b to c网站建设报价网络优化工程师工资
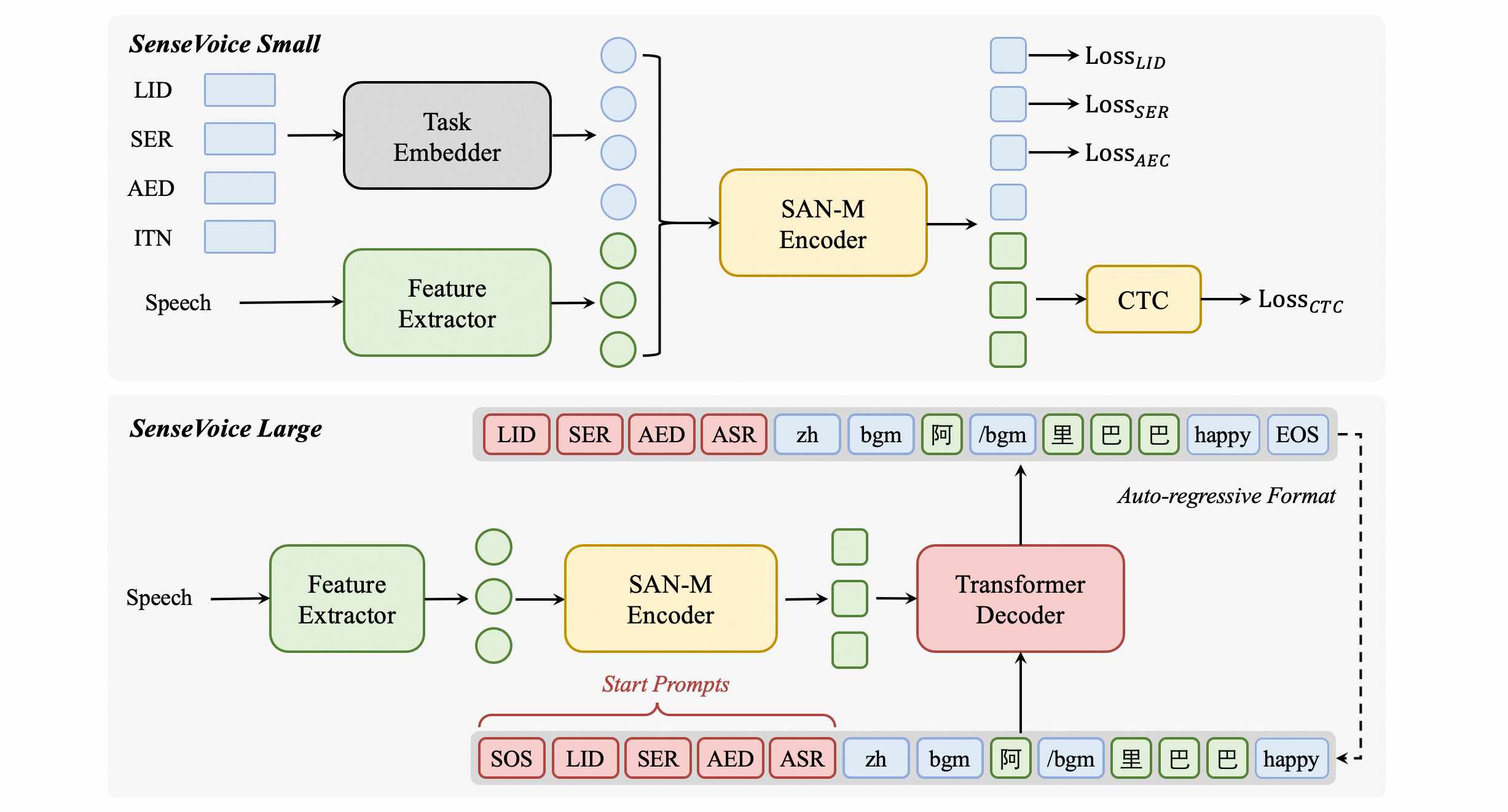
SenseVoiceSmall网络结构图
ASR(语音识别)是将音频信息转化为文字的技术。在实时语音识别中,一个关键问题是:如何决定将采集的音频数据输入大模型的最佳时机?固定时间间隔显然不够灵活,太短可能导致频繁调用模型,太长则会延迟文字输出。有没有更智能的方式?答案是肯定的。
一种常见的解决方案是使用 webrtcvad 库中的 Vad(VAD_MODE) 方法。它通过分析音频波动来判断是否有人说话,从而决定是否触发语音识别。然而,我在实际测试中发现,这种方法在某些场景下不够灵敏,尤其是在白噪音较大或较小的环境中,难以做到真正的自适应。
为了解决这一问题,我尝试了一种更综合的验证方式:结合 声波能量、VAD 和 频谱分析,通过多重验证来判断音频中是否包含语音活动。这种方法不仅能更精准地捕捉语音信号,还能有效过滤背景噪音,确保实时输出的准确性。
在模型选择上,我推荐使用 SenseVoiceSmall。这款模型在实时语音识别任务中表现优秀,既能保持高准确率,又能兼顾效率。openai推出的IWhisper也可以试试其效果,我主要识别的语言是中文,暂时还没试过这个模型。此外,值得一提的是,魔搭社区(ModelScope)提供了丰富的模型资源和详细的调用代码。如果你对语音识别感兴趣,这里是一个值得探索的平台。虽然它和 Hugging Face有些相似,但作为国产社区,它在本地化支持和模型适配上有着独特的优势,值得推荐。
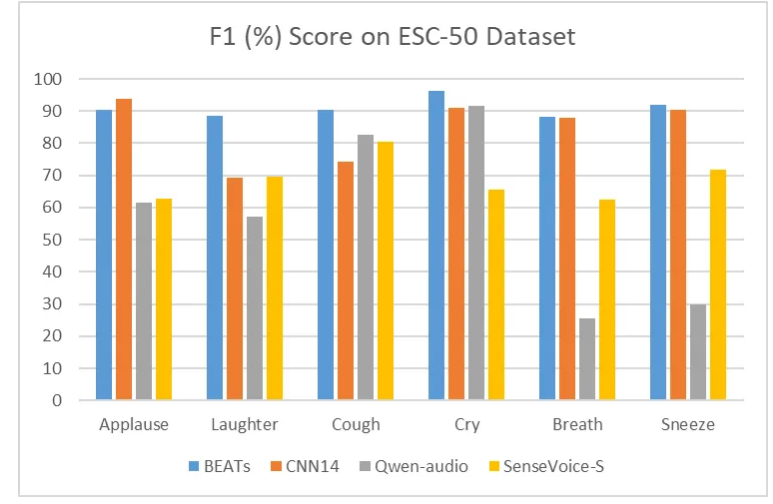
SenseVoiceSmall性能如下:
import pyaudio
import webrtcvad
import numpy as np
from pypinyin import pinyin, Style # 如果后续需要用,可按需使用
import refrom funasr import AutoModel
from funasr.utils.postprocess_utils import rich_transcription_postprocess
from modelscope.pipelines import pipeline# 参数配置
AUDIO_RATE = 16000 # 采样率(支持8000, 16000, 32000或48000)
CHUNK_SIZE = 480 # 每块大小(30ms,保证为10/20/30ms的倍数)
VAD_MODE = 1 # VAD 模式(0-3,数值越小越保守)# 初始化 VAD
vad = webrtcvad.Vad(VAD_MODE)# 初始化 ASR 模型
sound_rec_model = AutoModel(model=r"D:\Downloads\SenseVoiceSmall",trust_remote_code=True,remote_code="./model.py",vad_model="fsmn-vad",vad_kwargs={"max_single_segment_time": 30000},device="cuda:0",use_itn=True,disable_update = True,disable_pbar = True,disable_log = True)# 初始化说话人验证模型(如果需要后续使用)
