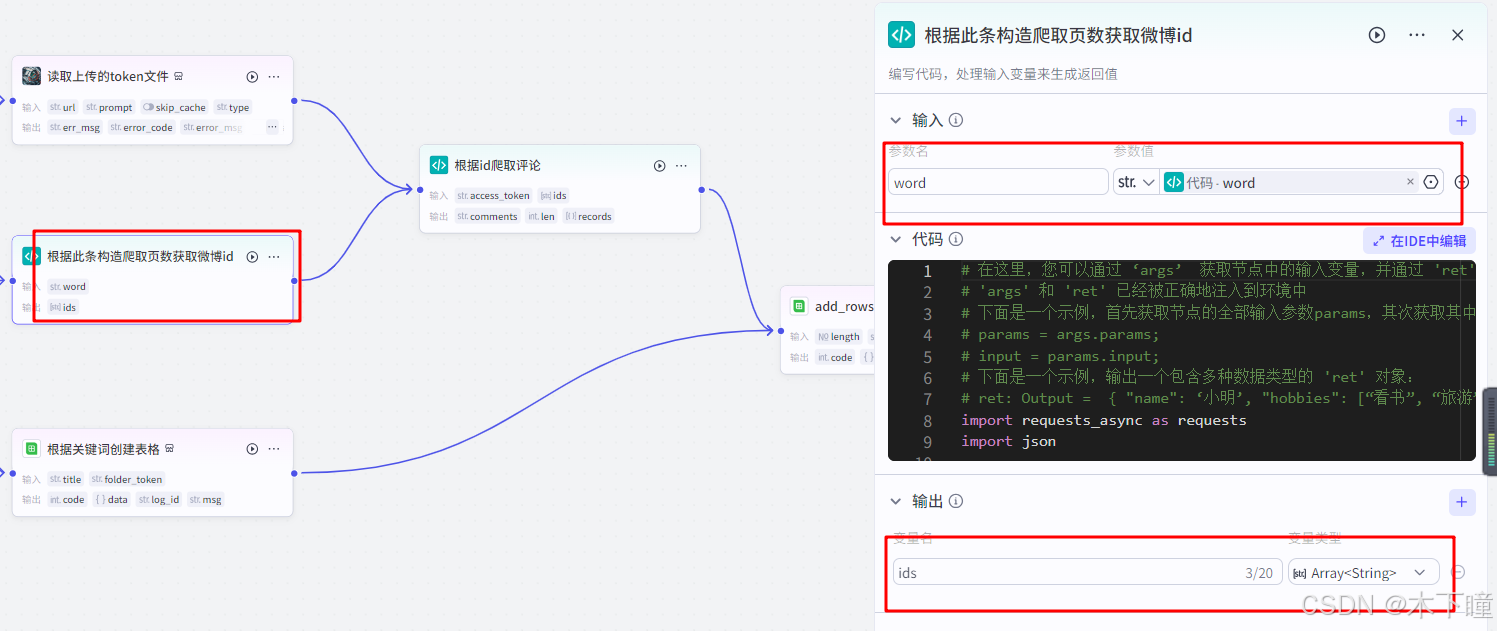
import requests_async as requests
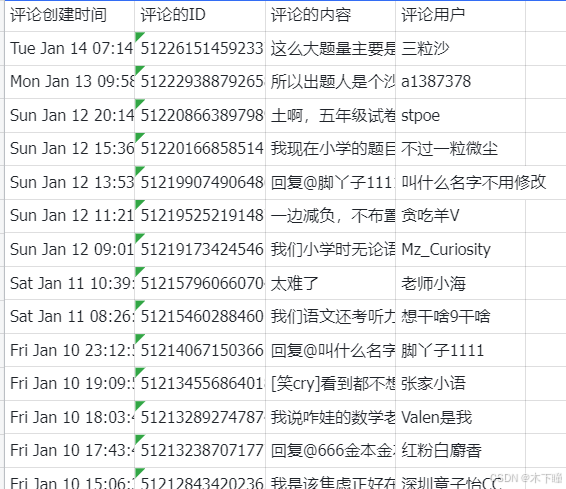
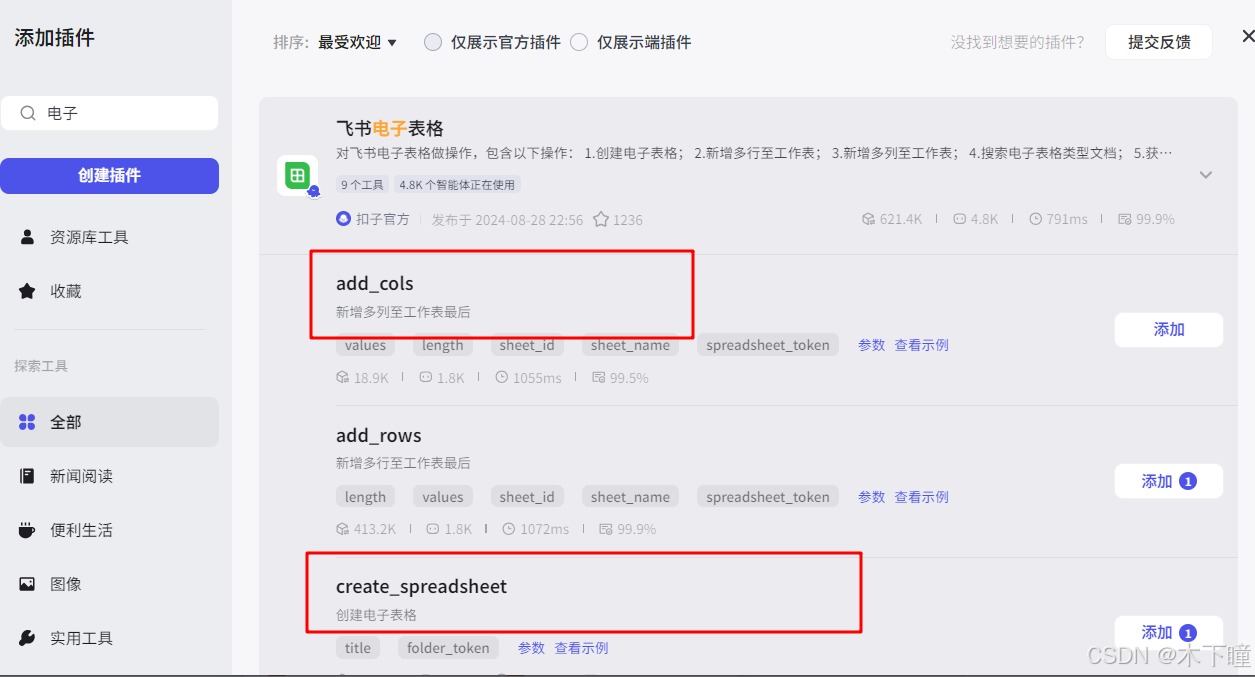
import jsonasync def main(args: Args) -> Output:params = args.paramsword = params['word']urls = ['https://m.weibo.cn/api/container/getIndex?containerid=100103type%3D1%26q%3D{}&page_type=searchall&page={}'.format(word, i) for i in range(1, 51)]headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36',}async def get_ids(urls):# 获取多页 idids = []for index, url in enumerate(urls):print(f'当前页数 {index + 1}/{len(urls)}........')response = await requests.get(url, headers=headers)data = json.loads(response.text)cards = data['data']['cards']for d in cards:try:id_ = d['mblog']['id']except KeyError:try:id_ = d['card_group'][0]['mblog']['id']except KeyError:id_ = ''if id_ != '':ids.append(id_)print(f'总共 {len(ids)} 条微博.')return idsids = await get_ids(urls)# 构建输出对象ret: Output = {"ids": ids[:1]}return ret数据用飞书电子表格保存,所以添加两个插件节点,一个是创建表格,一个是写入表格;
创建表格的名称引用代码分割的词条:
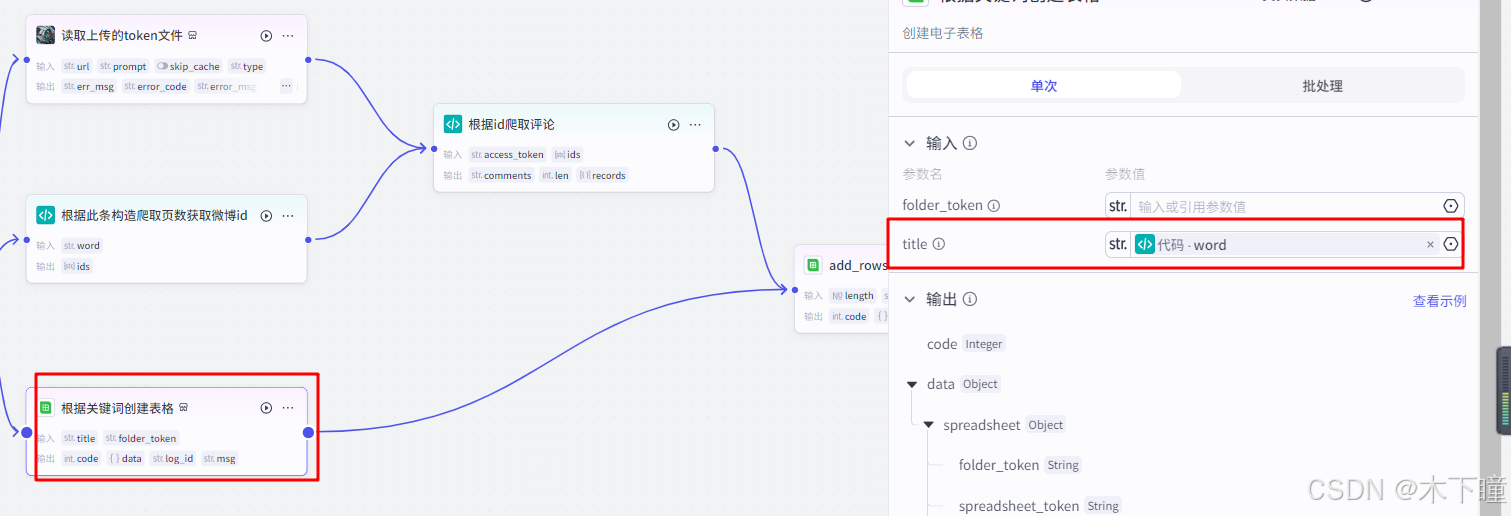
根据微博id爬取评论,也是一个代码节点,输入引用读取获得的 token,以及爬取得到的微博ids,输出爬取得到的评论列表及长度:
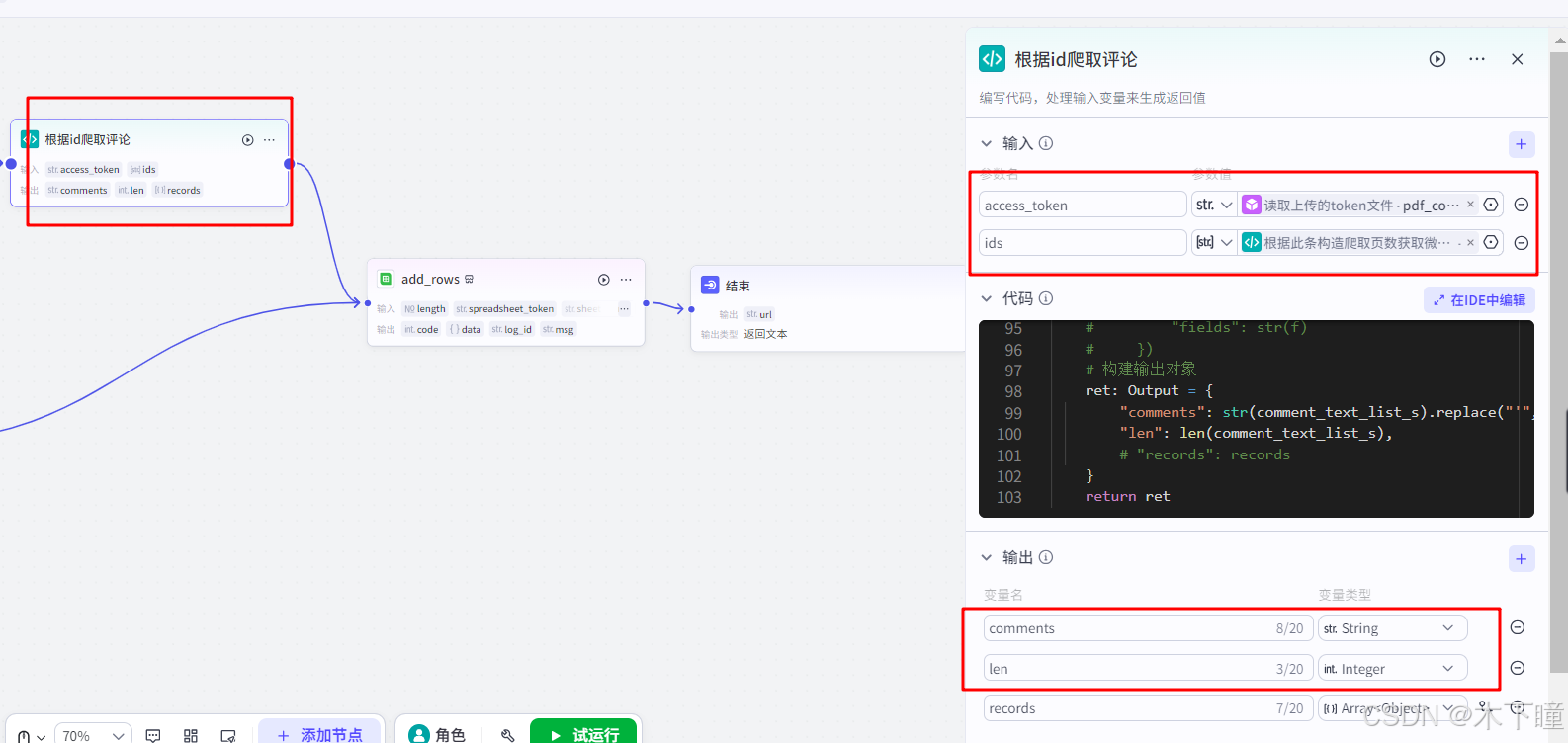
import json
import requests_async as requestsasync def main(args: Args) -> Output:params = args.paramsids = params['ids']access_token = json.loads(params['access_token'])['access_token']comment_text_list_s = [['评论创建时间', '评论的ID', '评论的内容', '评论用户']]for index, _id in enumerate(ids):created_at_lst = [] # 保存所有评论创建时间id_lst = [] # 保存所有评论的 idtext_lst = [] # 保存所有评论的 textuser_lst = [] # 保存所有评论的 user 信息user_name_lst = [] # 保存所有评论的 user 名称mid_lst = [] # 保存所有评论的 mididstr_lst = [] # 保存所有评论的字符串 idstatus_lst = [] # 保存所有评论的微博信息reply_comment_lst = [] # 保存所有评论来源评论,当本评论属于对另一评论的回复时返回此字段# 共获取 2 页 * 每页最多 100 条评论flag = 0for i in range(1, 3):url = 'https://api.weibo.com/2/comments/show.json'result = await requests.get(url, params={'access_token': access_token, 'id': _id, 'count': 100})# 判断是否被限流if json.loads(result.text).get('error') is not None:print(f'可能被限流了,{result.text}')exit(0)comments = json.loads(result.text)['comments']if not len(comments):breakfor item in comments:created_at = item['created_at']comment_id = item['id']text = item['text']user = item['user']user_name = user['name']mid = item['mid']idstr = item['idstr']status = item['status']reply_comment = item.get('reply_comment')# 判断时候评论开始重复if idstr in idstr_lst:print(f'当前页数 {i} 评论重复,跳过')flag = 1breakcreated_at_lst.append(str(created_at))id_lst.append(str(comment_id))text_lst.append(str(text))user_lst.append(str(user))user_name_lst.append(str(user_name))mid_lst.append(str(mid))idstr_lst.append(str(idstr))status_lst.append(str(status))reply_comment_lst.append(str(reply_comment))if flag:break# comment_text_list = list(zip(created_at_lst, id_lst, text_lst, user_lst, user_name_lst, mid_lst,# idstr_lst, status_lst, reply_comment_lst))comment_text_list = list(zip(created_at_lst, id_lst, text_lst, user_name_lst))comment_text_list_s.extend(comment_text_list)comment_text_list_s = comment_text_list_scomment_text_list_s = [list(i) for i in comment_text_list_s]# records = []# for c in comment_text_list_s:# f = {# "评论创建时间": c[0],# "评论的ID": c[1],# "评论的内容": c[2],# "评论的点赞数": c[3],# "评论用户": c[4],# "评论用户ID": c[5],# "字符串型的评论ID": c[6],# "评论的微博信息": c[7],# "评论来源评论": c[8]# }# records.append({# "fields": str(f)# })# 构建输出对象ret: Output = {"comments": str(comment_text_list_s).replace("'", '"'),"len": len(comment_text_list_s),# "records": records}return ret写入数据到表格,输入引用如下图:
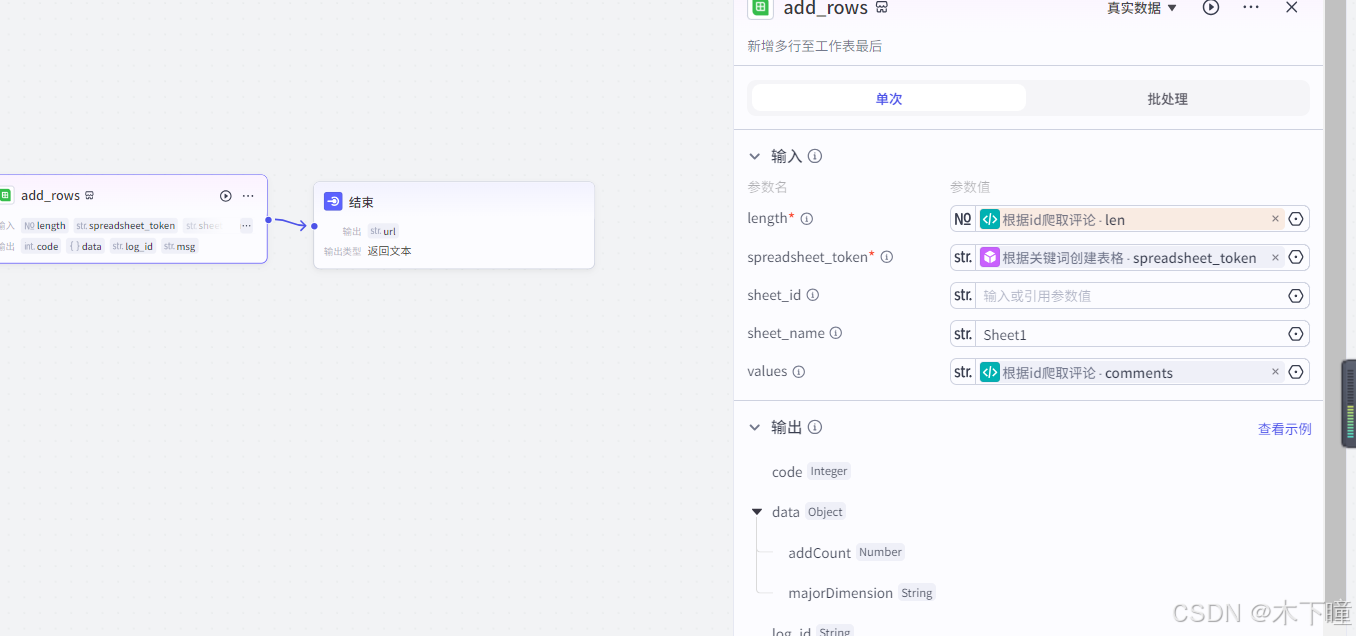
结束节点,就输出回复,飞书表格链接,要从后 200 行开始看:
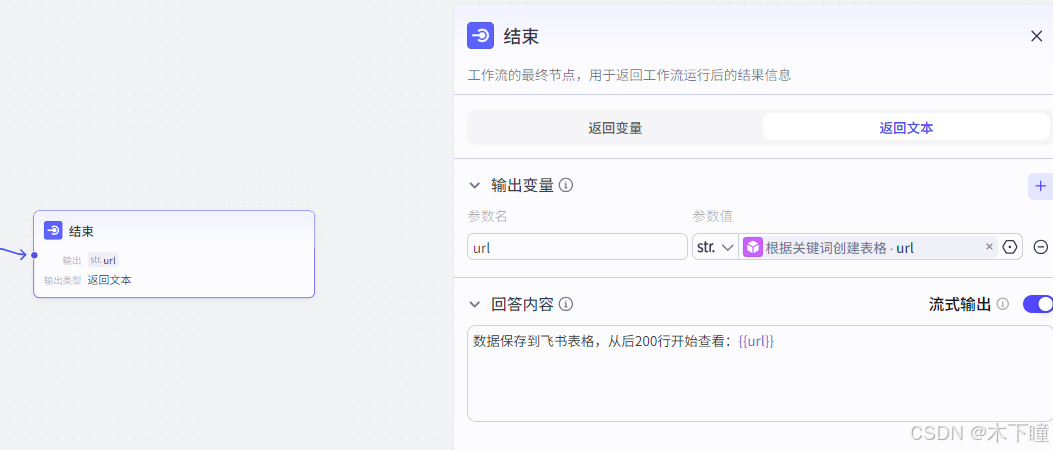
对话流配置好发布,在刚开始项目中添加即可完成了