小企业想做网站推广找哪家强策划书模板免费下载的网站
一、TL;DR
- 重要性:数据质量 > 数据数量
- 数据质量提升原则:提升数据多样性和分布和提升数据质量和高质量数据数量
- 具体如何提升:针对传统NN任务、LLM任务和MLLMs任务,方法和侧重点不一样
- 如何使用这些方法:将这些方法做成算子写入pipeline框架进行大规模使用
- 做完这些还缺什么:数据飞轮+数据合成
二、总体原则
数据重要性维度:数据质量 > 数据数量
数据质量维度,我觉得阿里的data-juicer总结的很好,如下所示:
- 提升数据多样性和分布
- 提升数据质量和高质量数据数量
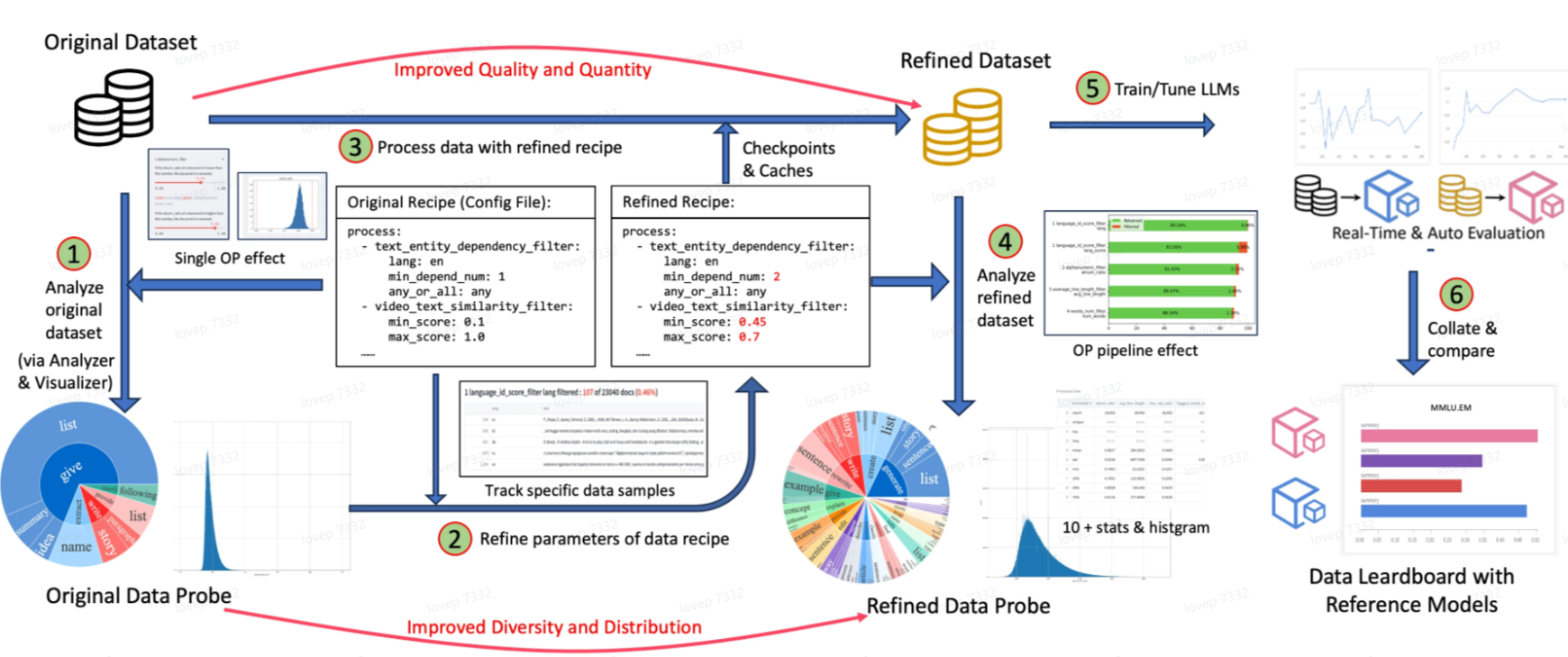
总体来说,阿里采用了一些启发式的规则以算子的形式通过ray部署进入数据pipeline,将源源不断的各类数据通过这些算子进行去重和过滤,得到最终的数据集。
三、如何提升数据质量
不同的任务对数据质量的提升方法不一样,如下所示。
3.1 detection/seg/classification等传统NN任务
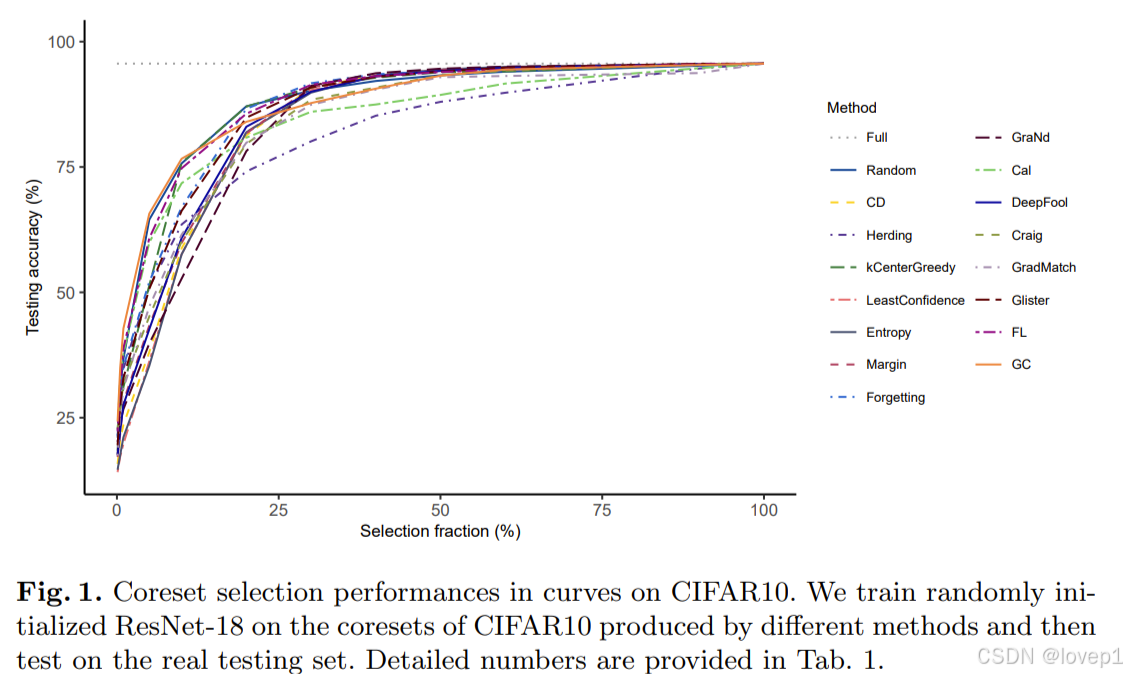
- 传统的NN任务可以使用active learning/coreset挑选/数据蒸馏的方式来做,基本可以做到30%的数据达到90%以上的性能,比如我之前的博客:
- https://blog.csdn.net/lovep1/article/details/146779443
-
