网站建设维护是啥意思wordpress仿国际
本文基于B站up主 code秘密花园 的代码编写,源码地址 ,并说明有关潜在的坑。如果无法打开也可以在文章后面找到源码。该代码使用unsloth框架微调DeepSeek-R1-Distill-Llama-8B,数据集使用https://huggingface.co/datasets/Conard/fortune-telling, 旨在将模型微调为一个算命大师。
数据集格式:{ Question, Response, Complex_CoT } ,因为微调的是一个推理模型,所以包含思维链。
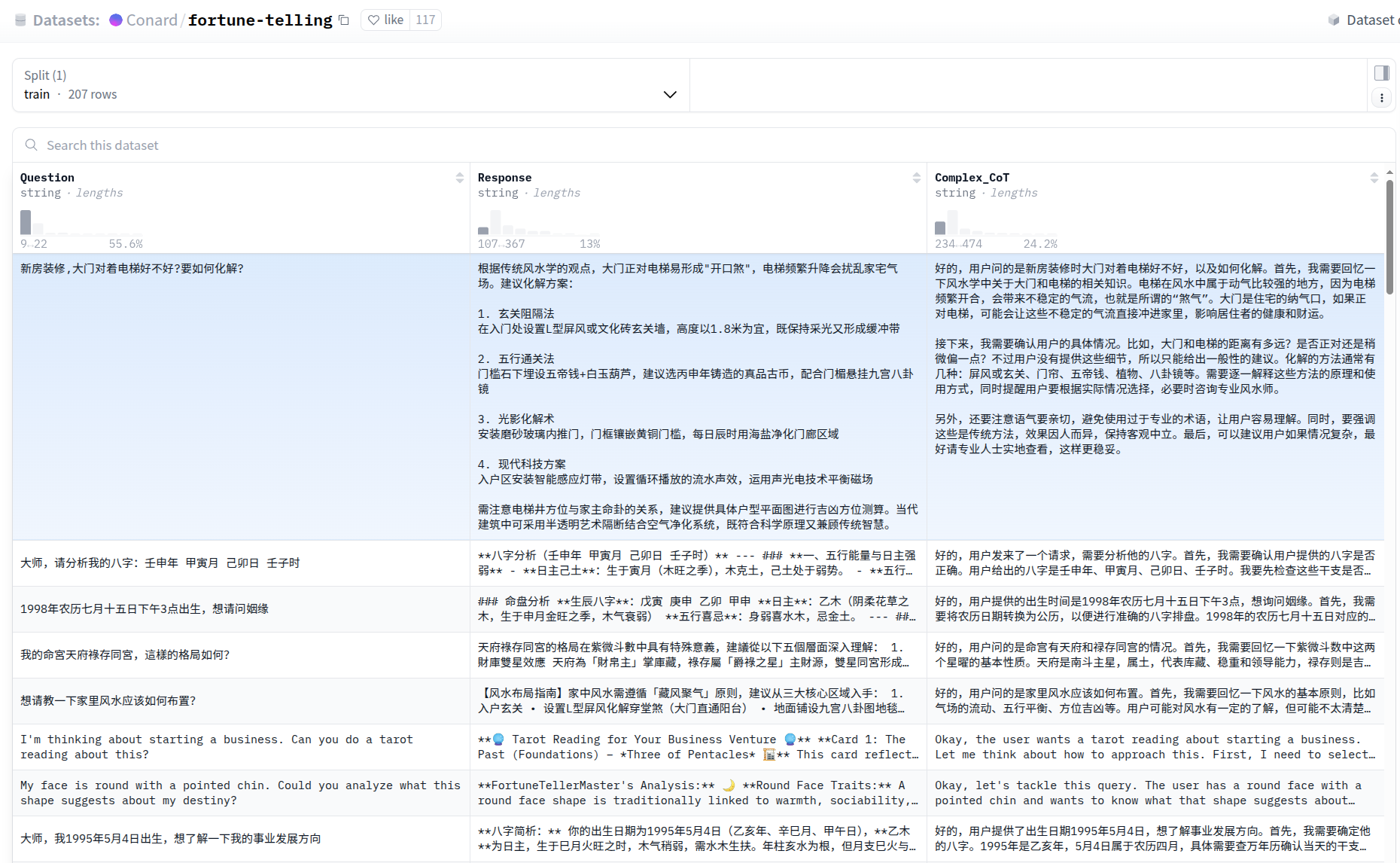
微调的大致流程如下
环境安装
需要安装conda、cuda、unsloth。conda和cuda不赘述了,unsloth可在官方仓库中找到安装方法。
conda create --name unsloth_env \python=3.11 \pytorch-cuda=12.1 \pytorch cudatoolkit xformers -c pytorch -c nvidia -c xformers \-y
conda activate unsloth_envpip install unsloth源码
设置代理
这一步不是源码给出的。主要用于设置代码涉及网络请求的时候设置代理,避免下载失败。前提是已经有了代理,比如clash的代理端口是7890,这时就可以直接直接将127.0.0.1:7890作为代理地址。
import os
os.environ["http_proxy"] = "http://127.0.0.1:7890"
os.environ["https_proxy"] = "http://127.0.0.1:7890"加载模型
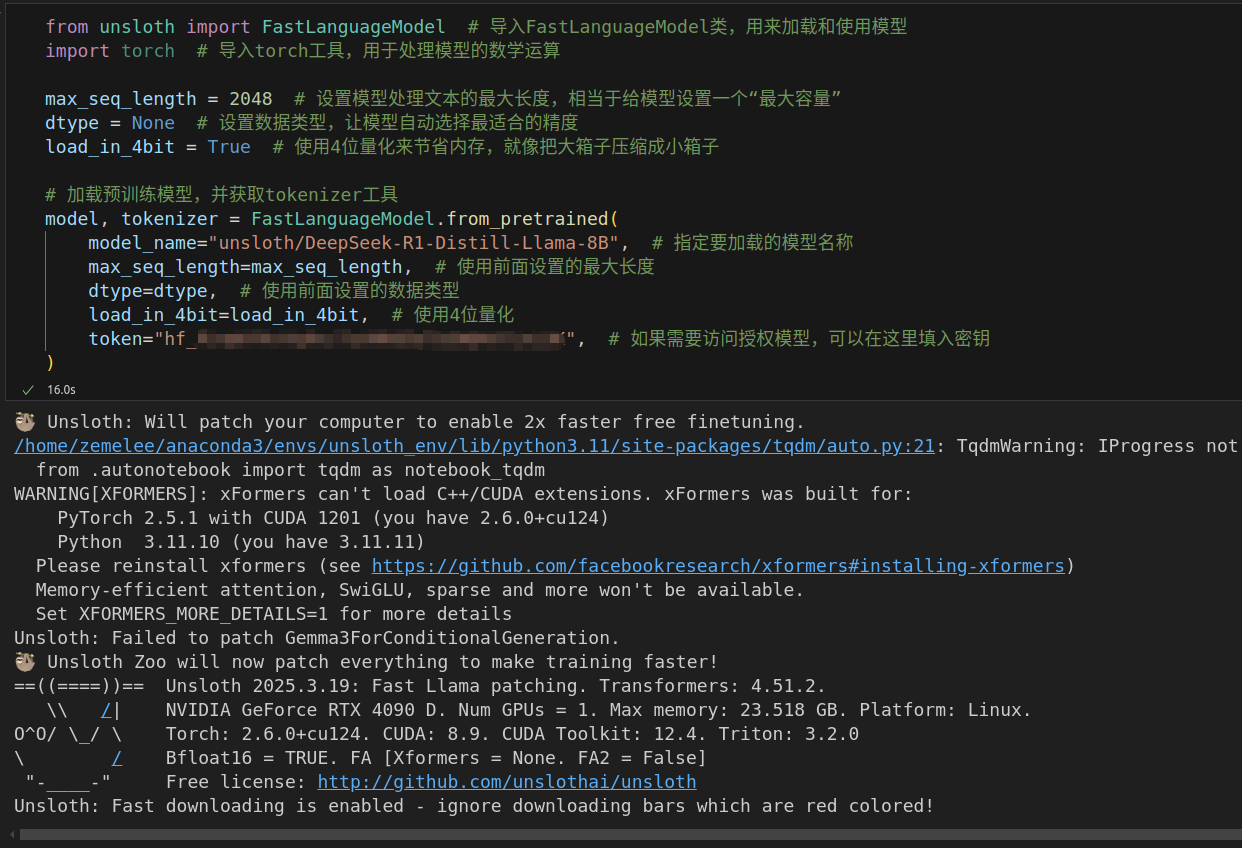
from unsloth import FastLanguageModel # 导入FastLanguageModel类,用来加载和使用模型
import torch # 导入torch工具,用于处理模型的数学运算max_seq_length = 2048 # 设置模型处理文本的最大长度,相当于给模型设置一个“最大容量”
dtype = None # 设置数据类型,让模型自动选择最适合的精度
load_in_4bit = True # 使用4位量化来节省内存,就像把大箱子压缩成小箱子# 加载预训练模型,并获取tokenizer工具
