网站排名推广的优点是什么分销微信小程序开发
张量-pytroch网站-笔记
张量是一种特殊的数据结构,跟数组(array)和矩阵(matrix)非常相似。
张量和 NumPy 中的 ndarray 很像,不过张量可以在 GPU 或其他硬件加速器上运行。
事实上,张量和 NumPy 数组有时可以共享底层内存,也就是说,不用来回复制数据(具体可以参考:与 NumPy 的桥接)。
张量还被优化过,用来自动求导
| 概念 | 通俗理解 |
|---|---|
| Tensor(张量) | 就是一个高级的“数组”,支持多维度、高性能计算 |
| 用途 | 是 PyTorch 中处理数据的核心工具,用来装模型的输入、输出和参数 |
| 优势 | 可以在 GPU 上运行、和 NumPy 兼容、支持自动求导 |
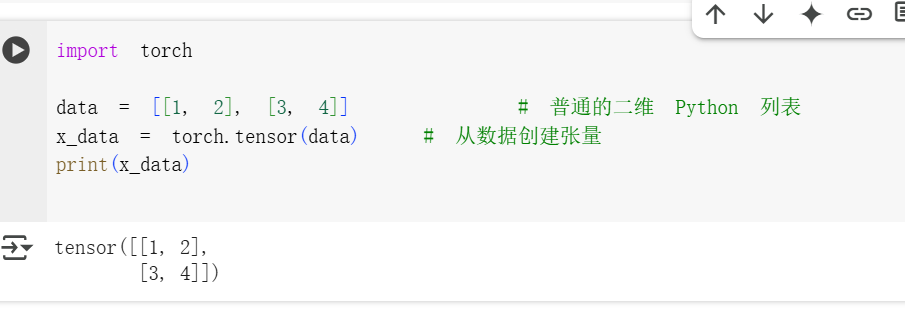
初始化一个张量(Tensor)
张量可以用很多不同的方法来创建。下面是一些例子:
从已有数据直接创建
张量可以直接用数据来创建,数据类型(比如整数、浮点数)会自动识别。
-
张量就像“多维数组”
-
你可以直接传入一个 Python 列表或列表嵌套,就能创建出张量
-
PyTorch 会自动判断你传入的数据是什么类型,比如整数、浮点数等
 从 NumPy 数组创建张量
从 NumPy 数组创建张量
张量可以从 NumPy 数组创建
-
PyTorch 和 NumPy 是好兄弟
-
可以:
-
把 NumPy 数组变成张量:用于神经网络训练
-
也可以把张量变回 NumPy 数组:用于数学计算或绘图
-
-
它们还可以共享内存,不需要复制,提高效率
-

反过来,把张量变成 NumPy:

从另一个张量创建新张量:
新张量会自动保留原张量的属性(比如形状、数据类型),除非你手动改了它。

使用 torch.ones_like(x_data) 创建一个 和 x_data 形状完全相同,但元素全部为 1 的张量。
使用 torch.rand_like(x_data) 创建一个和 x_data 形状一样的 随机数张量(数值范围在 [0, 1) 之间的浮点数)
使用随机值或常数值创建张量时,shape 是一个表示张量维度的元组。在下面这些函数中,shape 用来确定输出张量的维度。

张量(Tensor)的属性用来描述它的:
-
形状(shape)
-
数据类型(datatype)
-
所在设备(device)