# sv_pipeline = pipeline(
# task='speaker-verification',
# model=r'D:\Downloads\speech_campplus_sv_zh-cn_3dspeaker_16k'
# )def calibrate(stream, calibration_seconds=2, chunk_duration_ms=30):"""校准背景噪音:录制指定时长的音频,计算平均幅值与标准差,从而设置自适应阈值参数:calibration_seconds: 校准时间(秒)chunk_duration_ms: 每块时长(毫秒)返回:amplitude_threshold: 设定的音频幅值阈值"""print("开始校准背景噪音,请保持安静...")amplitudes = []num_frames = int(calibration_seconds * (1000 / chunk_duration_ms))for _ in range(num_frames):audio_chunk = stream.read(CHUNK_SIZE, exception_on_overflow=False)audio_data = np.frombuffer(audio_chunk, dtype=np.int16)amplitudes.append(np.abs(audio_data).mean())mean_noise = np.mean(amplitudes)std_noise = np.std(amplitudes)amplitude_threshold = mean_noise + 2 * std_noiseprint(f"校准完成:噪音均值={mean_noise:.2f},标准差={std_noise:.2f},设置阈值={amplitude_threshold:.2f}")return amplitude_thresholdclass SpeechDetector:"""SpeechDetector 负责处理音频块,结合能量预处理、VAD 和频谱分析进行语音检测,并在检测到语音结束后调用 ASR 模型进行转写,返回识别结果文本。"""def __init__(self, amplitude_threshold):self.amplitude_threshold = amplitude_threshold# 音频缓冲区,用于存储当前语音段的音频数据self.speech_buffer = bytearray()# 连续帧状态,用于平滑判断语音是否开始/结束self.speech_state = False # True:正在录入语音;False:非语音状态self.consecutive_speech = 0 # 连续语音帧计数self.consecutive_silence = 0 # 连续静音帧计数self.required_speech_frames = 2 # 连续语音帧达到此值后确认进入语音状态(例如 2 帧大约 60ms)self.required_silence_frames = 15 # 连续静音帧达到此值后确认语音结束(例如 15 帧大约 450ms)self.long_silence_frames = 67 # 连续静音帧达到此值后确认语音结束(例如 34 帧大约 1s)def analyze_spectrum(self, audio_chunk):"""通过频谱分析检测语音特性:1. 