one dirve做网站如何自建商城和电商平台
加州伯克利发布的超视觉多感知模态融合(FuSe, Fuse Heterogeneous Sensory Data)模型,基于视觉、触觉、听觉、本体及语言等模态,利用自然语言跨模态对齐(Cross-Modal Grounding)优调视觉语言动作等通用模型,提高模型任务成功率。
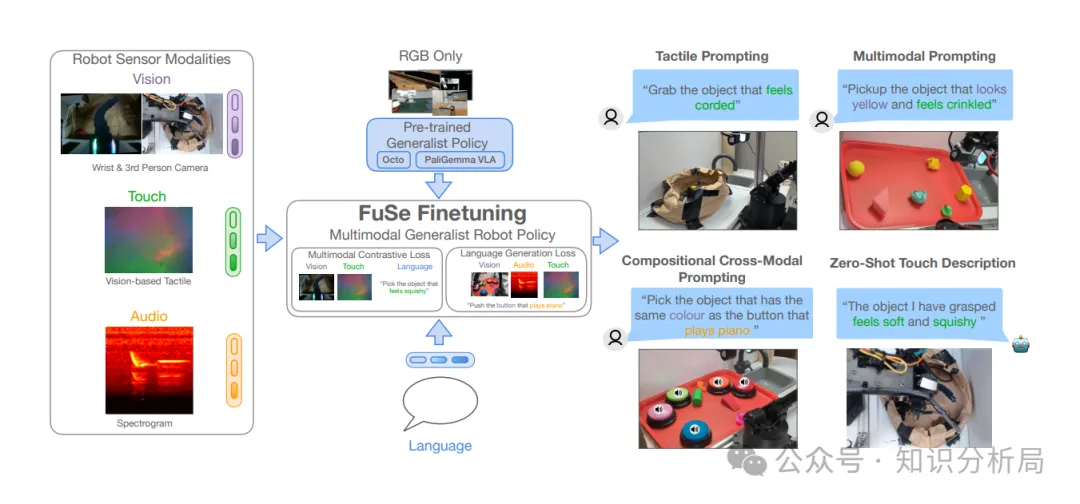
总体框架
基于预训练的Octo模型或PaliGemma视觉语言动作模型,利用机器人第三方视角相机及腕部相机图像,触觉感知图像,麦克风语谱图像(Spectrogram)及自然语言指令等,通过多模态对比损失、语言生成损失及动作损失,进行模型优调,实现自然语言指令或图像目标任务。
[图片来自网络]
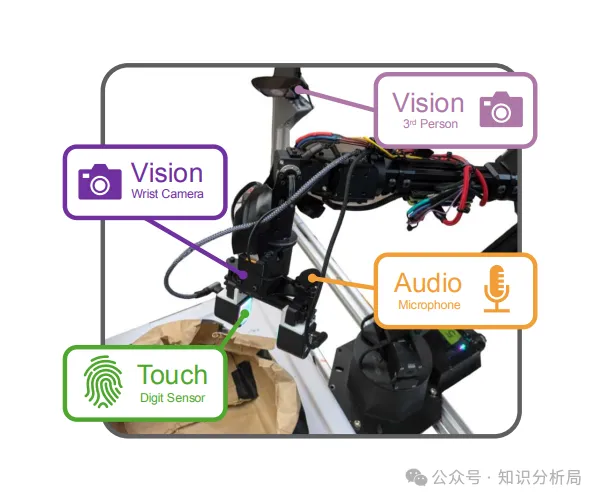
一、硬件环境
[图片来自网络]
机械臂, WidowX 250 6-DoF。
第三方视角相机, RGB相机。
腕部相机, RGB相机。
触觉传感器, DIGIT,2个,分置于终端钳。
麦克风, 标准型。
惯性测量单元, 9-DoF IMU。
二、训练环境及数据
TPU, Google v5e-128 TPU pod。
机器人任务轨迹收集器, Meta Quest 2 VR headset。
任务数据集,基于遥操作收集大概3万条轨迹。
每条轨迹通过模板化的语言指令(Templated Language Instruction)标记。
三类任务,两类抓取任务具备视觉、触觉及动作数据,一类具备声音的按钮任务。触觉观测信息去掉静态背景图。音频包括最近1秒的麦克风采样数据,频率44K。
三、机器学习框架
Google Research 发布的 JAX,基于自动梯度(Autograd)及线代加速器(XLA, Accelerated Linear Algebra)、自动向量实现自动微分(Automatic Differentiation)、实时编译(JIT, Just-In-Time)及并行计算,提高基于TPU等的大规模、高性能计算。不过易用性似不好。
四、触觉传感器(DIGIT)
GelSight DIGIT基于视觉的触觉传感器,利用相机捕获弹性材料的形变图像来测量接触力(Contact Forces).
