济南网站制作的公司青海网站如何建设
25年3月来自华中科技和小米电动汽车的论文“ORION: A Holistic End-to-End Autonomous Driving Framework by Vision-Language Instructed Action Generation”。
由于因果推理能力有限,端到端 (E2E) 自动驾驶方法仍然难以在交互式闭环评估中做出正确决策。当前的方法试图利用视觉-语言模型 (VLM) 强大的理解和推理能力来解决这一难题。然而,由于语义推理空间和动作空间中纯数值轨迹输出之间的差距,很少有用于 E2E 方法的 VLM 在闭环评估中表现良好。为了解决这个问题,本文提出 ORION,一个通过视觉-语言指令动作生成的整体 E2E 自动驾驶框架.ORION 独特地结合 QT-Former 来聚合长期历史上下文,大语言模型 (LLM) 用于驾驶场景推理,以及生成规划器用于精确轨迹预测。 ORION 进一步协调推理空间和动作空间,从而为视觉问答 (VQA) 和规划任务实现统一的端到端优化。其方法在 Bench2Drive 挑战数据集上取得令人印象深刻的闭环性能:77.74 的驾驶分数 (DS) 和 54.62% 的成功率 (SR),远超当前最先进 (SOTA) 方法,DS 和 SR 分别高达 14.28 和 19.61%。
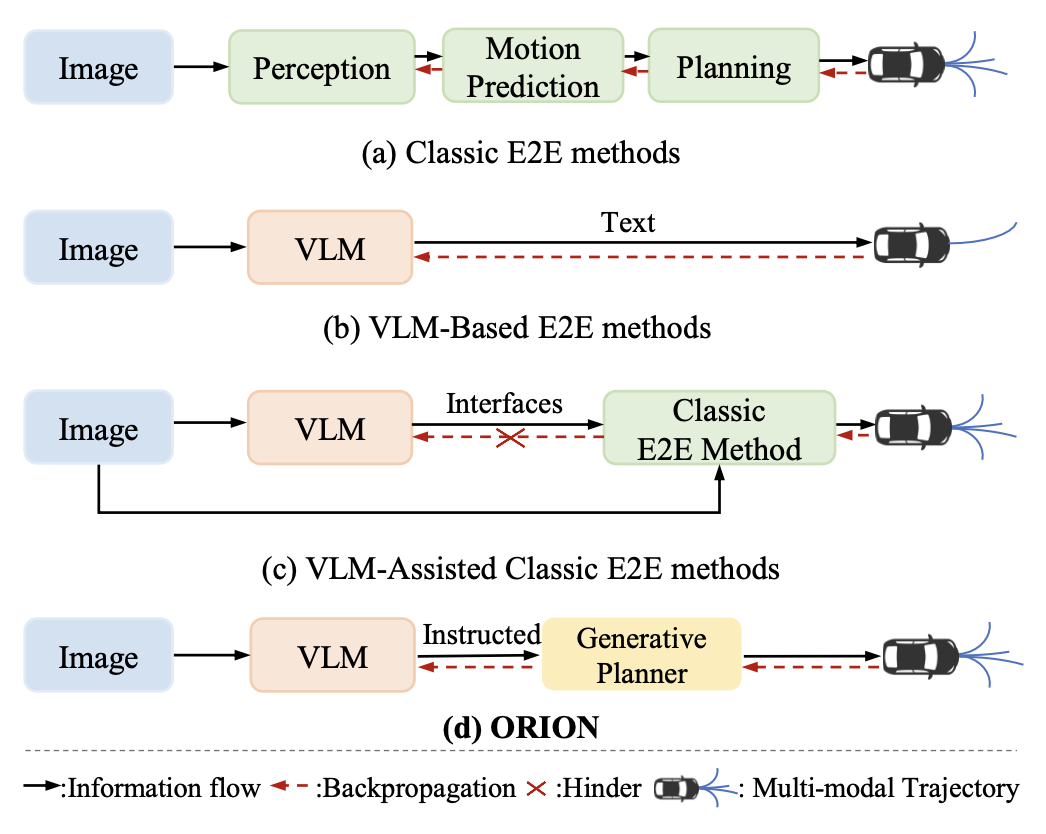
如图所示不同 E2E 范式的比较:(a-)传统端到端方法;(b-)基于 VLM 的端到端方法;(c-)VLM-辅助的经典端到端方法;(d-)ORION方法。ORION 框架通过生成规划器建立推理和动作空间之间可微分的连接。
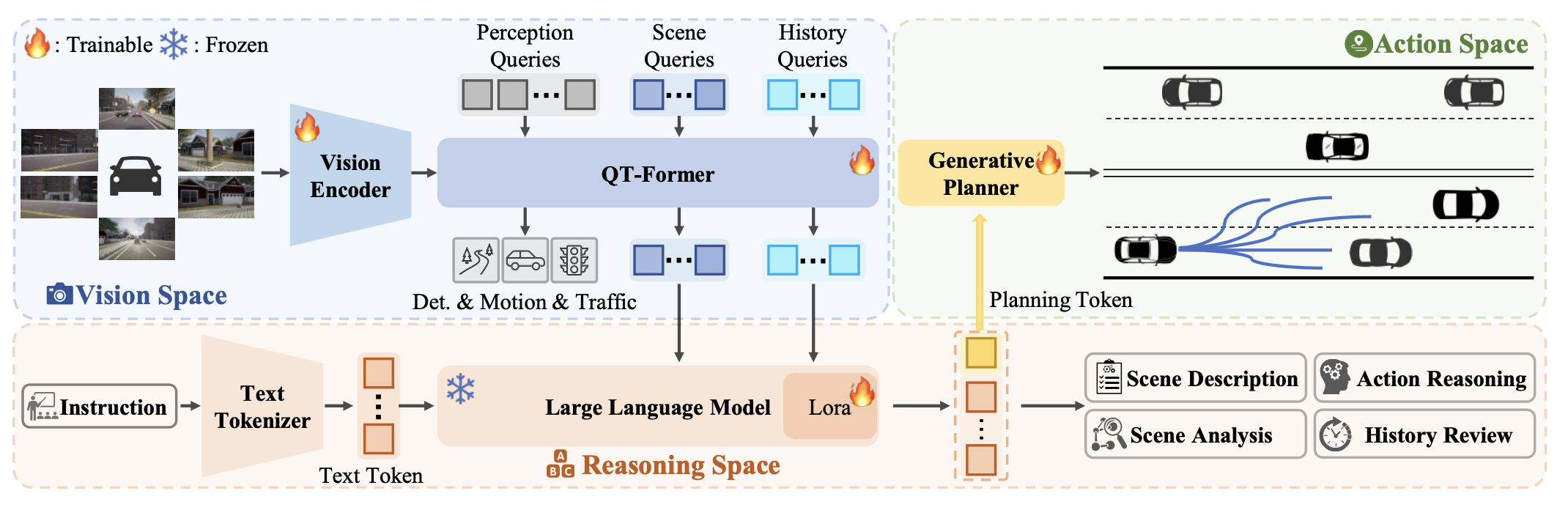
