网站板块的策划方案国家重点项目建设库网站
MCP项目开发-一个简单的RAG示例
前言
前言
- 客户端是基于官网的例子改的,模型改成了openai库连接
- 仅仅使用基础的RAG流程作为一个演示,包含了以下步骤
- query改写
- 搜索:使用google serper
- 重排序:使用硅基流动的api
- 大模型api也使用的硅基流动
- 调用速度还可以
官方文档
-
mcp官方文档
https://modelcontextprotocol.io/introduction
使用到的api注册
-
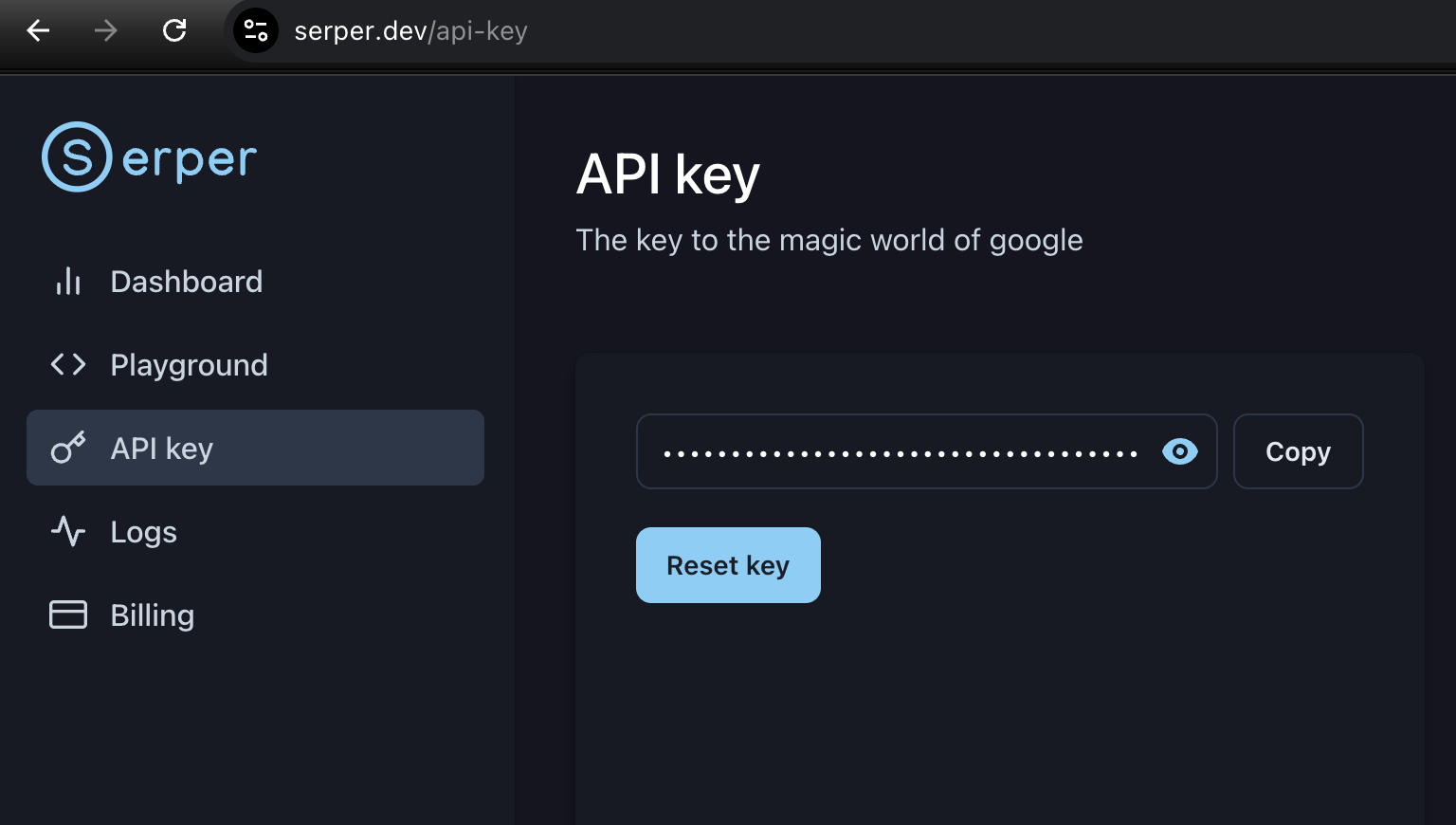
检索:google serper
https://serper.dev
有2500 Credits,具体也没搞明白,好像是每次检索返回的文本数量超过10则花费2Credits,不过这个不重要,反正自己用肯定够,api在这
连接示例
curl --location 'https://google.serper.dev/search' \ --header 'X-API-KEY: 你的api-key' \ --header 'Content-Type: application/json' \ --data '{"q": "你的问题","num": 2 }'其中q表示要检索的问题,然后num为返回的文本数,返回示例如下
{"searchParameters": {"q": "中国首都是哪","type": "search","num": 2,"engine": "google"},"organic": [{"title": "中华人民共和国首都 - 维基百科","link": "https://zh.wikipedia.org/zh-hans/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E9%A6%96%E9%83%BD","snippet": "中华人民共和国首都位于北京市,新中国成立前夕的旧称为北平,是中共中央及中央人民政府所在地,中央四个直辖市之一,全国政治、文化、国际交往和科技创新中心,中国古都、 ...","position": 1},{"title": "中华人民共和国首都_中华人民共和国中央人民政府门户网站","link": "https://www.gov.cn/guoqing/2005-05/24/content_2615214.htm","snippet": "1949年9月27日,中国人民政治协商会议第一届全体会议一致通过中华人民共和国的国都定于北平,即日起北平改名北京。 北京,简称京,是中国共产党中央委员会、中华人民共和国 ...","position": 2}],"relatedSearches": [{"query": "中国首都是北京还是上海"},{"query": "中国首都为什么是北京"},{"query": "中国首都上海"},{"query": "中国以前的首都"},{"query": "新中国首都选址"},{"query": "中国历代首都"},{"query": "中国首都候选"},{"query": "中国首都英文"}],"credits": 1 }主要的就是在
organic中,如果我们的num为2,则organic中返回两个dict,我们取的是没个dict中的snippet字段 -
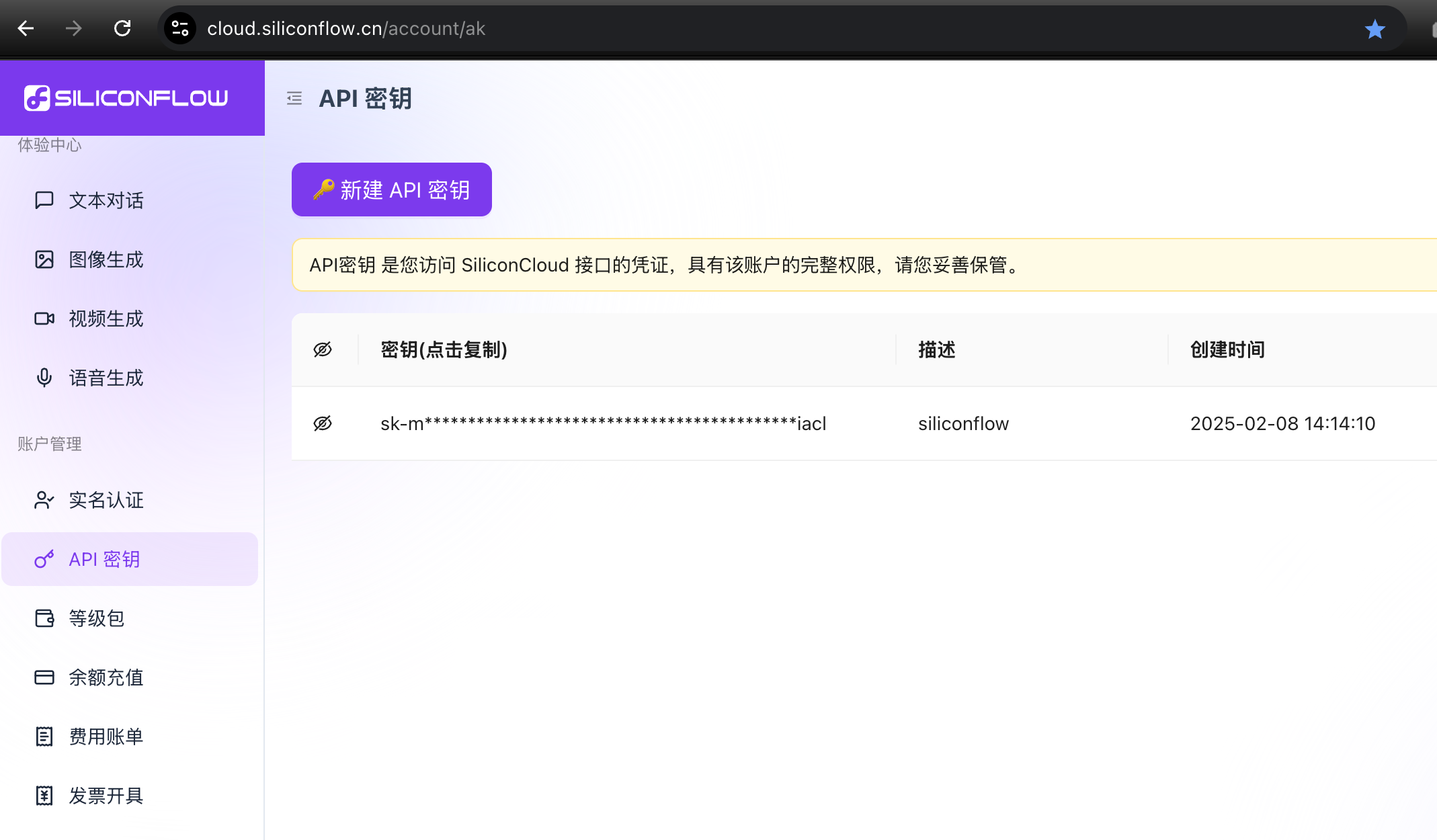
聊天大模型与重排序模型:硅基流动
https://cloud.siliconflow.cn/
注册可以看我的另一篇
https://blog.csdn.net/hbkybkzw/article/details/145558234
api-key如图
服务器
环境搭建
-
官方推荐使用uv来管理环境,先下载uv
