莱芜网站建设资情况介绍做ppt找素材的网站
1.机器学习概览
1.1 什么是机器学习
机器学习是通过编程让计算机从数据中进行学习的科学。
1.2 为什么使用机器学习?
使用机器学习,是为了让计算机通过数据自动学习规律并进行预测或决策,无需显式编程规则。
1.3 机器学习系统的类型
1.3.1 监督/非监督学习
机器学习可以根据训练时监督的量和类型进行分类。主要有四类:监督学习、非监督学习、半监督学习和强化学习。
监督学习(分类、回归)、非监督学习(聚类、降维)。
1.3.2 批量和在线学习
批量学习(Batch Learning)是在收集到完整数据集后一次性训练模型,适用于数据静态、训练资源充足的场景。
在线学习(Online Learning)是模型接收数据流时逐条或小批量更新,适用于动态环境和实时预测任务。
1.3.3 基于实例 vs 基于模型学习
基于实例的学习(Instance-based Learning) 是直接记忆训练数据,在预测时通过比较新样本与已有实例的相似度来做出判断,代表算法有K近邻(KNN)等。
基于模型的学习(Model-based Learning) 是通过训练数据构建一个通用的预测模型,学习参数或结构以适应数据分布,代表算法有线性回归、决策树、神经网络等。
1.4 机器学习的主要挑战
* 训练数据量不足
* 没有代表性的训练数据
* 低质量数据
* 不相关的特征
* 过拟合训练数据
* 欠拟合训练数据
1.5 测试和确认
要评估模型在新样本上的表现,不能仅依赖训练误差,而要使用测试集来估计其推广误差(对新样本的错误率称作推广错误)。通常将数据集按 80% 训练、20% 测试 进行划分。若训练误差低而测试误差高,说明模型发生了过拟合。
当需要比较多个模型或调整超参数(如正则化强度)时,直接在测试集上反复优化会导致对测试集过拟合,从而低估实际误差。
为避免这一问题,应引入验证集,专用于调参,测试集仅用于最终评估。为了最大化数据利用,通常采用交叉验证:将训练集划分为多个子集,轮流训练和验证,选出最佳模型后,再用全部训练集重新训练,并在测试集上评估最终性能。
4.训练模型
4.1 线性回归
首先我们将以一个简单的线性回归模型为例,讨论两种不同的训练方法来得到模型的最优解:
-
直接使用封闭方程进行求根运算,得到模型在当前训练集上的最优参数(即在训练集上使损失函数达到最小值的模型参数),本质上就是最小二乘法(Least Squares)在线性回归中的具体实现形式。
-
使用迭代优化方法:梯度下降(GD),在训练集上,它可以逐渐调整模型参数以获得最小的损失函数,最终,参数会收敛到和第一种方法相同的的值。同时,我们也会介绍一些梯度下降的变体形式:批量梯度下降(Batch GD)、小批量梯度下降(Mini-batch GD)、随机梯度下降(Stochastic GD),在第二部分的神经网络部分,我们会多次使用它们。
-

4.2 梯度下降
梯度下降是一种通用的优化算法,其核心思想是:通过不断迭代,沿着使损失函数下降最快的方向(即负梯度方向)调整参数,直到找到损失函数的最小值。
可以类比为:人在浓雾中下山,只能感知脚下的坡度,逐步往坡度最陡的方向走,最终走到山底。
算法从一个随机初始参数开始,每次计算损失函数的梯度,并更新参数。过程持续,直到梯度接近 0,表示已接近最低点,即模型收敛。
在梯度下降中一个重要的参数是步长,超参数学习率的值决定了步长的大小。如果学习率太小,必须经过多次迭代,算法才能收敛,这是非常耗时的。
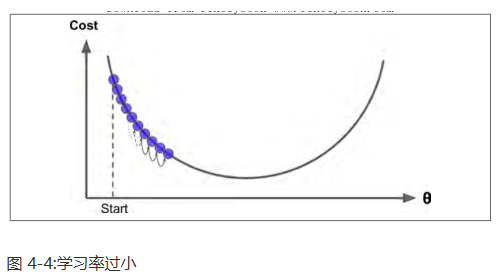
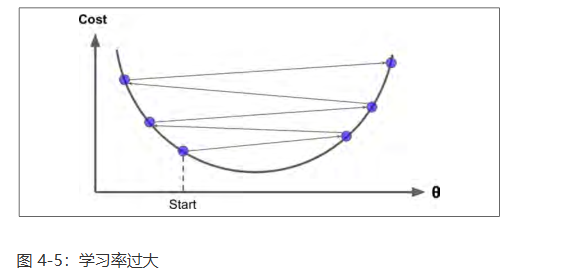
另一方面,如果学习率太大,你将跳过最低点,到达山谷的另一面,可能下一次的值比上一次还要大。这可能使的算法是发散的,函数值变得越来越大,永远不可能找到一个好的答案。
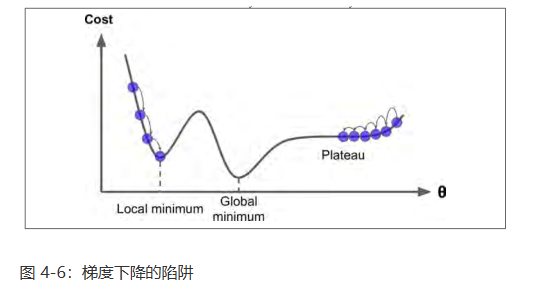
最后,并不是所有的损失函数看起来都像一个规则的碗。它们可能是洞,山脊,高原和各种不规则的地形,使它们收敛到最小值非常的困难。 图 4-6 显示了梯度下降的两个主要挑战:如果随机初始值选在了图像的左侧,则它将收敛到局部最小值,这个值要比全局最小值要大。 如果它从右侧开始,那么跨越高原将需要很长时间,如果你早早地结束训练,你将永远到不了全局最小值。
4.5 线性模型的正则化
降低模型的过拟合的好方法是正则化这个模型(即限制它):模型有越少的自由度,就越难以拟合数据。例如,正则化一个多项式模型,一个简单的方法就是减少多项式的阶数。
对于一个线性模型,正则化的典型实现就是约束模型中参数的权重。 接下来我们将介绍三种不同约束权重的方法:Ridge 回归,Lasso 回归和 Elastic Net。
4.6 逻辑回归
逻辑回归是一种用于二分类问题的统计模型,用来预测某个事件发生的概率,输出结果在 0 到 1 之间。
虽然名字叫“回归”,但逻辑回归实际上是一种分类算法。


5.支持向量机
SVM、SVR原理简单介绍-CSDN博客
6.决策树
决策树是一种树形结构的分类与回归模型,它通过一系列的“if-then”规则对样本进行划分,直到叶节点给出预测结果。
7.随机森林
随机森林是由多棵决策树构成的集成学习方法。每棵树都在随机选择的训练数据子集和特征子集上训练,最终通过投票(分类)或平均(回归)给出预测结果。
8.降维
降维就是把高维数据(有很多特征)压缩成更少维度的数据表示,同时尽量保留原始数据的重要信息。
想象你正在看一本100页的书(每页代表一个特征),但其实这本书大部分内容都在重复表达同一个观点。降维就是:
用一句话概括这本书的主要意思 —— 你丢弃了冗余内容,但保留了精华。
10.神经网络
神经网络是一种模拟人脑神经元结构的算法模型,广泛用于图像识别、语音处理、自然语言理解、预测等任务。


