酒店网站建设方案怎样在微信公众号里做微网站
Java爬虫 爬取某招聘网站招聘信息
- 一、系统介绍
- 二、功能展示
- 1.需求爬取的网站内容
- 2.实现流程
- 2.1数据采集
- 2.2页面解析
- 2.3数据存储
- 三、获取源码
一、系统介绍
系统主要功能:本项目爬取的XX招聘网站
二、功能展示
1.需求爬取的网站内容
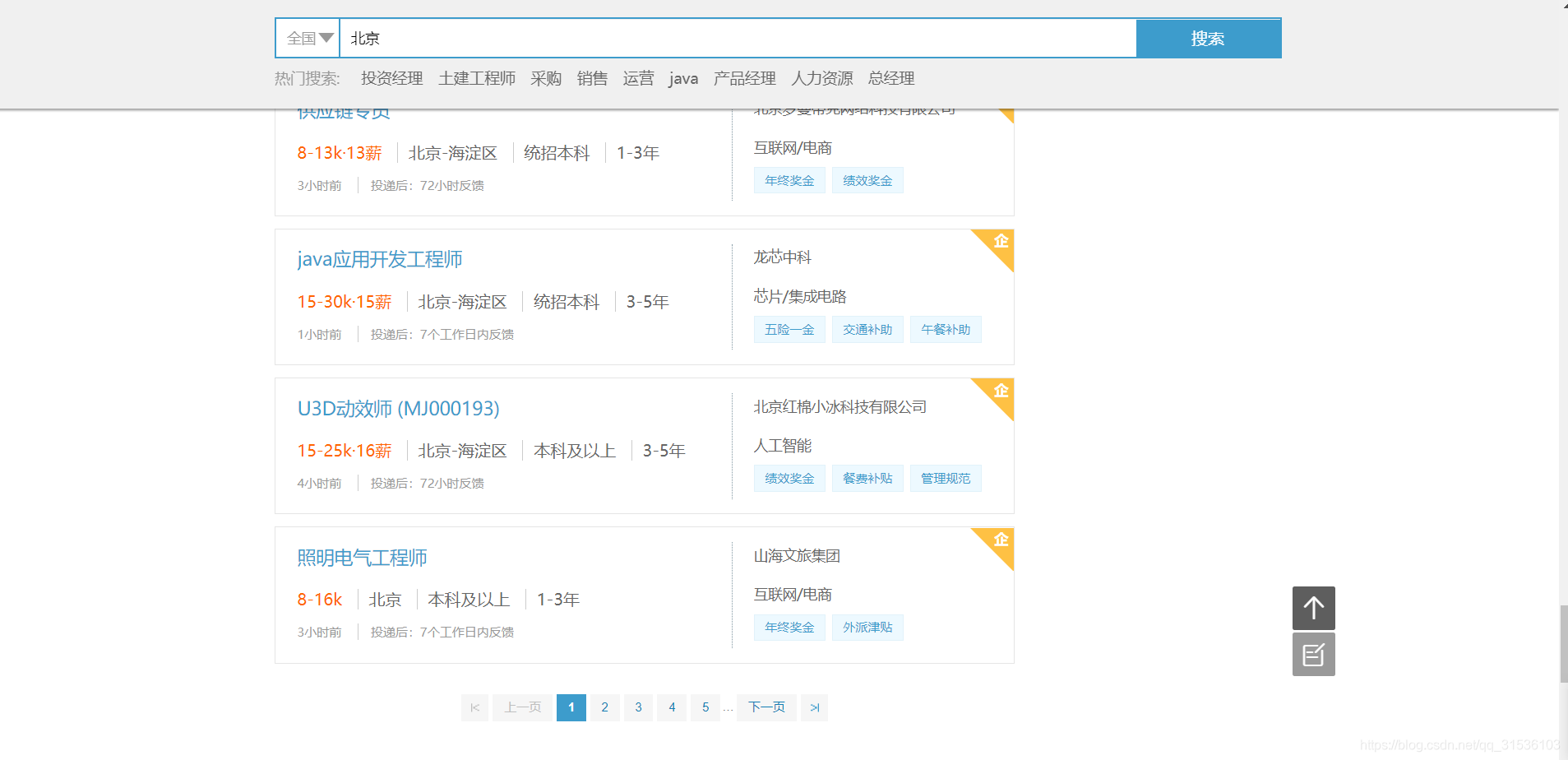
2.实现流程
爬虫可以分为三个模块:数据采集,数据解析,数据保存
项目结构:
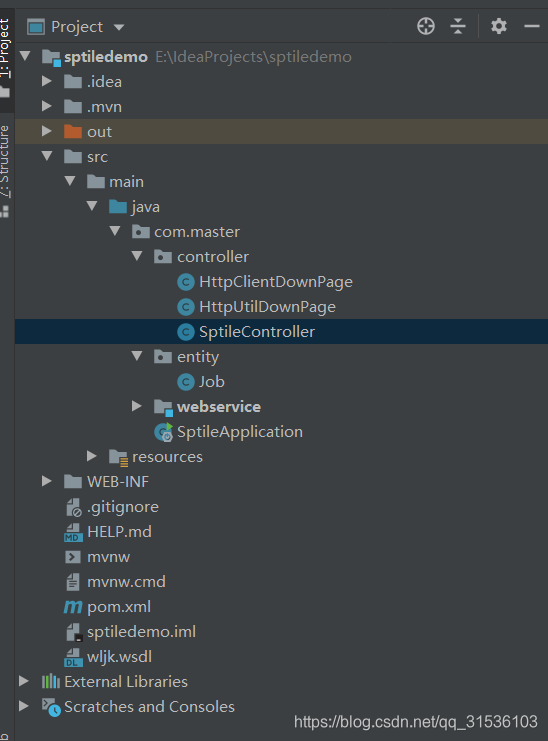
2.1数据采集
数据采集主要是通过HttpClient去请求url,获取网页源码。
(注:除了HttpClient,还可以用HttpUtil,具体使用方式可以百度得到,这里贴出两种工具的使用代码,实现的功能是一样的)
在pom.xml配置相关依赖
HttpClient:
<dependency><groupId>org.apache.httpcomponents</groupId><artifactId>httpclient</artifactId><version>4.5.9</version>
</dependency>
HttpUtil:
<dependency><groupId>net.sourceforge.htmlunit</groupId><artifactId>htmlunit</artifactId><version>2.27</version>
</dependency>
两种工具看个人喜好选择,本项目选择的是HttpClient.建议使用htmlunit,htmlunit爬内容相对齐全。
HTTPClient与HttpUtil的使用方法
HTTPClient
package com.master.controller;import org.apache.http.HttpEntity;
import org.apache.http.HttpStatus;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.config.RequestConfig;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.utils.HttpClientUtils;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;import java.io.IOException;public class HttpClientDownPage {//设置代理,模范浏览器private static final String USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36";public static String sendGet(String url){//1.生成httpclient,相当于该打开一个浏览器CloseableHttpClient httpClient = HttpClients.createDefault();//设置请求和传输超时时间RequestConfig requestConfig = RequestConfig.custom().setSocketTimeout(2000).setConnectTimeout(2000).build();CloseableHttpResponse response = null;String html = null;//2.创建get请求,相当于在浏览器地址栏输入 网址HttpGet request = new HttpGet(url);try {request.setHeader("User-Agent",USER_AGENT);request.setConfig(requestConfig);//3.执行get请求,相当于在输入地址栏后敲回车键response = httpClient.execute(request);//4.判断响应状态为200,进行处理if(response.getStatusLine().getStatusCode() == HttpStatus.SC_OK) {//5.获取响应内容HttpEntity httpEntity = response.getEntity();html = EntityUtils.toString(httpEntity, "GBK");} else {//如果返回状态不是200,比如404(页面不存在)等,根据情况做处理,这里略System.out.println("返回状态不是200");System.out.println(EntityUtils.toString(response.getEntity(), "utf-8"));}} catch (ClientProtocolException e) {e.printStackTrace();} catch (IOException e) {e.printStackTrace();} finally {//6.关闭HttpClientUtils.closeQuietly(response);HttpClientUtils.closeQuietly(httpClient);}return html;}
