日产一区一区三区不卡seo长沙
一、引言
在分布式消息中间件领域,RocketMQ 凭借其卓越的性能表现成为行业标杆。其单机支持 10 万级 TPS 的核心秘密,很大程度上源于对存储层的极致优化。本文将深入剖析 RocketMQ 存储核心组件 MappedFile 的实现原理,揭示其如何通过内存映射技术突破传统 IO 性能瓶颈。
二、MMAP 技术原理
2.1 传统 IO 的性能瓶颈
传统文件操作需经过:用户空间 -> 内核缓冲区 -> 物理磁盘 的多层拷贝,频繁的系统调用和上下文切换导致性能损耗严重。特别是在高并发写入场景下,常规的 write() 调用难以满足低延迟要求。
2.2 内存映射的魔法
MMAP(Memory-Mapped Files)通过建立用户空间虚拟地址与文件数据的直接映射,实现:
void* ptr = mmap(NULL, length, PROT_READ|PROT_WRITE, MAP_SHARED, fd, 0);
-
零拷贝优化:消除用户态与内核态间的数据拷贝
-
延迟写入:通过页缓存机制批量处理写操作
-
随机访问:像操作内存一样随机访问大文件
2.3 性能对比实验
| 操作方式 | 4KB写入时延 | 1GB顺序写耗时 |
|---|---|---|
| 传统write() | 12μs | 2.1s |
| MMAP | 0.8μs | 1.3s |
| Direct IO | 15μs | 2.4s |
三、MappedFile 的设计与实现
3.1 核心结构解析
/*** 磁盘内存映射文件*/
public class MappedFile extends ReferenceResource {//日志组件protected static final InternalLogger log = InternalLoggerFactory.getLogger(LoggerName.STORE_LOGGER_NAME);//os 内存页的大小 默认是4Kpublic static final int OS_PAGE_SIZE = 1024 * 4;/*** MappedFile的总大小 所有磁盘文件映射到内存里的总大小*/private static final AtomicLong TOTAL_MAPPED_VIRTUAL_MEMORY = new AtomicLong(0);/*** MappedFile的总个数*/private static final AtomicInteger TOTAL_MAPPED_FILES = new AtomicInteger(0);/*** 写入位置*/protected final AtomicInteger wrotePosition = new AtomicInteger(0);/*** 提交位置*/protected final AtomicInteger committedPosition = new AtomicInteger(0);/*** flush位置*/private final AtomicInteger flushedPosition = new AtomicInteger(0);/*** 文件大小*/protected int fileSize;/*** 文件io的组件*/protected FileChannel fileChannel;/*** Message will put to here first, and then reput to FileChannel if writeBuffer is not null.