核心集:DeepCore: A Comprehensive Library for CoresetSelection in Deep Learning-CSDN博客
-
3.2 LLM等大语言模型相关的任务
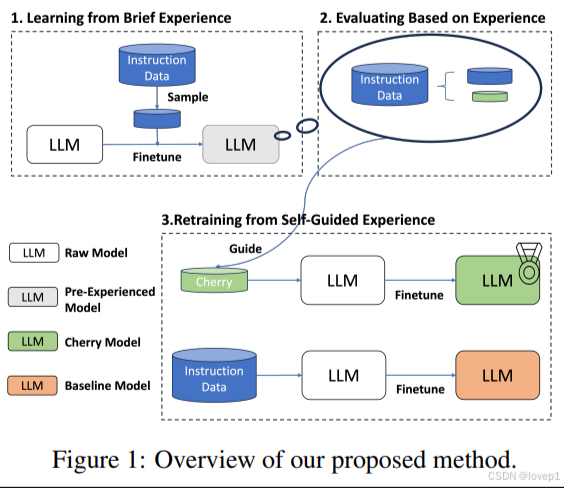
可以使IFD/MoDs/困惑度等LLM相关质量指标进行NLP数据过滤,GPT3使用未开源的过滤手段可以将40T的数据压缩至400G,压缩率98%,LIMA可以只使用1000条数据训练,具体的方法可以参考我之前的博客
- https://blog.csdn.net/lovep1/article/details/147032636
3.3 MLLMs等多模态任务
可以使用启发式规则+清洗的方式进行过滤,可以参考我之前的博客:
- https://blog.csdn.net/lovep1/category_12871625.html
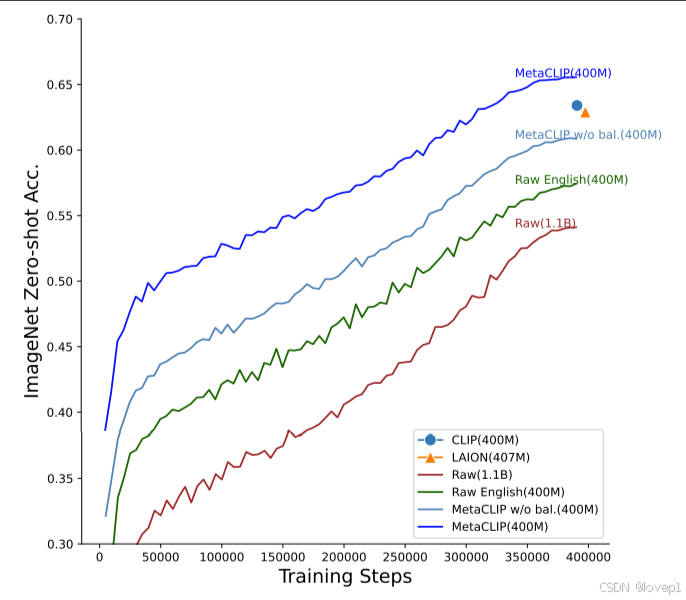
- 数据质量-MetaCLIP:DEMYSTIFYING CLIP DATA-CSDN博客
-
四、如何提升数据多样性
数据多样性一般从数据用途、数据形式和数据语义三个方面进行处理。核心目的:挑选出最具备diversity的分布:
4.1 数据用途(我的理解)
4.1.1 不同领域
大模型预训练或者sft时不同领域进行混合得到的数据,相当于不同的下游任务的场景,可以参考我之前的博客:InternVL2.5:Expanding Performance Boundaries of Open-SourceMultimodal Models 论文理解-CSDN博客
