外贸网站程序怎么给公司做网站
论文标题
MASKSEARCH: A Universal Pre-Training Framework to Enhance Agentic Search Capability
论文地址
https://arxiv.org/pdf/2505.20285
代码地址
https://github.com/Alibaba-NLP/MaskSearch
作者背景
阿里巴巴通义实验室
动机
RAG方法通过检索外部知识有效缓解了大模型的幻觉问题,被广泛应用于知识性问答系统中。近来随着Agent技术的快速发展,人们希望搜索工具更加智能化,能够自主地理解用户需求、规划查询步骤、调用搜索工具、理解搜索结果,从而解决复杂的现实问题
然而,当前的Agent式搜索模型,一般都只是在通用大模型上应用提示工程或简单微调,面对复杂问题时的表现不尽人意;尽管最近有一些面向检索场景的后训练工作试图让大模型真正掌握搜索能力,但它们都只是在有限的数据上做训练,需要大量标注并且缺乏通用性
search-r1:让大模型学会自己使用搜索引擎
ConvSearch-R1: 让LLM适应检索器的偏好或缺陷
于是作者受大模型“预训练”-“后训练”之分的启发,希望探索出一种针对信息搜索的“预训练”方法,在大规模通用数据上训练模型的搜索与推理技能,进而构建出一个“搜索基座”,提高下游搜索模型的效果
本文方法
本文提出了MashSearch,基于海量无监督文本迭代构建了上述搜索基座模型
一、预训练任务设计