pip install uv#或者macos linux curl -LsSf https://astral.sh/uv/install.sh | sh#或者windows powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex"之后重启终端
-
初始化项目。名称为rag_sample
uv init rag_sample -
创建虚拟环境并激活
cd rag_sample uv venv# windows .venv\Scripts\activate# linux source .venv/bin/activate -
安装依赖
openai库是客户端用的,为了方便,客户端就不初始化了,直接和服务器用同一个环境
# windows uv add mcp[cli] aiohttp dotenv openai rich# linux uv add "mcp[cli]" aiohttp dotenv openai rich
构建服务器
-
在rag_sample目录下,创建 .env 文件保存为环境变量
GOOGLE_SERPER_URL=https://google.serper.dev/search GOOGLE_SERPER_API= SILICONFLOW_RERANKING_BASE_URL=https://api.siliconflow.cn/v1/rerank SILICONFLOW_CHAT_BASE_URL=https://api.siliconflow.cn/v1/chat/completions SILICONFLOW_RERANKING_API_KEY= RERANKING_MODEL=BAAI/bge-reranker-v2-m3 OPENAI_CHAT_MODEL=Qwen/QwQ-32B OPENAI_BASE_URL=https://api.siliconflow.cn/v1将
GOOGLE_SERPER_API和SILICONFLOW_RERANKING_API_KEY填为自己的 -
rag_client.pyimport mcp import aiohttp import asyncio from mcp.server.fastmcp import FastMCP from utils import query_rewrite,search_with_serper,reranking_by_bgemcp = FastMCP("rag")@mcp.tool() async def rag_sample(query:str,doc_num:int=10,top_n:int=4) -> list:"""rag_sample: 输入query,输出检索重排序后的文档Parameters:-------------------------------------------------------------------------------------------------------------------query: type: str desc: 用户问题 doc_num: type: int desc: 检索文档数 top_n: type: top_n desc: 重排序后返回top_n Returns:-------------------------------------------------------------------------------------------------------------------reranked_doc: type: list desc: top_n检索文档"""rewrite_query = await query_rewrite(query=query)documents = await