济南优化网站关键词商品网站模板
我一直对数据中的模式很感兴趣——只要你提出正确的问题,混乱和原始的东西就可以变得清晰。所以当我遇到一个结合遥感、时间序列和分类的任务时,我觉得这是挑战自己和成长的完美方式。
这与提交或排行榜无关,而是关于探索现实世界的数据、试验想法,以及看看我能在多大程度上推动我对机器学习的理解。
解码任务:根据 NDVI 时间序列进行土地覆盖
问题:使用卫星获取的 NDVI 数据对土地覆盖类型(如森林、草地、水、果园)进行分类。
NDVI,即归一化差异植被指数,定义为:
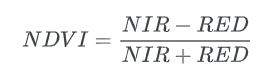
在哪里:
- NIR = 近红外反射
- RED = 红色反射率
它是一种反映植被健康状况的遥感指标。绿色、多叶区域显示较高的 NDVI;贫瘠或水域则较低。该数据集为每个位置提供了 27 个 NDVI 观测值,跨越两年——实际上,这是植被行为的时间序列。
每一行看起来都像这样:
- 身份证
- 27个时间点的NDVI
- 地面真实标签:{水、不透水、农场、森林、草地、果园} 之一
但没有任何东西是干净的。
数据并不完美——但正因如此,它才成为学习的完美工具
首先:数据缺失。大量的数据。云层遮挡了卫星视野,整个时间戳都变成了空白。
第二:嘈杂的标签,因为它们来自 openstreetmap 多边形——众包的,并不总是精确的。
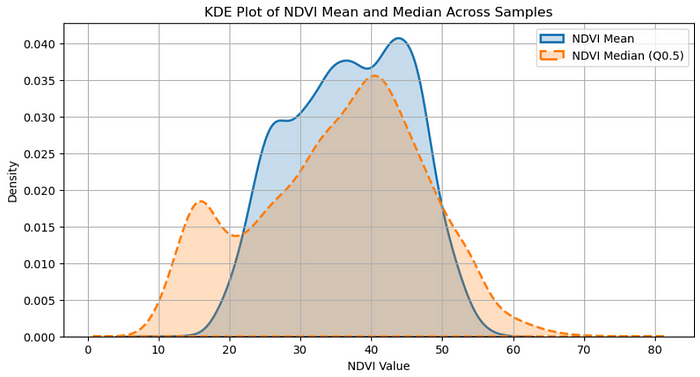
“森林”类别的 NDVI 值分布
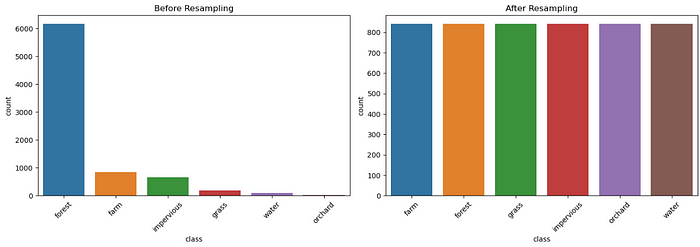
第三:严重的类别不平衡。几乎 75% 的样本被标记为“森林”,而其他样本的实例则少得多。
我很早就意识到,这并不是要向数据抛出一个花哨的模型,而是要设计特征、构建稳健性,以及学习如何像数据科学家一样思考。
预处理:仔细填补空白
我从简单的开始:用中位数插补来处理缺失值。平均值和 KNN 插补方法要么过于平滑,要么增加了偏差。而中位数让我可以保留每个样本中的季节性故事,而不会扭曲信号。
<span style="color:rgba(0, 0, 0, 0.8)"><span style="background-color:#ffffff"><span style="background-color:#f9f9f9"><span style="color:#242424">df = df.fillna(df.median(numeric_only = <span style="color:#aa0d91">True</span>))</span></span></span></span>对于类别不平衡,我对多数类别(森林)进行了欠采样,然后应用SMOTE对果园或水等少数类别进行上采样。这给了我一个更加平衡和易于学习的数据集,即不会让森林主导学习的数据集。
将时间序列转化为模型可以使用的内容
原始 NDVI 值只是数字。我需要它们来表达模式语言。
因此我设计了每个特征,旨在捕捉植被随时间的变化:
- 基本属性:
ndvi_mean,,,,ndvi_stdndvi_minndvi_maxndvi_range - 季节性:夏季与冬季的平均 NDVI 及其差异
- 趋势检测:线性回归斜率(
ndvi_trend) - 局部变化:滚动平均值和标准差以减少噪音并放大信号
- 变化指标:一阶差分(
ndvi_diff)和绿化率
将序列转化为汇总统计数据有助于反映现实世界的行为。
建模:从简单到强大
我从逻辑回归开始。它易于解释,速度快,并且是一个很好的基准。令人惊讶的是,经过特征工程后,它的表现相当不错,f1 分数为 0.78,准确率为 85%。
接下来我添加了随机森林,这对于嘈杂的数据非常有用并且仍然可以解释。
最后,我运行了XGBoost,使用网格搜索来调整超参数。
快速查看结果
在干净的、保留的测试拆分上:
logistic regression → macro f1 ≈ 0.78
random forest → macro f1 ≈ 0.94
xgboost → macro f1 ≈ 0.96准确度很高,但由于类别不平衡,宏 f1 分数在这里更重要。令人惊讶的是,由于有效的特征工程,即使是像逻辑回归这样更简单的模型也能保持其地位。
我使用了特征重要性图(来自随机森林和 xgboost)来查看最突出的特征。一致的顶级特征是:
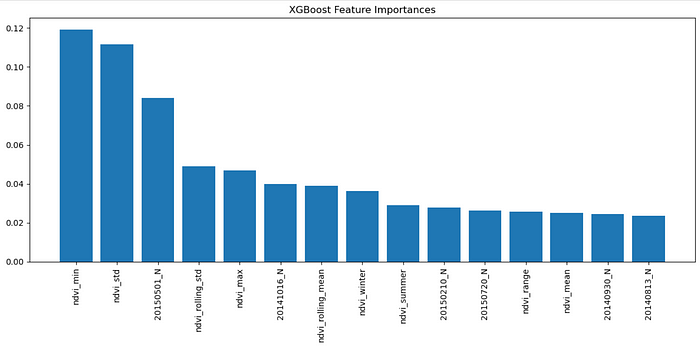
ndvi_greening_rateseason_diffndvi_trendrolling_std
这些特征不仅仅是数学上的,而且代表了真实的季节性植被行为。看到这些特征反映在模型的首选中,感觉很有说服力。
这教会了我什么
这不仅仅是建立一个模型。这是一门速成课程:
- 数据整理和归纳
- 时间特征工程
- 理解不平衡学习
- 选择和调整模型
- 使用特征重要性和视觉验证来解释结果
我了解到,即使数据混乱,经过深思熟虑的小步骤也能累积起来。如果做得正确,特征工程可以与复杂性竞争。
我接下来想尝试什么
我很好奇想了解更多:
- 直接在 NDVI 序列上使用1d 卷积或 LSTM
- 应用信号平滑(如 Savitzky-Golay)
- 结合空间背景——这个数据点在地理上位于哪里?
- 甚至可以构建一个小型 Web 应用程序,根据用户上传的 NDVI 数据预测土地覆盖类型