免费b2b网站大全不花钱成功的软文推广
目录
前言
什么是继承
继承的概念
继承的定义
基类与派生类对象的赋值转换
继承的作用域
派生类中的默认成员函数
默认成员函数的调用
构造函数与析构函数
拷贝构造
赋值运算符重载
显示成员函数的调用
构造函数
拷贝构造
赋值运算符重载
析构函数
继承与友元
继承与静态成员
菱形继承
继承和组合
前言
在编程中,继承是面向对象编程(OOP)的核心概念之一。它通过让一个类(子类)继承另一个类(父类)的特性和行为,帮助我们实现代码复用、提高程序的扩展性和灵活性。那么,为什么继承在编程中如此重要呢?
什么是继承
试想这样一个场景:假设有个App需要去获取不同类型用户的数据,并进行分类,那么就需要我们去写对应不同的类,比如说学生、老师、军人、公司职工…………每个类都需要有名字、联系方式、家庭住址、年龄……,我们会发现这样每个类都要写一份,非常冗余,于是我们的祖师爷为了解决这个问题,设计出了继承的语法,比如说用户的共同点是都是用户,我们就可以写一个关于人的类,作为基类,而不同类型用户就作为基类的派生类,去继承基类的成员,从而达到我们的目的。
继承的概念
继承(inheritance)机制是面向对象程序设计使代码可以复用的最重要的手段,它允许程序员在保持原有类特性的基础上进行扩展,增加功能,这样产生新的类,称派生类。继承呈现了面向对象程序设计的层次结构,体现了由简单到复杂的认知过程。以前我们接触的复用都是函数复用,继承是类设计层次的复用。
- 被继承对象:父类 / 基类 (
base) - 继承方:子类 / 派生类 (
derived)
继承的本质 就是 - 复用代码
举个例子 : 假设我现在要设计一个校园管理系统,那么肯定会设计很多角色类,比如学生、老师、保安、保洁等等之类的。
设计好以后,我们发现,有些数据和方法是每个角色都有的,而有些则是每个角色独有的。
为了复用代码、提高开发效率,可以从各种角色中选出共同点。组成 基类,比如每个人都有姓名、年龄、联系方式等基本信息,而 教职工 与 学生 的区别就在于 管理与被管理,因此可以在 基类 的基础上加一些特殊信息如教职工号 表示 教职工,加上 学号 表示学生,其他细分角色设计也是如此
这样就可以通过 继承 的方式,复用 基类 的代码,划分出各种 子类

像上面共同拥有的数据和方法我们可以重新设计一个类Person ,然后让 Student 和 Teacher 去继承它,如下:
// 大众类 --- 基础属性
class Person
{
public:Person(string name = string(), string tell = string(), int age = int()):_name(name),_tell(tell),_age(age){}void Print(){cout << "我的名字是 :" << _name << endl;cout << "我的电话是 :" << _tell << endl;cout << "我的年龄是 :" << _age << endl;}
protected:string _name; // 姓名string _tell; // 电话int _age; // 年龄
};// 学生类 --- 派生/子属性
class Student : public Person
{
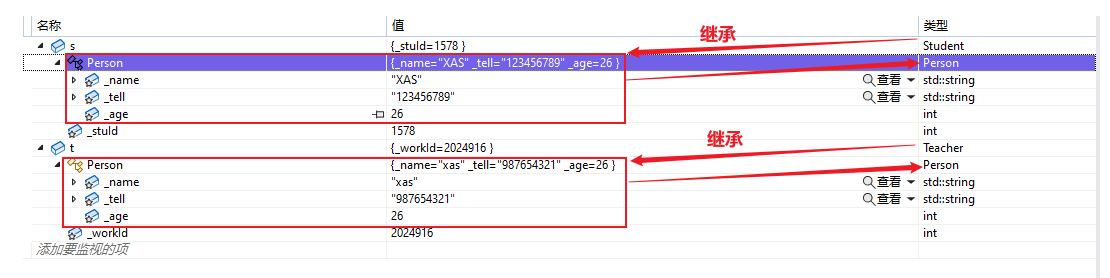
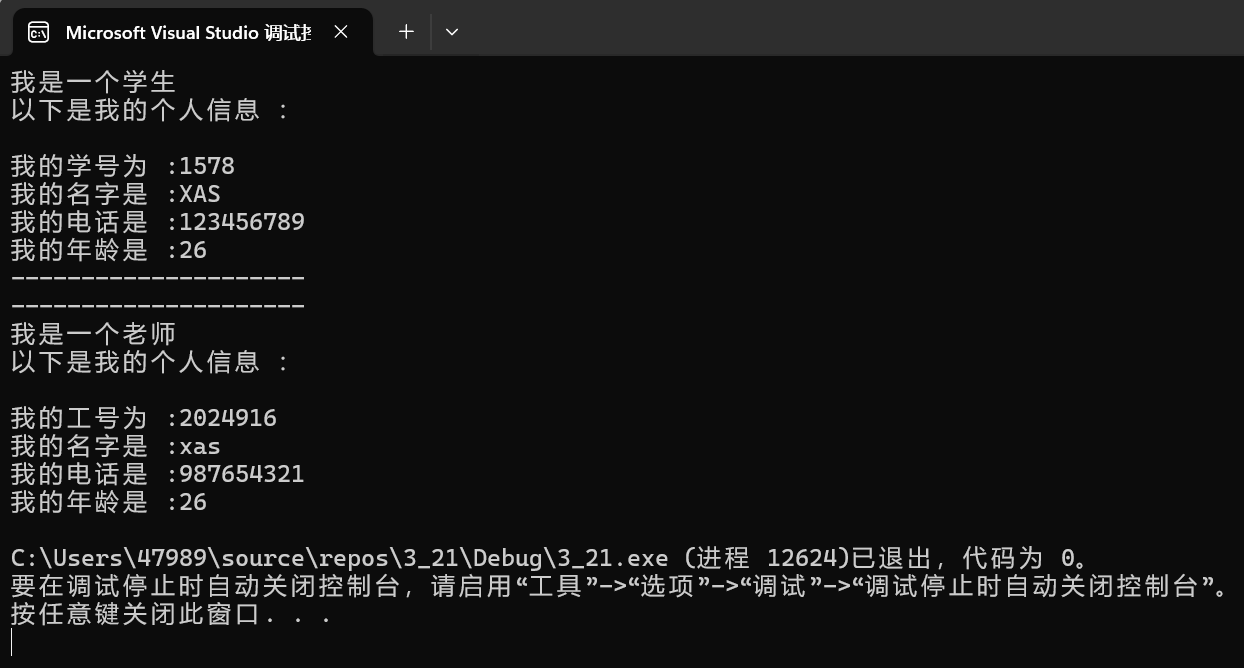
public:Student(int stuId = 1578):Person("XAS","123456789",26),_stuId(stuId){cout << "我是一个学生" << endl;cout << "以下是我的个人信息 :" << endl;cout << endl;cout << "我的学号为 :" << _stuId << endl;}
protected:int _stuId; // 学号
};// 老师类 --- 派生/子属性
class Teacher : public Person
{
public:Teacher(int workId = 2024916):Person("xas","987654321",26),_workId(workId){cout << "我是一个老师" << endl;cout << "以下是我的个人信息 :" << endl;cout << endl;cout << "我的工号为 :" << _workId << endl;}
protected:int _workId; // 工号
};int main()
{Student s;s.Print();cout << "---------------------" << endl;cout << "---------------------" << endl;Teacher t;t.Print();return 0;
}继承后,父类的 Person 的成员(成员函数+成员变量)都会变成子类的一部分。这里体现出了 Student 和 Teacher 复用了 Person
继承的定义
格式:Person是父类,也称作基类。Student是子类,也称作派生类

继承有权限的概念,分别为:公有继承(public)、保护继承(protected)、私有继承(private)没错,与 类 中的访问 限定修饰符 一样,不过这些符号在这里表示 继承权限
简单回顾下各种限定符的用途
- 公有 public:公开的,任何人都可以访问
- 保护 protected:保护的,只有当前类和子类可以访问
- 私有 private:私有的,只允许当前类进行访问
权限大小:公有 > 保护 > 私有
保护 protected 比较特殊,只有在 继承 中才能体现它的价值,否则与 私有 作用一样
我们会发现继承方式和访问限定符都存在公有、保护、私有这三种继承模式。

 总结:
总结:
1、基类private成员在派生类中无论以什么方式继承都是不可见的。这里的不可见是指基类的私有成员还是被继承到了派生类对象中,但是语法上限制派生类对象不管在类里面还是类外面都不能去访问它。
2、基类private成员在派生类中是不能被访问,如果基类成员不想在类外直接被访问,但需要在派生类中能访问,就定义为protected。可以看出保护成员限定符是因继承才出现的。(所以我们不想让子类继承就写成私有,想让子类继承就写成保护。可以理解为private防外人也防儿子,但是protected防外人但是不防儿子。)
3、 上面表格我们进行一下总结会发现,基类的私有成员在子类都是不可见。基类的其他成员在子类的访问方式 == Min(成员在基类的访问限定符,继承方式),public > protected> private。
4、使用关键字class时默认的继承方式是private,使用struct时默认的继承方式是public,我们常用的一般都是class,所以最好显示地写出继承方式。
5、在实际运用中一般使用都是public继承,几乎很少使用protetced/private继承,也不提倡
使用protetced/private继承,因为protetced/private继承下来的成员都只能在派生类的类里
面使用,实际中扩展维护性不强
如何证明呢? 通过一下的代码,我们来验证上面的结论!!
