免费空间建网站网站开发 北京外包公司
1 介绍
- Unsloth 让微调大语言模型(如 Llama-3、Mistral、Phi-4 和 Gemma)的速度提升 2 倍,内存占用减少 70%,同时不牺牲精度
1.1 LoRA VS QLoRA
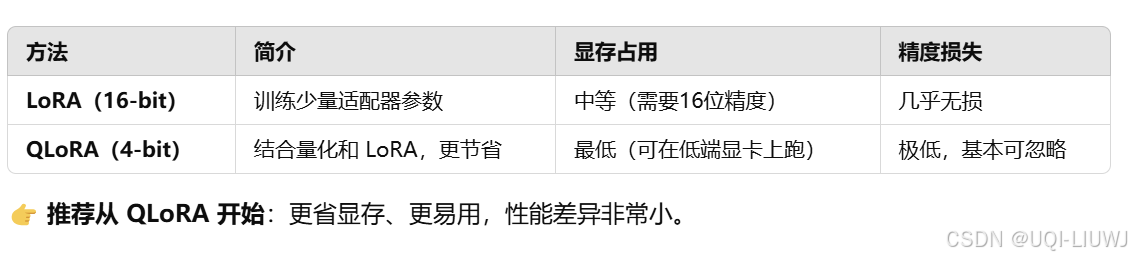
1.2 Base 模型 vs Instruct 模型
📦 Base 模型(基础模型)
-
预训练原始模型,没有指令微调
-
专为“自定义微调”设计,适合根据你自己的数据进行大幅度改造
-
微调后行为由你定义,最灵活!
🧑🏫 Instruct 模型(指令模型)
-
已经过 instruction tuning,能理解“用人类语言说的提示”
-
开箱即用,适合 prompt-based 应用
-
可以做轻量微调,使其更符合你的风格,而保留原有能力

1.3 所有支持的模型
All Our Models | Unsloth Documentation
2 Unsloth 超参数设置指南
2.1 目标:
-
提高模型的准确率
-
避免 过拟合(模型死记硬背)
-
避免 欠拟合(模型没学到东西)
-
得到一个“泛化能力强”的模型
2.2 核心微调超参数
| 超参数 | 说明 | 推荐值 |
|---|---|---|
| 学习率 |
| 1e-4(0.0001)到 5e-5(0.00005) |
| Epochs(训练轮数) |