本文提出一个由视觉-语言模型指令动作生成的整体端到端自动驾驶框架,称为 ORION。ORION 的流程如图所示。具体而言,给定当前场景的多视角图像,ORION 首先使用视觉编码器对图像 tokens 进行编码。然后,QT-Former利用各种查询来聚合长期视觉上下文、压缩图像 tokens 并感知交通元素。随后,LLM 将压缩的场景特征和历史视觉信息与用户指令相结合,执行各种理解和推理任务并生成规划 tokens。
最后,生成规划器连接 LLM 的推理空间和轨迹的动作空间,预测由规划 tokens 决定的多模态轨迹。 ORION 通过这些核心组件有效地协调视觉-推理-行动空间,实现统一空间中场景理解和轨迹生成的协同优化。
QT-Former
为了在压缩和提取来自视觉编码器多视角图像特征 F_m 的同时,实现长期信息建模,引入基于查询的时间模块 QT-Former,如图所示。具体而言,借鉴 Q-Former3D [59],首先设置两类可学习的查询:场景查询 Q_s 和感知查询 Q_p,其中 N_s 和 N_p 分别为场景查询和感知查询的数量,C_q 为查询通道。Q_s 和 Q_p 通过自注意 (SA) 进行处理以交换信息。然后,它们在交叉注意 (CA) 模块中与具有 3D 位置编码 [37] P_m 的图像特征 F_m 进行交互。之后,感知查询被输入到多个辅助头中,用于目标检测(例如,关键目标和车道)、交通状态和动态智体的运动预测。场景查询充当表示当前场景关键信息的 tokens。
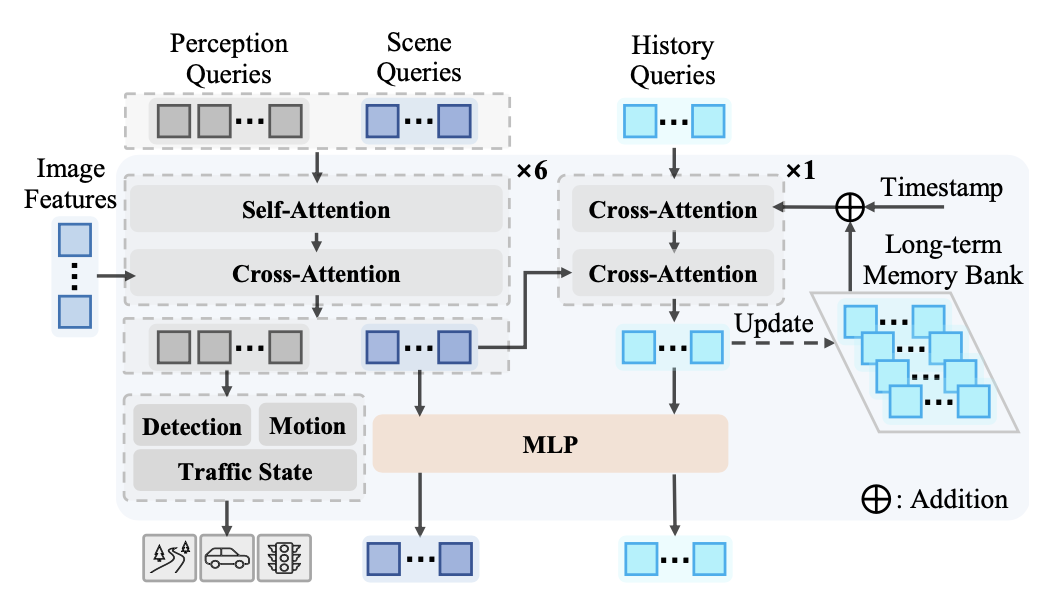
此外,用一组历史查询 Q_h 和一个长期记忆库 M 来高效地检索和存储重要的历史信息(例如,先前的路况和自我状态),其中 N_h 是历史查询的数量,n 是最大历史帧长度。利用 Q_h 通过一个 CA 块提取 M 中带有相对时间戳嵌入 P_t 的前帧查询。然后,Q_h 与另一个 CA 块中的当前场景特征 Q_s 进行交互,从而提取与当前场景相关的细节。
随后,更新后的历史查询 Qˆ_h 按照先进先出 (FIFO) 替换策略存储在记忆 M 中。
虽然一些方法 [51, 58] 也利用记忆存储先前的信息,但它们通常仅存储压缩的历史信息,而没有指导提取当前场景信息。因此,初始化少量历史查询,以进一步提取与历史信息最密切相关的当前场景特征,从而增强模型的长期记忆能力。
