如何做好公司网站建设广州网站建设公司哪个好
对比
对比维度及优缺点分析
| 对比维度 | LangChain(封装 FAISS) | 直接使用 FAISS |
|---|---|---|
| 易用性 | ✅ 高,提供高级封装,简化开发流程 | ❌ 中等,需要熟悉 FAISS API |
| 学习成本 | ✅ 低,适合快速开发 | ❌ 高,需要掌握 FAISS 的索引类型、添加/查询流程等 |
| 集成能力 | ✅ 强,天然支持 LLM、Prompt、Chain 等模块 | ❌ 弱,需手动集成 LLM 相关逻辑 |
| 封装程度 | ✅ 高,隐藏底层实现细节 | ✅ 低,需自己管理索引、内存、数据结构等 |
| 灵活性 | ❌ 有限,依赖 LangChain 提供的封装接口 | ✅ 高,可完全控制 FAISS 行为 |
| 性能优化 | ❌ 一般,封装可能带来额外开销 | ✅ 高,可针对特定场景进行优化 |
| 持久化支持 | ✅ 有,LangChain 提供了 save_local / load_local 方法 | ✅ 有,FAISS 也支持保存和加载索引文件 |
| 索引类型支持 | ✅ 有限(通常使用 IndexFlatL2) | ✅ 丰富(支持 IndexFlatL2、IVFPQ、HNSW 等) |
| 扩展性 | ✅ 高,可轻松对接其他向量数据库(如 Pinecone、Chroma) | ❌ 低,需手动切换数据库 |
| 部署难度 | ✅ 低,适合本地开发、小项目 | ✅ 中等,适合中大型项目或生产环境优化 |
| 调试与维护 | ✅ 简单,封装好日志、错误提示 | ❌ 复杂,需自行处理底层错误、内存问题等 |
典型使用场景对比
| 使用场景 | 推荐方式 | 说明 |
|---|---|---|
| 快速搭建一个本地向量数据库 | ✅ LangChain + FAISS | 适合开发、测试、教学 |
| 需要高性能、大规模向量检索 | ✅ 直接使用 FAISS | 可选择 IVFPQ、HNSW 等高效索引 |
| 与 LLM、Prompt、Chain 结合使用 | ✅ LangChain | LangChain 提供了统一接口,方便构建完整流程 |
| 需要切换向量数据库(如从 FAISS 切换到 Pinecone) | ✅ LangChain | 封装抽象,只需改配置 |
| 需要深度优化索引性能 | ✅ 直接使用 FAISS | 可灵活配置索引类型、量化方式等 |
| 生产环境部署 | ✅ LangChain + FAISS(简单场景) ✅ 直接使用 FAISS(复杂场景) | 根据规模和性能需求选择 |
本地搭建embedding模型(Qwen3-Embedding-0.6B)
本文向量提取均使用本地embedding模型
vllm下载
conda create -n myenv python=3.12 -y
conda activate myenv
pip install --upgrade uv
uv pip install vllm --torch-backend=auto -i https://pypi.tuna.tsinghua.edu.cn/simple
下载模型
pip install modelscope
mkdir models
modelscope download --model Qwen/Qwen3-Embedding-0.6B --local_dir /models/Qwen3-Embedding-8B
