aspx怎么做网站推蛙网络
文章目录
- 前言
- 一、环境设计
- 二、动作设计
- 三、状态设计
- 四、神经网路设计
- 五、效果展示
- 其他问题
- 总结
前言
本学期的大作业,要求完成多智能体PPO的乒乓球对抗环境,这里我使用IPPO的方法来实现。
正好之前做过这个单个PPO与pong环境内置的ai对抗的训练,具体见:【游戏ai】从强化学习开始自学游戏ai-1非侵入式玩像素小鸟的第一部分。
想着这次做IPPO的自博弈,应该会好上手不少,但是实际情况,这个Pettingzoo里的环境,还是有些bug的,经过修改后,可以达到良好的效果。
效果见:

代码见:FreeRL_for_play/tree/main/IPPO_for_pong (欢迎star)
一、环境设计
环境见:https://pettingzoo.farama.org/environments/atari/pong/

环境参数:
主要是这里

问题1:
在具体实现训练中,(右边是first_0,左边是second_0),会出现first_0发完第一个球后,若是second_0没有接到球,则会出现不发球的情况。
解决:
在具体的环境里,有发球这个动作,1:Fire,经过测试,这个发球是遵循环境的规则来发球,让上一局赢的(得分+1)一方来发球。
于是设计每过200帧判断当前的分数是否与上一个200帧的分数一致,若是一致,则发球,这样可以避免上述的环境问题。
并且经过测试,即使双方在胶着打乒乓时,互相击球超过了200帧,此时分数没有变化,此发球动作也不会影响两者的击球,即并不会突然停下来发球。
'''
| Action | Behavior |
|:---------:|-----------|
| 0 | No operation |
| 1 | Fire |
| 2 | Move right |
| 3 | Move left |
| 4 | Fire right |
| 5 | Fire left |'
'''
问题2:
此环境如规则所说,不是一个零和环境,在击球时会出现击球的一方-1,被击球的一方0的奖励,此奖励在官方Atari
https://ale.farama.org/environments/pong/中也没有设置此奖励。
此奖励或许会导致误解,在击球后,在一个准备接球的状态时获得一个-1奖励,导致智能体学不好。
并且有此奖励时,奖励函数不会收敛到一个0和的状态。
解决:
将此奖励屏蔽掉。
当奖励出现不是一个为1一个为-1时,将这个奖励都置为0。
问题3:
当问题1被解决时,又迎来一个新问题,即在环境中出现了一步发球动作,此动作会调用env.step(),此时会导致一个大问题和一个小问题,小问题是:使得环境本身计算出的truncation不准确;大问题是:会偶尔出现刚好这一步之后这一步的truncation为True,所以之后就不应该再进行动作,否则就会出现无图像的错误。