[图片来自网络]
拆解图,左至右,弹性材料(Elastomer),窗(Acrylic Window),卡座(Snap-Fit Holder),照明电路板(Lighting PCB),外壳(Plastic Housing),相机电路板(Camera PCB),背壳(Back Housing)。
超态模型
一、模型框架
[图片来自网络]
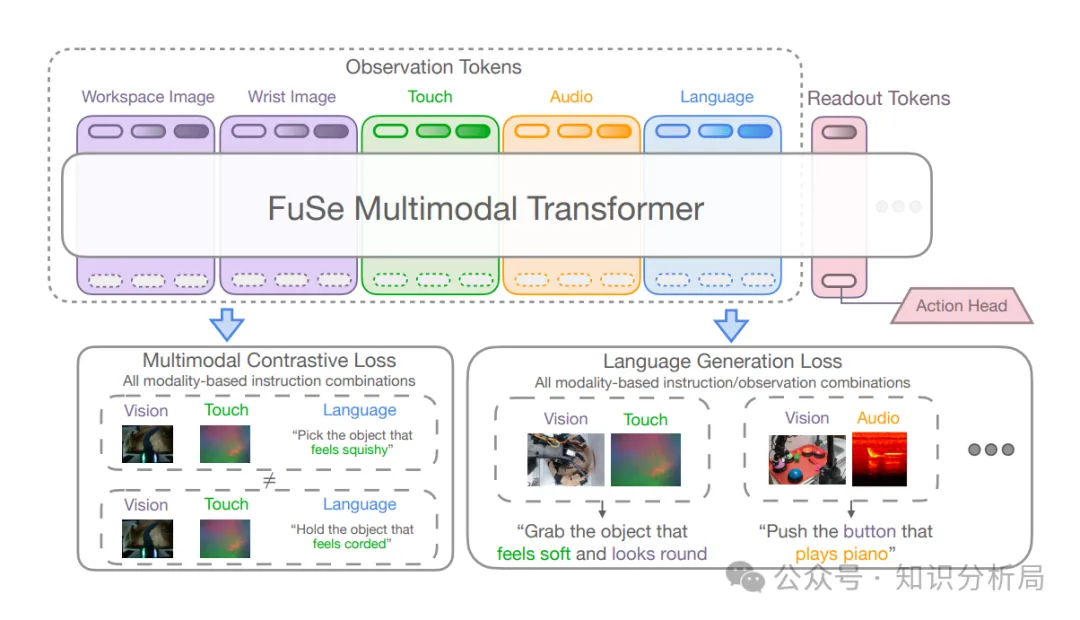
框架图,顶部,自然语言标记化作任务标记(原图似未正确表示);相机图像、触觉图像、语音谱图标记化作观测标记(Observation Tokens);取读标记(Readout Tokens)添加到变换器输入,用于注意此前任务及观测标记;任务标记、观测标记及取读标记基于遮挡码方法实现注意力规则,通过多模态编码变换器生成注意力嵌量;底部,基于动作头(Action Head)生成动作; 基于多模态对比损失对齐视触觉与语言指令,基于语言生成损失对齐多模态与语言语义,基于动作损失对齐多模态与动作; 基于注意力嵌量,利用累加损失训练模型。
取读标记(Readout Tokens)作用类似基于变换器的双向编码器表征模型(BERT, Bidirectional Encoders Representations From Transformers)中的[CLS]标记(Token)。可存在多个取读(Readout),一个取读可对应多个标记(Tokens)。取读标记实例化时等价于位置嵌量。
动作头(Action Head)基于标准去噪扩散概率模型(DDPM, Denoising Diffusion Probabilistic Models),利用变换器生成的动作取读(Action Readout)注意力嵌量等信息学习去噪神经网络,通过对标准高斯噪声多步去噪预测动作。
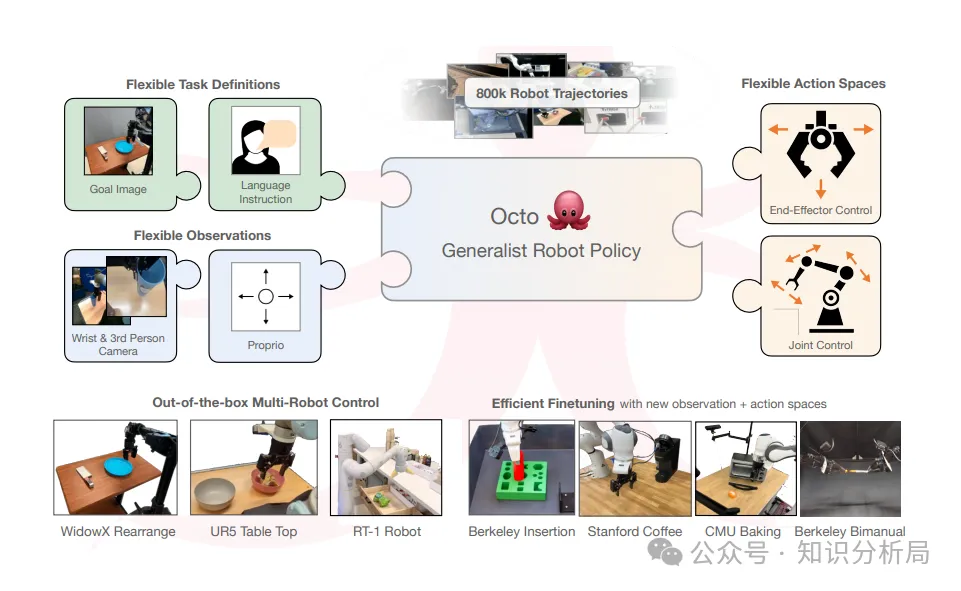
二、多模态模型Octo
基于视觉变换器(ViT, Vision Transformer)及开源具身数据集(Open X-Embodiment Dataset)预训练实现的机器人通用控制策略模型。
[图片来自网络]
模型框架定义。
[图片来自网络]
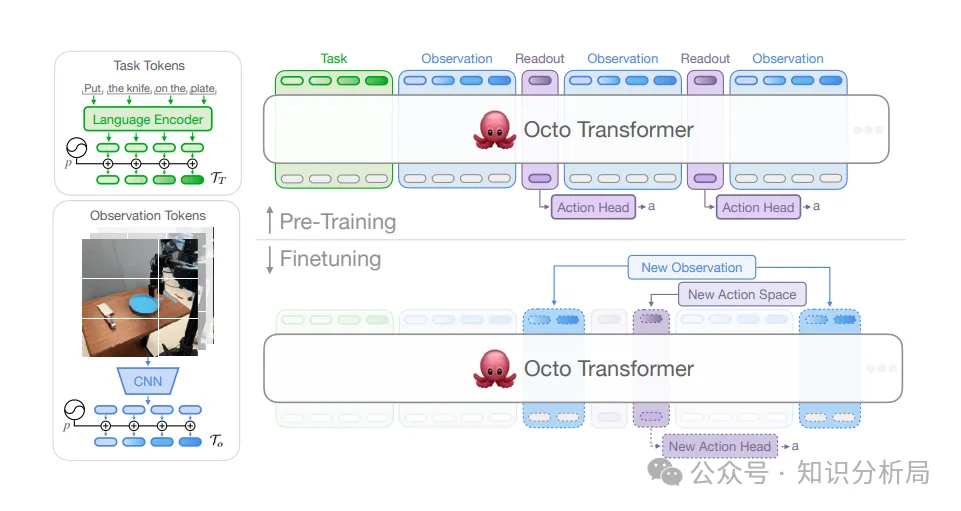
框架图,左侧,分别基于预训练语言模型与轻型卷积神经网络标记化任务及观测信息;顶部,预训练框架,任务及观测标记序列通过变换器骨干网络生成取读标记(Readout Tokens);取读标记基于动作头(Action Head)生成动作;底部,优调框架,基于变换器的块注意力结构(Block-Wise Attention Structure),优调过程中可添加或移走输入、输出量,比方,新的观测量或动作空间。
三、编码器
1、自然语言编码器
T5-Base变换器模型。
