可以做app的网站9377将军
Lambda 架构概述
Lambda 架构是一种大数据处理架构,旨在同时支持实时数据处理和批量数据处理。它通过结合这两种方式,确保系统能够高效地处理大规模数据,并提供低延迟的实时分析能力。
Lambda 架构分为五个主要层次:数据采集层、数据集成层、数据存储层、数据计算层、数据展现层。下面我将用通俗易懂的方式逐一讲解每个层次的功能和作用。
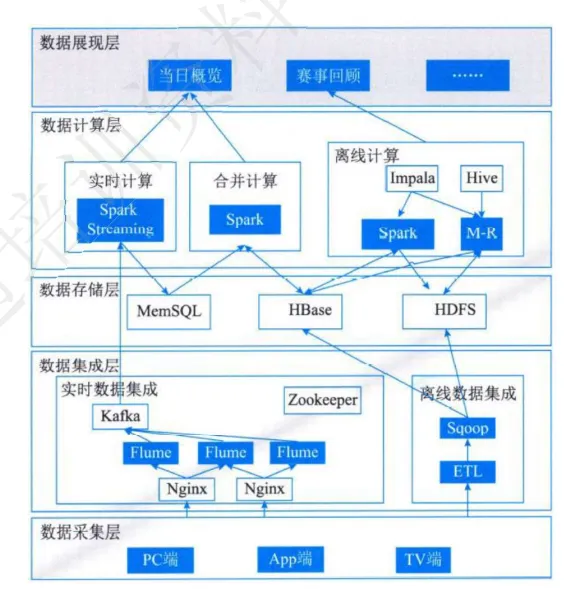
1. 数据采集层
- 位置:最底层。
- 作用:负责从各种数据源收集原始数据。
- 包含内容:
- PC 端:来自电脑设备的数据(例如网页访问日志)。
- App 端:来自移动应用的数据(例如用户行为记录)。
- TV 端:来自智能电视或其他终端设备的数据(例如观看历史)。
通俗解释
想象一下,这是一个“数据入口”,所有原始数据(比如用户的点击、浏览、购买记录等)都会从这里进入系统。这些数据可能是实时产生的,也可能是批量上传的。
2. 数据集成层
- 位置:第二层。
- 作用:负责将采集到的原始数据进行初步整合和预处理,以便后续的存储和计算。
- 包含内容:
- 实时数据集成:
- Flume:用于实时传输数据到中间存储系统(如 Kafka)。
- Kafka:一个分布式消息队列系统,用于缓冲和传递实时数据。
- Nginx:作为负载均衡器,分发实时数据流。
- 离线数据集成:
- Sqoop:用于将关系型数据库中的数据导入到 Hadoop 生态系统中(如 HDFS)。
- ETL:提取、转换、加载过程,对离线数据进行清洗和整理。
- 实时数据集成:
通俗解释
这一层就像是一个“中转站”。实时数据通过 Flume 和 Kafka 进行传输和缓冲,而离线数据则通过 Sqoop 和 ETL 工具进行整合和清洗。Zookeeper 是一个协调服务,用于管理分布式系统的配置和状态。
3. 数据存储层
- 位置:第三层。
- 作用:负责存储不同类型的数据,为后续的计算和分析提供基础。
- 包含内容:
- MemSQL:内存数据库,适合存储需要快速查询的实时数据。
- HBase:分布式 NoSQL 数据库,适合存储结构化和半结构化的实时数据。
- HDFS:Hadoop 分布式文件系统,适合存储海量的离线数据。
通俗解释
这一层是“数据仓库”,不同类型的数据库和文件系统分别存储不同类型的数据。MemSQL 和 HBase 用于存储实时数据,因为它们速度快;HDFS 则用于存储大量的历史数据,因为它的存储成本低且容量大。
4. 数据计算层
- 位置:第四层。
- 作用:负责对存储的数据进行计算和分析,生成最终的结果。
- 包含内容:
- 实时计算:
- Spark Streaming:用于实时处理数据流,生成实时结果。
- 合并计算:
- Spark:用于整合实时计算和离线计算的结果。
- 离线计算:
- Impala:基于 HDFS 的快速 SQL 查询引擎,用于离线数据分析。
- Hive:基于 HDFS 的数据仓库工具,用于离线批处理。
- MapReduce (M-R):经典的批处理框架,用于离线数据处理。
- 实时计算:
通俗解释
这一层是“大脑”,负责对数据进行计算和分析。实时计算(Spark Streaming)处理的是刚刚采集到的最新数据,而离线计算(Impala、Hive、MapReduce)处理的是历史数据。Spark 负责将两者的结果合并,以提供全面的分析结果。
5. 数据展现层
- 位置:最顶层。
- 作用:将计算层生成的结果展示给用户,供决策使用。
- 包含内容:
- 当日概览:展示当天的数据统计和趋势。
- 赛事回顾:分析过去某个事件或比赛的相关数据。
- ……:其他可能的展示内容。
通俗解释
这一层是“出口”,将经过计算和分析的结果以可视化的方式呈现给用户。例如,可以显示当天的销售数据、用户行为分析、赛事回顾等信息,帮助用户做出决策。
Lambda 架构的核心特点
-
实时计算与离线计算并存:
- 实时计算(Spark Streaming)处理最新的数据,提供低延迟的结果。
- 离线计算(Impala、Hive、MapReduce)处理历史数据,提供更全面和准确的分析结果。
- Spark 负责将两者的结果合并,确保最终结果既及时又准确。
-
多层架构设计:
- 每一层都有明确的职责,分工协作,使得整个系统更加灵活和可扩展。
-
支持大规模数据处理:
- 使用 Hadoop 生态系统(如 HDFS、Hive、Impala)来处理海量的历史数据。
- 使用 Spark、Kafka 等工具来处理实时数据。
举例说明
假设我们要构建一个电商平台的大数据分析系统:
-
数据采集层:
- 用户在 PC 端、App 端、TV 端的行为数据(如点击、购买、浏览)被采集进来。
-
数据集成层:
- 实时数据通过 Flume 和 Kafka 进行传输,离线数据通过 Sqoop 导入到 HDFS。
