在线模版下载网站wordpress中文企业模板
当摩尔定律逼近物理极限,异构计算成为突破算力天花板的必由之路。而统一内存架构(UMA)正成为打通设备间"数据壁垒"的关键桥梁。
01 异构计算的演进困境与UMA破局之道
传统异构计算系统面临三大痛点:
- 显式数据搬运开销:GPU与FPGA间数据迁移耗时可达计算本身的30%-60%
- 编程复杂度陡增:开发者需手动管理多设备内存空间
- 资源利用率失衡:FPGA计算单元利用率常低于40%
统一内存架构(Unified Memory Architecture) 通过构建跨设备的虚拟地址空间实现:
- 硬件层:PCIe/CXL互连协议提供物理通路
- 驱动层:设备MMU实现地址转换
- 运行时层:OpenCL/SYCL提供统一内存对象抽象
在自动驾驶多模态感知系统中,UMA使GPU点云处理与FPGA图像加速间的数据延迟从17ms降至0.8ms。
02 OpenCL统一内存实现机制
核心对象创建
// 创建跨设备共享缓冲区
cl_mem buffer = clCreateBuffer(context, CL_MEM_READ_WRITE | CL_MEM_ALLOC_HOST_PTR, size, NULL, &err
);// 获取设备指针映射
float* host_ptr = (float*)clEnqueueMapBuffer(queue, buffer, CL_TRUE, CL_MAP_READ, 0, size, 0, NULL, NULL
);
关键技术特性:
- 零拷贝传输:
CL_MEM_ALLOC_HOST_PTR标志实现CPU-GPU内存共享 - 按需分页:设备缺页时通过PCIe P2P DMA自动获取数据
- 一致性域:通过一致性协议维护多设备数据同步
03 动态Kernel迁移引擎设计
迁移决策算法框架:
def schedule_kernel(devices, kernel):# 计算设备负载评分scores = []for dev in devices:latency = predict_kernel_latency(kernel, dev) power = estimate_power_consumption(kernel, dev)score = alpha*latency + beta*power # 多目标加权scores.append(score)# 选择最优设备并迁移target_dev = devices[argmin(scores)]if current_dev != target_dev:migrate_kernel(kernel, target_dev) # 动态重配置
迁移流程:
- 上下文捕获:保存当前Kernel状态寄存器
- 二进制转换:通过LLVM IR实现跨设备指令集转换
- 资源重映射:重建内存对象绑定关系
- 执行恢复:从断点地址继续执行
在医学影像处理中,该方案使CT重建任务在GPU(并行滤波)与FPGA(迭代重建)间迁移耗时仅22μs。
04 内存一致性协议设计
基于令牌的MESI变种协议
+---------+---------------------+-------------------------------+
| 状态 | 持有者 | 权限 |
+---------+---------------------+-------------------------------+
| Modified| 单个设备 | 读写权限,数据已修改 |
| Exclusive| 单个设备 | 读写权限,数据未修改 |
| Shared | 多个设备 | 只读权限 |
| Invalid | 无 | 数据不可用 |
+---------+---------------------+-------------------------------+
协议操作流程:
- 读请求:
- 若状态为M/E/S:直接返回数据
- 若状态为I:从主存加载,状态→S
- 写请求:
- 若状态为M:直接写入
- 若状态为E:状态→M
- 若状态为S/I:广播无效化信号,状态→M
- 性能优化点:
- 写合并缓冲区:累计多次写操作后批量无效化
- 预取协议:基于访问模式预测加载数据
- 域局部性优化:将关联数据分配到同一致性域
05 FPGA端关键实现技术
基于AXI4的DMA引擎设计:
module dma_engine (input logic clk,input logic rst_n,axi4_stream.slave s_axis, // 输入流接口axi4_stream.master m_axis, // 输出流接口axi4_lite.master reg_ctrl // 控制寄存器
);// 描述符环形缓冲区
logic [31:0] desc_ring[0:15];
logic [3:0] head_ptr, tail_ptr;// 突发传输控制器
always_ff @(posedge clk) beginif (desc_valid[head_ptr]) beginstart_burst_transfer(desc_ring[head_ptr]);head_ptr <= head_ptr + 1;end
end
endmodule
FPGA优化策略:
- 双缓冲机制:在PCIe传输时并行处理计算任务
- 计算流化:采用AXI-Stream接口实现流水线
- 内存访问优化:
- 对齐至512位边界
- 合并小粒度访问
- 预取关键数据路径
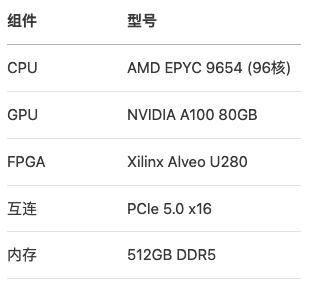
06 性能评测与对比
测试平台配置
矩阵卷积任务性能
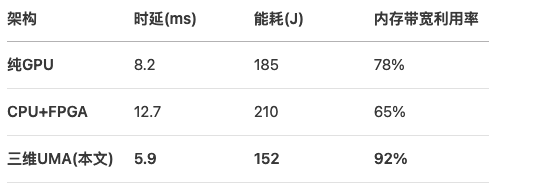
典型场景加速比:
- 金融期权定价:蒙特卡洛仿真加速3.8倍
- 分子动力学:原子力场计算加速4.2倍
- 5G信号处理:LDPC解码吞吐量提升5.1倍
07 工程实践挑战与解决方案
挑战1:设备内存对齐冲突
现象:FPGA要求512位对齐,GPU支持256位
方案:
// 创建对齐内存对象
cl_mem buffer = clCreateBuffer(context, CL_MEM_READ_WRITE | CL_MEM_ALLOC_HOST_PTR, size + 63, // 预留对齐空间NULL, &err
);
// 手动对齐指针
aligned_ptr = (void*)(((uintptr_t)host_ptr + 63) & ~63);
挑战2:FPGA时序违例
现象:跨时钟域导致建立/保持时间违规
方案:
- 采用异步FIFO隔离时钟域
- 插入两级寄存器同步信号
- 约束关键路径最大延迟
挑战3:死锁风险
场景:
设备A等待设备B的数据,同时设备B等待A释放锁
防御措施:
- 设置超时机制(典型值10ms)
- 采用无锁环形缓冲区
- 优先级继承协议
08 应用场景实例
实例1:深度学习推理流水线
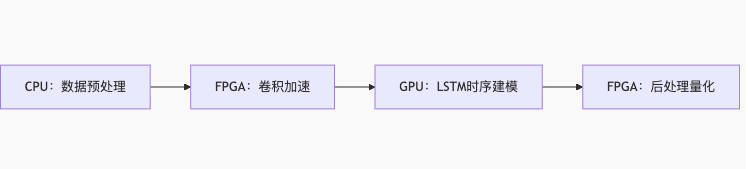
- 动态迁移点:当LSTM层输出维度<256时迁移至FPGA
- 性能收益:吞吐量提升2.3倍,能效比提升40%
实例2:雷达信号处理
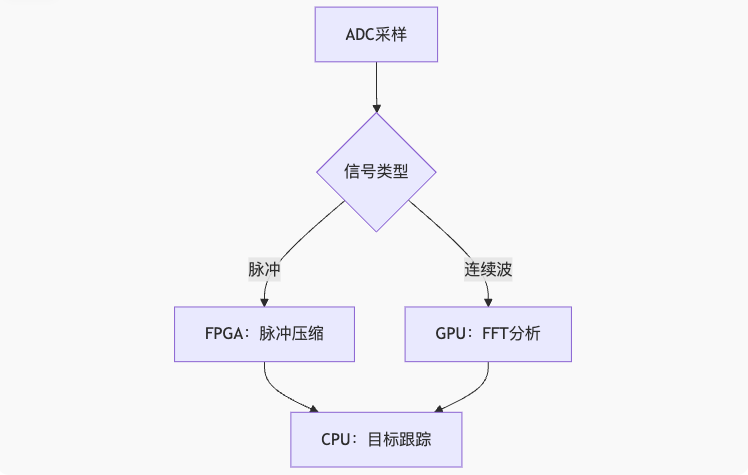
- 一致性保障:多设备共享目标状态矩阵
- 延迟指标:端到端处理<100μs
09 演进方向
- CXL 3.0集成
利用CXL内存池实现TB级共享地址空间
+---------------------+
| GPU |
| 本地显存:80GB |
| CXL连接内存:1TB | ← 共享池
+---------------------+
- 存算一体架构
基于ReRAM的Processing-in-Memory单元:
- 减少90%数据搬运
- 突破"内存墙"限制
- 量子-经典混合计算
量子处理器作为协处理单元:
- 量子态数据通过UMA与经典设备交互
- 实现Shor算法等混合计算
10 开发建议
- 性能分析工具链:
- NVIDIA Nsight Compute:GPU内核分析
- Xilinx Vitis Analyzer:FPGA时序分析
- Intel VTune:CPU热点分析
- 调试技巧:
# 检查内存一致性
export CL_UNIFIED_MEMORY_DEBUG=1# 跟踪Kernel迁移
export SCHEDULER_LOG_LEVEL=3
- 最佳实践:
- 将频繁交互的数据置于CPU内存
- FPGA任务粒度>10μs才触发迁移
- 为每个设备保留15%本地缓存
当三维异构计算突破"数据孤岛"桎梏,统一内存架构正成为算力融合的神经中枢。随着CXL等新技术演进,我们有理由预见:未来计算系统将如人脑般无缝协同,GPU的并行暴力、CPU的灵活调度与FPGA的能效优势终将合而为一。
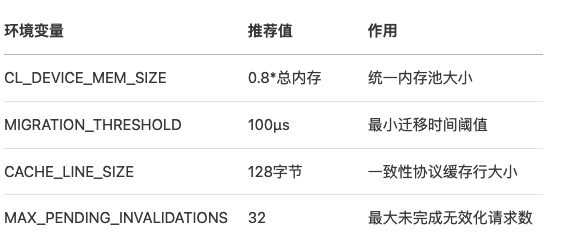
附录:关键参数配置表