最后,利用一个双层多层感知器 (MLP) 将更新后的历史查询 Qˆ_h 和当前场景特征 Q_s 转换为 LLM 推理空间中的历史 tokens x_h 和场景 tokens x_s。
大语言模型
LLM 在其框架中至关重要,因为对当前驾驶场景进行高质量的推理,对于指导生成式规划器在行动空间中生成合理的轨迹至关重要。
用户指令首先由文本 token 化器编码为语言 token x_q,其中 L 为 token 长度,C 为 LLM 的维度。然后,场景token x_s 和历史 token x_h 与语言 token x_q 组合并输入 LLM。
借助 LLM 丰富的世界知识和卓越的推理能力,ORION 可以在驾驶场景中执行各种基于文本的理解和推理任务,包括场景描述、历史信息回顾、场景分析和动作推理。同时,其设计一个规划问答模板,其中 LLM 带有一个特殊的规划 token s,作为最终的问答,将整个驾驶场景的理解和推理上下文积累到 s 中,正式写为:s ∼ p(s|x_s, x_h, x_q, x_a),其中 x_a 表示 LLM 的生成答案。规划 token s 的嵌入将作为控制轨迹生成的条件。
然而,在闭环仿真环境中仍然缺乏高质量的 VQA 注释来训练 LLM 全面理解驾驶场景。因此,通过由 Qwen2-VL [57] 驱动的全自动 VQA 注释流程扩展 Bench2Drive 数据集,并提出自己的 VQA 数据集 Chat-B2D,希望进一步推动 VLM 在闭环仿真领域的研究。
生成式规划器
生成式模型 [14, 28, 48] 可以通过学习数据分布来有效地捕捉数据的内在特征。最近的研究 [5, 38, 47] 证明了不同模态数据的潜空间之间存在语义相关性,调整一个模态空间的分布参数可以精确控制另一个模态空间的生成过程。