2、图像编码器
卷积栈(Shallow Convolution Stack)。
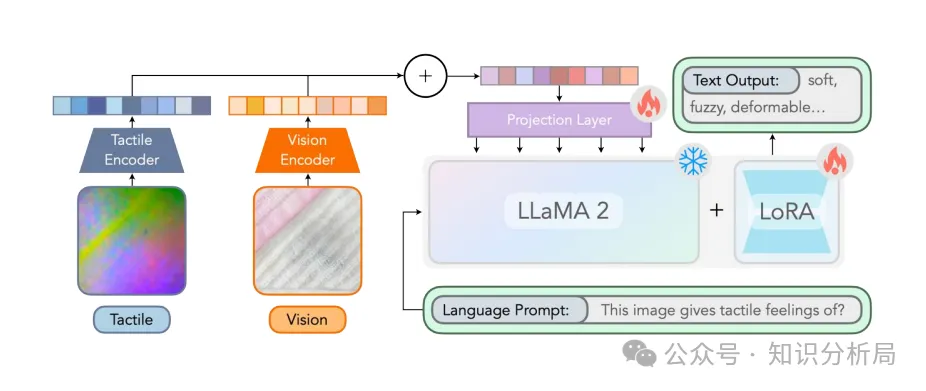
3、触觉编码器(Tactile Encoder)
基于每对模态之间,比方视觉语言、触觉语言及触觉视觉的对比损失训练模型。
[图片来自网络]
4、音频编码器(Audio Encoder)
基于快速傅立叶变换(FFT, Fast Fourier Transform)得到语谱图,利用ResNet26编码器进行编码。
模型训练
参数更新基于余弦学习率调度器(Cosine Learning Rate Scheduler)。
一、标记序列
标记序列定义。
[task, observation 0, observation 1, observation 2, …]
标记序列示例。
[ , <t=0 “image_primary” tokens>, <t=0 “image_wrist” tokens>, <t=0 readout_action tokens>, … <t=1 “image_primary” tokens>, <t=1 “image_wrist” tokens>, <t=1 readout_action tokens>, … <t=2 “image_primary” tokens>, <t=2 “image_wrist” tokens>, <t=2 readout_action tokens>, … …]
二、遮挡规则
Octo模型是块因果变换器(Block-Wise Casual Transformer),每个时步只注意当前及此前时步。
观测标记注意任务标记,当前及此前时步的所有观测标记。
取读标记只注意该标记前的标记序列。
三、损失函数
[图片来自网络]
优调过程的损失函数程序实现。
def loss_fn(params, batch, rng, train=True, use_action_loss=True, use_contrastive_loss=True, use_generative_loss=True, **kwargs): info = {} loss = 0.0 bound_module = model.module.bind({“params”: params}, rngs={“dropout”: rng}) if use_action_loss: ac_loss, ac_metrics = loss_fn_action(bound_module, batch, train, **kwargs) info.update(ac_metrics) loss += ac_loss if use_contrastive_loss: lang_loss, lang_metrics = loss_fn_contrastive(bound_module, batch, train, **kwargs) info.update(lang_metrics) loss += lang_loss if use_generative_loss: gen_loss, gen_metrics = loss_fn_generative(model=model, params=params, rng=rng, batch=batch, **kwargs) info.update(gen_metrics) loss += gen_loss info[‘loss_total’] = loss return loss, info
浅析: Nvidia GR00T模型及Physical Intelligence模型,基于动作状态,通过扩散变换器或流匹配生成未来动作;利用视觉语言模态注意力嵌量直接调控动作生成;利用行为克隆进行总对齐。
超视觉模态模型基于多模态图像及语言,通过编码变换器(Transformer Encoder)及标准扩散模型进行嵌量化及生成动作;基于行为克隆对齐的同时,利用对比损失及生成损失进行嵌量对齐,间接调控动作生成。
超视觉模态模型框架似过冗,多模态注意力嵌量直接调控扩散变换器或流匹配模型可能是更适合的方法。
基于触觉、听觉等模态信息及遮挡码注意力规则可提供更全面的语义对齐能力;同时,利于基于多样化的环境反馈实现机器人操作控制约束条件。
新发布的触觉传感器DIGIT360可实现全向感知、近千万级感素(Taxels),空间特征分辨率可到7微米,法向力(Normal Forces)及切向力(Shear Forces)分辨率可到近1毫牛,可感知振动、热,甚至异味。
基于U-Net骨干神经网络的标准去噪扩散概率模型应可替换成扩散变换器(DiT, Diffusion Transformer)或流匹配模型,以提高性能或平滑性。
人形机器人基于惯性测量单元的超视觉模态注意力对齐,似有利于实现多任务操作时的整机平衡。
参考:
Beyond Sight: Finetuning Generalist Robot Policies with Heterogeneous Sensors via Language Grounding.
A Touch, Vision, and Language Dataset for Multimodal Alignment.
Octo: An Open-Source Generalist Robot Policy.
DIGIT: A Novel Design for a Low-Cost Compact High-Resolution Tactile Sensor with Application to In-Hand Manipulation.
Digitizing Touch with an Artificial Multimodal Fingertip.