// 父类
class A
{
public:int _a;
protected:int _b;
private:int _c;
};// 子类
class B : public A
{
public:B(){cout << _a << endl;cout << _b << endl;cout << _c << endl;}
};int main()
{// 外部(子类对象)B b; b._a;
}下面我们一起去验证一下
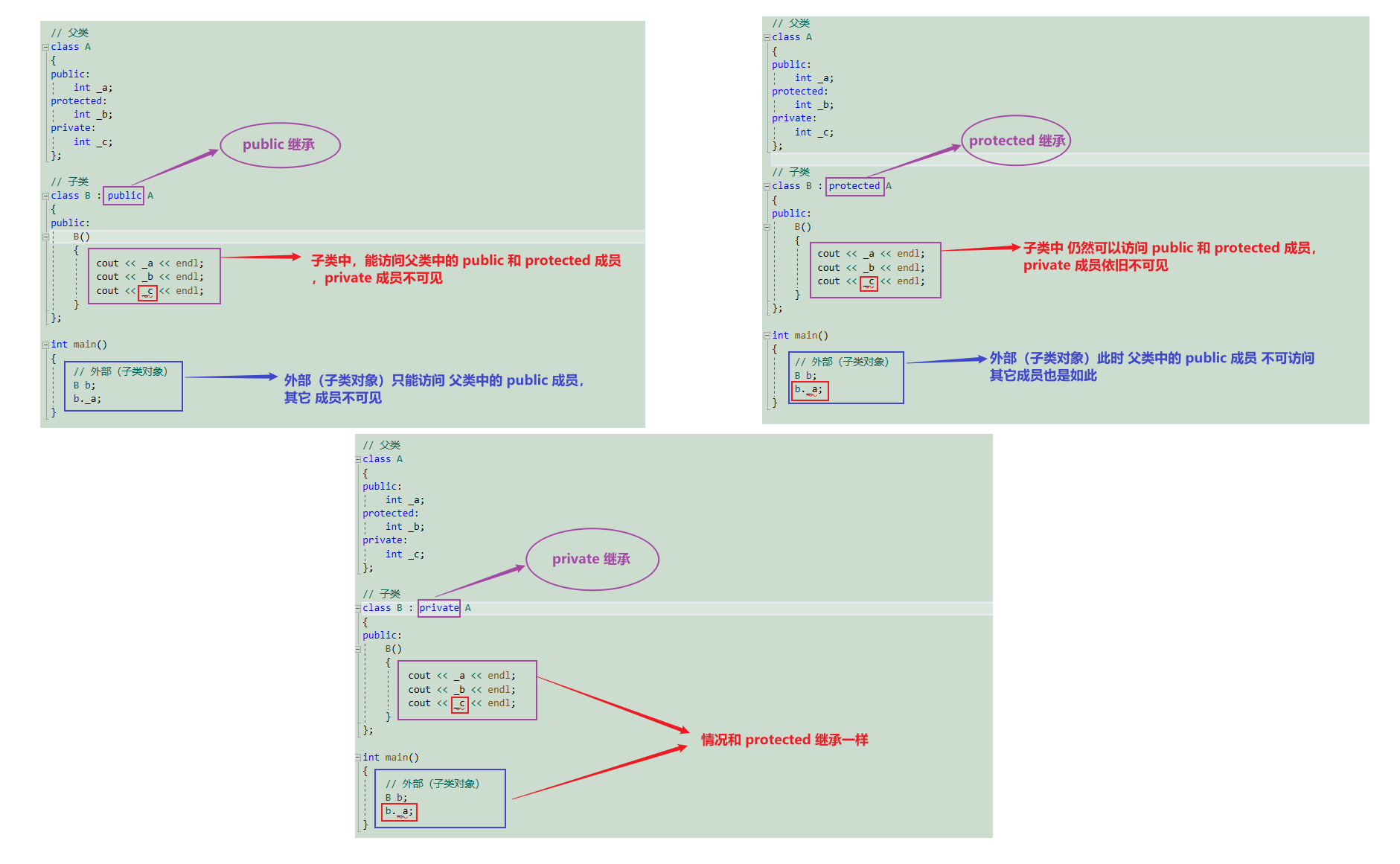
之所以说 C++ 的继承机制设计复杂了,是因为 protected 和 private 继承时的效果一样
其实 C++ 中搞这么多种情况(9种)完全没必要,实际使用中,最常见到的组合为 public : public 和 protected : public
如何优雅的使用好 继承权限 呢
对于只想自己类中查看的成员,设为 private,对于想共享给子类使用的成员,设为 protected,其他成员都可以设为 public
比如在张三家中,张三家的房子面积允许公开,家庭存款只限家庭成员共享,而个人隐私数据则可以设为私有
class Home
{
public:int area = 500; //500 平米的大房子
};class Father : public Home
{
protected:int money = 50000; //存款五万
private:int privateMoney = 100; //私房钱,怎能公开?
};class Zhangsan : public Father
{
public:Zhangsan(){cout << "我是张三" << endl;cout << "我知道我家房子有 " << area << " 平方米" << endl;cout << "我也知道我家存款有 " << money << endl;cout << "但我不知道我爸爸的私房钱有多少" << endl;}
};class Xiaoming
{
public:Xiaoming(){cout << "我是小明" << endl;cout << "我只知道张三家房子有 " << Home().area << " 平方米" << endl;cout << "其他情况我一概不知" << endl;}
};int main()
{Zhangsan z;cout << "================" << endl;Xiaoming x;return 0;
}
基类与派生类对象的赋值转换
在继承中,允许将 子类 对象直接赋值给 父类,但不允许 父类 对象赋值给 子类
- 这其实很好理解,儿子以后可以当父亲,父亲还可以当儿子吗?
并且这种 赋值 是非常自然的,编译器直接处理,不需要调用 赋值重载 等函数
子类对象可以赋值给父类对象
//基类
class Person
{
public:string _name; // 姓名string _sex; // 性别int _age; // 年龄
};//派生类
class Student : public Person
{
public:int _id;
};int main()
{Person p;Student s;s._name = "张三";s._sex = "男";s._age = 20;s._id = 8888;p = s; // 子类对象赋值给父类对象return 0;
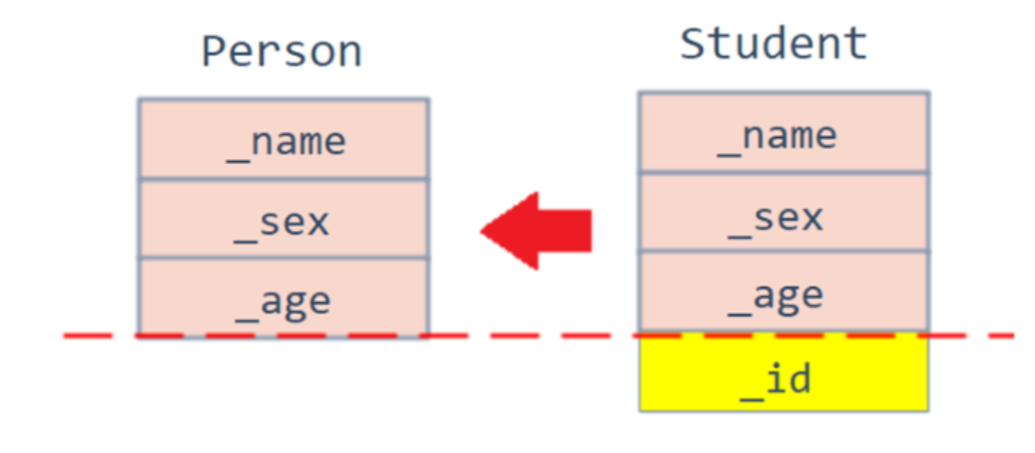
}通过调式可以看到,为什么没有把 id 赋值过去呢?