受生成式领域的启发,本文引入一个生成式规划器来弥合推理和动作空间之间的差距。具体而言,将动作空间中的当前轨迹 a 表示为条件概率分布 p(a|s),其中 s 是规划 tokens。为了构造 p(a|s),生成领域有许多优秀的方法(例如变分自编码器 (VAE) [28] 和扩散模型 [48])。
由于 VLM 的推理空间和轨迹的动作空间在分布上存在本质区别,使用 VAE [28] 模型将它们在高斯分布中对齐。采用两层 MLP 将状态 s 和真实轨迹 t 投影到潜空间中的高斯变量 z 中。
然后,用 Kullback-Leibler 散度损失来强制执行分布匹配。最后,使用 GenAD [70] 中的 GRU 解码器从潜空间 z 解码轨迹。注:本文 VAE 函数与 GenAD 中的 VAE 不同。其仅使用从自身车辆视角在推理空间中编码的单个 token 作为输入,旨在弥合推理空间和动作空间之间的差距。相比之下,后者利用在 BEV 空间中编码的所有智体特征作为输入,旨在学习自车和其他智体高度结构化轨迹的特定模式。
此外,也还尝试用其他生成模型(例如用于轨迹生成的扩散模型)替代 VAE。得益于所提出的方法,通过潜空间中的分布学习来弥合推理和动作空间之间的差距,该框架与其他方法相比仍然表现出优异的性能。
训练目标
对于所提出的 QT-Former 的检测任务,检测损失定义为 L_det = L_cls + L_reg,其中 L_cls 为焦点损失 [34],L_reg 为 L1 损失。对于交通状态和运动预测,损失分别定义为 L_tra 和 L_m = L_mcls + L_mreg,其中 L_tra 和 L_mcls 为焦点损失,L_mreg 为 L1 损失。
对于 LLM,利用自回归交叉熵损失 L_ce。对于框架中的生成规划器,L_vae 是 Kullback-Leibler 散度损失,用于对齐推理空间和动作空间。遵循 VAD [25],采用碰撞损失 L_col、边界损失 L_bd 和 MSE 损失 L_mse 进行规划预测。