modelscope download --model Qwen/Qwen3-Embedding-0.6B --local_dir /models/Qwen3-Reranker-8B
启动命令
vllm serve Qwen/Qwen3-Embedding-0.6B
本地接口测试
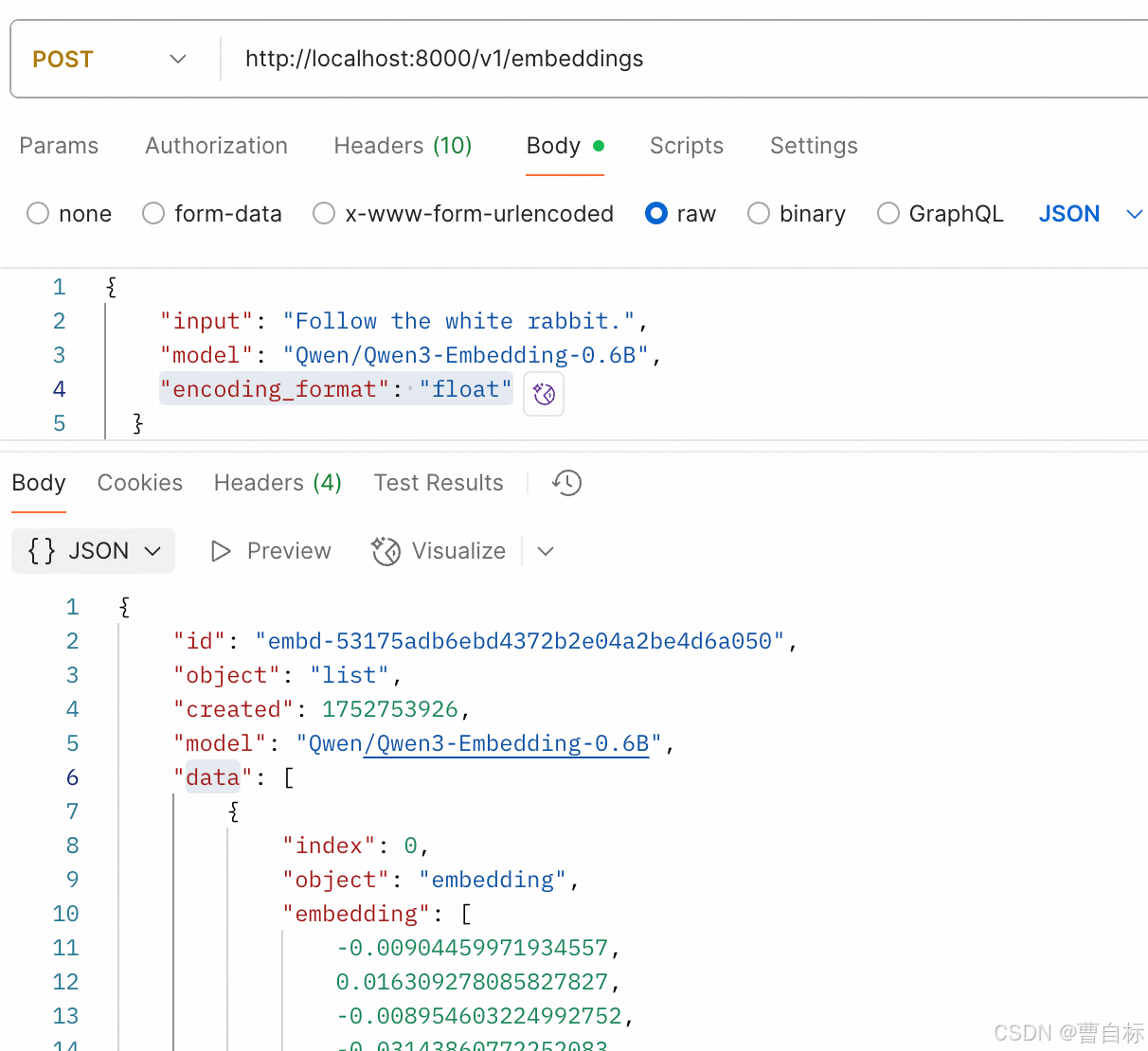
curl --location 'http://localhost:8000/v1/embeddings' \
--header 'Content-Type: application/json' \
--data '{"input": "Follow the white rabbit.","model": "Qwen/Qwen3-Embedding-0.6B","encoding_format": "float"}'
自封装本地embedding模型
class LocalEmbeddings(Embeddings):def __init__(self, api_url: str = "http://localhost:8000/v1/embeddings"):self.api_url = api_urldef embed_documents(self, texts: List[str]) -> List[List[float]]:payload = {"input": texts,"model": "Qwen/Qwen3-Embedding-0.6B", # 替换为你实际使用的模型名"encoding_format": "float"}response = requests.post(self.api_url, json=payload)if response.status_code != 200:raise Exception(f"API request failed with status code {response.status_code}: {response.text}")result = [item["embedding"] for item in response.json()["data"]]return resultdef embed_query(self, text: str) -> List[float]:return self.embed_documents([text])[0]
Langchain实现
安装faiss(https://github.com/facebookresearch/faiss/blob/main/INSTALL.md)
conda install -c pytorch faiss-cpu=1.11.0
进行向量存储和检索
from langchain.embeddings.base import Embeddings
import requests
from typing import List
from langchain_community.document_loaders import TextLoader
from langchain_community.vectorstores import FAISS
from langchain_text_splitters import RecursiveCharacterTextSplitter# 初始化本地 embeddings
embeddings = LocalEmbeddings()# 示例文本