这里有个形象的说法叫切片或者切割,相当于把派生类中父类那部分切来赋值过去,如图所示:
子类对象可以赋值给父类指针
//基类
class Person
{
public:string _name; // 姓名string _sex; // 性别int _age; // 年龄
};//派生类
class Student : public Person
{
public:int _id;
};int main()
{Student s;s._name = "张三";s._sex = "男";s._age = 20;s._id = 8888;Person* p = &s;return 0;
}可以看到,当父类对象是一个指针的时候,照样可以赋值过去:

子类对象赋值给父类指针切片图:
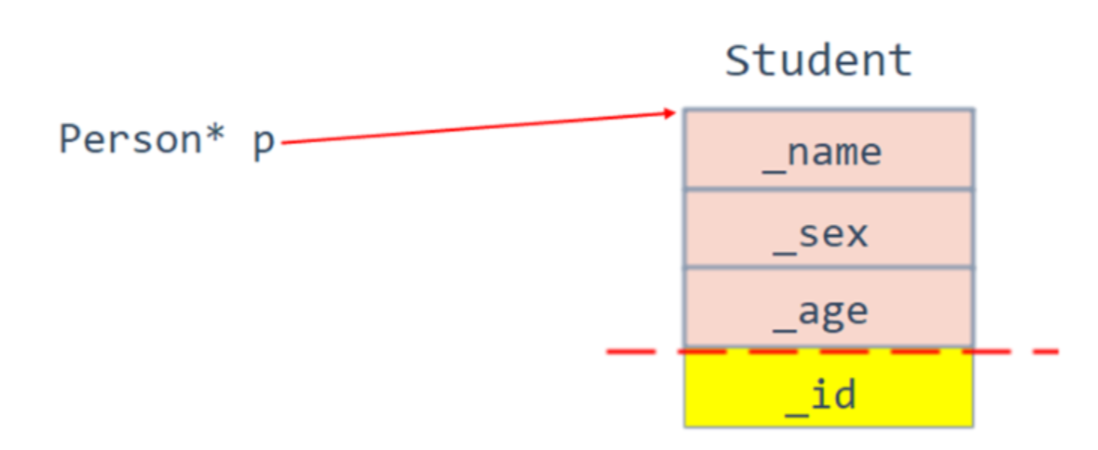
子类对象可以赋值给父类引用
//基类
class Person
{
public:string _name; // 姓名string _sex; // 性别int _age; // 年龄
};//派生类
class Student : public Person
{
public:int _id;
};int main()
{Student s;s._name = "张三";s._sex = "男";s._age = 20;s._id = 8888;Person& rp = s;return 0;
}可以看到,当父类对象是一个引用的时候,也可以赋值过去:

子类对象赋值给父类引用切换图片:
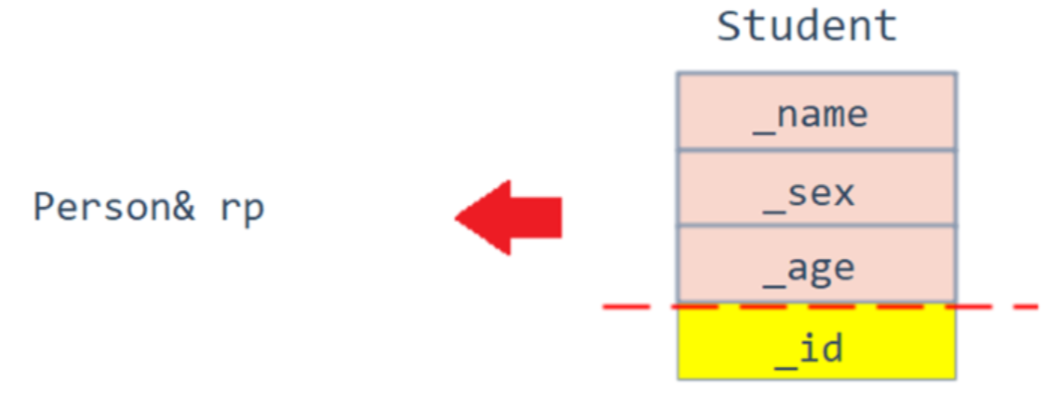
父类对象不能赋值给子类对象
//基类
class Person
{
public:string _name; // 姓名string _sex; // 性别int _age; // 年龄
};//派生类
class Student : public Person
{
public:int _id;
};int main()
{Student s;Person p;s = p;return 0;
}编译会报错:
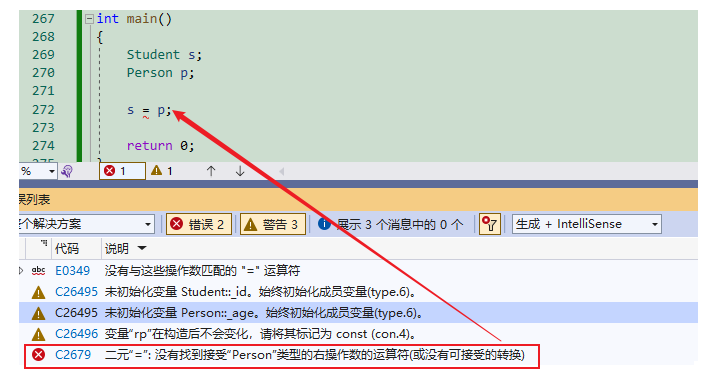
继承的作用域
在继承体系中 基类 和 派生类 都有独立的作用域,如果子类和父类中有同名成员,子类成员将屏蔽父类对同名成员的直接访问,这种情况叫 隐藏,也叫重定义。
代码示例:
Student 的 _num 和 Person的 _num 构成隐藏关系,可以看出这样代码虽然能跑,但是非常容易混淆。
// 基类
class Person
{
protected:string _name = "Edison"; // 姓名int _num = 555; // 身份证号
};// 派生类
class Student : public Person
{
public:void Print(){cout << "姓名:" << _name << endl;cout << "学号:" << _num << endl;}
protected:int _num = 888; // 学号