search_with_serper(query=rewrite_query,document_num=doc_num)reranked_doc = await reranking_by_bge(query=query,documents=documents,top_n=top_n)return reranked_docasync def test():query = "MCP协议介绍"reranked_doc = await rag_sample(query=query)importrich.print(reranked_doc)if __name__ == "__main__":# asyncio.run(test())mcp.run(transport="stdio")test函数是用来测试的
我们将主要的代码放在
rag_client.py,辅助函数都放在utils.py中主要的流程就是
query_rewrite: 传入用户问题,返回改写后的问题search_with_serper: 传入改写后的问题和检索数量,返回检索到的文档信息reranking_by_bge:传入用户问题和检索到的信息,返回相似度高的top_n文档信息
代码见下面的utils.py
-
utils.pyimport asyncio import aiohttp from dotenv import load_dotenv import os#从.env文件加载环境变量 load_dotenv()# google serper google_serper_url = os.getenv("GOOGLE_SERPER_URL") google_serper_api = os.getenv("GOOGLE_SERPER_API")# siliconflow api chat_base_url = os.getenv("SILICONFLOW_CHAT_BASE_URL") reranking_base_url = os.getenv("SILICONFLOW_RERANKING_BASE_URL") reranking_api_key = os.getenv("SILICONFLOW_RERANKING_API_KEY") reranking_model = os.getenv("RERANKING_MODEL")# query rewrite prompt query_rewrite_prompt = """ 请根据以下规则优化用户的问题: 1. 首先判断用户query是否为问候或打招呼(例如:'你好'、'在吗'、'您好'等)。如果是问候,直接返回原文query。 2. 如果不是,对query进行优化改写,请保持原意并使改写后的query更精准更简洁,限制在15个字以内 示例:- 输入:'你好,能帮个忙吗?'输出:'你好,能帮个忙吗?'- 输入:'怎么重写句子结构?'输出:'句子结构优化步骤示例'输出时无需解释,仅返回最终结果。 """async def fetch_search_results(url, headers, payload):"""发动请求并获取响应"""async with aiohttp.ClientSession() as session:async with session.post(url, headers=headers, json=payload) as response:assert response.status == 200response_json = await response.json()return response_json # 返回响应jsonasync def query_rewrite(query:str):"""一个简单的query改写,直接用aiohttp了,没有使用openai"""url = chat_base_urlheaders = {'Authorization': f'Bearer {reranking_api_key}','Content-Type': 'application/json'}payload={"model": "Qwen/Qwen2.5-72B-Instruct","messages": [{"role": "system","content": query_rewrite_prompt},{"role": "user","content": query}],"max_tokens": 512,"stream":False}response_data = await fetch_search_results( url=url,headers=headers,payload=payload)rewrite_query = response_data['choices'][0]['message']['content']return rewrite_queryasync def search_with_serper(query:str,document_num:int=10):"""google serper 搜索并返回documents,形式如下[{"title1":"","link1":"","snippet1":"","position1":""},{"title2":"","link2":"","snippet2":"","position2":""},...]"""url = google_serper_urlheaders = {'X-API-KEY': google_serper_api,'Content-Type': 'application/json'}payload = {"q": query, # 要搜索的问题"num": document_num # 要所搜的文档数量}response_data = await fetch_search_results( url=url,headers=headers,payload=payload)documents = response_data['organic']return documents async def reranking_by_bge(query:str,documents:list[dict],top_n:int=4):"""调用排序模型,返回排序后的文档"""doc_to_rerank = [doc["snippet"] for doc in documents]url = reranking_base_urlheaders = {'Authorization': f'Bearer {reranking_api_key}','Content-Type': 'application/json'}payload = {"model": reranking_model,"query": query,"documents": doc_to_rerank,"top_n": top_n,"return_documents": True, # 如果是false则只返回索引,麻烦"max_chunks_per_doc": 1024,"overlap_tokens": 80}reranked_info = await fetch_search_results( url=url,headers=headers,payload=payload)reranked_doc =[item['document']['text'] for item in reranked_info['results']]return reranked_docasync def test():import richquery = "流水不争先"rewrite_query = await