| 1~3(超过 3 通常不理想,除非你希望模型更少产生幻觉,但也会减少创造力) |
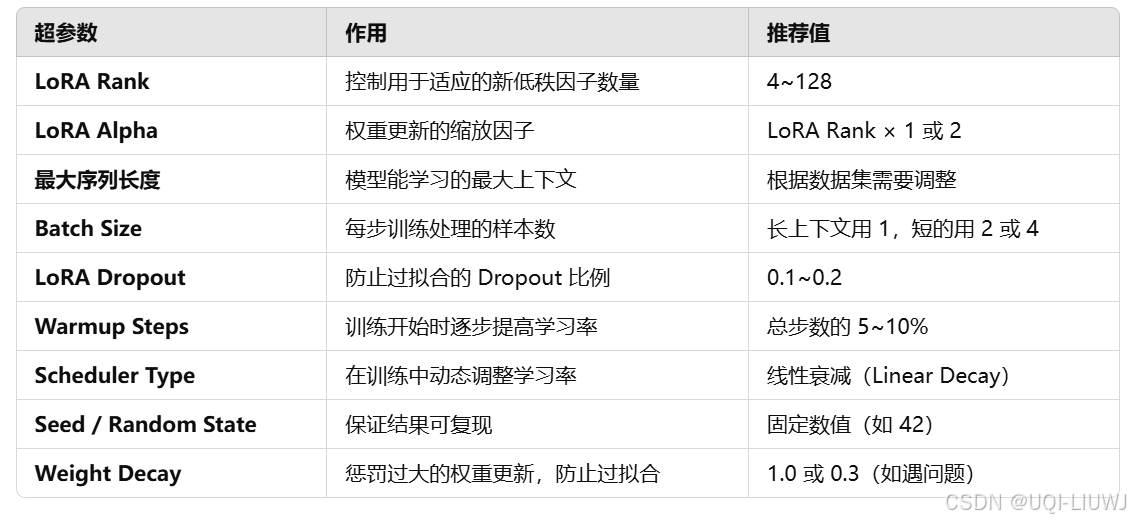
注:复杂任务、小模型推荐更大 rank,如果欠拟合,可以适当增加rank和alpha
| per_device_train_batch_size | 就是前面说的batch size 提高值可以更好利用 GPU,但会因为 padding 导致训练变慢。 |
| gradient_accumulation_steps | 相比于直接设置per_device_train_batch_size,如果要提升训练效率,可以设置gradient_accumulation_steps,相当于变相增加batch 大小 |
| max_steps | 用于快速训练(即使一个epoch的数据没有train 完,到达max_steps步数后,也会停下来) |
3 微调
3.1 理解微调
- 微调大型语言模型(LLM)可以自定义其行为,增强并注入新知识,优化在特定领域或任务中的表现。例如:
- GPT-4 是基础模型;但 OpenAI 对其进行了微调,使其更好地理解指令与提示,从而诞生了大家现在使用的 ChatGPT-4。