};int main()
{Student s1;s1.Print();return 0;
}运行可以看到,访问的是子类中的_num (类似于局部优先的原则)
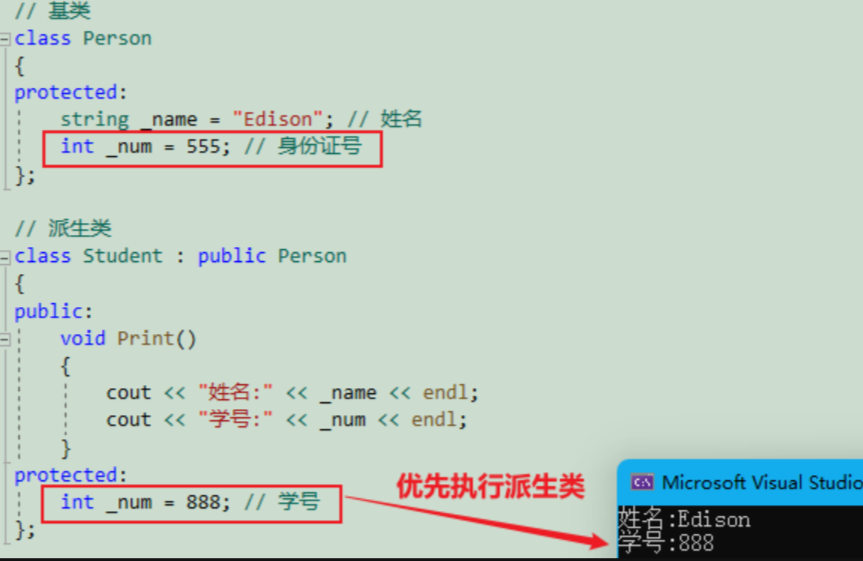
这时候你肯定会有疑问了,那么如果我想访问父类中的_num 呢 ? 可以使用 基类 :: 基类成员显示 的去访问
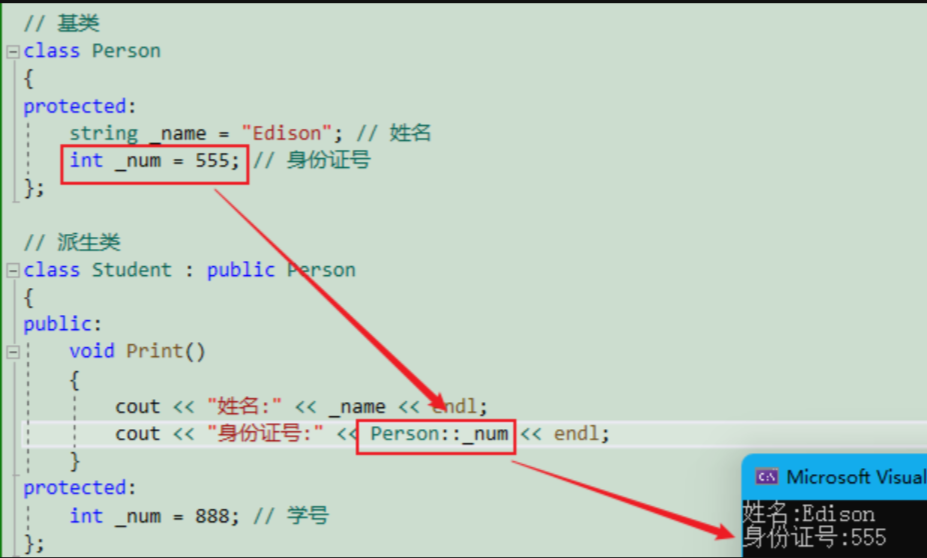
// 基类
class Person
{
protected:string _name = "Edison"; // 姓名int _num = 555; // 身份证号
};// 派生类
class Student : public Person
{
public:void Print(){cout << "姓名:" << _name << endl;cout << " 身份证号:" << Person::_num << endl;}
protected:int _num = 888; // 学号
};int main()
{Student s1;s1.Print();return 0;
}可以看到,此时就是访问的父类中的 _num
还有一点需要注意的是 : 如果是成员函数的隐藏,只需要函数名相同就构成隐藏。
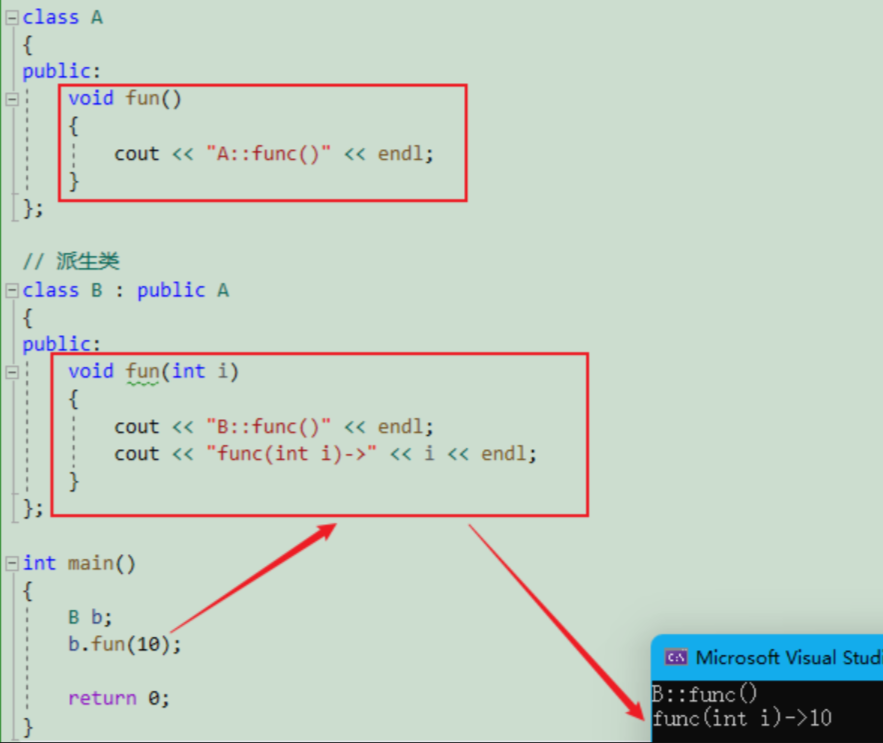
// 基类
class A
{
public:void fun(){cout << "A::func()" << endl;}
};// 派生类
class B : public A
{
public:void fun(int i){cout << "B::func()" << endl;cout << "func(int i)->" << i << endl;}
};int main()
{B b;b.fun(10);return 0;
}可以看到,默认是去调用子类的 fun() 函数,因为成员函数满足函数名相同就构成隐藏。
如果想调用父类的 fun() 还是需要指定作用域
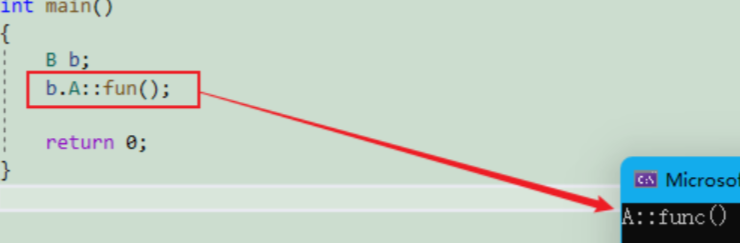
// 基类
class A
{
public:void fun(){cout << "A::func()" << endl;}
};// 派生类
class B : public A
{
public:void fun(int i){cout << "B::func()" << endl;cout << "func(int i)->" << i << endl;}
};int main()
{B b;b.A::fun();return 0;
}运行可以看到,此时就是调用 父类的 fun()
注意 :B 中的 fun 和 A 中的 fun 不是构成函数重载,而是隐藏 !函数重载的要求是在同一作用域里面!!
另外,在实际中在继承体系里面最好不要定义同名的成员。
派生类中的默认成员函数
6个默认成员函数,“默认”的意思就是指我们不写,编译器会变我们自动生成一个,那么在派生类中,这几个成员函数是如何生成的呢?