query_rewrite(query=query)rich.print('rewrite_query',rewrite_query)documents = await search_with_serper(query=rewrite_query,document_num=4)rich.print('documents',documents)reranked_doc = await reranking_by_bge(query=query,documents=documents,top_n=2)rich.print("reranked_doc",reranked_doc)if __name__ == "__main__":asyncio.run(test())test函数是用来测试的
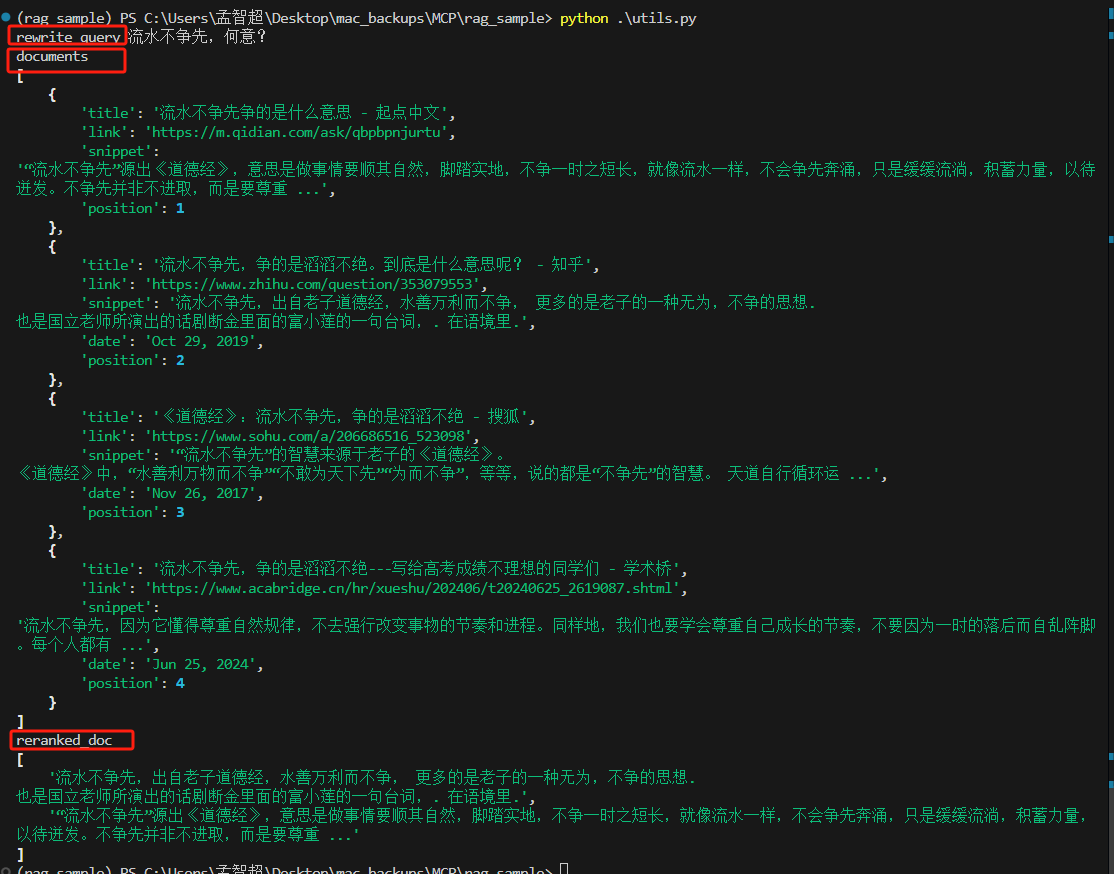
-
运行 python rag_client.py以确认一切正常
app端使用(cherrystudio为例)
-
安装cherrystudio,并配置好模型
https://cherry-ai.com/
-
在app端添加单个weather服务器,下面的json文件需要复制到cherrystudio中
{"mcpServers": {"rag": {"command": "uv","args": ["--directory","C:\\Users\\孟智超\\Desktop\\mac_backups\\MCP\\rag_sample","run","rag_client.py"]}} }意思是:
- 有一个名为“天气”的 MCP 服务器
- 通过运行
uv --directory C:\\Users\\孟智超\\Desktop\\mac_backups\\MCP\\rag_sample run rag_client.py来启动它(项目的地址)
-
将上面的json文本复制到cherrystudio
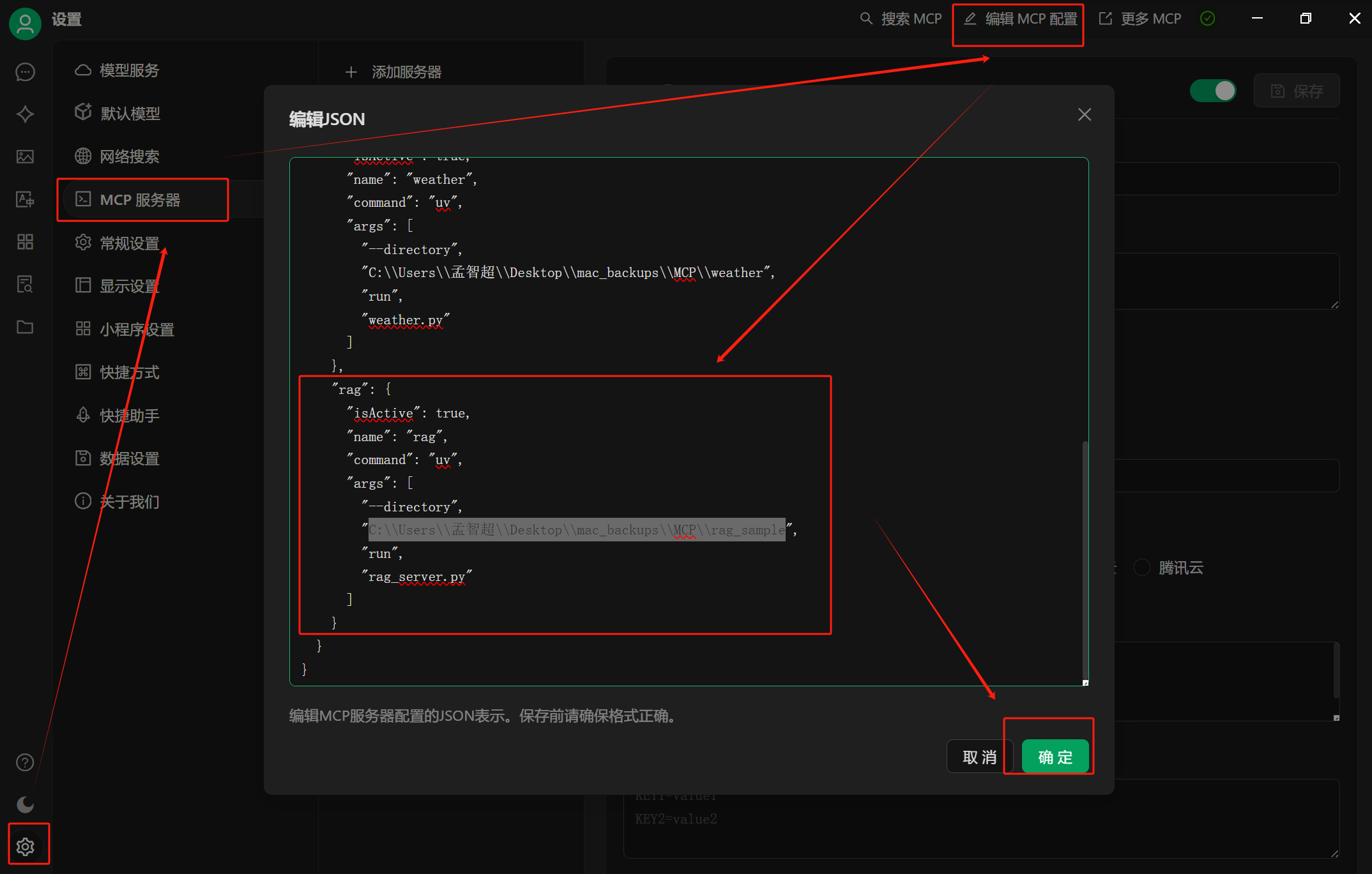
-
选择模型,因为mcp也借用了functioncalling,所以需要选用的模型必须支持functioncalling(tools)
在cherrystudio中的表现就是,有绿色的小扳手
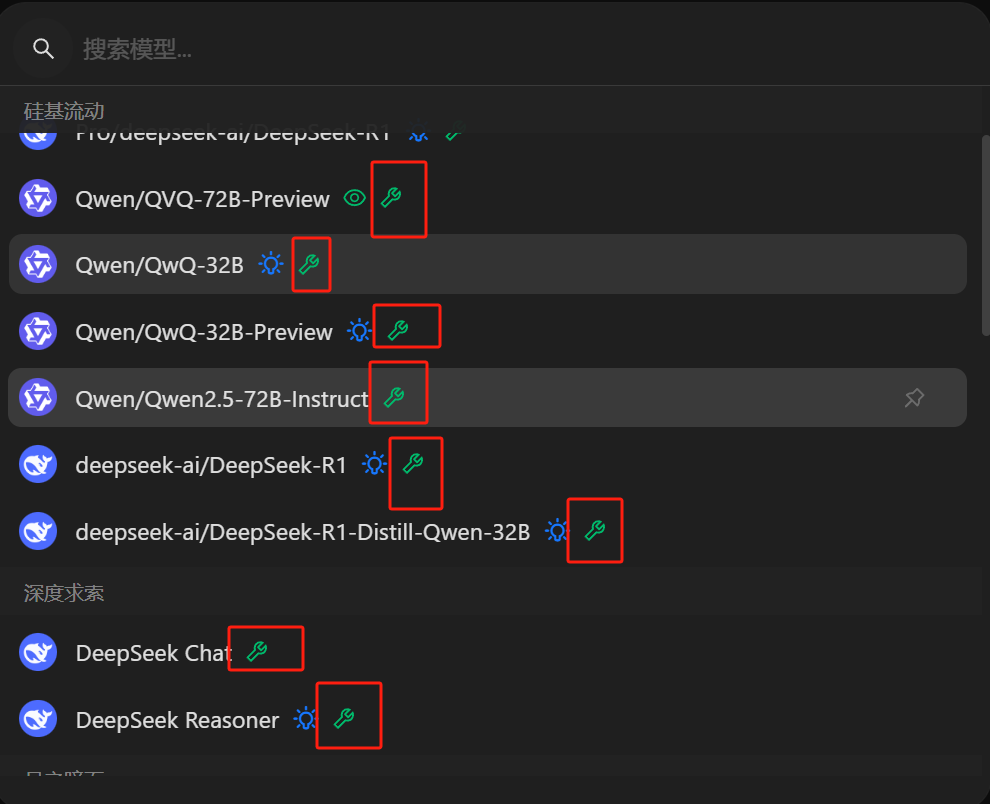
-
开始聊天之前开启mcp
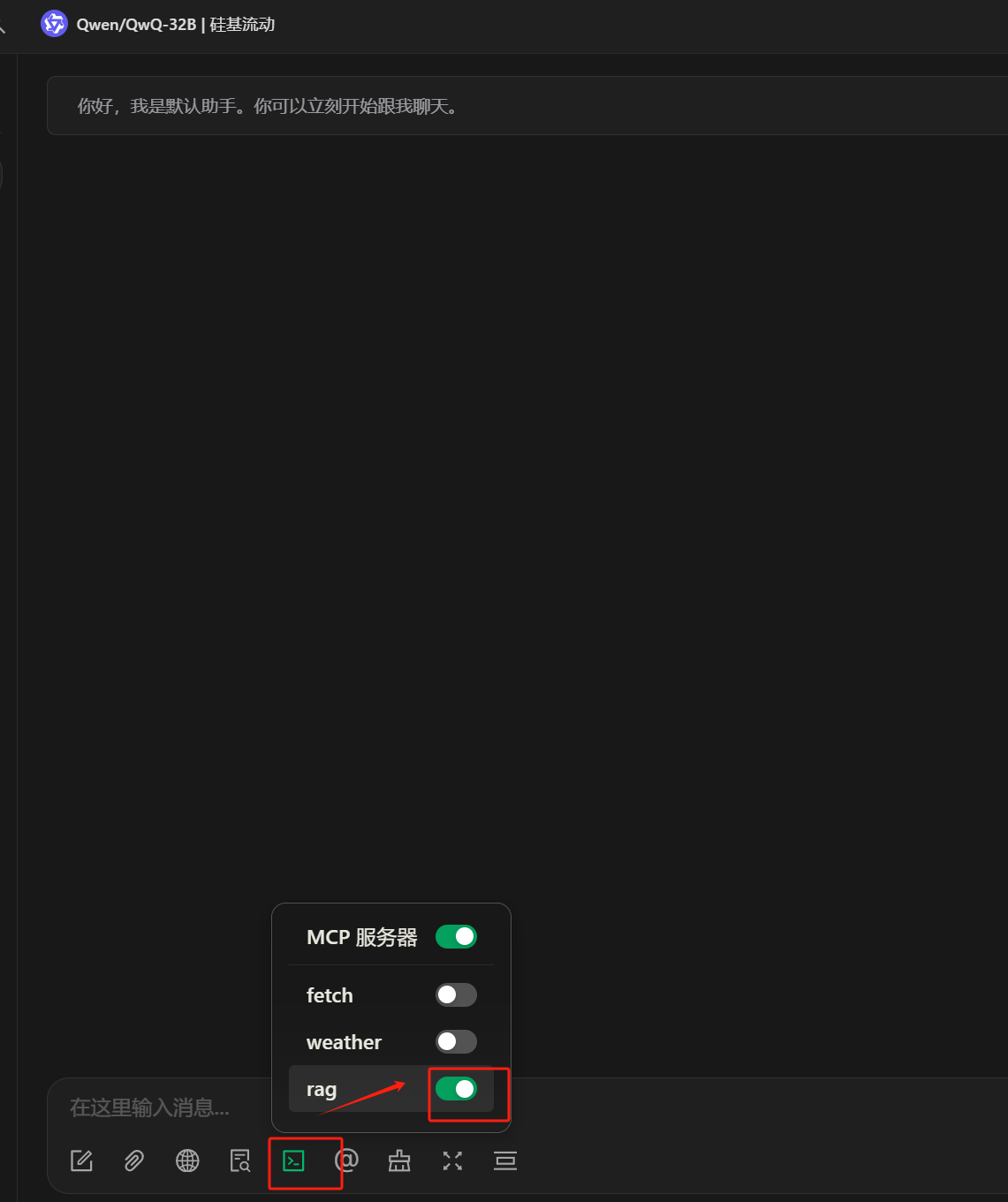
-
看看使用前后的对比
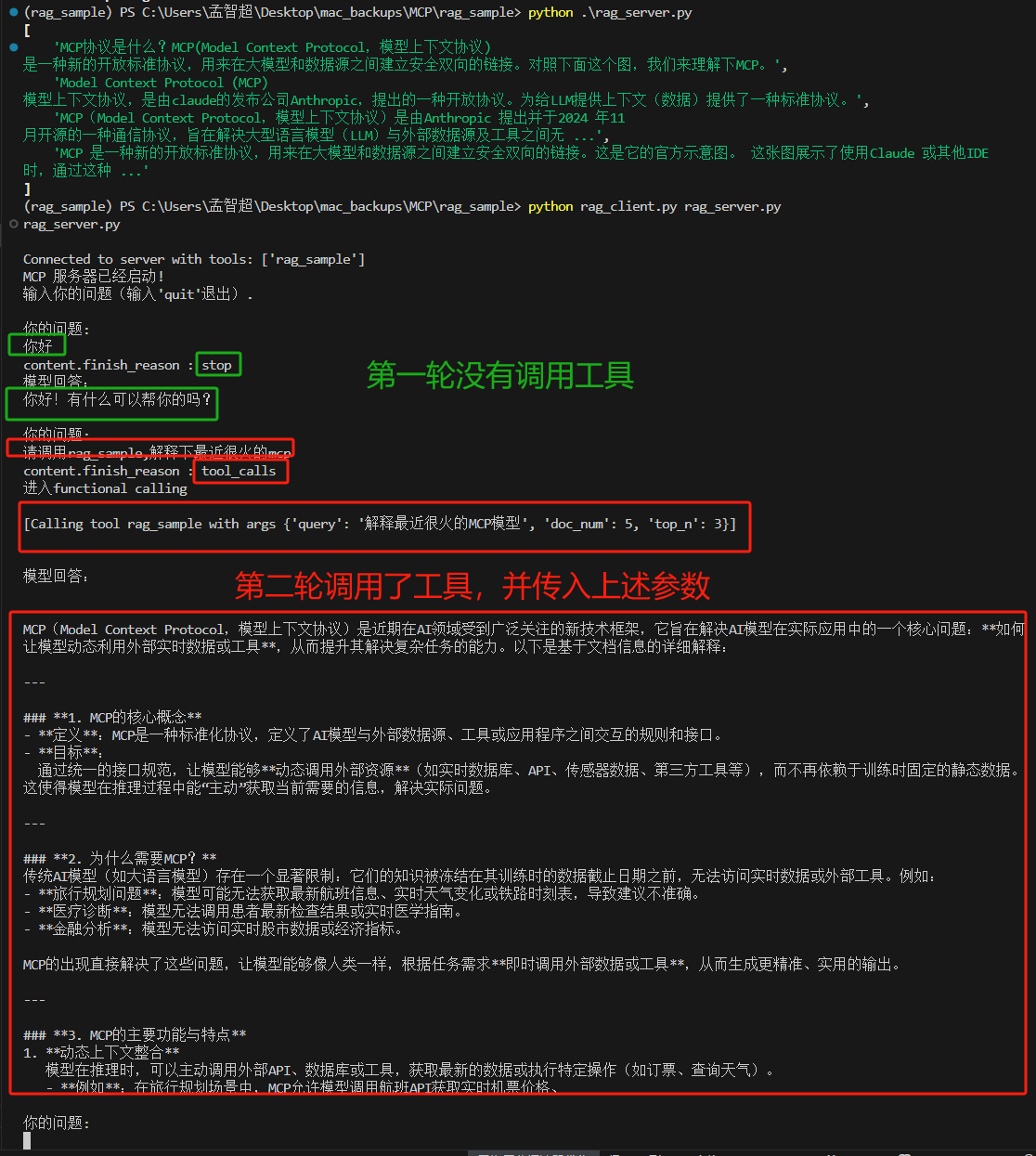
问题:什么是MCP?
未开启前,列举了很多,但是都不是我们想要的
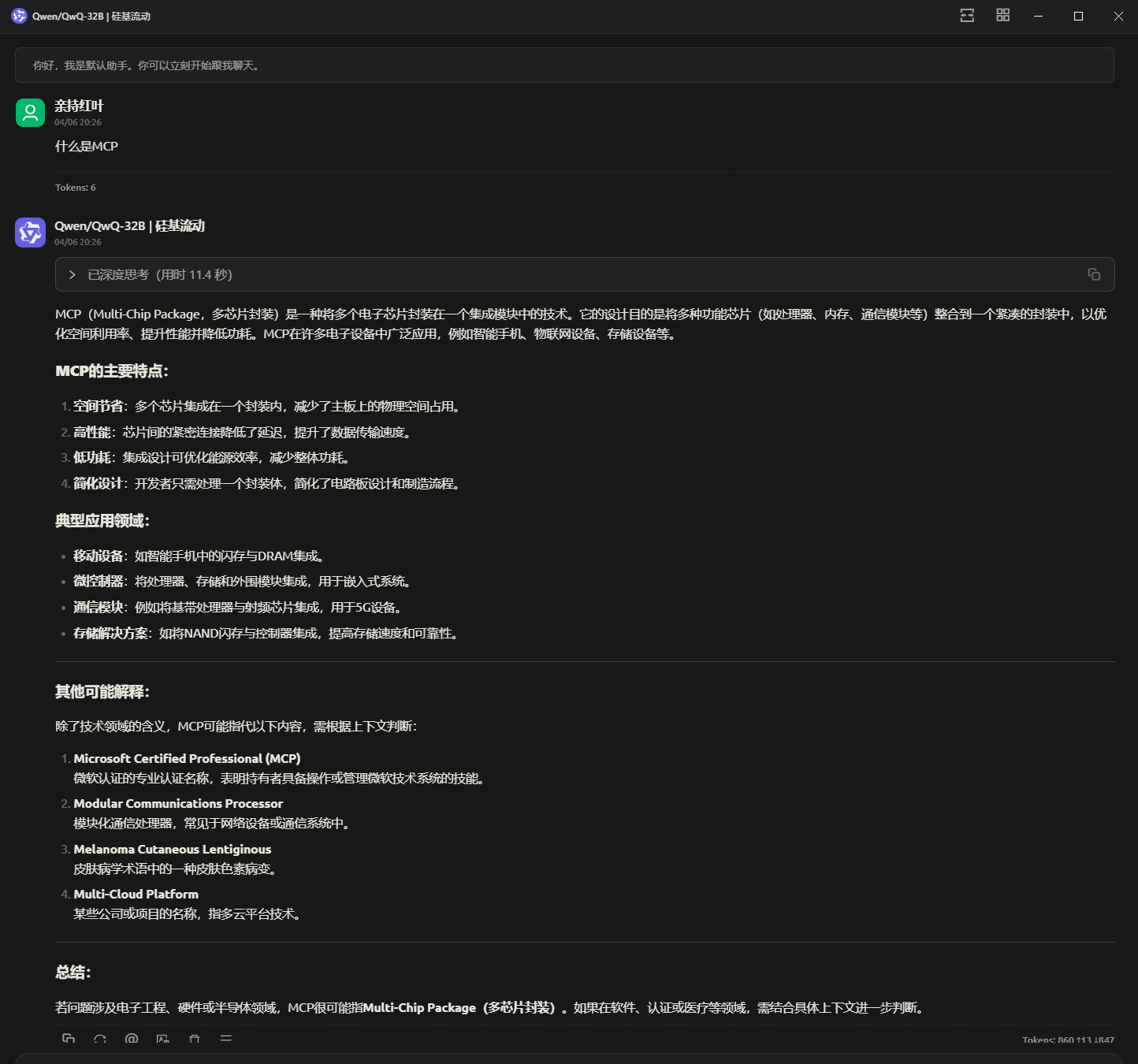
开启后,虽然在思考过程中也提到了其他无关的,但是最后还是决定调用工具rag_sample,最后得到的是我们想要的正确答案。
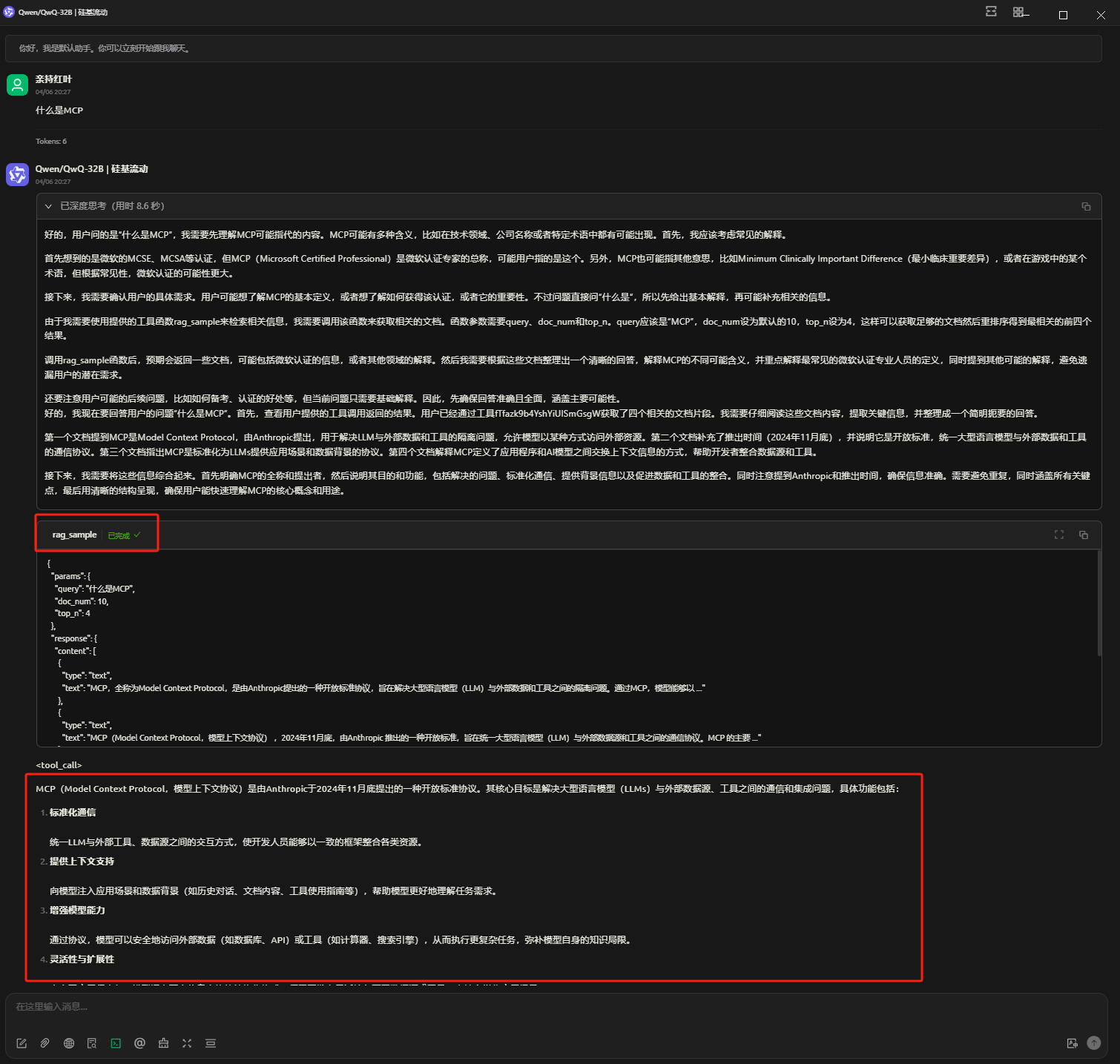
客户端
代码
-
和服务器共用一个环境(不推荐,一般重新开一个环境)
-
代码
rag_client.pyimport os import sys import json import asyncio from typing import Optional from contextlib import AsyncExitStackfrom mcp import ClientSession,StdioServerParameters from mcp.client.stdio import stdio_clientimport openai from openai import OpenAI from dotenv import load_dotenv import traceback# 从.env文件加载环境变量 load_dotenv() # siliconflow