模型设置。与 Bench2Drive 上的经典 E2E 基线 [18, 25, 70] 一致,ORION 是一种完全无需高清地图的方法,仅使用导航指令 (NC) 作为轨迹预测的输入条件,而非车道中心(即目标点,TP)的位置。ORION 是一种无需锚点的方法,输出 6 种模式轨迹预测,分别对应于 Bench2Drive 中定义的 6 个 NC。
训练过程。所有实验均在 32 块 NVIDIA A800 GPU(配备 80 GB 内存)上进行。遵循 Omnidrive [59] 的方法,采用 EVA-02-L [12] 作为视觉编码器。 ORION 采用 Vicuna v1.5 [69] 版本,并使用 LoRA [16] 进行微调,秩维度和 alpha 均设置为 16。场景、感知和历史查询的默认数量分别为 512、600 和 16。将记忆库的存储帧数 n 设置为 16。训练期间,会对输入图像进行数据增强,首先将图像调整为 640 × 640 的分辨率。
标注流水线。如图所示,自动注释流程包含三个步骤:
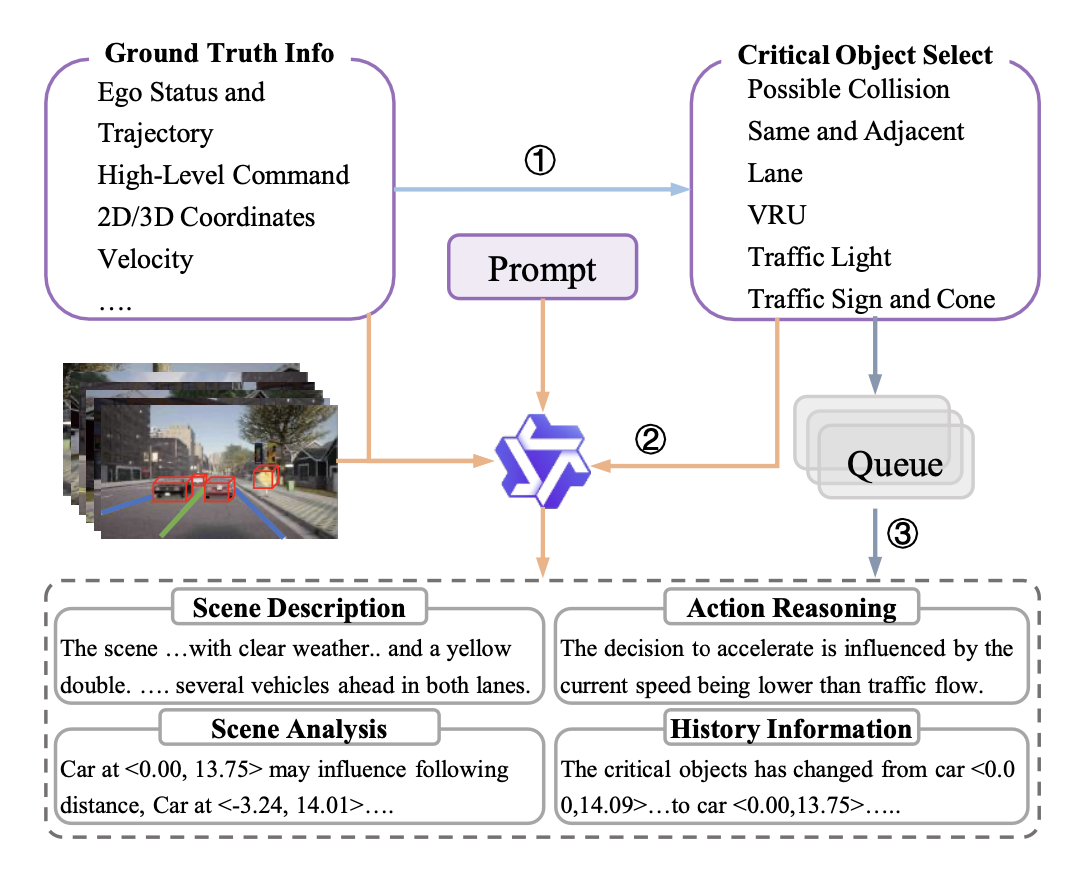
关键目标选择。与主流自动驾驶感知模块平等处理所有检测的目标不同,强调识别可能影响自车驾驶行为的关键目标,这种识别基于人类驾驶策略。选择标准包括:1)目标在三秒内可能发生碰撞。2)当前车道和相邻车道上的前导车辆。3)主动交通信号灯。4)弱势道路使用者 (VRU),例如行人/骑行者。
描述生成。提取包含当前帧和前五帧的视频片段。随后,这些片段与自车状态以及所选关键目标的真值信息(例如 2D/3D 坐标和速度等)一起作为 Qwen2VL-72B [57] 的输入,进行多任务生成:1)场景描述; 2) 关键目标的属性及其对自身车辆的影响;3) 自主导航的操作元命令和动作推理。
历史信息。在生成过程中,采用队列机制来保存重要的历史信息。存储的信息主要包含两个部分:1) 环境动态,用于捕捉关键场景元素的时空变化;2) 通过比较分析当前速度/动作与前几帧中的历史对应速度/动作得出的自身运动特征。
生成的描述和收集的历史信息与预定义的问题模板相结合,创建 VQA 对。