解决:
小问题:手动计算truncation逻辑,将发球的步数也加入在内。
大问题:判断发球这步是否已结束,结束则跳过后面的动作,重新reset,不结束则继续,这里有个点要注意一下:关于是否将这发球这步的状态,动作,加入到经验池里,我这里没有加入,因为在动作设计上没有发球这步,所有我并没有添加。
最后环境的默认终止条件是一方达到21分时,则一方获胜,此游戏结束,默认截断条件是帧数达到100000(max_cycles=100000)时为截断,为了实际训练的速度的加快,这里将max_cycles设置为10000。
'''
class ParallelAtariEnv(ParallelEnv, EzPickle):def __init__(self,game,num_players,mode_num=None,seed=None,obs_type="rgb_image",full_action_space=False,env_name=None,max_cycles=100000,render_mode=None,auto_rom_install_path=None,):
'''二、动作设计
同样的,这里将动作设计和【游戏ai】从强化学习开始自学游戏ai-1非侵入式玩像素小鸟的第一部分一样,将动作改成了二维动作,只有下述的2和3的动作。
'''
| Action | Behavior |
|:---------:|-----------|
| 0 | No operation |
| 1 | Fire |
| 2 | Move right |
| 3 | Move left |
| 4 | Fire right |
| 5 | Fire left |'
'''
三、状态设计
状态设计,和【游戏ai】从强化学习开始自学游戏ai-1非侵入式玩像素小鸟的第一部分一样,
参考https://gist.github.com/karpathy/a4166c7fe253700972fcbc77e4ea32c5
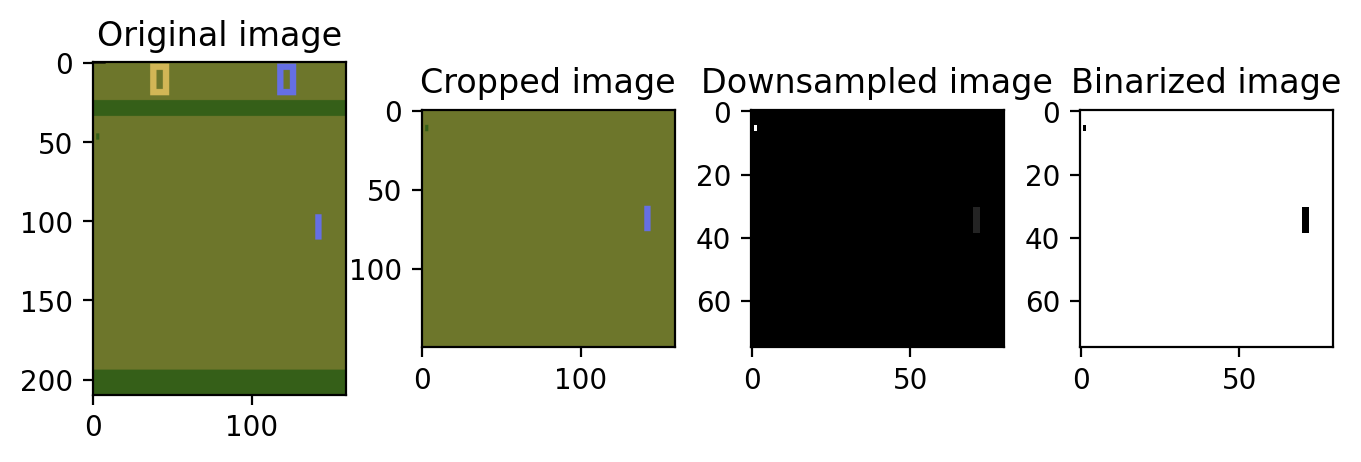
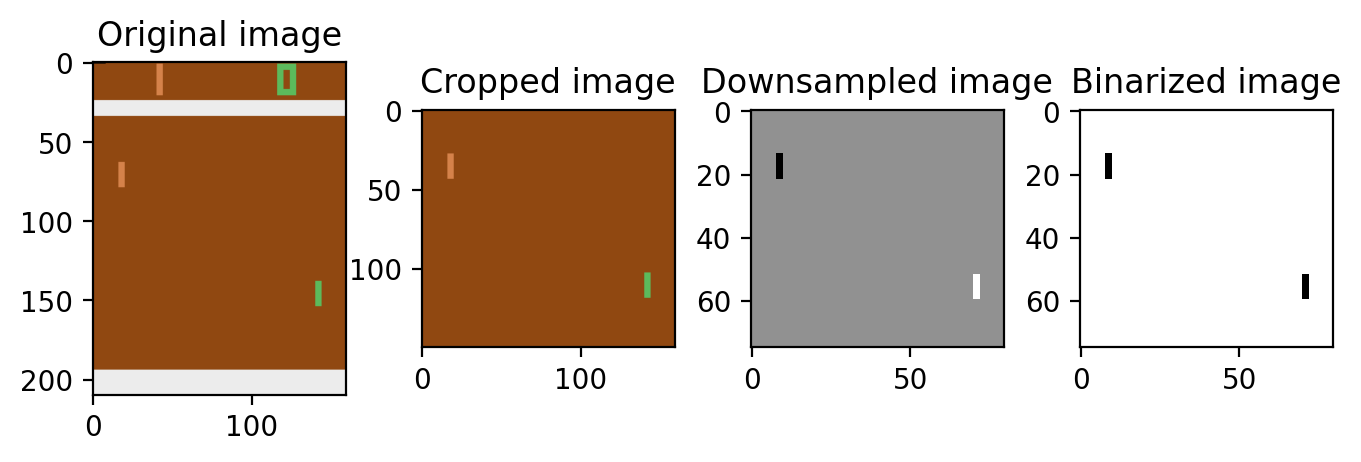
裁剪三通道图基本和参考代码一致:
def prepro(image_in):image=image_in.copy() # 第1张图image = image[35:185] # crop # 第2张图image = image[::2,::2,0] # downsample by factor of 2 # 