- DeepSeek-R1-Distill-Llama-8B 是 Llama-3.1-8B 的微调版本。DeepSeek 使用其 DeepSeek-R1 生成的数据对 Llama-3.1-8B 进行了微调。这个过程被称为“蒸馏”(distillation),是微调的一个子类,它将数据注入 Llama 模型中以学习推理能力。
3.2 选择模型

- 可以根据 Hugging Face 上模型名称更换模型,例如:
- "unsloth/llama-3.1-8b-bnb-4bit"
- 有几个重要参数可以选择
- max_seq_length = 2048
- 控制上下文长度。Llama-3 支持最多 8192,但建议测试用 2048
- dtype = None
- 默认是 None。也可以设置为
torch.float16或torch.bfloat16,适用于新显卡
- 默认是 None。也可以设置为
- load_in_4bit = True
- 启用 4-bit 量化,显存节省 4 倍。适用于 16GB 显存的训练
- 如果使用大显卡(如 H100),关闭它能稍微提高 1–2% 的准确率
- full_finetuning = True
- 全参数微调
- load_in_8bit = True
- 8-bit 微调
- max_seq_length = 2048
3.3 数据集准备
- 对于 LLM 来说,数据集是可用于训练的文本集合。
- 为了有效训练,文本需要可以被分词器处理。
- 通常需要创建包含两个列的结构:question 和 answer