- 派生类的构造函数必须调用基类的构造函数初始化基类的那一部分成员。如果基类没有默认的构造函数,则必须在派生类构造函数的初始化列表阶段显示调用。
- 派生类的拷贝构造函数必须调用基类的拷贝构造完成基类的拷贝初始化。
- 派生类的operator=必须要调用基类的operator=完成基类的复制。
- 派生类的析构函数会在被调用完成后自动调用基类的析构函数清理基类成员。因为这样才能保证派生类对象先清理派生类成员再清理基类成员的顺序。
- 派生类对象初始化先调用基类构造再调派生类构造,派生类对象析构清理先调用派生类析构再调基类的析构。
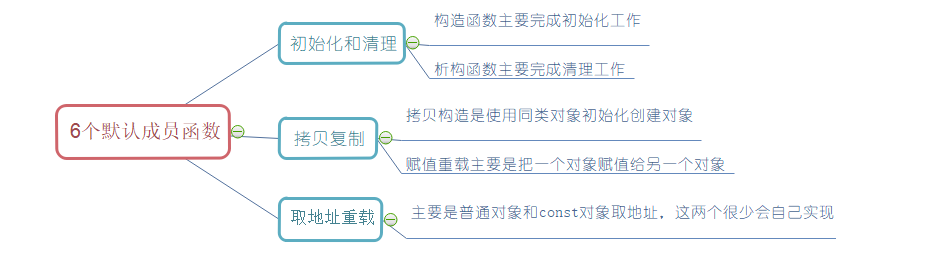
这里我们只以下面的两个类为基础,讨论四类默认成员函数:构造函数、拷贝构造、赋值运算符重载、析构函数
class Person
{
public:Person(const std::string name = std::string(), const int age = 18, const int sex = 1): _name(name), _age(age), _sex(sex){std::cout << "Person()" << std::endl;}Person(const Person& p): _name(p._name), _age(p._age), _sex(p._sex){std::cout << "Person(const Person& p)" << std::endl;}Person& operator= (const Person& p){std::cout << "operator= (const Person& p)" << std::endl;if (this != &p){_name = p._name;}return *this;}~Person(){std::cout << "~Person()" << std::endl;}
protected:std::string _name;int _age = 18;int _sex = 1;
};class Student : public Person
{
public:
protected:long long _st_id;
};默认成员函数的调用
构造函数与析构函数
以下是main函数的逻辑
int main()
{Student st;return 0;
}输出结果
Person() // s1 的构造
~Person() // s1 的析构说明了:派生类的默认构造函数和默认析构函数都会 - 自动调用基类的构造和析构
拷贝构造
int main()
{Student st1;Student st2(st1);return 0;
}输出结果:
Person() // s1 的构造函数
Person(const Person& p) // s2 拷贝构造
~Person() // s2 的析构函数
~Person() // s1 的析构函数说明:派生类的默认拷贝构造会自动调用基类的拷贝构造
赋值运算符重载
int main()
{Student st1, st2;st1 = st2;return 0;
}输出结果
Person() // s1 的拷贝构造
Person() // s2 的拷贝构造
operator= (const Person& p) // 赋值重载
~Person() // s2 的析构函数
~Person() // s1 的析构函数说明:派生类的默认赋值运算符重载会自动调用基类的赋值运算符重载
实际上,我们可以将派生类的成员分成三部分:基类成员、内置类型成员、自定义类型成员
-
继承相较于我们以前学的类和对象,可以说就是多了基类那一部分
-
当调用派生类的默认成员函数时,对于基类成员都会调用对应基类的默认成员函数来处理
显示成员函数的调用
构造函数
当实现派生类的构造函数时,就算不显示调用基类的构造,系统也会自动调用基类的构造:
class Student : public Person
{
public:Student(long long st_id = 111): _st_id(st_id){std::cout << "Student()" << std::endl;}
protected:long long _st_id;
};
int main()
{Student st;return 0;
}输出结果
Person()
Student()
~Person()我们会发现, 这里也没有定义父类对象,但是会调用父类的构造函数,因为C++有规定,派生类必须调用父类的构造函数初始化父类的成员。
如果需要显示的调用基类的构造函数,应该这样写:
Student(long long st_id = 111): _st_id(st_id), Person("xas", 18)
{std::cout << "Student()" << std::endl;
}注意:如果基类没有提供默认构造函数(即没有没有参数的构造函数),并且派生类没有在构造函数初始化列表中显式调用基类的构造函数,则会导致编译错误。必须在派生类的构造函数中显式调用基类的构造函数。

还有个问题,这个是Person先初始化还是id先初始化呢?答案是Person先初始化
因为基类的声明优先级是在派生类之上的。它是把父类看成了一个整体。
派生类初始化的时候,可以初始化基类的成员变量吗?
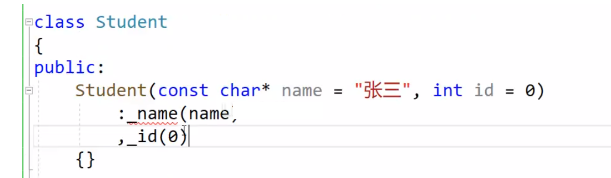
在 C++ 中,当创建派生类对象时,派生类只能初始化派生类中的成员,而基类成员的初始化通常是通过基类的构造函数来完成的。基类的构造函数是在派生类构造函数执行之前调用的。
拷贝构造
派生类的拷贝构造也不能初始化基类的成员

如果我们不写基类的拷贝构造呢?会咋样
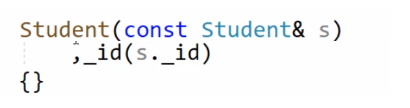
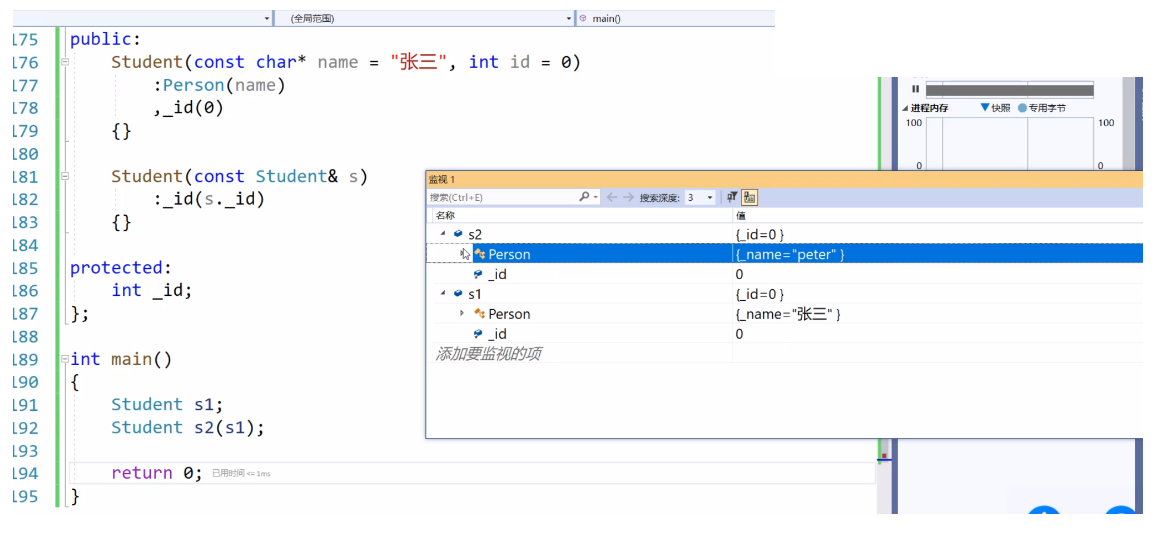
s2的peter就是父类默认构造的内容。如果基类没有提供拷贝构造。就会去调用基类的默认构造构造。要是基类默认构造也没那就会报错。所以派生类也要显示调用拷贝构造
赋值运算符重载
在实现派生类的赋值运算符重载时,如果没有显式调用 基类的赋值运算符重载,系统也不会自动调用基类的赋值运算符重载
class Student : public Person
{
public:Student(long long st_id = 111): _st_id(st_id), Person("xas", 18){std::cout << "Student()" << std::endl;}Student& operator= (const Student& s){std::cout << "operator= (const Student& s)" << std::endl;if (this != &s){_st_id = s._st_id;}return *this;}
protected:long long _st_id;
};
int main()
{Student st1, st2;st1 = st2;return 0;
}输出结果
Person()
Student()
Person()
Student()
operator= (const Student& s)
~Person()
~Person()为什么呢,不是说 派生类的默认赋值运算符重载会自动调用基类的赋值运算符重载吗?
其实这里是构成了隐藏。由于基类和派生类的赋值运算符重载构成隐藏,因此要用 :: 指定类域
Student& operator= (const Student& s)
{std::cout << "operator= (const Student& s)" << std::endl;if (this != &s){Person::operator=(s); //由于基类和派生类的赋值运算符重载构成隐藏,因此要用 :: 指定类域_st_id = s._st_id;}return *this;
}析构函数
在实现派生类的析构函数时,不要显式调用基类的析构函数,系统会在派生类的析构完成后自动调用基类的析构
class Student : public Person
{
public:Student(long long st_id = 111): _st_id(st_id), Person("xas", 18){std::cout << "Student()" << std::endl;}~Student(){std::cout << "~Student()" << std::endl;}
protected:long long _st_id;
};int main()
{Student st1;return 0;
}输出结果
Person()
Student()
~Student()
~Person()这时候可能还会有小伙伴说,为什么呢别的默认成员函数都需要显性调用,而析构函数不要显性呢?