PyTorch 提供了 超过 1200 种张量操作,包括:
-
算术运算(加减乘除)
-
线性代数运算(矩阵乘法、逆矩阵等)
-
矩阵操作(转置、索引、切片等)
-
采样(比如从概率分布中随机取样)
所有这些操作都可以在:
-
CPU
-
或者加速器上运行,例如:
-
CUDA(NVIDIA 的 GPU)
-
MPS(Mac 上的 GPU 加速)
-
MTIA, XPU(英特尔或其他厂商的加速器)
-
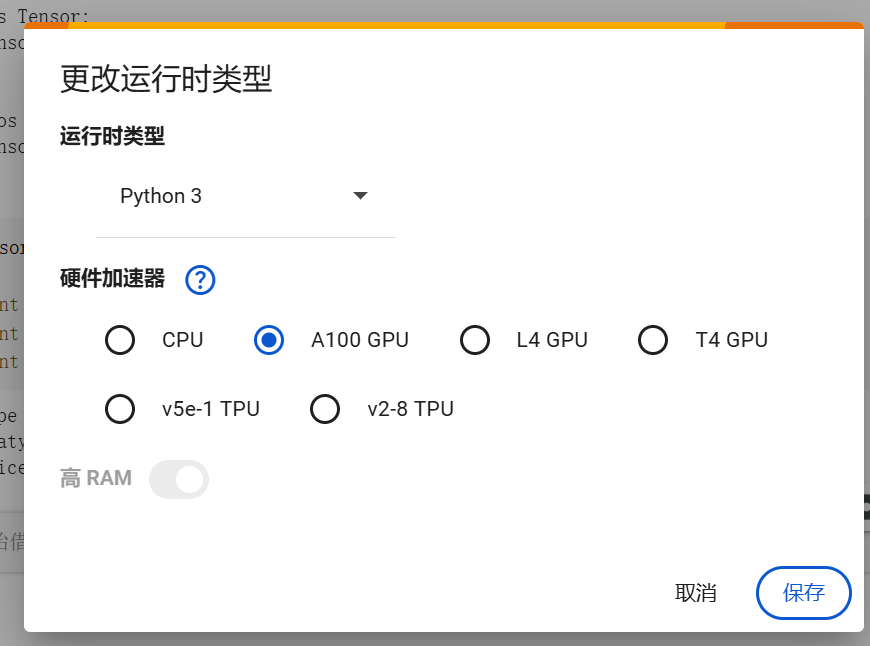
如果在用 Google Colab(一个在线的 Python 运行环境):
-
可以点击菜单栏的:
Runtime > Change runtime type > GPU -
来分配一个 GPU 加速器,从而提升运算效率。
-
默认情况下,张量是在 CPU 上创建的。
-
如果想让它在 GPU 上运算,就需要用
.to()方法显式地移动: -
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") x = x.to(device)在不同设备(比如从 CPU → GPU)之间移动大张量时,会消耗时间和内存。
-
PyTorch 支持大量张量操作,这些操作可以在 CPU 或各种加速器(如 GPU)上运行。但默认张量是在 CPU 上,需要手动移动到 GPU,而且大张量的设备间拷贝是耗资源的,要谨慎操作。
-
你可以尝试一下列表中的一些操作(指张量的操作)。如果你熟悉 NumPy 的 API(编程接口),你会发现 PyTorch 的张量 API 用起来非常简单,就像“轻而易举”一样
-
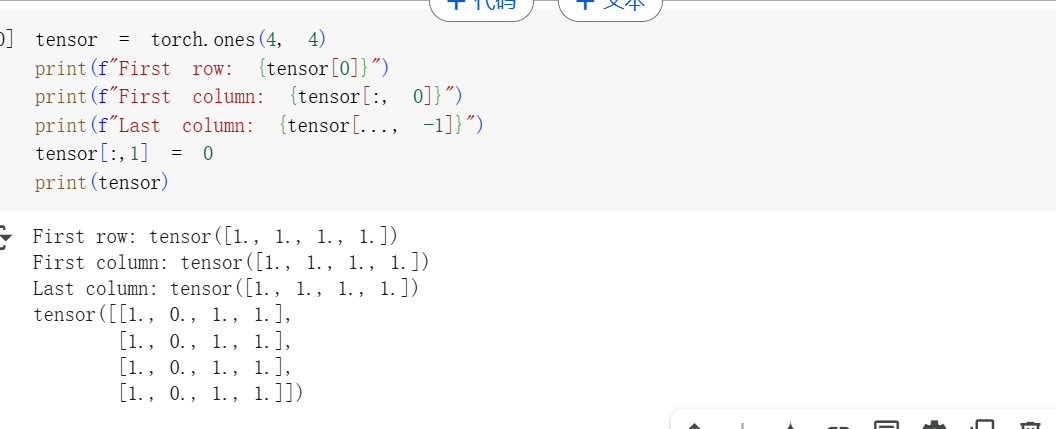
4行4列 标准索引和切片方法