model, tokenizer = FastLanguageModel.from_pretrained(model_name="unsloth/DeepSeek-R1-Distill-Llama-8B", # 指定要加载的模型名称max_seq_length=max_seq_length, # 使用前面设置的最大长度dtype=dtype, # 使用前面设置的数据类型load_in_4bit=load_in_4bit, # 使用4位量化token="hf_...", # 如果需要访问授权模型,可以在这里填入密钥
)运行效果如下,这一步是在从huggingface上下载unsloth/DeepSeek-R1-Distill-Llama-8B模型,也就是 https://huggingface.co/unsloth/DeepSeek-R1-Distill-Llama-8B 。其中token参数不需要填写。
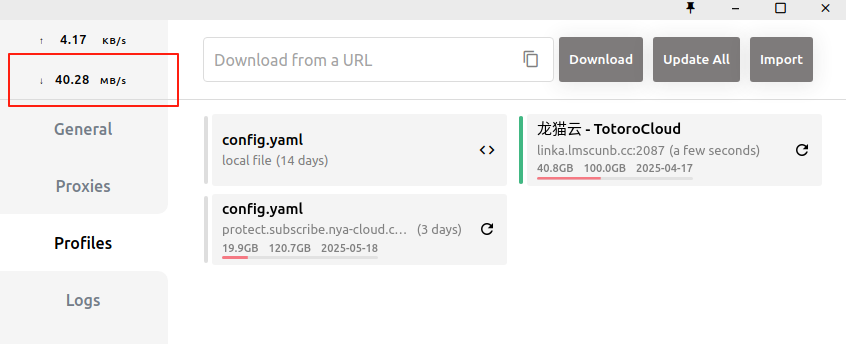
如果下载的时候报错,可以参考下设置代理的步骤。可能不会出现进度条,但是通过clash的显示可以确定,他正在疯狂下载模型。网速飙到了40MB/s...
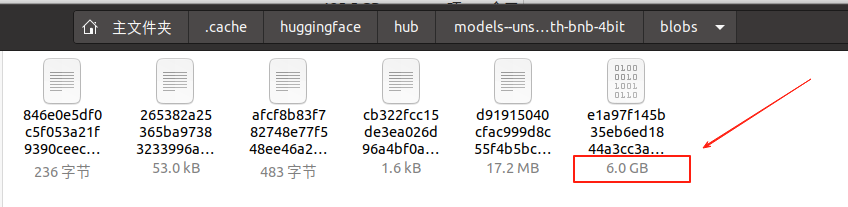
模型下载地址默认在 ~/.cache/huggingface/hub/models--unsloth--deepseek-r1-distill-llama-8b-unsloth-bnb-4bit/下。 (ubuntu)
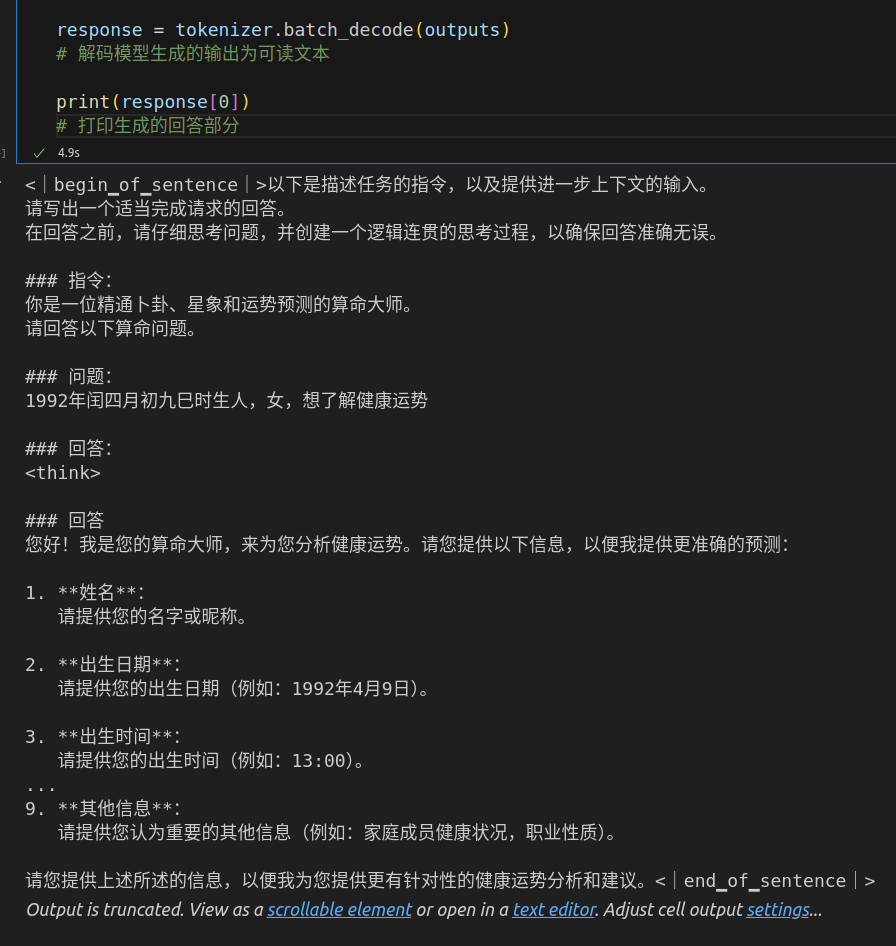
微调前测试
prompt_style = """以下是描述任务的指令,以及提供进一步上下文的输入。
请写出一个适当完成请求的回答。
在回答之前,请仔细思考问题,并创建一个逻辑连贯的思考过程,以确保回答准确无误。### 指令:
你是一位精通卜卦、星象和运势预测的算命大师。
请回答以下算命问题。### 问题:
{}### 回答:
<think>{}"""
# 定义提示风格的字符串模板,用于格式化问题question = "1992年闰四月初九巳时生人,女,想了解健康运势"
# 定义具体的算命问题FastLanguageModel.for_inference(model)
# 准备模型以进行推理inputs = tokenizer([prompt_style.format(question, "")], return_tensors="pt").to("cuda")