- 数据集的质量与数量将直接影响最终微调效果,因此这一部分非常关键。
- 可以用 ChatGPT 或本地 LLM 合成数据,并将其结构化成 QA 对
- 微调可以永久性地将现有文档库纳入模型知识中,并可不断扩展,但单纯“塞数据”效果不佳
- 为了最佳结果,构建结构清晰的 QA 格式数据集能更好地提升理解力与回答准确性。
- 但这不是绝对的,例如:如果你把代码数据整体 dump 给模型,哪怕没有结构化,模型也可能有明显性能提升。因此这取决于具体任务。
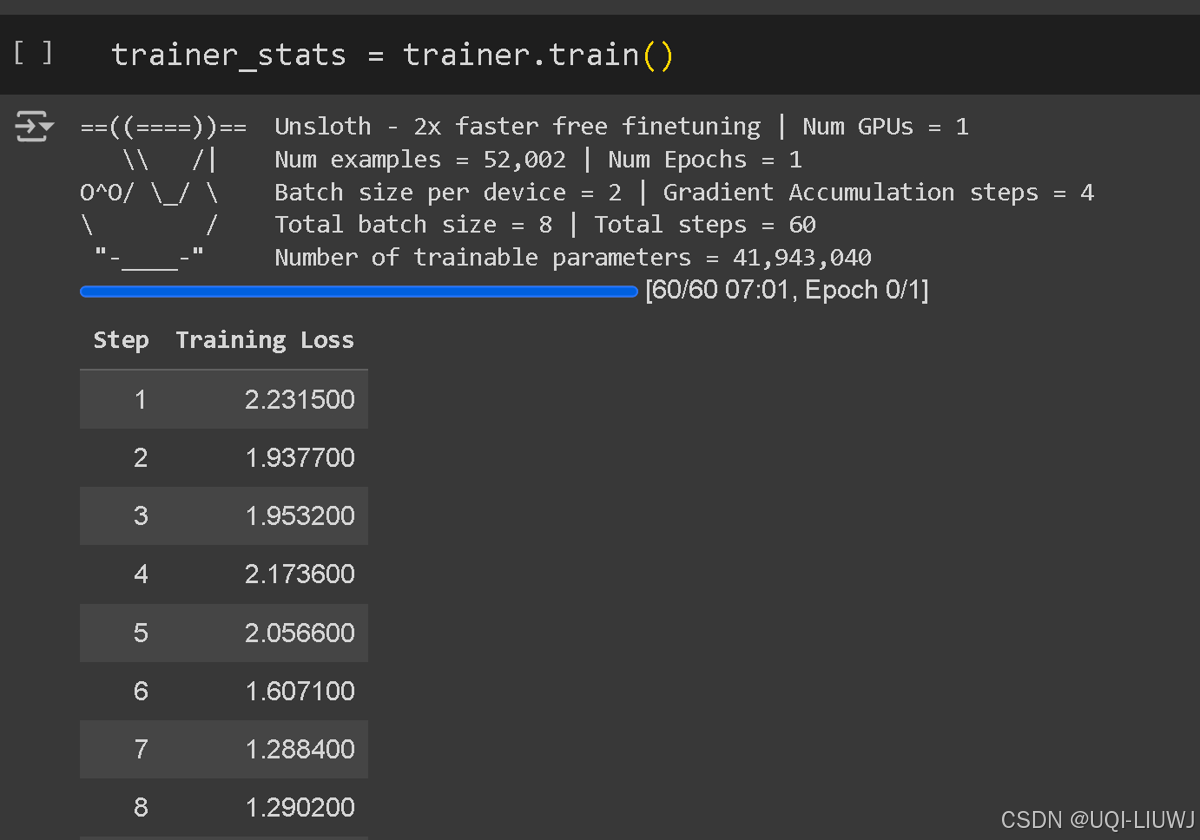
3.4 训练
3.5 测试
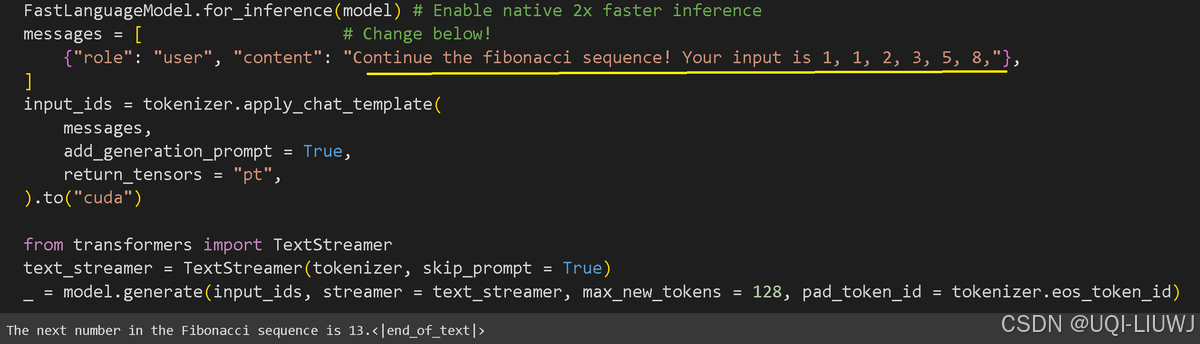
- Unsloth 内部自带 2 倍推理加速,所以别忘记使用FastLanguageModel.for_inference(model)
- 如果希望生成更长的回答,设置:max_new_tokens = 256 或 1024
-
数值越大,输出越长,等待时间也会更久。
-
3.6 保存
保存至本地/线上
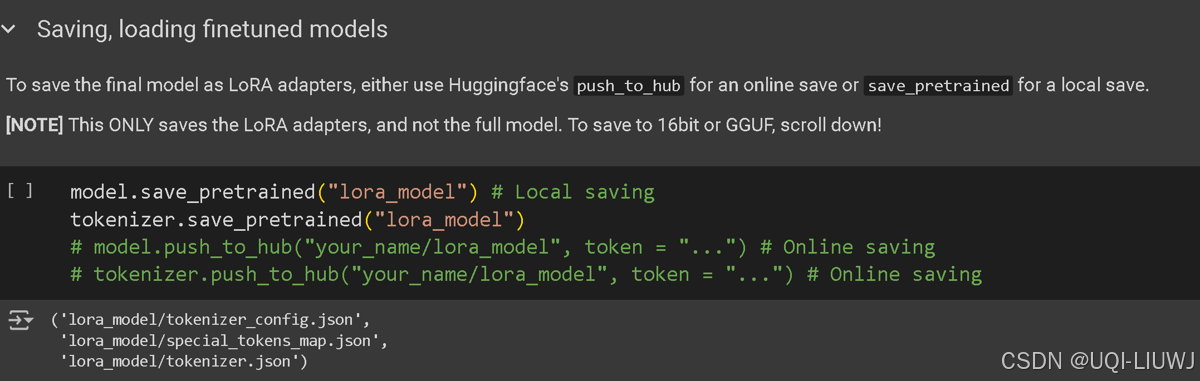
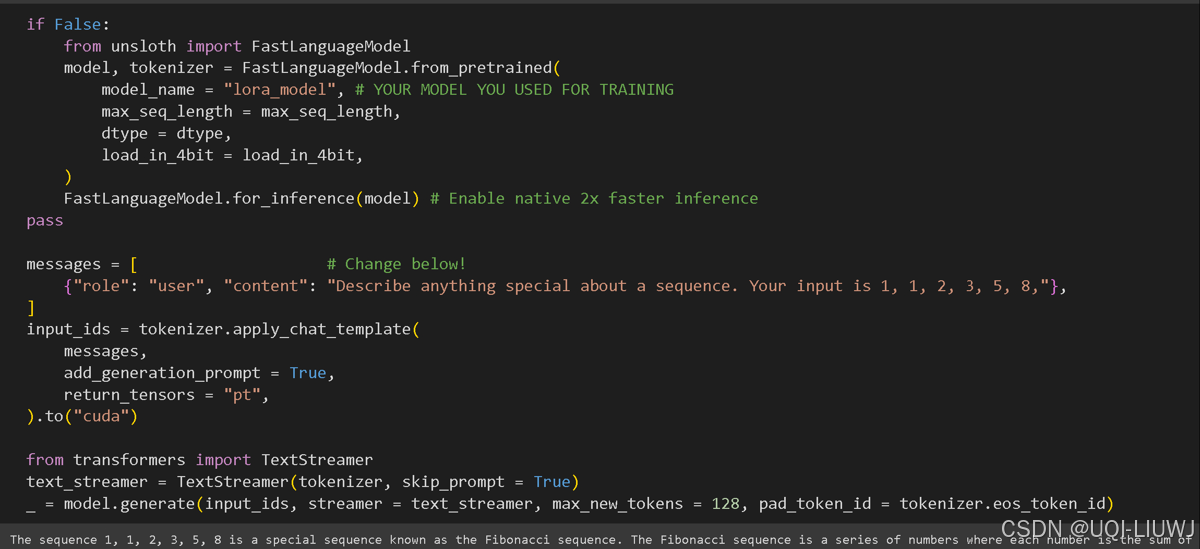
3.7 加载
from_pretrained就行
4 GRPO
Reasoning - GRPO & RL | Unsloth Documentation