第3张图image[image == 144] = 0 # 擦除背景 (background type 1) # 第4张图image[image == 109] = 0 # 擦除背景image[image != 0] = 1 # 转为灰度图,除了黑色外其他都是白色 return image.astype(np.float32).ravel()
此裁剪展示参考代码:【强化学习】玩转Atari-Pong游戏
在背景为109的裁剪展示
背景为144的裁剪展示
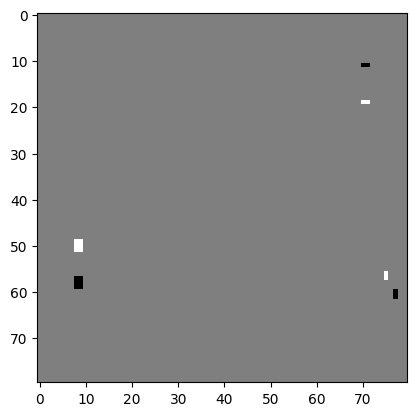
参考代码的状态输入:
第1帧为obs输入全为0的图,展成1维,将当前帧赋给上一帧
第2及之后的帧为obs输入为当前帧减去上一帧的图(展成1维),将当前帧赋给上一帧
效果展示为如下:
我的代码的状态输入:
第1帧为obs输入全为0的图,展成1维,将当前帧赋给上一帧(第一帧)
第2及之后的帧为obs输入为当前帧减去上一帧(此帧没变一直为第一帧)的图(展成1维)
这是我在实验时,不小心忘记加入prev_x = cur_x的结果
效果展示如下:
但是这个效果竟然比参考代码的收敛效果好一点,于是就一直保留此状态设计。
效果对比如下,5为参考代码的效果,4为我的效果。
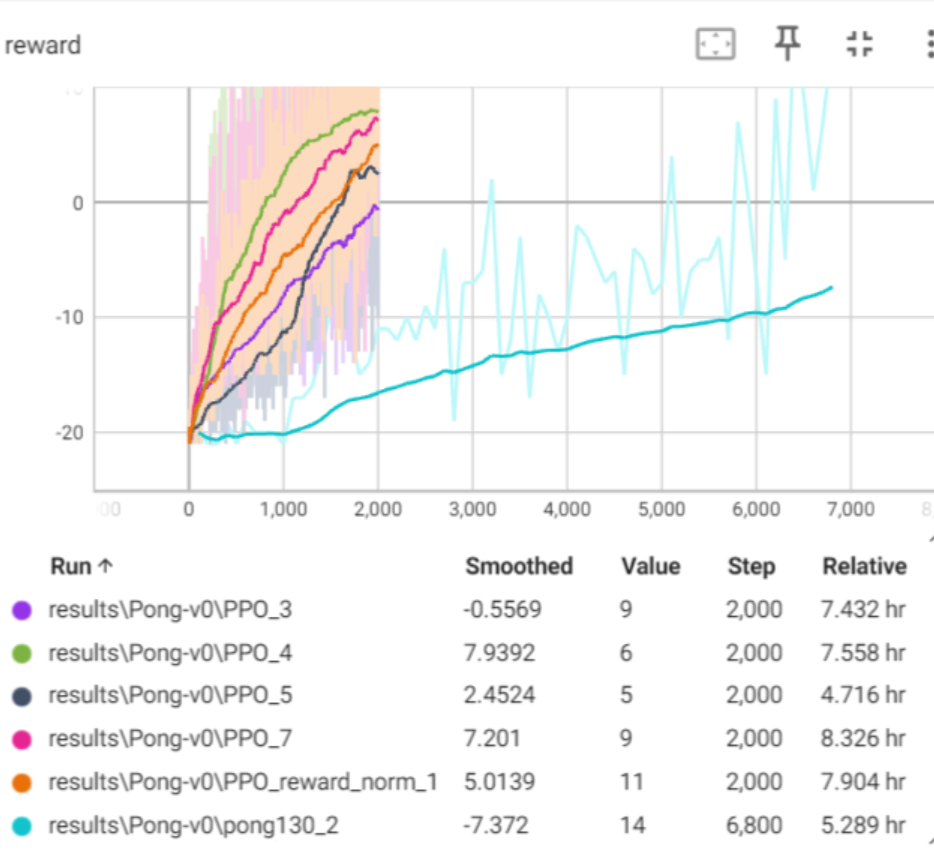