对音频块应用汉宁窗后计算 FFT2. 统计局部峰值数量(峰值必须超过均值的1.5倍)3. 当峰值数量大于等于3时,认为该块具有语音特征"""audio_data = np.frombuffer(audio_chunk, dtype=np.int16)if len(audio_data) == 0:return False# 应用汉宁窗减少 FFT 泄露window = np.hanning(len(audio_data))windowed_data = audio_data * window# 计算 FFT 并取正频率部分spectrum = np.abs(np.fft.rfft(windowed_data))spectral_mean = np.mean(spectrum)peak_count = 0for i in range(1, len(spectrum) - 1):if (spectrum[i] > spectrum[i - 1] and spectrum[i] > spectrum[i + 1] and spectrum[i] > spectral_mean * 1.5):peak_count += 1return peak_count >= 3def is_speech(self, audio_chunk):"""判断当前音频块是否包含语音:1. 先通过能量阈值预过滤低幅值数据2. 再结合 VAD 检测与频谱分析判断"""threshold = self.amplitude_threshold if self.amplitude_threshold is not None else 11540.82audio_data = np.frombuffer(audio_chunk, dtype=np.int16)amplitude = np.abs(audio_data).mean()if amplitude < threshold:return Falsevad_result = vad.is_speech(audio_chunk, AUDIO_RATE)spectral_result = self.analyze_spectrum(audio_chunk)return vad_result and spectral_resultdef process_chunk(self, audio_chunk):"""处理每个音频块,并在识别到语音结束后返回文本结果。工作流程:- 若检测到语音:* 增加连续语音帧计数(consecutive_speech),清零静音帧计数* 若达到语音起始帧阈值,则进入语音状态* 处于语音状态时,将当前音频块追加到缓冲区- 若检测为静音:* 累计静音帧数,同时清零语音计数* 若处于语音状态且静音帧达到设定阈值,认为当前语音段结束,则调用 ASR 模型进行识别,并返