这是因为,如果显示调用了基类的析构,就会导致基类成员的资源先被清理,如果此时派生类成员还访问了基类成员指向的资源就会导致野指针问题。因此,必须保证析构顺序为先子后父,保证数据访问的安全
继承与友元
友元关系不能继承,好比你爸爸的朋友,并不是你的朋友。也就是说 基类友元不能访问子类私有和保护成员,只能访问自己的私有和保护成员。
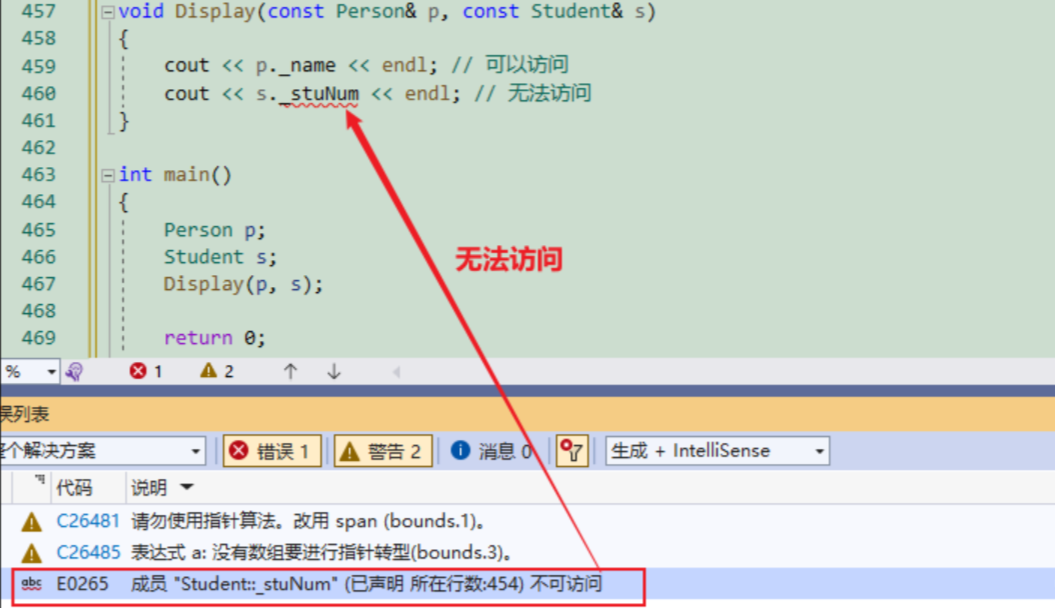
下面代码中,Display 函数是基类 Person 的友元,但是 Display 函数不是派生类 Student 的友元
class Student;class Person
{
public:friend void Display(const Person& p, const Student& s);
protected:string _name; // 姓名
};class Student : public Person
{
protected:int _stuNum; // 学号
};void Display(const Person& p, const Student& s)
{cout << p._name << endl; // 可以访问cout << s._stuNum << endl; // 无法访问
}int main()
{Person p;Student s;Display(p, s);return 0;
}可以看到运行会报错,因为Display是爸爸的朋友,但是可不是儿子的朋友
如果想让 Display 函数也能够访问派生类Student 的私有和保护成员,只需要在派生类Student 当中进行友元声明。
class Student;class Person
{
public:friend void Display(const Person& p, const Student& s); // 声明Display是Person的友元
protected:string _name; // 姓名
};class Student : public Person
{
public:friend void Display(const Person& p, const Student& s); // 声明Display是Student的友元
protected:int _stuNum; // 学号
};void Display(const Person& p, const Student& s)
{cout << p._name << endl; // 可以访问cout << s._stuNum << endl; // 可以访问
}int main()
{Person p;Student s;Display(p, s);return 0;
}继承与静态成员
友元不能继承,但是静态成员有使用权。如果基类中定义了static 静态成员,则整个继承体系里面只有一个这样的成员。 无论派生出多少个子类,都只有一个 static 成员实例。
下面代码中,在基类 Person 当中定义了静态成员变量 _ count, 派生类 Student 和 Graduate 继承了Person
// 基类
class Person
{
public:Person() { ++_count; }
protected:string _name; // 姓名
public:static int _count; // 统计人的个数。
};// 静态成员在类外面定义
int Person::_count = 0; // 派生类
class Student : public Person
{
protected:int _stuNum; // 学号
};// 派生类
class Graduate : public Student
{
protected:string _seminarCourse; // 研究科目
};int main()
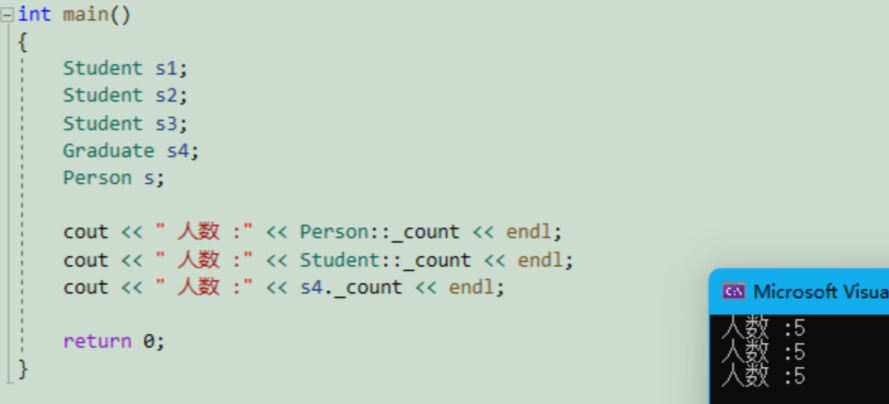
{Student s1;Student s2;Student s3;Graduate s4;Person s;cout << " 人数 :" << Person::_count << endl;cout << " 人数 :" << Student::_count << endl;cout << " 人数 :" << s4._count << endl;return 0;
}我们定义了5个对象,那么每定义一个对象都会去调用一次++ _count ,打印以后可以看到,这几个对象里面的 _count 都是一样的:
同时,我们还可以打印一下地址,可以看到也是同一个:
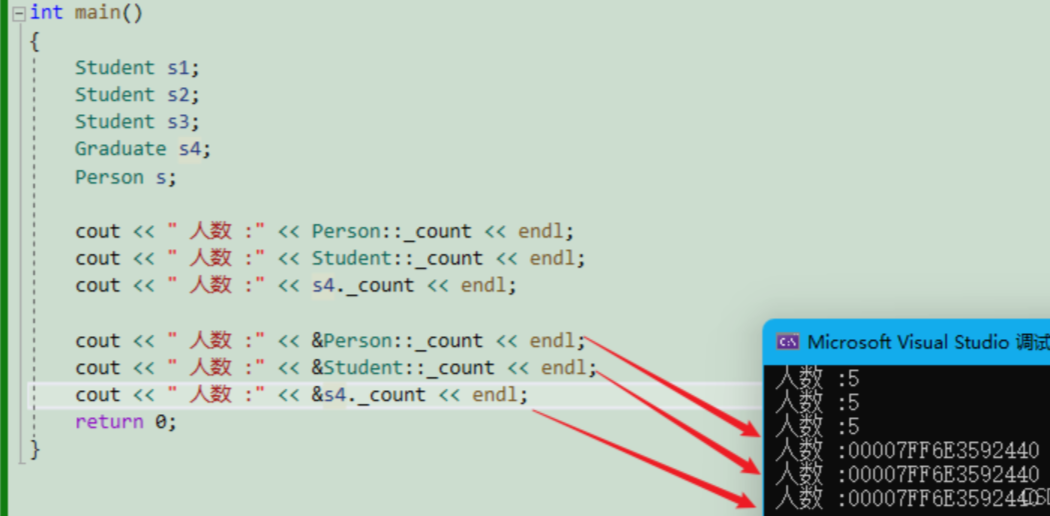
静态成员属于父类和派生类,在派生类中不会单独拷贝一份,它继承的是使用权
如何计算该程序中一共创建了多少个对象??