收敛时间上还是4快,
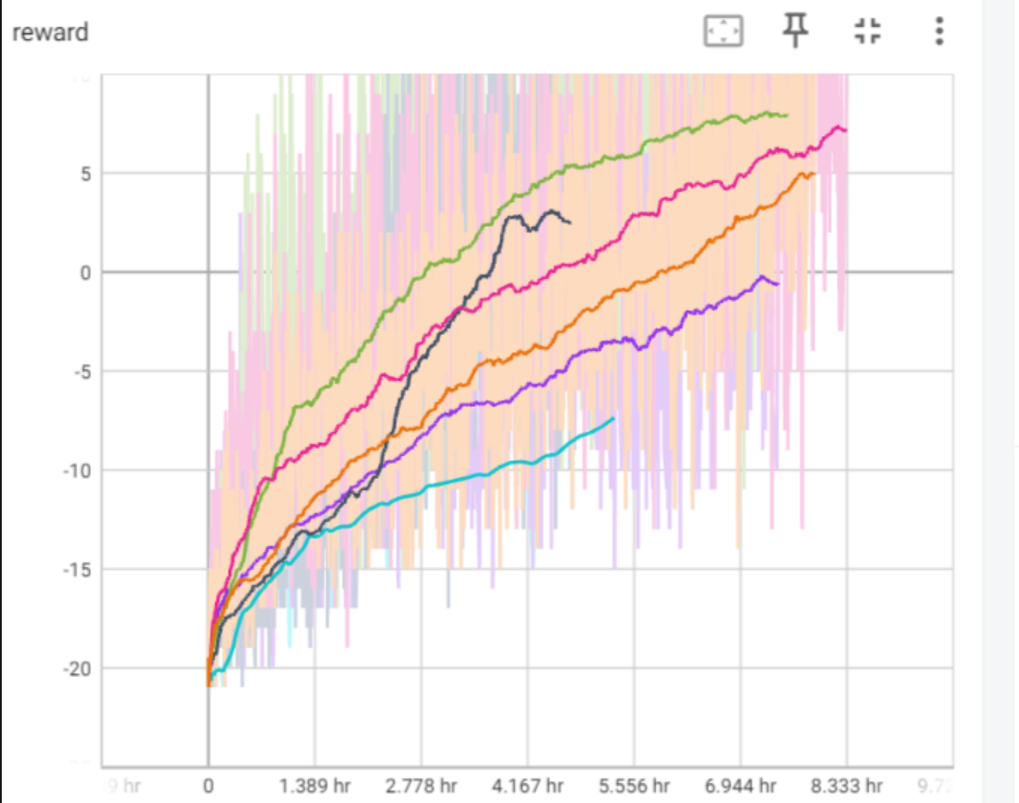
注:这里4我再测试一次是4.4h,应该是没选择用cpu训练的缘故导致的7h。
四、神经网路设计
这里Actor和Critic网路还是沿用简单的MLP设计,而没有使用cnn网路的设计
具体见:【游戏ai】从强化学习开始自学游戏ai-1非侵入式玩像素小鸟的第一部分
原因:
使用cnn网路来训练时,训练的效果太慢了
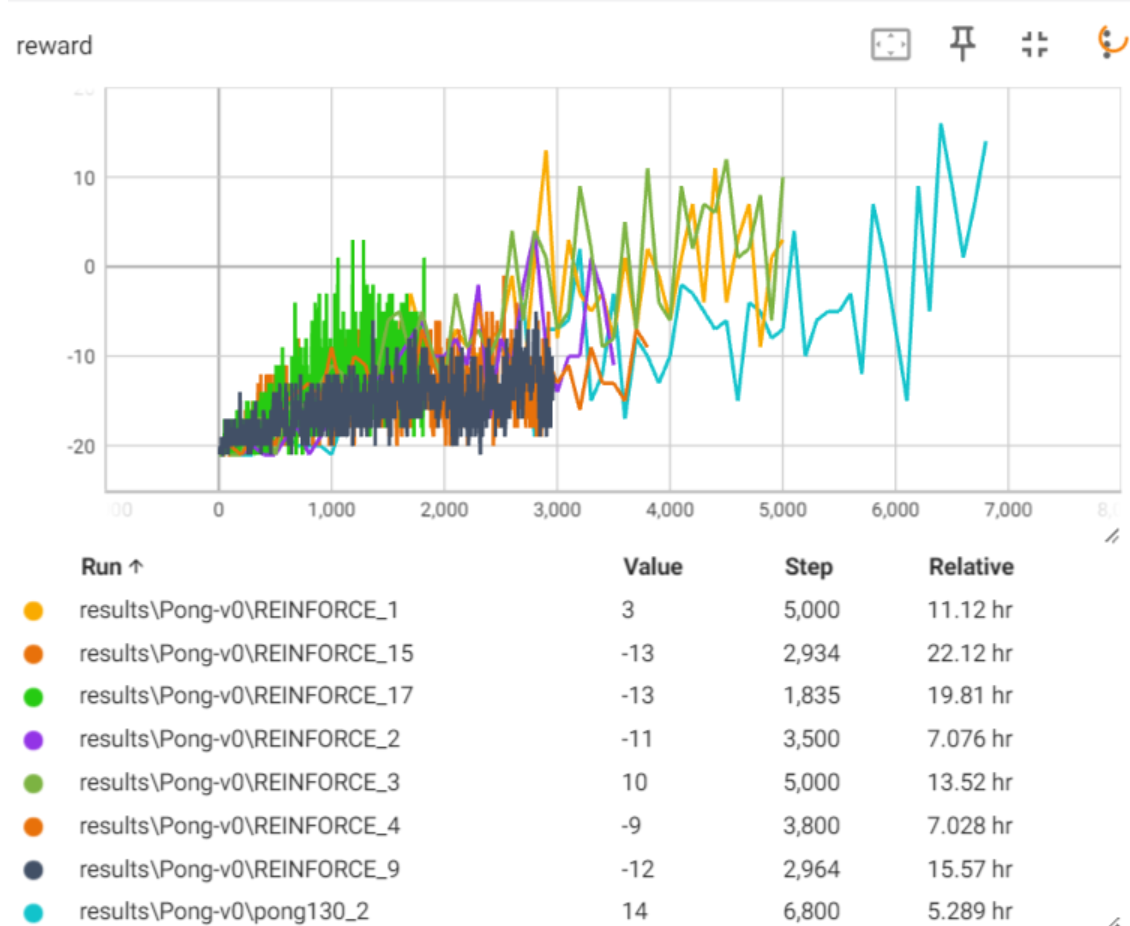
效果如下:
9,15,17为cnn训练,其余1,2,3,4,9为mlp训练。
五、效果展示
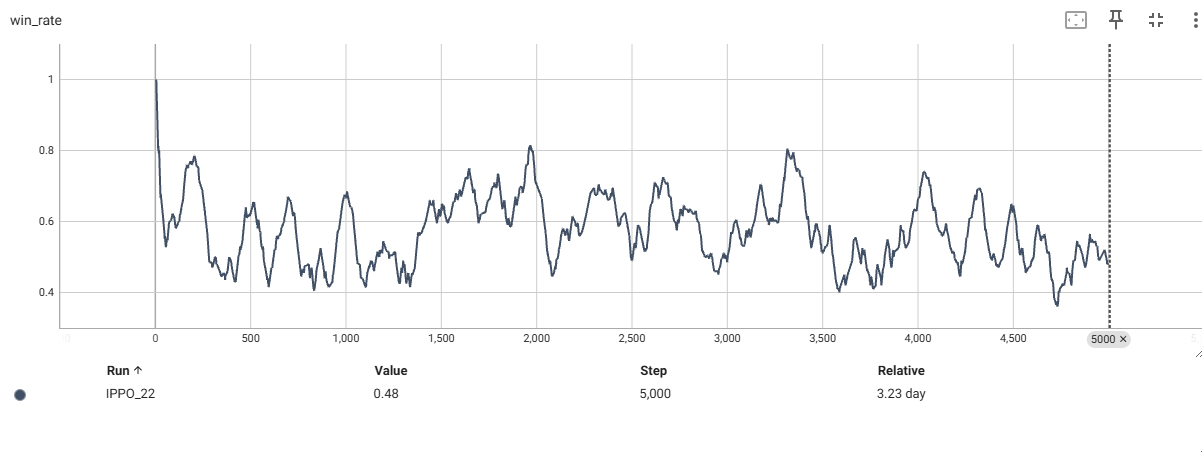
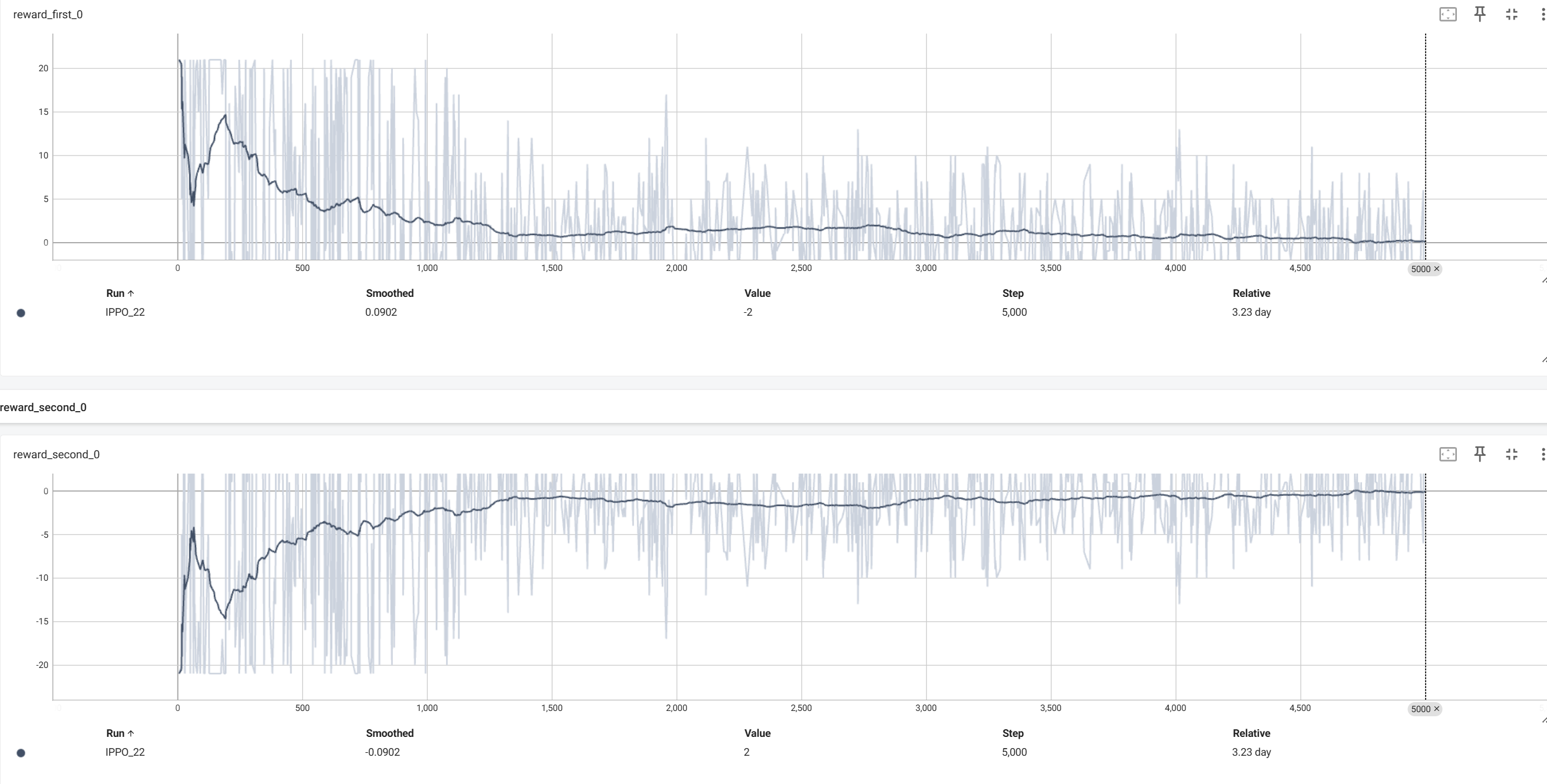
训练时,将两个智能体的奖励,终局分数,first智能体的胜率进行了保存。
由于这里将环境的截断设置为10000,会有可能在两者没有决出胜负(一方达到21)的情况下进行截断,所以将胜率设计如下:
## 计算胜率if episode_score[env_agents[0]] > episode_score[env_agents[1]]:win_list.append(1)elif