预训练任务名为“检索增强的掩码预测” (Retrieval-Augmented Mask Prediction, RAMP) ,类似于 BERT 的掩码填空,但难度更高:模型不仅要分析上下文,还需要调用搜索工具查找外部信息才能预测被mask的内容。具体地,作者利用Qwen-Turbo模型,从海量无监督文本(维基百科)中,挑选出需要外部知识才能推断的片段进行mask(例如命名实体、日期、本体、术语、数值等,还可以基于困惑度进一步提高样本的挑战性),每条样本中mask片段的数量为1~4处
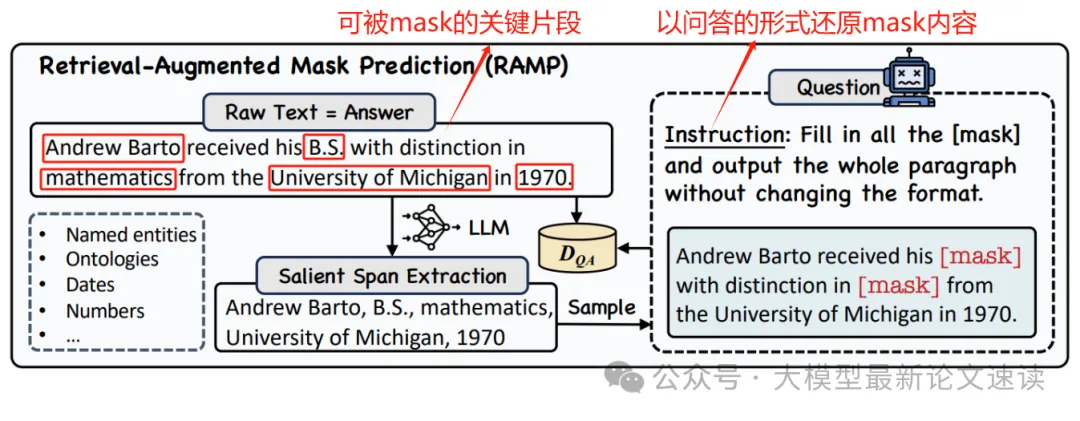
二、预训练数据合成
为了训练模型推理与搜索的能力,还需要生成上述样本的CoT数据。作者采用了两种方法:
1. Agent冷启动
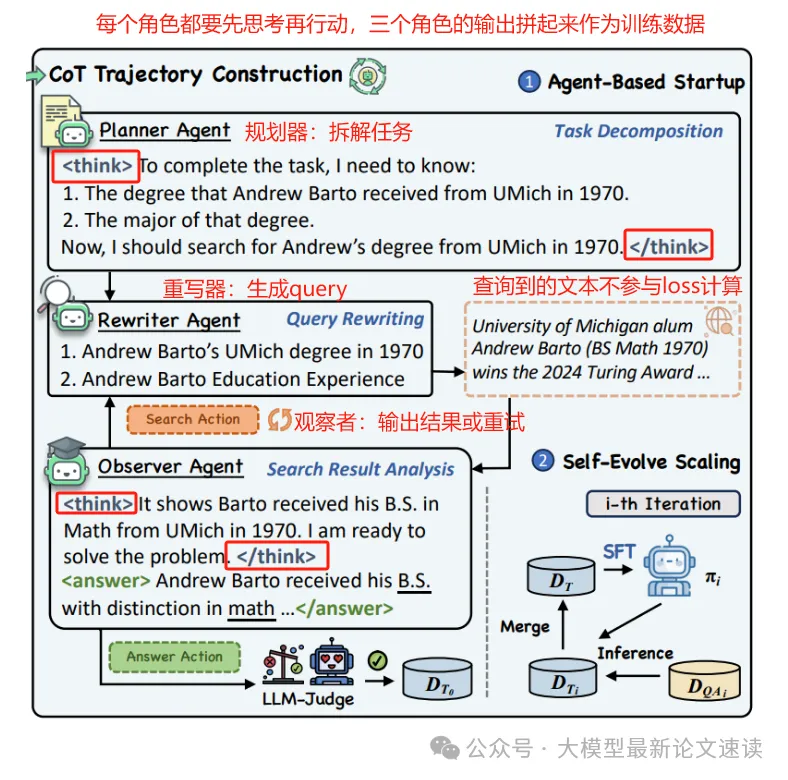
在强模型上使用提示词搭建一个多agent系统,包括:
- planner: 将任务分解为子问题(如:“需要查找某人1970年的学位是什么,专业是什么”)
- rewriter: 根据子问题生成具体搜索文本(如搜索“某某 1970 学位”)
- observer: 分析搜索结果提取答案线索,最终给出填空答案
整合这3个agent的输出,我们便能得到步骤清晰规范的思维链数据,筛选其中输出答案正确的样本,便得到了质量较高的初始训练数据
2. 自蒸馏迭代