dim=1 列,cat合并
-
torch.cat是 PyTorch 中的一个函数,用来拼接多个张量。 -
拼接时要求:除了指定拼接的那个维度以外,其他维度必须一致。
-
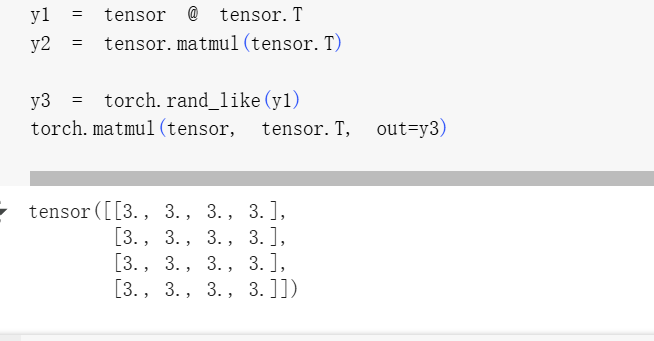
tensor.T:表示张量tensor的 转置(把行列对换)。 -
@和matmul()都是做 矩阵乘法 的方式,它们等价。 -
out=y3是在指定:把结果 直接存储进 y3,不返回新张量,节省内存。
-
这部分不是做矩阵乘法,而是逐个元素相乘(element-wise multiply)
-
也就是说
tensor[i][j] * tensor[i][j],每个元素单独相乘。 -
和矩阵乘法的规则不同,不涉及转置、不涉及矩阵行列数匹配。
-
总结对比:
运算类型 操作符 / 函数 是否逐元素? 是否需要转置? 输出维度变化? 矩阵乘法 @,matmul()❌ 否 ✅ 通常需要转置 ✅ 会变 逐元素乘法(Hadamard) *,mul()✅ 是 ❌ 不需要 ❌ 不变
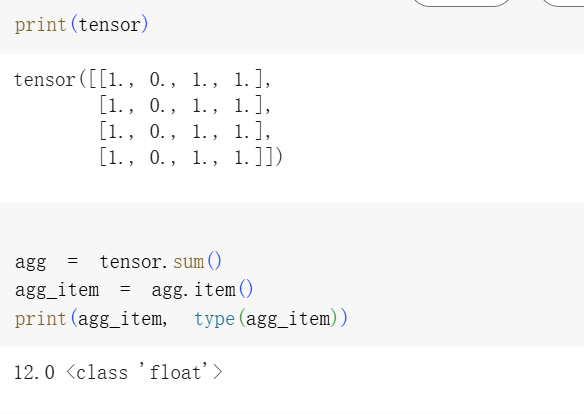
单元素张量(single-element tensor)是指只有一个元素的张量。
比如你对一个张量做了求和(sum)、平均(mean)等操作,结果就是一个单个值的张量。
如果你想把这个张量变成普通的 Python 数值(比如 int 或 float),可以使用 .item() 方法
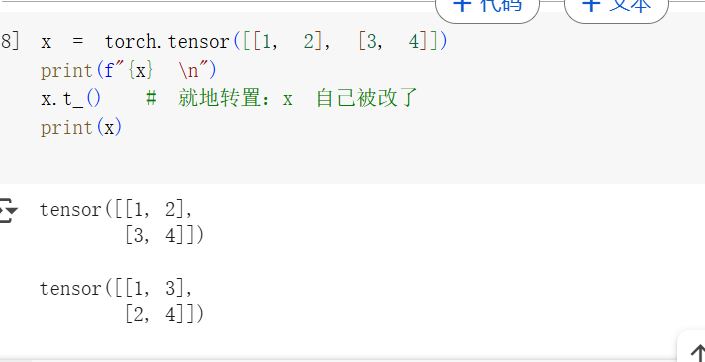
In-place operations(就地操作)是指那些直接把结果存回原变量的操作。
这类操作的特点是:不会创建新张量,而是直接修改原张量本身。
它们通常在函数名后面加一个 下划线 _ 来表示,比如:
-
x.copy_(y):把y的值复制进 x,直接修改x的内容。 -
x.t_():将x转置,结果直接替代原来的x。 -

