网站 建设 初期规划网络营销推广的策略有哪些
“我....我要....学学学学....编程 java!”
—— 这类“重复唠叨”的文本是否让你在清洗数据时头疼不已?
本文将带你一步步掌握正则表达式中的反向引用技术,并结合 Java 实现一个中文文本去重与清洗的实用工具。
结合经典的结巴实例。如何高效地将这样的文本规范化为"我要编程 java!"呢?这正是正则表达式反向引用大显身手的地方。
一、正则表达式基础回顾
1. 捕获组(Capturing Group)
括号 () 会把匹配到的内容保存为“捕获组”,可以在替换或后续匹配中通过编号引用,例如 $1 表示第一个捕获组。
2. 反向引用(Backreference)
反向引用指在正则表达式内部或替换字符串中引用前面捕获的组:
-
在匹配时,
\\1表示匹配和第一个捕获组相同的内容; -
在替换时,
$1表示用第一个捕获组的内容来替换。
问题分析与第一步处理
我们先看原始代码处理的第一步:
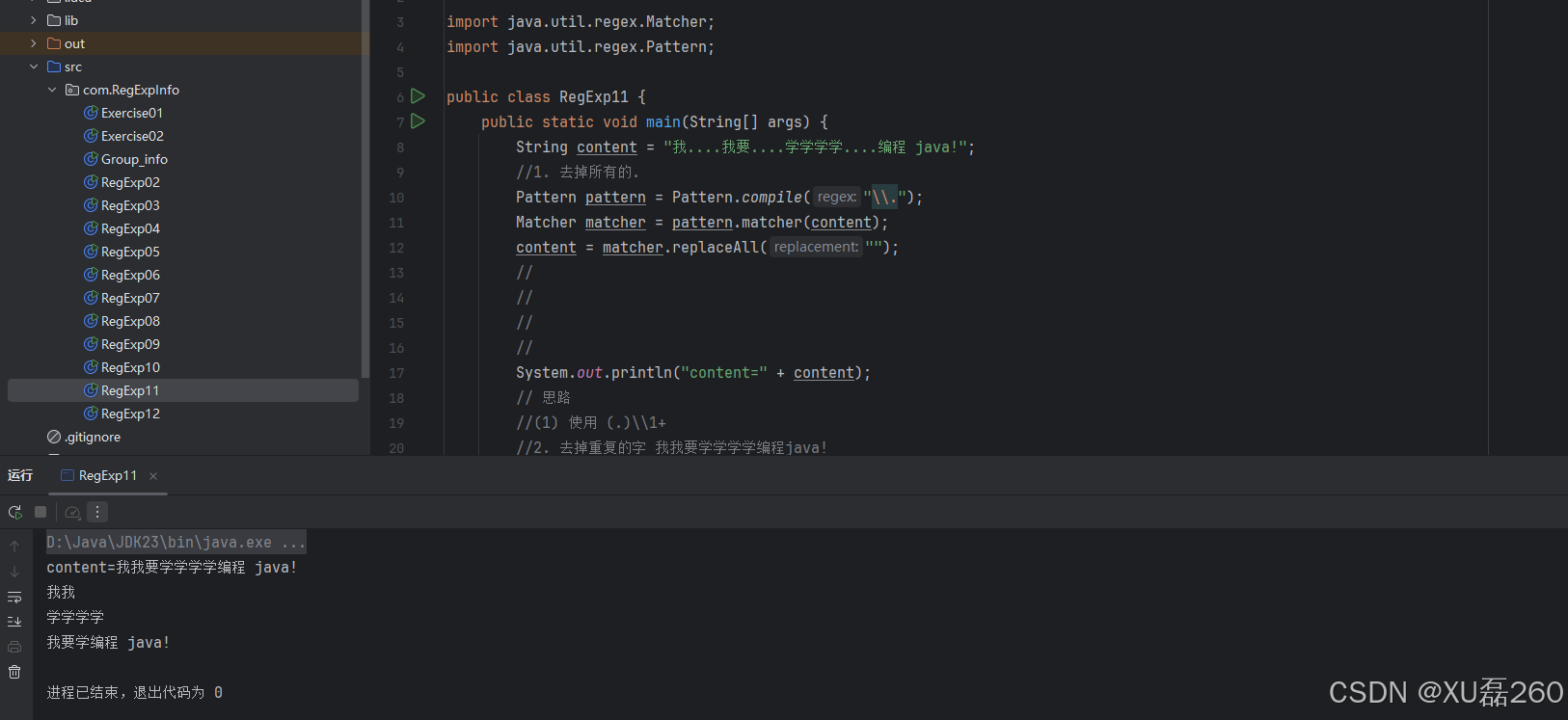
String content = "我....我要....学学学学....编程 java!";
// 1. 去掉所有的.