# texts = ["这是一个测试句子", "这是另一个测试句子"]
#
# # 使用 embeddings 构建向量数据库
# vectorstore = FAISS.from_texts(texts=texts, embedding=embeddings)# 加载本地文档,并进行切分
raw_documents = TextLoader('xxx.txt').load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
print(len(documents))# 对切分后的文档进行提取特征和入库向量库
db = FAISS.from_documents(documents, embedding=embeddings)# 查询相似文本
query = "测试句子"
docs = db.similarity_search(query, 4)
print(docs)

langchain调用qwen文章参考:https://qwen.readthedocs.io/zh-cn/latest/framework/Langchain.html
Faiss实现
直接上代码
import faiss
from langchain.embeddings.base import Embeddings
import requests
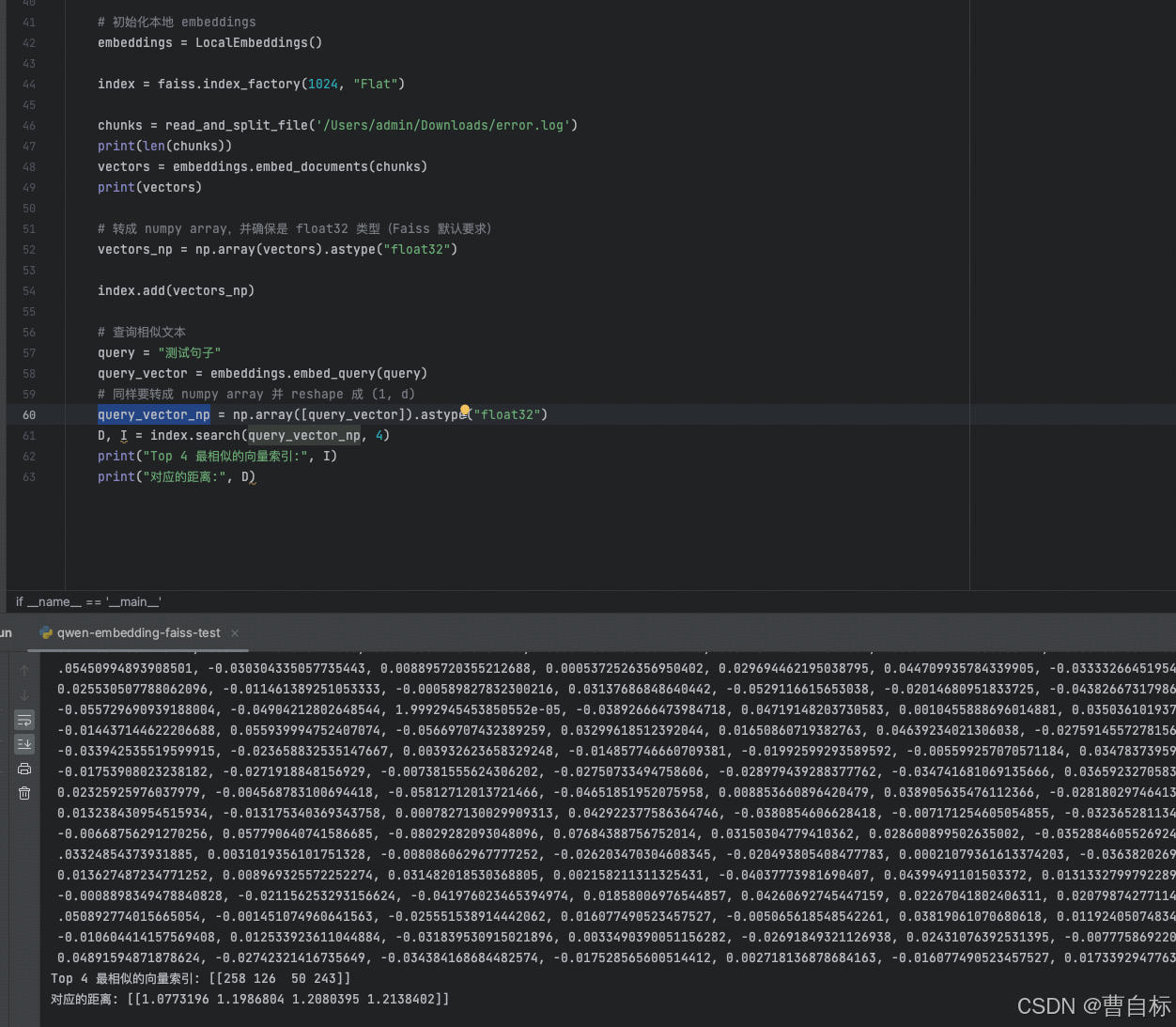
from typing import Listdef read_and_split_file(filepath, chunk_size=500):with open(filepath, 'r', encoding='utf-8') as file:data = file.read()# Split the text into chunks of 500 characters.chunks = [data[i:i + chunk_size] for i in range(0, len(data), chunk_size)]return chunks# 初始化本地 embeddings
embeddings = LocalEmbeddings()index = faiss.index_factory(1024, "Flat")chunks = read_and_split_file('/Users/admin/Downloads/error.log')
print(len(chunks))
vectors = embeddings.embed_documents(chunks)
print(vectors)# 转成 numpy array,并确保是 float32 类型(Faiss 默认要求)
vectors_np = np.array(vectors).astype("float32")index.add(vectors_np)# 查询相似文本
query = "测试句子"
query_vector = embeddings.embed_query(query)
# 同样要转成 numpy array 并 reshape 成 (1, d)
query_vector_np = np.array([query_vector]).astype("float32")
D, I = index.search(query_vector_np, 4)
print("Top 4 最相似的向量索引:", I)
print("对应的距离:", D)