为了在保持高数据质量的同时快速扩展数据集,作者采用了一种迭代生成策略:每生产出一批数据后,便拿去做SFT训练出一个独立的教师模型,教师模型在新的掩码任务上推理,产生格式相同的解题轨迹,再通过强 LLM 判别筛选其中的正确样本用于下一轮训练。反复执行这一过程,便可以得到规模可观的高质量 RAMP 数据集
三、预训练方法
作者探究了SFT和RL两种方法来完成上述迭代训练
- 有监督微调 (SFT): 利用上述思维链数据直接训练模型,学习掩码任务的思考和行动模式
- 强化学习 (RL): 使用 DAPO 优化算法进行强化训练,奖励包括格式与结果两方面的考察:如果模型输出了合理的思维链和检索格式则得1分,否则0分;再部署一个强模型(Qwen2.5-72B-instruct)评判模型最终结果与ground truth(mask前的真实内容)的匹配度作为结果分
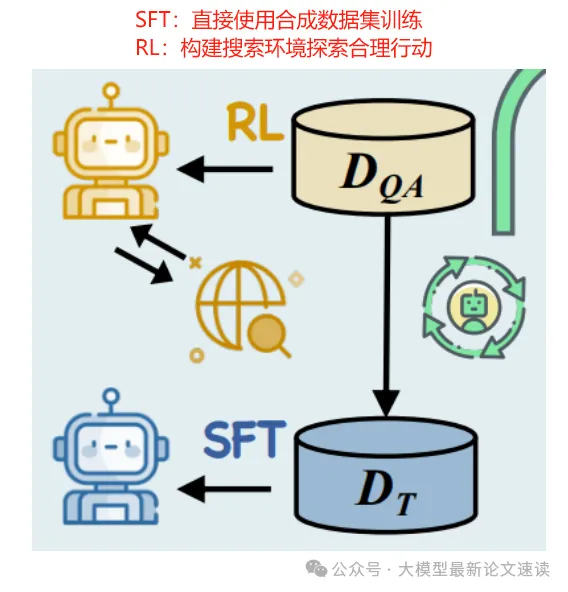
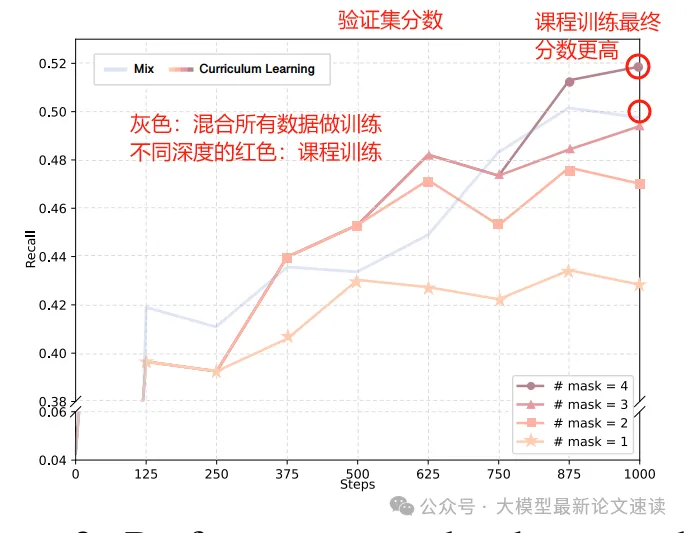
作者还使用了课程训练方法:对训练样本进行了难度排序(由mask片段数量决定,mask越多认为任务越难),并以渐进的方式呈现给模型
于是 MASKSEARCH 在预训练阶段就赋予了模型基本的agent式搜索本领,为应对后续各种复杂搜索任务打下了坚实基础;此外上述流程理论上可以无限扩展,因为可以从海量文本中不断挖掘训练数据
实验结果
实验组:
- RAG-PE: 经典的检索增强模型,只检索一次文档然后直接生成答案,这代表不具备多步规划的传统方法