-
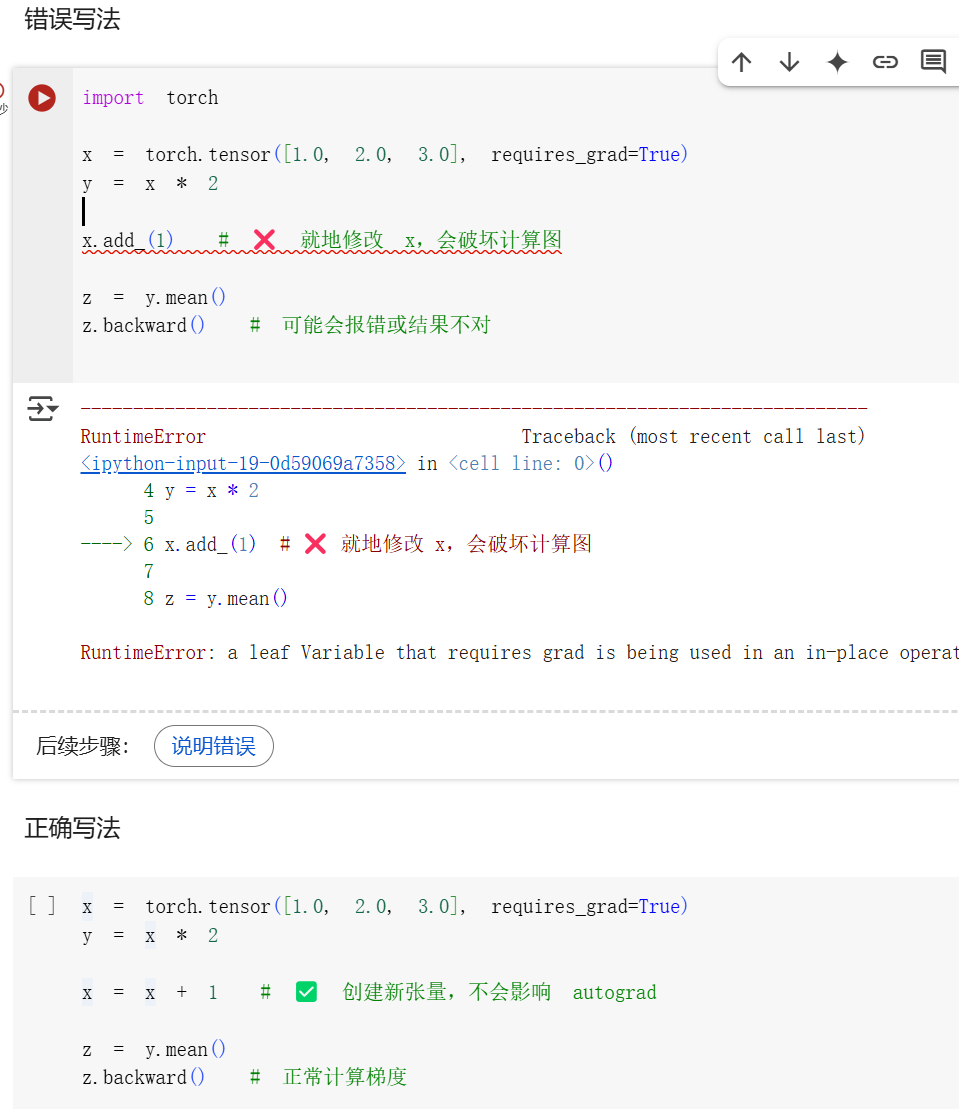
就地操作(in-place operations)虽然可以节省一些内存,
但在计算梯度(导数)时可能会出问题,因为它们会立即丢失计算历史(history),
所以一般不推荐在需要反向传播(backpropagation)的时候使用 in-place 操作。
在 PyTorch 中,自动求导(autograd)系统需要记录每一个操作的计算历史,以便后面做反向传播(计算梯度)。
-
普通操作会保留这些历史;
-
就地操作(比如
x += 1或x.copy_(...))会直接覆盖原变量的值,导致 PyTorch 无法回溯计算路径,从而报错或者计算错误。 -
-
in-place 操作虽然省内存,但有可能破坏 PyTorch 的计算图,导致梯度无法正确求解,因此在训练模型时最好避免使用。

当张量(Tensor)位于 CPU 上时,它和 NumPy 数组可以共享底层内存地址(memory location),
所以修改其中一个,另一个也会跟着改变。

改动 NumPy,也会影响张量