episode_score[env_agents[0]] == episode_score[env_agents[1]]:win_list.append(0.5)else:win_list.append(0)win_rate = sum(win_list) / len(win_list) if len(win_list) < 100 else sum(win_list[-100:]) / 100
最终效果如下:
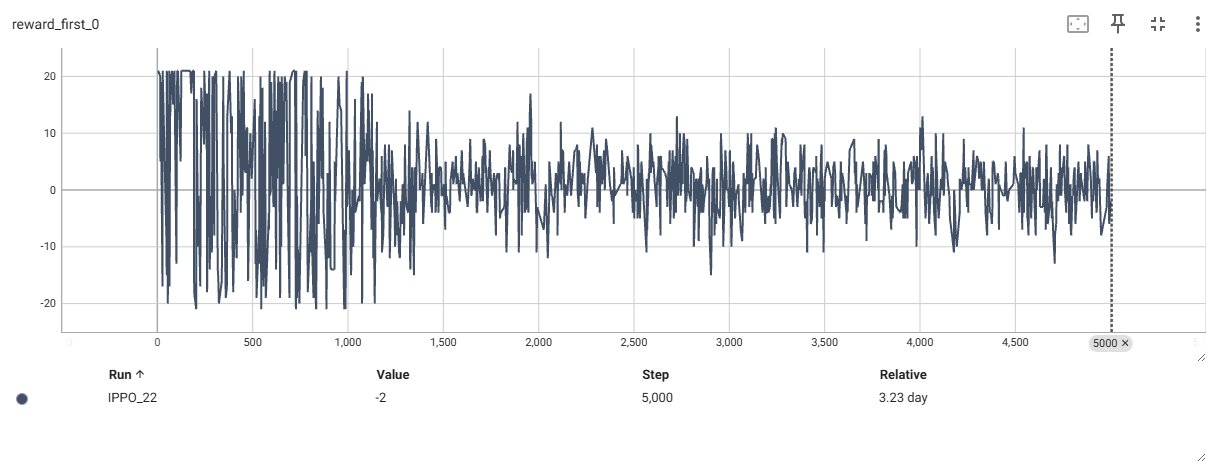
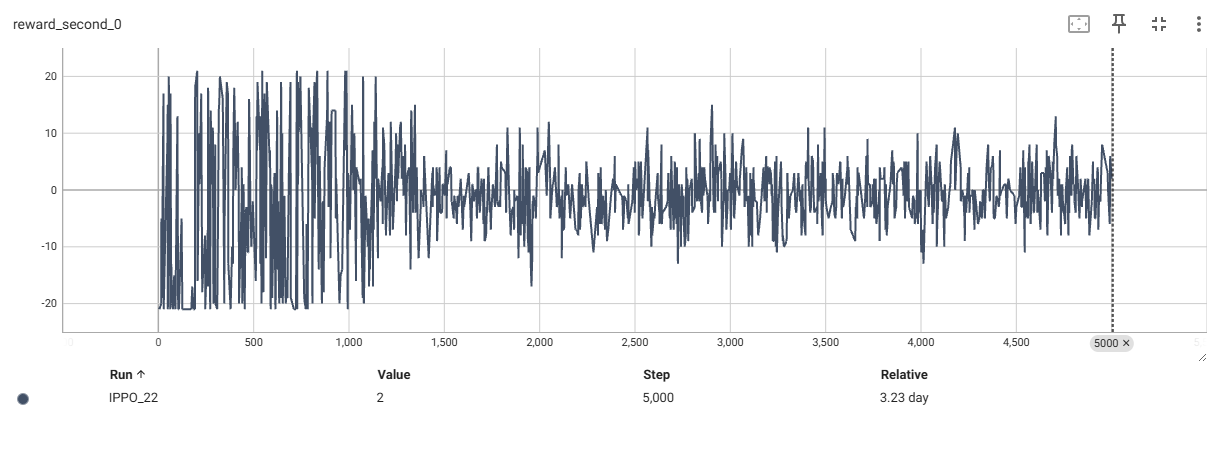
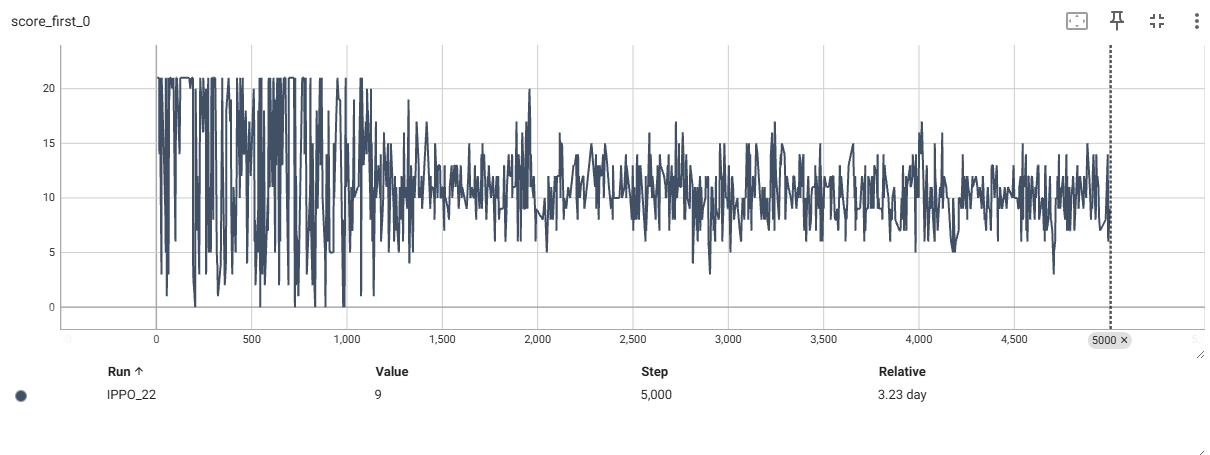
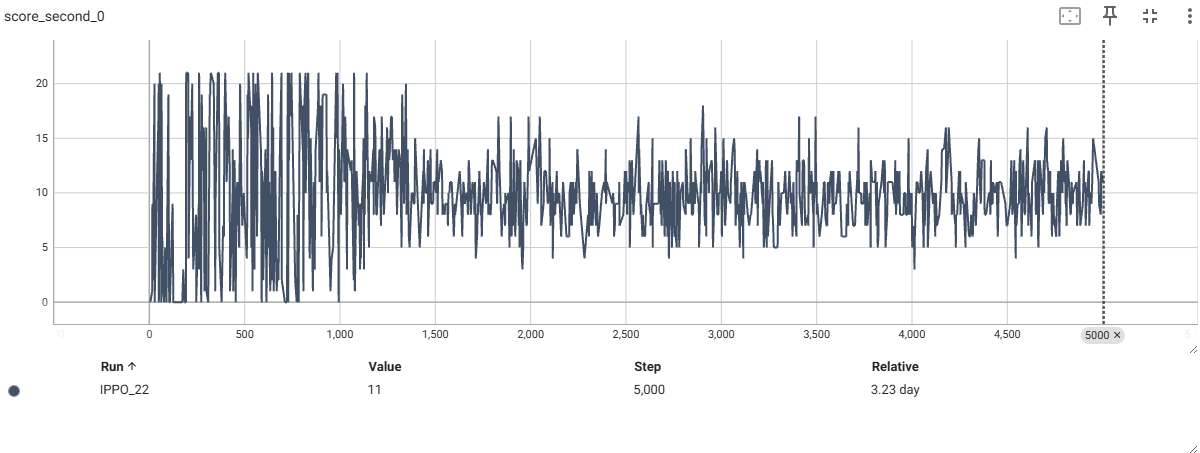
平滑后的奖励曲线
平滑后的分数曲线
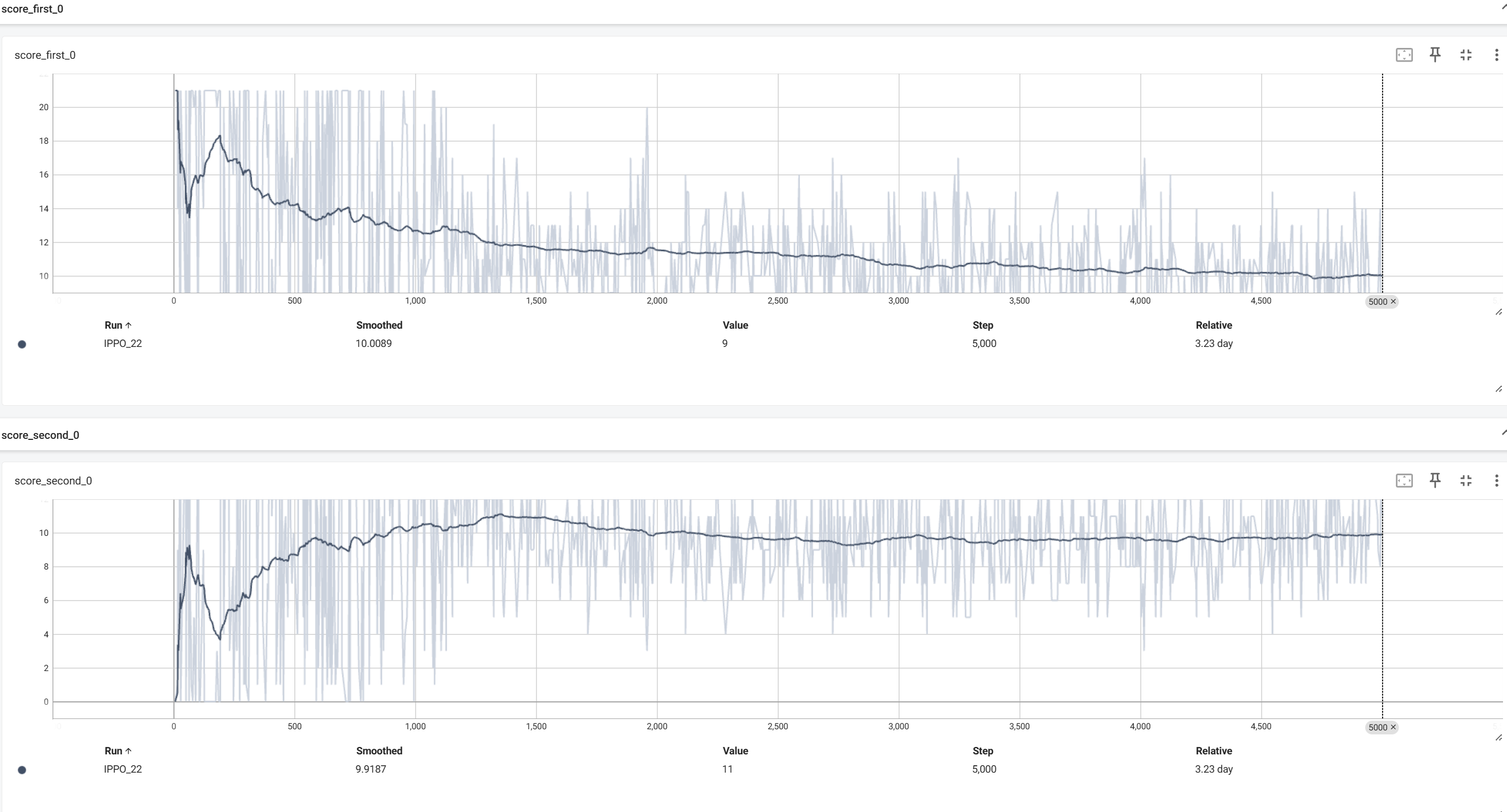
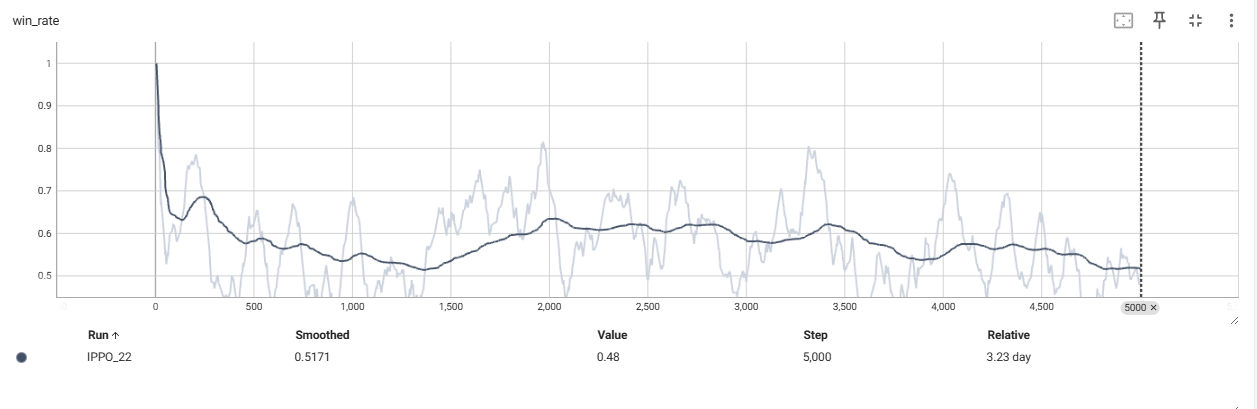
从上可以看到奖励曲线,最终都收敛到了0附近,分数曲线收敛到了相近的分数附近,first智能体的胜率为50%左右。
这里分数曲线收敛到了10附近大概率是因为我环境的截断设置为10000帧的缘故,如果加大这个数目,可能最终两者都收敛到20附近,(21分获胜)。