- Agent-PE: 使用先进的提示策略让模型在推理过程中显式地产生行动和思考,用作对照看纯提示能达到的效果
- distill search-R1: 用HotpotQA数据集(二跳问答,58k)训练instruct模型,作为没有额外预训练的 Agent 方案基线
- search-R1: 与distill search-R1类似,但使用强化学习训练
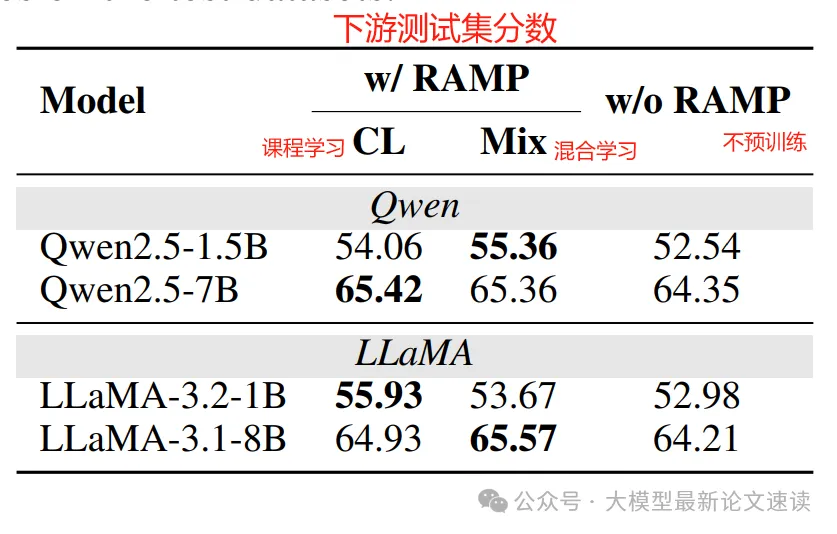
- MaskSearch: 分别使用SFT或RL,在上述合成数据上对instruct模型做预训练,使用 HotpotQA 数据集做后训练
实验指标:
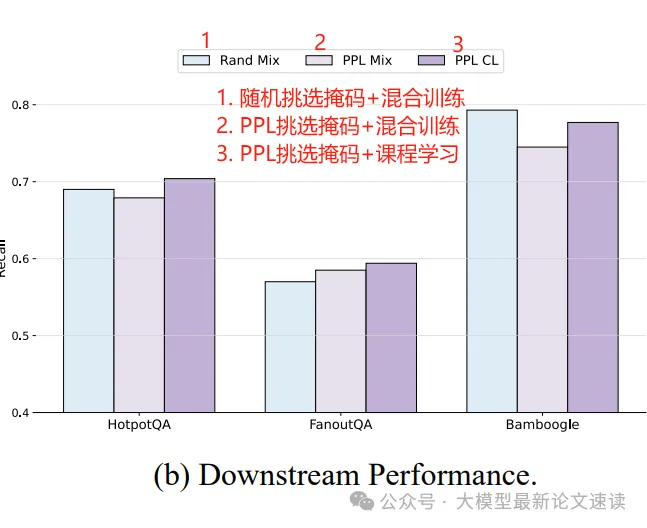
答案召回率,衡量模型作答包含正确答案成分的程度
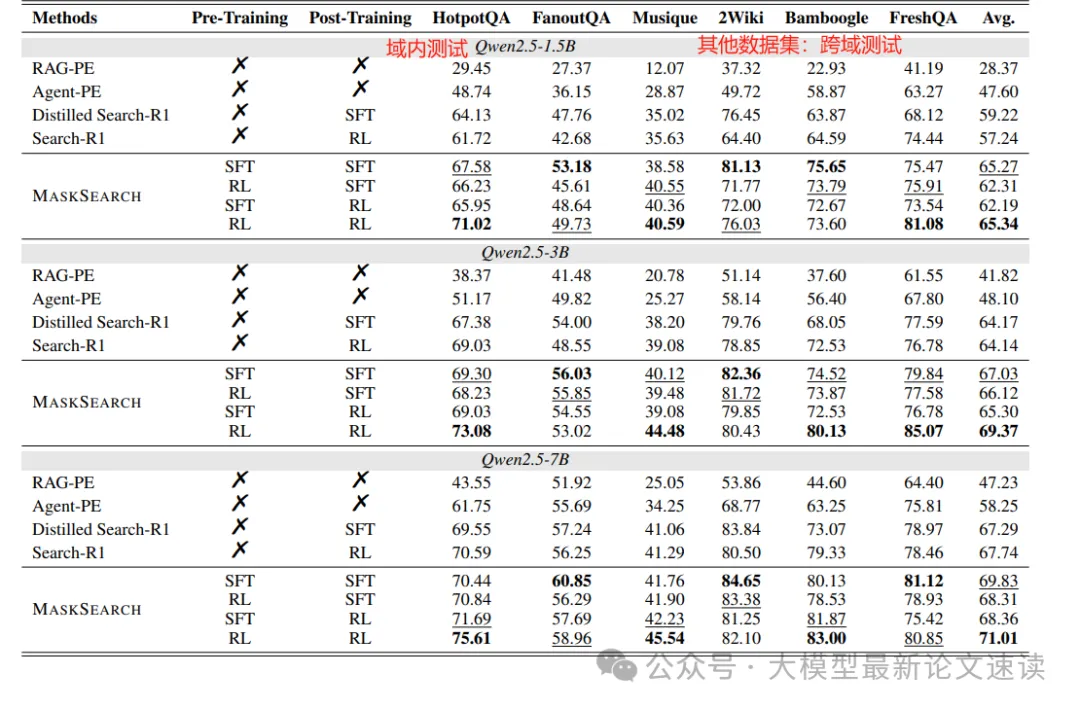
可见本文提出的MaskSearch预训练方法为下游搜索任务带来了稳定而显著的提升,并且在难度较高、跨域的测试问题上也全面超越了对比方法;
与SFT预训练相比,利用RL探索学习通用检索任务,效果更好;
对于尺寸较大的模型,增加预训练数据集大小带来的最终性能提升有限,可能是由于自我迭代过程产生数据集不够多样化所致,所以后续还能探索更多样的数据合成方案;
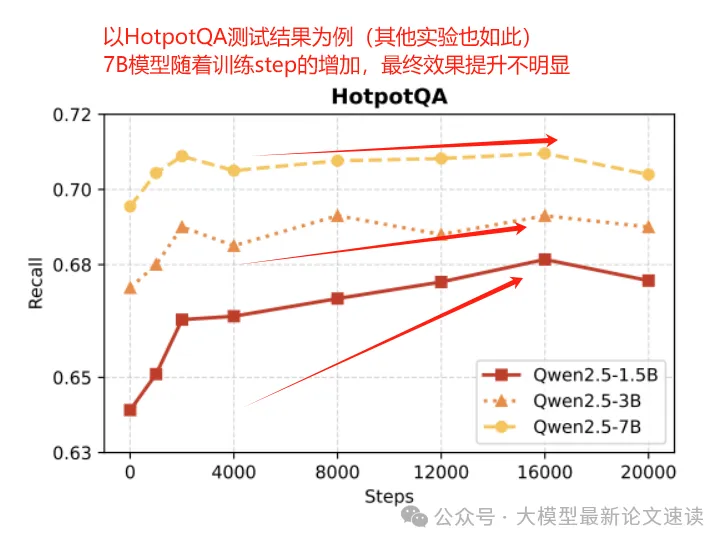
在预训练的验证集上,课程学习能达到更高的测试分数;在下游任务的测试集上,课程学习可能但不一定带来增益