设置一个静态成员变量,然后在基类的构造函数里++
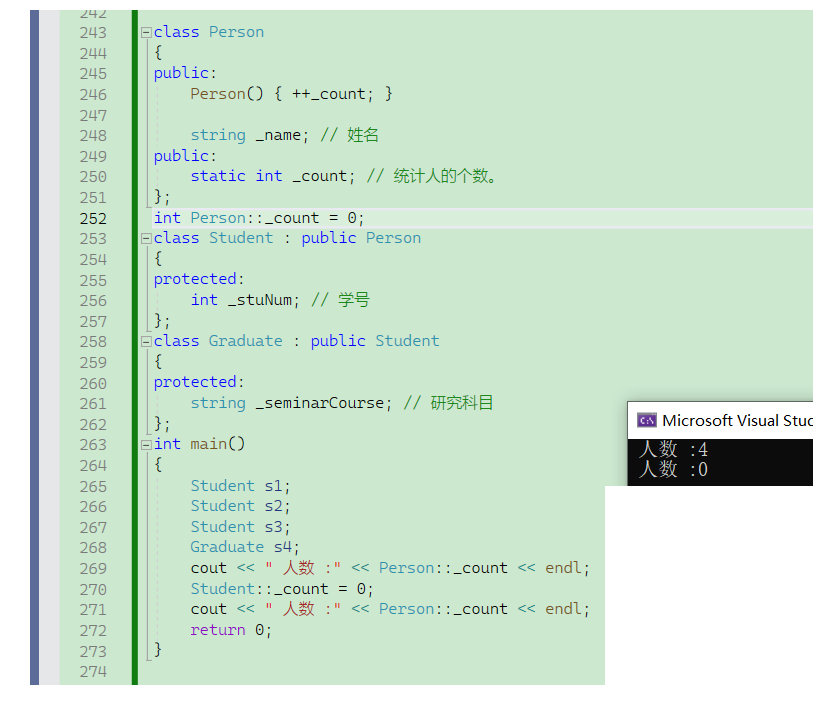
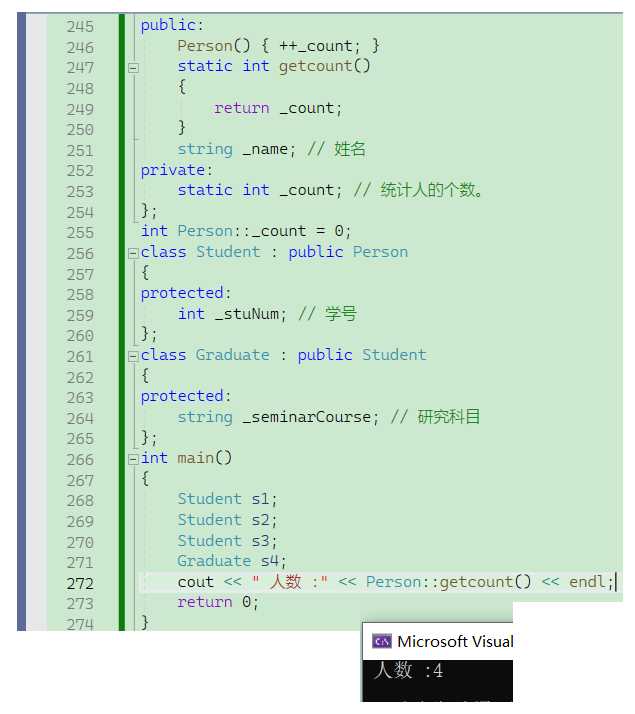
如上图,我们可以发现如果把静态成员设为公有,那么就会出现可以修改的情况,所以我们最好把静态成员变量设成私有,然后用写一个静态成员函数getcount去获取结果。
如何实现一个不能被继承的类 ?
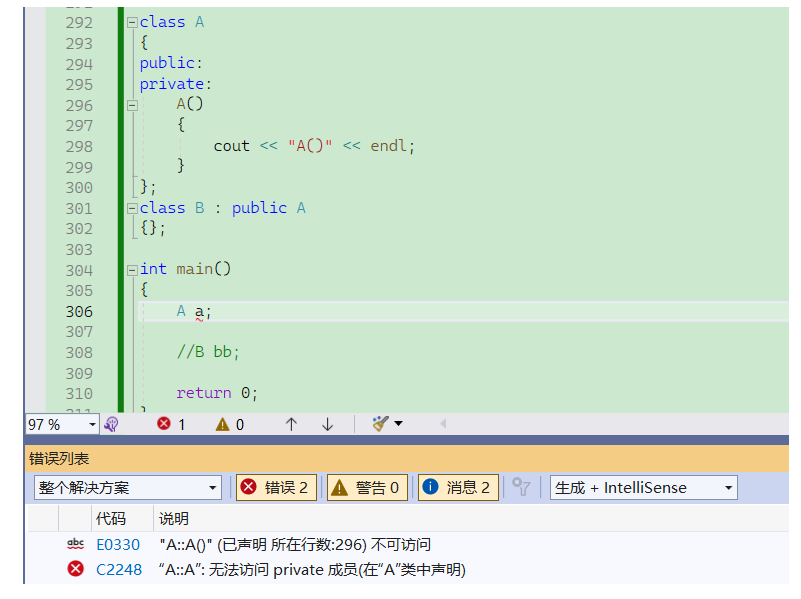
将基类的构造函数藏在私有作用域里,这样继承的时候子类不可见基类构造函数,就无法创建出子类对象了!(将析构函数设成私有也可以)
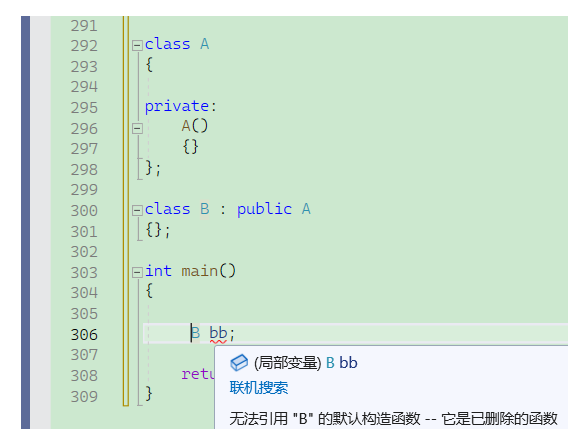
但是你可能会想,把构造函数放在私域,那A不是也创建不了对象了吗???确实是这样的!
但是也有一个解决的方法,就是利用静态成员函数去返回这个构造函数。
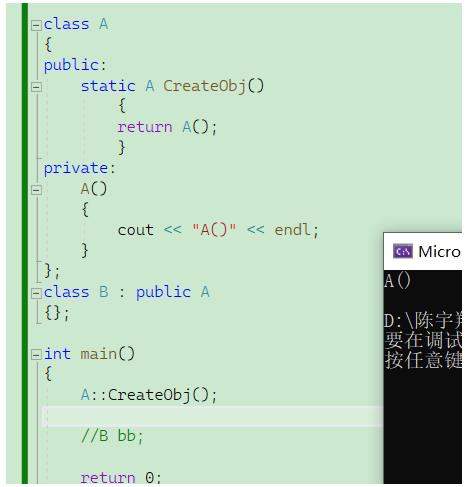
为什么用静态成员函数呢??