-
数据存储层:
- 实时数据存储在 MemSQL 和 HBase 中,方便快速查询。
- 历史数据存储在 HDFS 中,用于后续的批量分析。
-
数据计算层:
- 实时计算(Spark Streaming)分析当前用户的购买行为,生成实时推荐。
- 离线计算(Impala、Hive)分析过去一个月的销售数据,生成销售报告。
- Spark 将实时推荐和历史销售数据结合起来,提供更全面的分析结果。
-
数据展现层:
- 展示当天的销售概览、热门商品排行、用户行为分析等信息。
Kappa 架构与 Lambda 架构对比
背景
- Lambda 架构:结合实时计算和离线计算,通过两套独立的系统(实时处理和批量处理)来处理数据。
- Kappa 架构:简化了 Lambda 架构,仅使用一套实时处理系统来处理所有数据,包括历史数据。
以下是 Kappa 架构与 Lambda 架构在各个方面的对比:
1. 复杂度
- Lambda 架构:
- 需要同时维护两套系统:实时处理系统和批量处理系统。
- 数据存储、计算和展现层都需要分别支持实时和离线两种模式。
- 系统架构复杂,需要协调两套系统的输出并进行合并。
- Kappa 架构:
- 只使用一套实时处理系统,避免了实时和离线系统的重复建设。
- 数据处理逻辑统一,减少了系统的复杂性。
- 更加简洁,易于理解和维护。
总结:
- Lambda 架构:复杂度高,需要管理两套系统。
- Kappa 架构:复杂度低,仅需一套系统。
2. 开发维护成本
- Lambda 架构:
- 需要开发和维护两套独立的系统(实时和离线),增加了开发工作量。
- 系统之间的数据同步和一致性维护较为困难,需要额外的资源投入。
- 长期维护成本较高,尤其是在扩展和升级时。
- Kappa 架构:
- 由于只有一套系统,开发和维护的工作量显著减少。
- 统一的数据处理逻辑降低了维护难度。
- 长期来看,维护成本更低。
总结:
- Lambda 架构:开发和维护成本高。
- Kappa 架构:开发和维护成本低。
3. 计算开销
- Lambda 枚架:
- 实时处理和离线处理需要分别运行,计算资源被重复利用。
- 离线批处理通常需要较大的计算资源,尤其是在处理大规模历史数据时。
- 总体计算开销较高。
- Kappa 架构:
- 仅使用一套实时处理系统,计算资源利用率更高。
- 历史数据可以通过回放机制重新处理,无需专门的离线计算资源。
- 总体计算开销较低。
总结:
- Lambda 架构:计算开销高。
- Kappa 架构:计算开销低。
4. 实时性
- Lambda 架构:
- 实时处理部分能够提供低延迟的结果,但离线处理部分存在延迟。
- 合并实时和离线结果的过程可能引入额外的延迟。
- 实时性和离线处理的延迟需要权衡。
- Kappa 架构:
- 采用纯实时处理方式,所有数据都通过实时流处理系统处理。
- 没有离线处理的延迟问题,实时性更高。
- 能够提供一致的低延迟结果。
总结:
- Lambda 架构:实时性一般,存在离线处理的延迟。
- Kappa 架构:实时性高,无离线处理延迟。
5. 历史数据处理能力
- Lambda 架构:
- 离线处理系统专门用于处理历史数据,能够对大规模历史数据进行深度分析。
- 支持复杂的批处理任务,适合长期数据分析。
- 历史数据处理能力较强。
- Kappa 架构:
- 通过回放机制(Replay)处理历史数据,即将历史数据作为实时流重新输入到系统中。
- 历史数据处理依赖于实时处理系统的性能和扩展性。
- 历史数据处理能力相对较弱,尤其是对于非常大规模的历史数据。
总结:
- Lambda 架构:历史数据处理能力强。
- Kappa 架构:历史数据处理能力较弱,依赖实时处理系统。
6. 最终表格总结
| 对比维度 | Lambda 架构 | Kappa 架构 |
|---|---|---|
| 复杂度 | 高,需要同时维护实时和离线两套系统。 | 低,仅需一套实时处理系统。 |
| 开发维护成本 | 高,开发和维护两套系统的工作量大。 | 低,开发和维护工作量少,维护成本低。 |
| 计算开销 | 高,实时和离线处理需要分别运行,计算资源重复利用。 | 低,仅需一套实时处理系统,计算资源利用率高。 |
| 实时性 | 一般,实时处理部分低延迟,但离线处理部分存在延迟。 | 高,所有数据通过实时处理系统处理,无离线处理延迟。 |
| 历史数据处理能力 | 强,离线处理系统专门用于处理大规模历史数据。 | 较弱,依赖实时处理系统的回放机制,适合较小规模的历史数据处理。 |
结论
- Lambda 架构适合需要同时处理实时和离线数据的场景,尤其在历史数据处理要求较高的情况下表现更好。
- Kappa 架构更适合追求简单性和实时性的场景,能够显著降低复杂度和维护成本,但历史数据处理能力相对较弱。