api openai.base_url = os.getenv("OPENAI_BASE_URL") openai.api_key = os.getenv("SILICONFLOW_RERANKING_API_KEY") openai_chat_model = os.getenv("OPENAI_CHAT_MODEL")class MCPClient:def __init__(self):# 初始化会话和客户端对象self.session: Optional[ClientSession] = None # 保存mcp客户端会话self.exit_stack = AsyncExitStack()self.model = openai_chat_modelself.openai = OpenAI(base_url=openai.base_url,api_key=openai.api_key)async def connect_to_server(self, server_script_path:str):"""connect_to_server: 连接到mcp服务器 Parameters:-------------------------------------------------------------------------------------------------------------------server_script_path: type:str desc: server脚本地址(.py or .js) """is_python = server_script_path.endswith('.py') # python脚本?is_js = server_script_path.endswith('.js') # node 脚本?if not (is_python or is_js):raise ValueError("Server script must be a .py or .js file")command = "python" if is_python else "node"server_params = StdioServerParameters(command=command,args=[server_script_path],env=None) # 告诉mcp客户端如何启动服务器,比如当前的 python rag_server.pystdio_transport = await self.exit_stack.enter_async_context(stdio_client(server_params) # 启动服务器进程,建立标准I/O通信管道)self.stdio,self.write = stdio_transport # 拿到读写流self.session = await self.exit_stack.enter_async_context(ClientSession(self.stdio,self.write) # 创建MCP客户端会话,与服务器交互)await self.session.initialize() # 发送初始化消息给服务器,等待服务器就绪。# 列出 mcp 服务器上可用的工具response = await self.session.list_tools() # 向 mcp 服务器请求所有已注册的工具(即@mcp.tool)tools = response.toolsprint("\nConnected to server with tools:", [tool.name for tool in tools])async def process_query(self,query:str) -> str:"""process_query: 使用大模型处理查询,调用已经注册的MCP工具 