# 使用 tokenizer 对格式化后的问题进行编码,并移动到 GPUoutputs = model.generate(input_ids=inputs.input_ids,attention_mask=inputs.attention_mask,max_new_tokens=1200,use_cache=True,
)
# 使用模型生成回答response = tokenizer.batch_decode(outputs)
# 解码模型生成的输出为可读文本print(response[0])
# 打印生成的回答部分一个可能的回复。
加载数据集
# 定义结束标记(EOS_TOKEN),用于指示文本的结束
EOS_TOKEN = tokenizer.eos_token # 必须添加结束标记# 导入数据集加载函数
from datasets import load_dataset
# 加载指定的数据集,选择中文语言和训练集的前200条记录
dataset = load_dataset("Conard/fortune-telling", 'default', split = "train[0:200]", trust_remote_code=True)
# 打印数据集的列名,查看数据集中有哪些字段
print(dataset.column_names)数据集保存在~/.cache/huggingface/datasets下
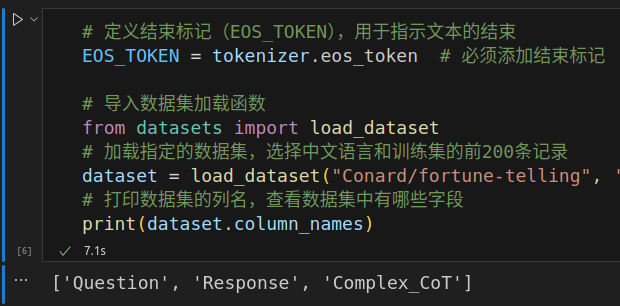
执行会加载数据集,并打印数据集的已有字段,即{ Question, Response, Complex_CoT }
格式化数据集
# 定义一个函数,用于格式化数据集中的每条记录
def formatting_prompts_func(examples):# 从数据集中提取问题、复杂思考过程和回答inputs = examples["Question"]cots = examples["Complex_CoT"]outputs = examples["Response"]texts = [] # 用于存储格式化后的文本# 遍历每个问题、思考过程和回答,进行格式化for input, cot, output in zip(inputs, cots, outputs):# 使用字符串模板插入数据,并加上结束标记text = train_prompt_style.format(input, cot, output) + EOS_TOKENtexts.append(text) # 将格式化后的文本添加到列表中return {"text": texts, # 返回包含所有格式化文本的字典}dataset = dataset.map(formatting_prompts_func, batched = True)