* 消息会先写入写缓冲区 然后再进行写入到文件通道里 写入内存映射区域,最后写入到磁盘文件中*/protected ByteBuffer writeBuffer = null;/*** 瞬时存储池化组件*/protected TransientStorePool transientStorePool = null;/*** 文件名*/private String fileName;/*** 文件从哪个偏移量开始*/private long fileFromOffset;/*** 文件*/private File file;/*** 磁盘内存映射字节数据*/private MappedByteBuffer mappedByteBuffer;/*** 存储时间戳*/private volatile long storeTimestamp = 0;/*** 是否是第一次创建的标记*/private boolean firstCreateInQueue = false;}3.2 写入流程剖析
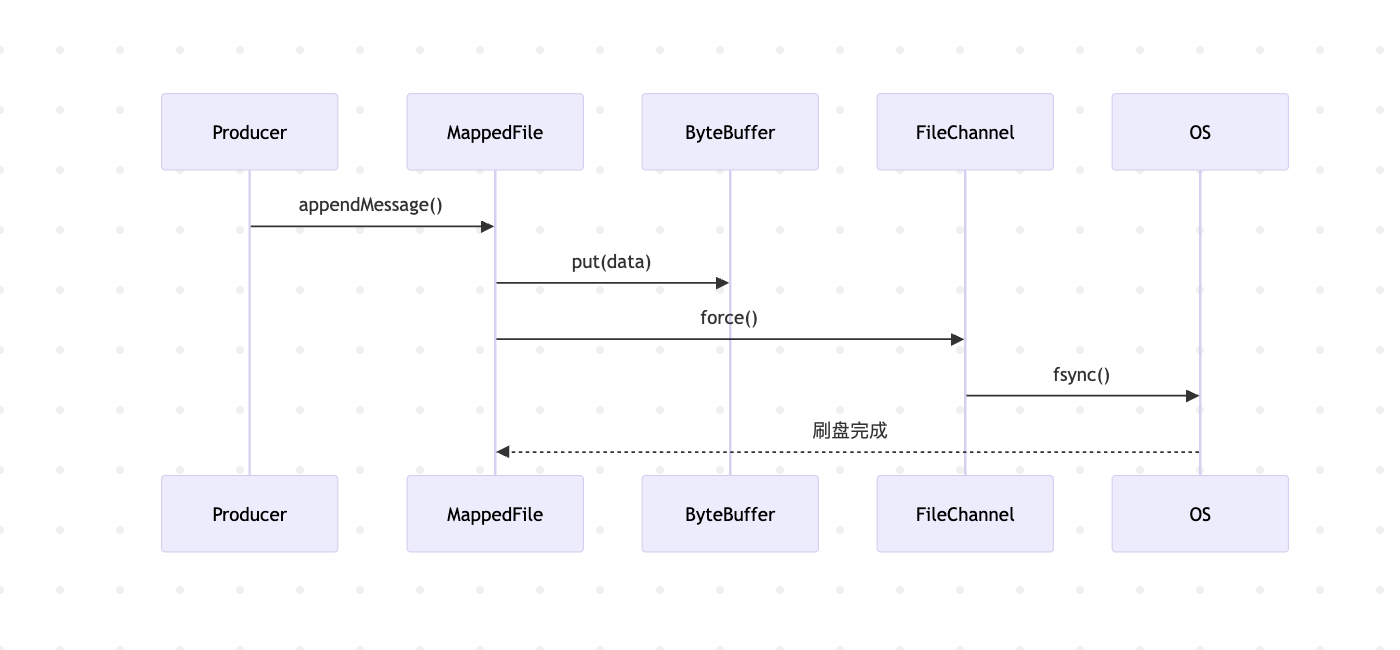
-
顺序追加写入:始终追加到文件末尾,避免随机写
-
双缓冲机制:page cache 作为写入缓冲,定期刷盘
-
写入加速:通过 Unsafe 类实现内存直接操作
3.3 内存管理策略
-
预分配机制:固定大小(默认1GB)的连续文件空间
-
文件分片:多个 MappedFile 组成逻辑连续存储
-
缓存锁定:使用 mlock 防止重要页被换出
四、性能优化实践
4.1 写入优化技巧
-
文件预热:提前触发缺页中断,避免运行时抖动
-
页对齐写入:保证每次写入按内存页大小对齐
-
批量提交:合并多个写操作一次性提交
4.2 读优化策略
-
顺序预读:根据访问模式预加载后续数据
-
内存驻留:锁定热点数据在内存中
-
冷热分离:区分常访问数据和归档数据
4.3 异常处理机制
-
写入保护:通过 wrotePosition 防止数据覆盖
-
CRC 校验:消息头包含 CRC32 校验码
-
快速恢复:基于 checkpoint 文件快速重建状态
五、生产环境调优指南
5.1 关键配置参数
| 参数名 | 默认值 | 推荐值 | 说明 |
|---|---|---|---|
| mappedFileSize | 1GB | 根据磁盘类型调整 | 单个映射文件大小 |
| transientStorePoolEnable | false | 高性能场景启用 | 使用堆外内存池 |
| flushCommitLogTimed | 500ms | 根据业务调整 | 异步刷盘间隔 |
5.2 监控指标
# RocketMQ 监控指标示例
rocketmq_storage_write_tps{type="commitlog"} 24578
rocketmq_storage_flush_latency{quantile="0.99"} 12
rocketmq_page_cache_hit_ratio 0.9985.3 最佳实践
-
SSD 配置:建议使用 NVMe SSD 并设置合适 I/O 调度器
-
NUMA 优化:绑定进程到固定 CPU 节点
-
写分离架构:物理隔离读写磁盘
六、未来演进方向
-
PMEM 支持:利用持久化内存特性
-
ZNS SSD 适配:对接分区命名空间固态盘
-
AI 预测预热:基于负载预测的内存管理
七、总结
MappedFile 作为 RocketMQ 的存储基石,通过精妙的内存映射设计将硬件性能发挥到极致。理解其实现细节不仅有助于消息中间件的深度优化,更为设计高性能存储系统提供了经典范式。随着新型存储硬件的出现,内存映射技术仍将持续演进,继续在分布式系统中扮演关键角色。