Parameters:-------------------------------------------------------------------------------------------------------------------query: type:str desc:用户问题 """messages = [{"role":"user","content": query}]response = await self.session.list_tools() # 向 mcp 服务器请求所有已注册的工具(即@mcp.tool)# 转换为functional calling 的available_tools格式available_tools = [{"type": "function","function": {"name": tool.name,"description": tool.description,"input_schema": tool.inputSchema}} for tool in response.tools]# print(f"available_tools:\n{available_tools}")# 初始化 大模型连接(OpenAI)response = self.openai.chat.completions.create(model=self.model,max_tokens=1000,messages=messages,tools=available_tools)content = response.choices[0]print(f"content.finish_reason : {content.finish_reason}")if content.finish_reason == "tool_calls": print(f"进入functional calling")# content.finish_reason == "tool_calls"表示要调用工具# 会在content.message.tool_calls 列表中声明要用哪个函数、参数是什么tool_call = content.message.tool_calls[0]tool_name = tool_call.function.nametool_args = json.loads(tool_call.function.arguments)# 取出工具名 tool_name 和参数 tool_args,执行mcp工具result = await self.session.call_tool(tool_name, tool_args)print(f"\n[Calling tool {tool_name} with args {tool_args}]\n\n")# print(f"\n\ncall_tool_result: {result}")# print(f"\n\ncall_tool_result.content[0].text:{result.content[0].text}")# print(f"i.text for i in result.content:{[i.text for i in result.content]}")# 将模型返回的调用哪个工具数据和工具执行完成后的数据都存入messages中messages.append(content.message.model_dump())messages.append({"role": "tool","content": f"{[i.text for i in result.content]}","tool_call_id": tool_call.id,})# 将上面的结果再次返回给大模型并产生最终结果response = self.openai.chat.completions.create(model=self.model,max_tokens=1000,messages=messages,)return response.choices[0].message.content# 如果没有调用工具则直接返回当前结果return content.message.contentasync def chat_loop(self):"""运行一个交互式聊天循环"""print("MCP 服务器已经启动!")print("输入你的问题(输入'quit'退出).")while True:try:query = input("\n你的问题:\n").strip()if query.lower() == "quit":breakresponse = await self.process_query(query)print(f"模型回答:\n{response}")except Exception as e:tb = traceback.extract_tb(e.__traceback__)for frame in tb:print("File:", frame.filename)print("Line:", frame.lineno)print("Function:", frame.name)print("Code:", frame.line)async def cleanup(self):"""清理资源"""# 异步地关闭所有在 exit_stack 中注册的资源(包括 MCP 会话)。await self.exit_stack.aclose()async def main():"""main: 主执行逻辑,以现在的rag为例子标准IO启动需要服务器的代码作为客户端的子进程启动服务器代码:rag_server.py客户端代码:rag_client.py因为都在同一个项目下,所以启动直接为python rag_client.py rag_server.py"""if len(sys.argv) < 2: # print("Usage: python client.py <path_to_server_script>")sys.exit(1)client = MCPClient()try:print(sys.argv[1])# python rag_client.py rag_server.py ,则argv[1] = rag_client.py 为客户端代码await client.connect_to_server(sys.argv[1]) await client.chat_loop()finally:await client.cleanup()if __name__ == "__main__":asyncio.run(main())-
connect_to_server:连接到MCP服务器 -
process_query: 使用大模型处理查询,将MCP工具转换为OpenAI兼容的格式,允许模型决定是否调用工具,如果是,则调用已经注册的MCP工具 -
chat_loop: 交互式聊天(只有单轮) -
main:主函数因为在客户端脚本中,启动方式是"stdio"
if __name__ == "__main__":mcp.run(transport="stdio")这种适合在客户端和服务器在同一个环境中的情况下,是将服务器作为客户端的子进程
所以其中这个客户端的命令如下
python rag_client.py rag_server.py
-
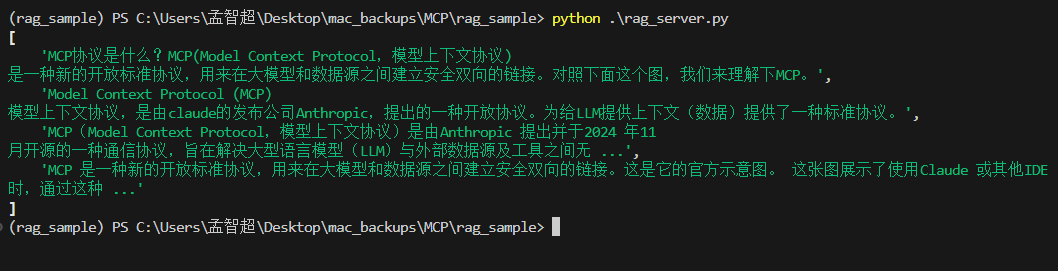
测试运行
-
启动
python rag_client.py rag_server.py -
测试下
(模型不太好触发这个tool,所以我直接加了“请调用rag_sample”)
问题:
请调用rag_sample,解释下最近很火的mcp