dataset["text"][0]设置lora参数
FastLanguageModel.for_training(model)model = FastLanguageModel.get_peft_model(model, # 传入已经加载好的预训练模型r = 16, # 设置 LoRA 的秩,决定添加的可训练参数数量target_modules = ["q_proj", "k_proj", "v_proj", "o_proj", # 指定模型中需要微调的关键模块"gate_proj", "up_proj", "down_proj"],lora_alpha = 16, # 设置 LoRA 的超参数,影响可训练参数的训练方式lora_dropout = 0, # 设置防止过拟合的参数,这里设置为 0 表示不丢弃任何参数bias = "none", # 设置是否添加偏置项,这里设置为 "none" 表示不添加use_gradient_checkpointing = "unsloth", # 使用优化技术节省显存并支持更大的批量大小random_state = 3407, # 设置随机种子,确保每次运行代码时模型的初始化方式相同use_rslora = False, # 设置是否使用 Rank Stabilized LoRA 技术,这里设置为 False 表示不使用loftq_config = None, # 设置是否使用 LoftQ 技术,这里设置为 None 表示不使用
)设置SFT的超参数
from trl import SFTTrainer # 导入 SFTTrainer,用于监督式微调
from transformers import TrainingArguments # 导入 TrainingArguments,用于设置训练参数