这也符合零和博弈应该的效果,大家都是50%的获胜概率,50%的概率获得1分。50%的概率丢一分,那么奖励曲线就收敛到0附近了。
其他问题
问题:为什么使用常见意义上的MAPPO不能实现此自博弈训练。
解决:
IPPO和MAPPO的区别
宏观上 IPPO和MAPPO的区别就是critic的输入不一样,MAPPO的critic是global state信息,而IPPO的critic只有local obs。
微观上 MAPPO的训练逻辑是训所有agent的reward 即 (+1 -1 ) +(-1 +1)+ (-1 +1) = 0
IPPO是各自训自己的 (+1 -1 -1)(第一个和) (-1+1 +1)(第二个和)。
所以导致MAPPO只能用来合作环境,而IPPO既可以合作也可以博弈
老师说可以将MAPPO来当成一个PPO(智能体)来看,另外一个MAPPO当作对手智能体来看,可以这样学。
这里没有实现此想法,尝试用IPPO来做自博弈。
问题:环境的安装
解决:此环境的安装在windows上不可行,在WSL上的linux下解决安装问题
总结
此次项目需要很多前置经验和知识,是一次难度很大的项目,但是也使我获益良多,针对各种各样的环境,强化学习的训练难点有时即在算法的挑选上,又在环境的搭建上,又可能在奖励的设计上,也有可能是状态的挑选上,无论是哪个没有做到位,都有可能导致项目的失败。