Pattern pattern = Pattern.compile("\\.");
Matcher matcher = pattern.matcher(content);
content = matcher.replaceAll("");这一步使用简单的正则表达式\\.匹配所有点号,并用空字符串替换它们。处理后得到:
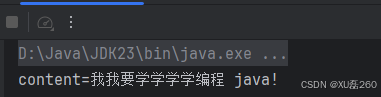
我我要学学学学编程 java!技术难点:识别并处理重复字符
接下来的才是真正的挑战——如何处理重复的汉字。这里我们需要解决两个关键技术点:
-
如何识别连续重复的字符
-
如何引用匹配到的内容进行替换
正则表达式分组与反向引用
核心代码展示了解决方案:
pattern = Pattern.compile("(.)\\1+"); // 分组的捕获内容记录到$1
matcher = pattern.matcher(content);这个正则表达式(.)\\1+分解来看:
-
(.):匹配任意单个字符并捕获到第一个分组 -
\\1+:引用第一个分组匹配的内容,并要求至少重复一次
这里的\\1就是反向引用(backreference),它引用正则表达式中第一个括号捕获的内容。这种机制允许我们匹配重复的模式而不需要预先知道具体是什么字符。
代码执行过程解析
让我们通过调试视角观察匹配过程:
while (matcher.find()) {System.out.println(matcher.group(0));
}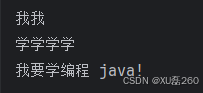
这展示了正则表达式如何找到:
-
连续的两个"我"
-
连续的四个"学"
替换过程
关键替换代码:
String s = matcher.replaceAll("$1");
System.out.println(s);这里$1同样是反向引用,但在替换字符串中使用,表示"用第一个分组匹配的内容替换整个匹配"。因此:
-
"我我" → "我"
-
"学学学学" → "学"
最终输出:
技术深度:反向引用的工作原理
反向引用的实现基于正则引擎的以下机制:
-
捕获组记忆:当
(.)匹配一个字符时,引擎会记住这个具体字符 -
引用机制:
\1或$1在不同上下文(模式匹配/替换)中引用同一捕获组 -
动态匹配:引用的内容是动态的,取决于实际匹配时捕获组捕获的内容
这种机制使得正则表达式能够处理模式重复而内容未知的情况,大大增强了表达能力。
性能与优化考虑
在实际应用中,我们还需要考虑:
-
分步处理:如示例中先处理点号再处理重复字符,分步正则通常比复杂单次正则更高效
-
预编译模式:对于频繁使用的正则,
Pattern.compile()应该只执行一次 -
Unicode支持:
(.)能匹配大多数Unicode字符,但某些复杂字符可能需要特殊处理
扩展应用场景
反向引用的应用远不止于此,还包括:
-
HTML标签匹配:匹配成对的开放和闭合标签
-
重复单词检测:如"the the"中的重复单词
-
简单模板引擎:替换文本中的变量引用
完整代码
public class RegExpCleanRepeat {public static void main(String[] args) {String content = "我....我要....学学学学....编程 java!";// Step 1: 去掉所有的英文句点.content = content.replaceAll("\\.", "");// Step 2: 使用反向引用去除重复字content = content.replaceAll("(.)\\1+", "$1");System.out.println("清洗后内容: " + content);}
}
简化版:
//3.使用一条语句去掉重复的字我我要学学学学编程java!content=Pattern.compile("(.)\\1+").matcher(content).replaceAll("$1");结论
通过这个案例,我们看到了正则表达式反向引用如何优雅地解决文本去重问题。这种技术的核心价值在于:
-
模式抽象能力:不需要知道具体重复什么字符,只需描述重复模式
-
代码简洁性:几行正则可以替代复杂的循环和状态判断
-
表达力强大:能够处理各种复杂的文本模式匹配场景
掌握反向引用这一特性,能够显著提升开发者处理文本问题的效率和质量,是正则表达式进阶应用的重要里程碑。