from unsloth import is_bfloat16_supported # 导入函数,检查是否支持 bfloat16 数据格式trainer = SFTTrainer( # 创建一个 SFTTrainer 实例model=model, # 传入要微调的模型tokenizer=tokenizer, # 传入 tokenizer,用于处理文本数据train_dataset=dataset, # 传入训练数据集dataset_text_field="text", # 指定数据集中 文本字段的名称max_seq_length=max_seq_length, # 设置最大序列长度dataset_num_proc=2, # 设置数据处理的并行进程数packing=False, # 是否启用打包功能(这里设置为 False,打包可以让训练更快,但可能影响效果)args=TrainingArguments( # 定义训练参数per_device_train_batch_size=2, # 每个设备(如 GPU)上的批量大小gradient_accumulation_steps=4, # 梯度累积步数,用于模拟大批次训练warmup_steps=5, # 预热步数,训练开始时学习率逐渐增加的步数max_steps=75, # 最大训练步数learning_rate=2e-4, # 学习率,模型学习新知识的速度fp16=not is_bfloat16_supported(), # 是否使用 fp16 格式加速训练(如果环境不支持 bfloat16)bf16=is_bfloat16_supported(), # 是否使用 bfloat16 格式加速训练(如果环境支持)logging_steps=1, # 每隔多少步记录一次训练日志optim="adamw_8bit", # 使用的优化器,用于调整模型参数weight_decay=0.01, # 权重衰减,防止模型过拟合lr_scheduler_type="linear", # 学习率调度器类型,控制学习率的变化方式seed=3407, # 随机种子,确保训练结果可复现output_dir="outputs", # 训练结果保存的目录report_to="none", # 是否将训练结果报告到外部工具(如 WandB),这里设置为不报告),
)开始训练
trainer_stats = trainer.train()然后显卡就开始疯狂旋转了~~
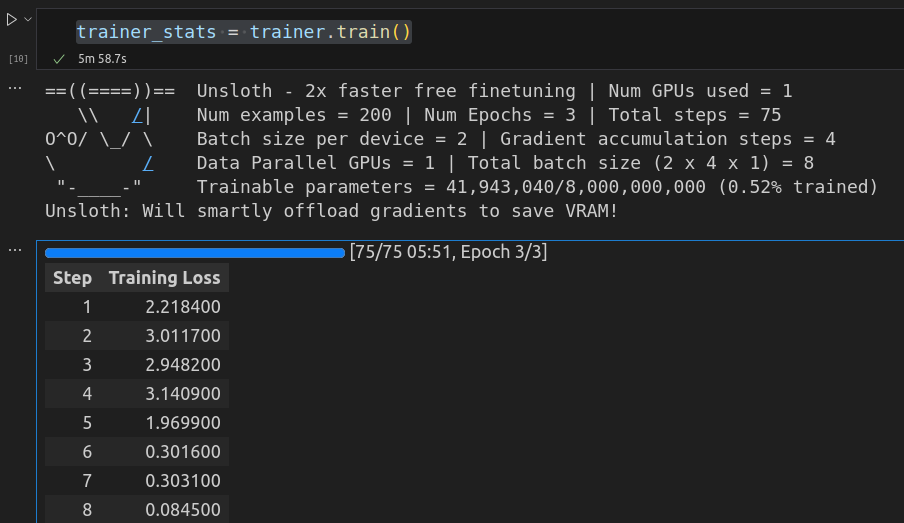
设置SFT的超参数步骤里,steps设置的75,75步之后,loss为0.001200,结束训练了。
# 将模型切换到推理模式,准备回答问题
FastLanguageModel.for_inference(model)
question = "我是2001年9月出生,我的学业运势如何??"