4.1.2 相同领域/相同模态
对同类型或者同模态的数据从各种细节上要求多样性,比如同一种语言代表不同的语义、同一种语言不同的翻译等:
- 以视频模态为例,对地域、语言等做出多样性要求
4.2 数据形式
这边主要是指prompt和对应的answer的形式:
- prompt表达方式的多样性:同一个语义在不同的场景和上下文中回答
- prompt的难度:对prompt的难度进行把控,使得在同一语义空间的prompt变得足够的差异化和多样性,比如Wizard方法
- prompt/answer的长度:既要保留长数据,也要保留短数据,所谓的长数据还需要将各种重点信息隐藏在长句子中
- answer的分布多样性:answer需要足够的diversity
4.3 数据语义
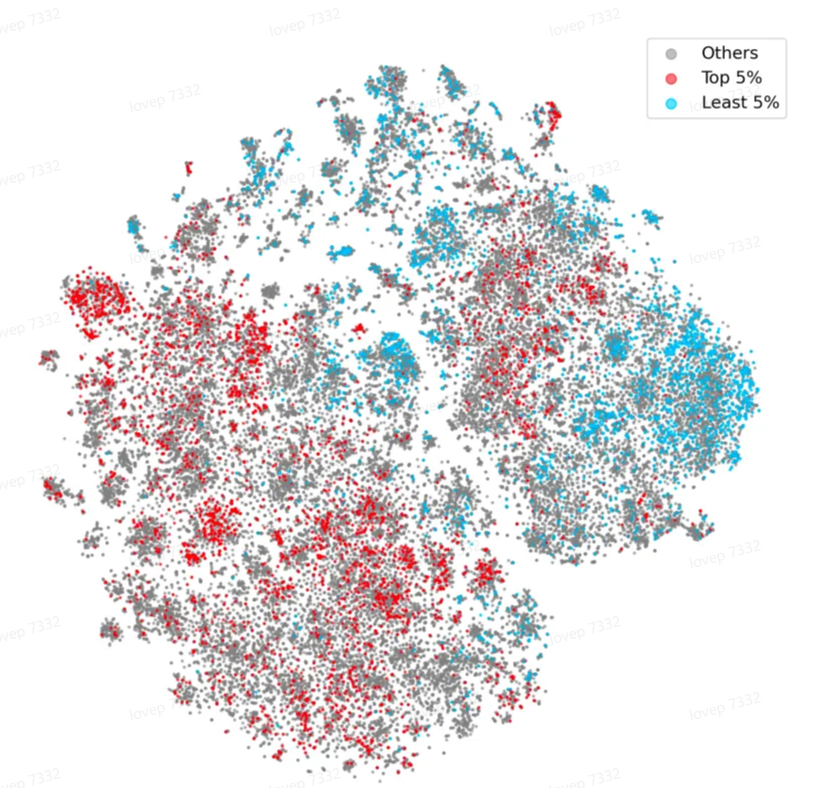
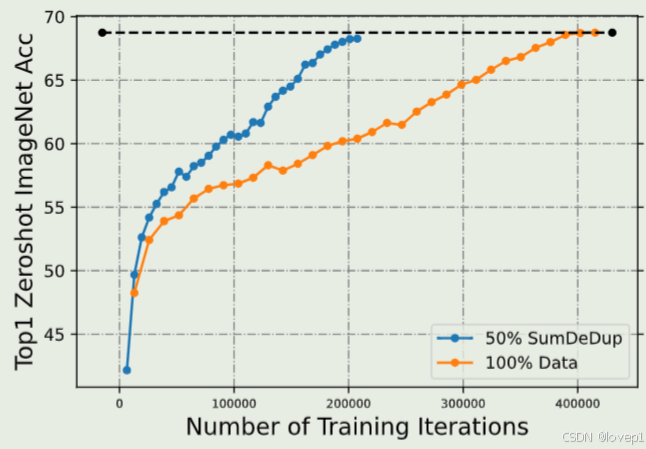
数据语义其实在MLLMs中是存在的比较多的,我的理解是通过图像/视频语义的分布来进行数据的筛选,如下所示:
数据质量-SemDeDup: Data-efficient learning at web-scale through semantic deduplication_semdedup去重-CSDN博客
五、如何使用这些方法呢
我们可以将上述的方法和规则做成算子写到data-juicer等框架里面,做成数据filter的pipeline,这样就可以大规模的将网上的爬虫数据、公开数据、领域数据进行蒸馏和压缩,从而获得高质量数据。