}HttpUtil
package com.master.controller;import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.NicelyResynchronizingAjaxController;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlPage;public class HttpUtilDownPage {//新建一个模拟谷歌Chrome浏览器的浏览器客户端对象private static final WebClient webClient = new WebClient(BrowserVersion.CHROME);public static String sendGet(String url){//当JS执行出错的时候是否抛出异常, 这里选择不需要webClient.getOptions().setThrowExceptionOnScriptError(false);//当HTTP的状态非200时是否抛出异常, 这里选择不需要webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);webClient.getOptions().setActiveXNative(false);//是否启用CSS, 因为不需要展现页面, 所以不需要启用webClient.getOptions().setCssEnabled(false);//很重要,启用JSwebClient.getOptions().setJavaScriptEnabled(true);//很重要,设置支持AJAXwebClient.setAjaxController(new NicelyResynchronizingAjaxController());HtmlPage page = null;try {page = webClient.getPage(url);} catch (Exception e) {e.printStackTrace();}finally {webClient.close();}//异步JS执行需要耗时,所以这里线程要阻塞30秒,等待异步JS执行结束webClient.waitForBackgroundJavaScript(30000);//直接将加载完成的页面转换成xml格式的字符串String pageXml = page.asXml();return pageXml;}
}上面两种方法都可请求到页面源码信息,这里用的是字符串接收下来。
(注:如果使用HttpClient,有些网页无法获取到全部的页面代码信息,可换成HttpUtil尝试,如果还是不行,那可能是该网站采取了一些反爬措施,需要小伙伴自己动脑解决了)
2.2页面解析
页面源码请求下来了,那么就轮到页面解析模块出厂了。
我们看到的网页,本质上都是由一个个标签嵌套组合而成,再加上js,css等渲染成一个美观的页面,但是我们需要的的数据,所以摒除绚丽的外观,我们只需要解析出目标数据所在的标签就行了。
解析页面的方法也有多种,有htmlcleaner,Jsoup等,这里使用的是Jsoup,HTMLCleaner使用标签的Xpath解析,Xpath可以在浏览器中 进行一下操作 ctrl+shift+c,然后找到目标标签,点击鼠标右键,选择copy,会有cpoy Xpath选项即可,具体玩转需要小伙伴自己去探索,因为笔者也不懂。。。
使用Jsoup,在springboot中只需配置相关依赖便可使用
<!--Jsoup--><dependency><groupId>org.jsoup</groupId><artifactId>jsoup</artifactId><version>1.11.3</version></dependency>
将获取的网页信息通过Jsoup.parse(content)方法转化成Document对象,传到解析模块,解析模块相关代码:
private void paraseList(Document document) throws InterruptedException {//根据网页标签解析源码Elements elements = document.getElementsByClass("sojob-item-main clearfix");for(Element element:elements){Elements elements1 = element.select("h3");String job = elements1.attr("title");Elements elements2 = element.select(".condition");String all = elements2.attr("title");String[] a = all.split("_");String salary = a[0];String address = a[1];String require = a[2]+a[3];Elements elements3 = (element.select(".temptation")).select("span");String welfare = elements3.text();//公司名称Elements elements4 = (element.select(".company-name")).select("a");String companyname = elements4.text();Job jobs = new Job();//kay是字段名 value是字段值jobs.setJob(job);jobs.setSalary(salary);jobs.setAddress(address);jobs.setCompanyname(companyname);jobs.setRequire(require);jobs.setWelfare(welfare);list.add(jobs);}}
这里是解析页面,获取想要的职位信息,将解析的数据封装到QCPage中,效果图如下

2.3数据存储
数据解析完,就差数据存储了。
笔者采用了excel存储
public void saveXls(List list,String name) {//第一步,创建一个workbook对应一个excel文件HSSFWorkbook workbook = new HSSFWorkbook();//第二部,在workbook中创建一个sheet对应excel中的sheetHSSFSheet sheet = workbook.createSheet("招聘表");//第三部,在sheet表中添加表头第0行,老版本的poi对sheet的行列有限制HSSFRow row = sheet.createRow(0);//第四步,创建单元格,设置表头HSSFCell cell = row.createCell(0);cell.setCellValue("招聘公司");cell = row.createCell(1);cell.setCellValue("岗位名称");cell = row.createCell(2);cell.setCellValue("岗位薪资");cell = row.createCell(3);cell.setCellValue("工作地点");cell = row.createCell(4);cell.setCellValue("岗位要求");cell = row.createCell(5);cell.setCellValue("福利待遇");//第五步,写入实体数据,实际应用中这些数据从数据库得到,对象封装数据,集合包对象。对象的属性值对应表的每行的值for (int i = 0; i < list.size(); i++) {HSSFRow row1 = sheet.createRow(i + 1);//创建单元格设值row1.createCell(0).setCellValue(((Job) list.get(i)).getCompanyname());row1.createCell(1).setCellValue(((Job) list.get(i)).getJob());row1.createCell(2).setCellValue(((Job) list.get(i)).getSalary());row1.createCell(3).setCellValue(((Job) list.get(i)).getAddress());row1.createCell(4).setCellValue(((Job) list.get(i)).getRequire());row1.createCell(5).setCellValue(((Job) list.get(i)).getWelfare());}File file = new File("D:/"+name+".xls");if (file.exists()) {file.delete();}//将文件保存到指定的位置try {file.createNewFile();FileOutputStream fos = new FileOutputStream(file);workbook.write(fos);System.out.println("写入成功");workbook.close();} catch ( IOException e) {e.printStackTrace();}}
效果

三、获取源码
点击下载
Java爬虫 爬取某招聘网站招聘信息