# 将问题转换成模型能理解的格式,并发送到 GPU 上
inputs = tokenizer([prompt_style.format(question, "")], return_tensors="pt").to("cuda")# 让模型根据问题生成回答,最多生成 4000 个新词
outputs = model.generate(input_ids=inputs.input_ids, # 输入的数字序列attention_mask=inputs.attention_mask, # 注意力遮罩,帮助模型理解哪些部分重要max_new_tokens=4000, # 最多生成 4000 个新词use_cache=True, # 使用缓存加速生成
)# 将生成的回答从数字转换回文字
response = tokenizer.batch_decode(outputs)# 打印回答
print(response[0])测试模型
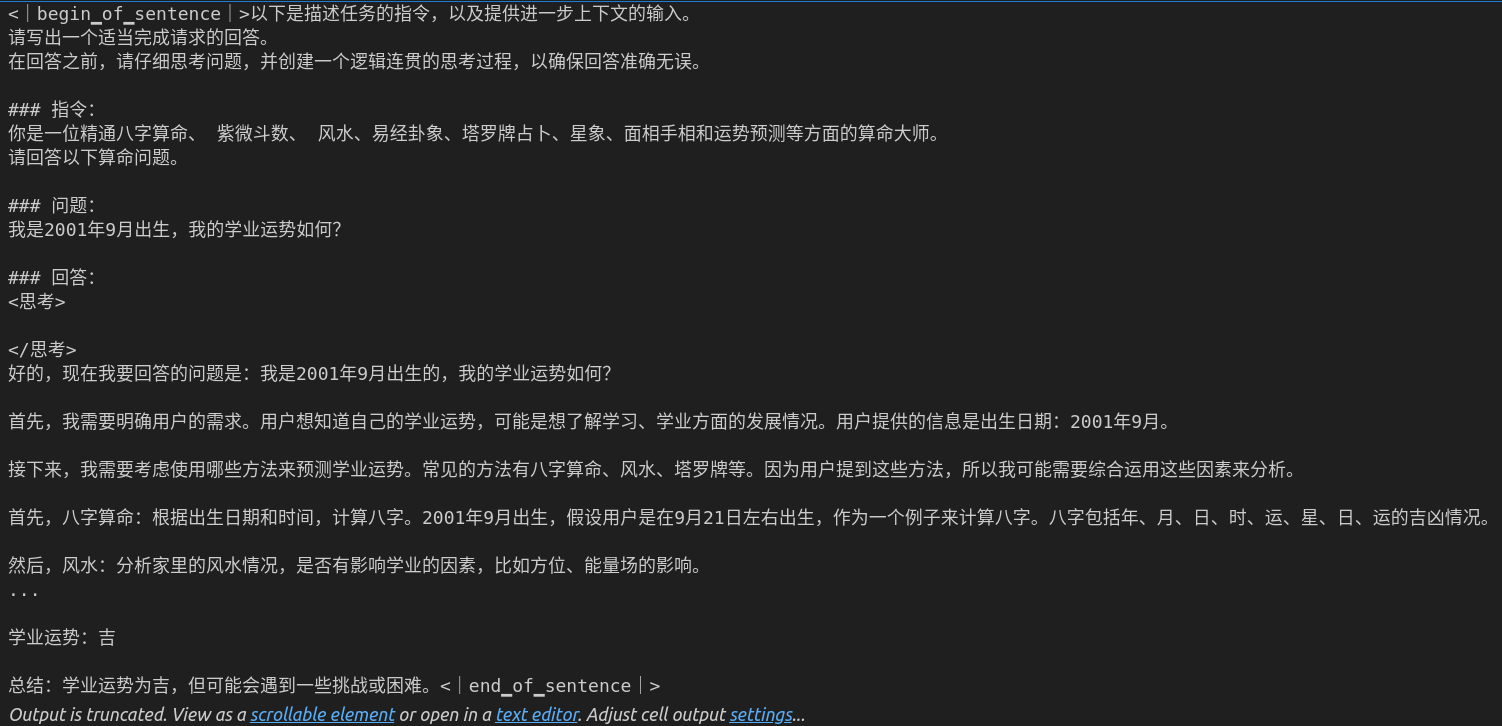
ennn说实话我看不出来。。。。管他呢,不瞎回答就行了。保存模型!
保存模型
GGUF是一种用于存储LLM数据的高效量化格式。源码里提供了3种保存方法,4b、8b、16b量化。代码选择的8b量化,在文件大小和运行速度之间折了个中。然后根目录就会多一个model文件夹,即模型文件夹。
# 将模型保存为 8 位量化格式(Q8_0)
# 这种格式文件小且运行快,适合部署到资源受限的设备
if True: model.save_pretrained_gguf("model", tokenizer,)# 将模型保存为 16 位量化格式(f16)
# 16 位量化精度更高,但文件稍大
if False: model.save_pretrained_gguf("model_f16", tokenizer, quantization_method = "f16")# 将模型保存为 4 位量化格式(q4_k_m)
# 4 位量化文件最小,但精度可能稍低
if False: model.save_pretrained_gguf("model", tokenizer, quantization_method = "q4_k_m")保存有可能会报错:RuntimeError: Unsloth: The file 'llama.cpp/llama-quantize' or 'llama.cpp/quantize' does not exist,可以参考以下链接解决:
https://github.com/unslothai/unsloth/issues/1936
然后下次就可以通过直接指定本地目录就可以加载模型了
model, tokenizer = FastLanguageModel.from_pretrained(model_name="/home/zemelee/code/q11e/model", # 模型保存路径max_seq_length=max_seq_length, # 使用前面设置的最大长度dtype=dtype, # 使用前面设置的数据类型load_in_4bit=load_in_4bit, # 使用4位量化
)将模型上传到hf
上传需要hf的令牌,可到hf的官网创建并填写在代码中。必须选择具有写权限的token,因为需要将模型上传到自己的仓库中。将自己的用户名和仓库名写入代码中,不需要提前创建仓库。
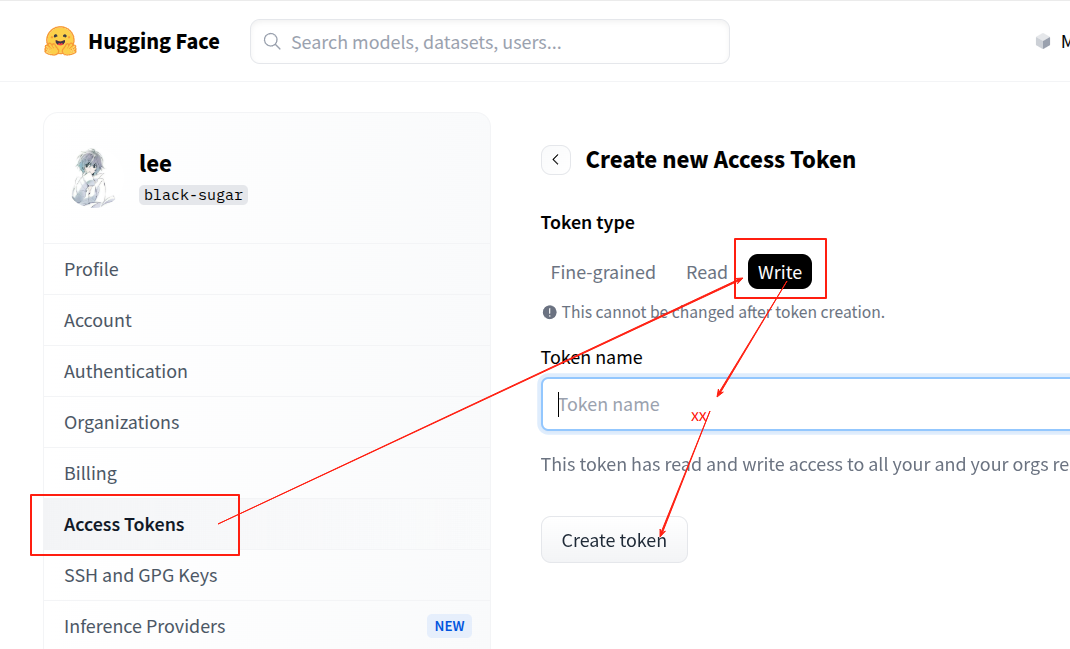
# huggingface 令牌
HUGGINGFACE_TOKEN = "hf_...."
# 导入 Hugging Face Hub 的 create_repo 函数,用于创建一个新的模型仓库
from huggingface_hub import create_repo# 在 Hugging Face Hub 上创建一个新的模型仓库
create_repo("black-sugar/TVBS", token=HUGGINGFACE_TOKEN, exist_ok=True)# 将模型和分词器上传到 HuggingFace Hub 上的仓库
model.push_to_hub_gguf("black-sugar/TVBS", tokenizer, token=HUGGINGFACE_TOKEN)然后模型就会自动创建仓库并上传模型文件。虽然不一定有进度条,但是clash的上传速率飙到了49MB/s,说明正在上传。
然后查看:https://huggingface.co/black-sugar/TVBS 模型有了!
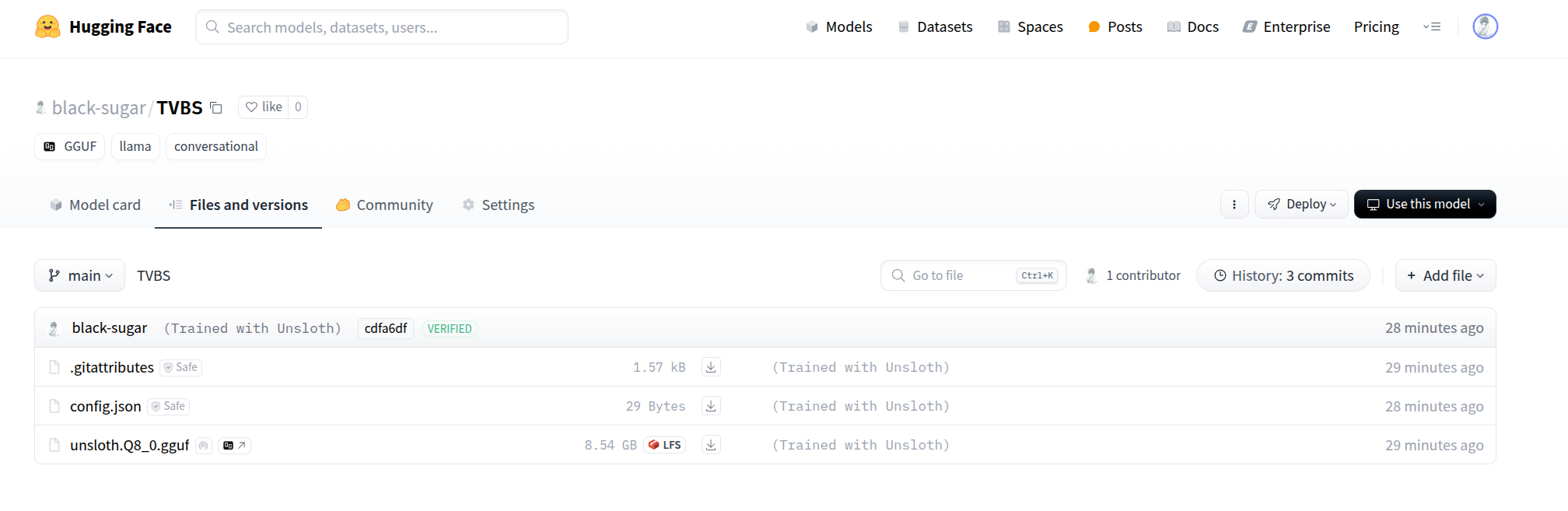
ollama跑模型
上传之后,可以通过以下命令加载模型。
ollama run hf.co/black-sugar/TVBS试了一下ollama run /home/zemelee/code/q11e/model,无法加载,不清楚为什么。
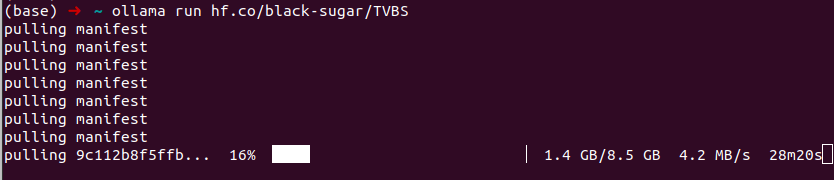
但是有可能会卡在小文件的下载上,这是需要将原命令中的“hf.co”改为“hf-mirror.com”,执行一次新的命令。然后就能下载完成了。