因为这涉及到先有鸡还是先有蛋的问题,我们不创建对象就调用不了这个函数,但是要调用这个函数又需要一个对象,所以为了解决这个问题,只能将该函数变成静态成员函数,这样我们可以通过类限定符去访问他
菱形继承
单继承:一个子类只有一个直接父类时称这个继承关系为单继承
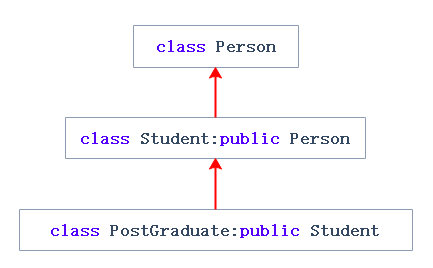
多继承:一个子类有两个或以上直接父类时称这个继承关系为多继承
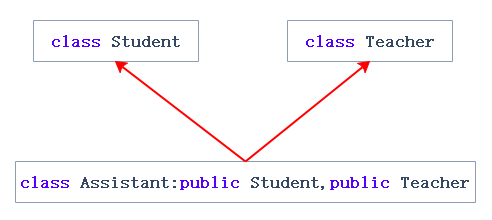
菱形继承:菱形继承是多继承的一种特殊情况。
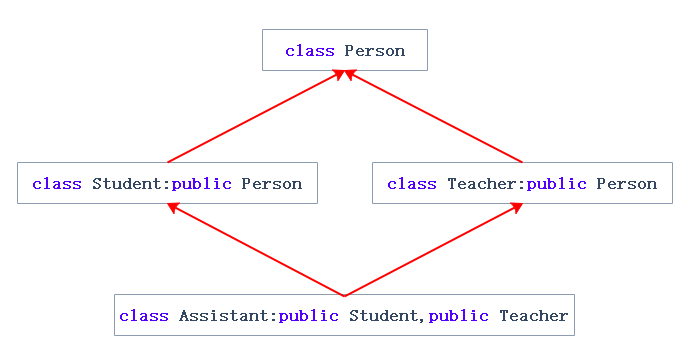
菱形继承的问题:从下面的对象成员模型构造,可以看出菱形继承有数据冗余和二义性的问题。
在Assistant的对象中Person成员会有两份。
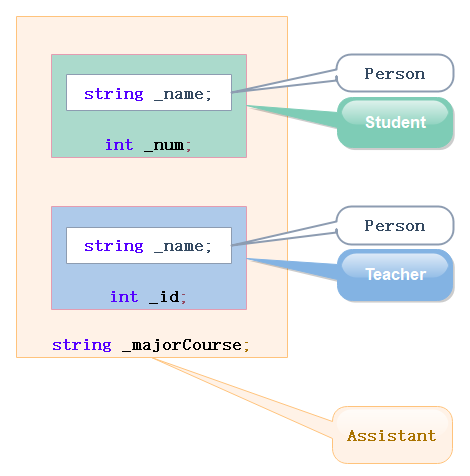
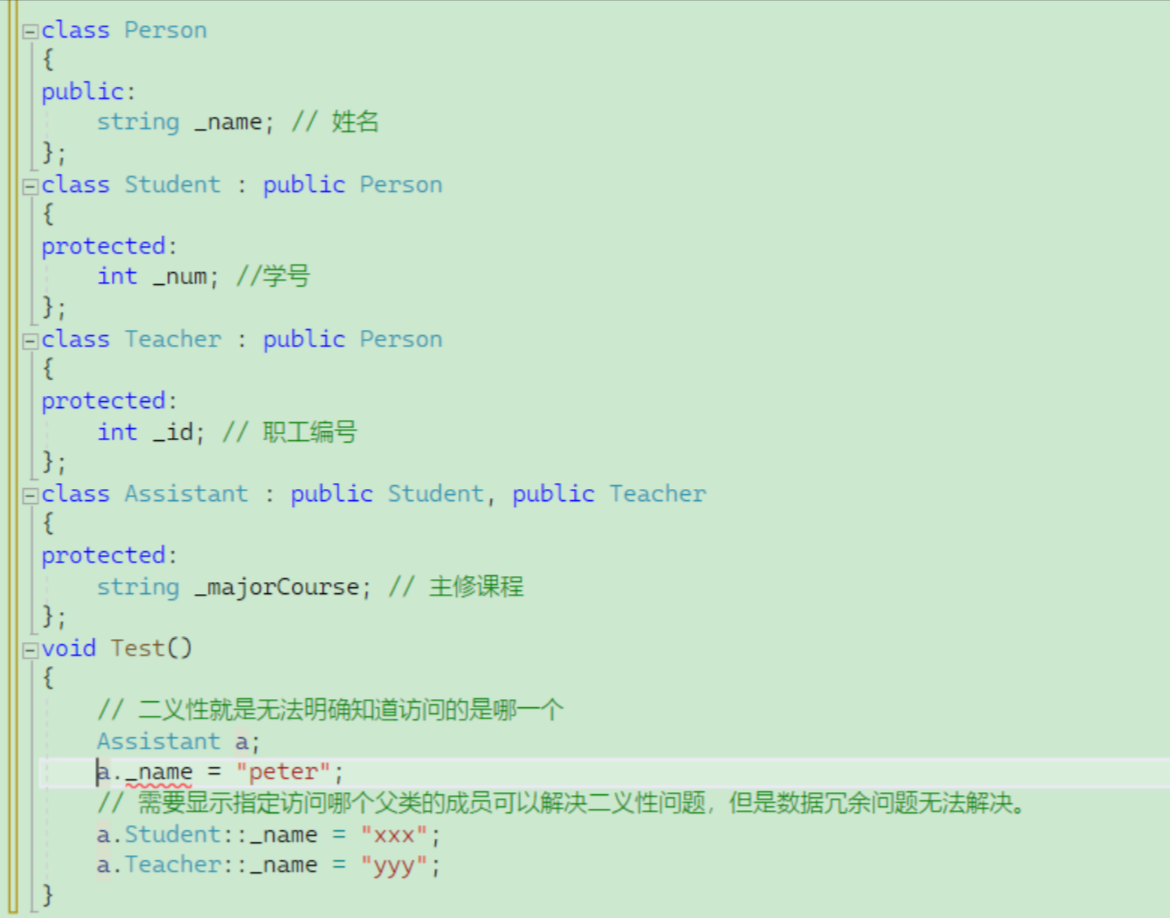
虚拟继承可以解决菱形继承的二义性和数据冗余的问题。如上面的继承关系,在Student和Teacher的继承Person时使用虚拟继承,即可解决问题。
什么是虚继承呢,也就是在继承的中间加一个virtual 例如 class C : virtuai public A
需要注意的是,虚拟继承不要在其他地方去使用。为了能够更好地观察虚继承的过程,我们选择一个较为简单的模型。
class A
{
public:int _a;
};
// class B : public A
class B : public A
{
public:int _b;
};
// class C : public A
class C : public A
{
public:int _c;
};
class D : public B, public C
{
public:int _d;
};
int main()
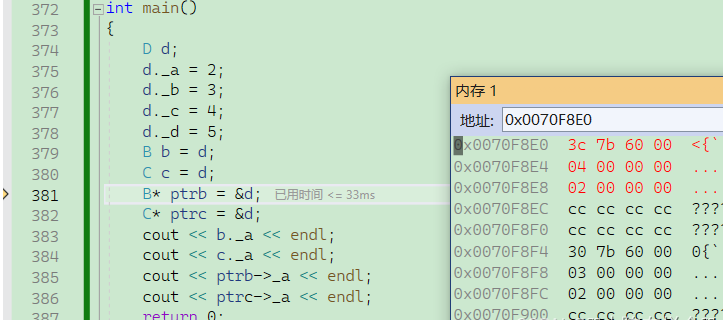
{D d;d.B::_a = 1;d.C::_a = 2;d._b = 3;d._c = 4;d._d = 5;return 0;
}我们先看看没有进行虚继承时,内存中是怎样的
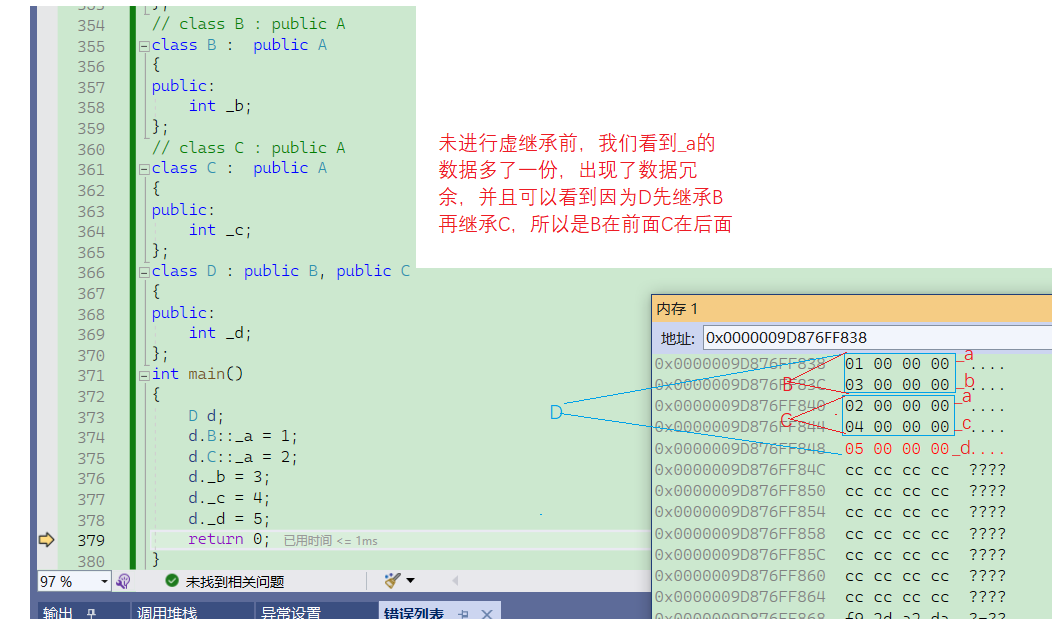
我们看看虚继承后是怎样的,为了能更好地观察,我们用32位环境
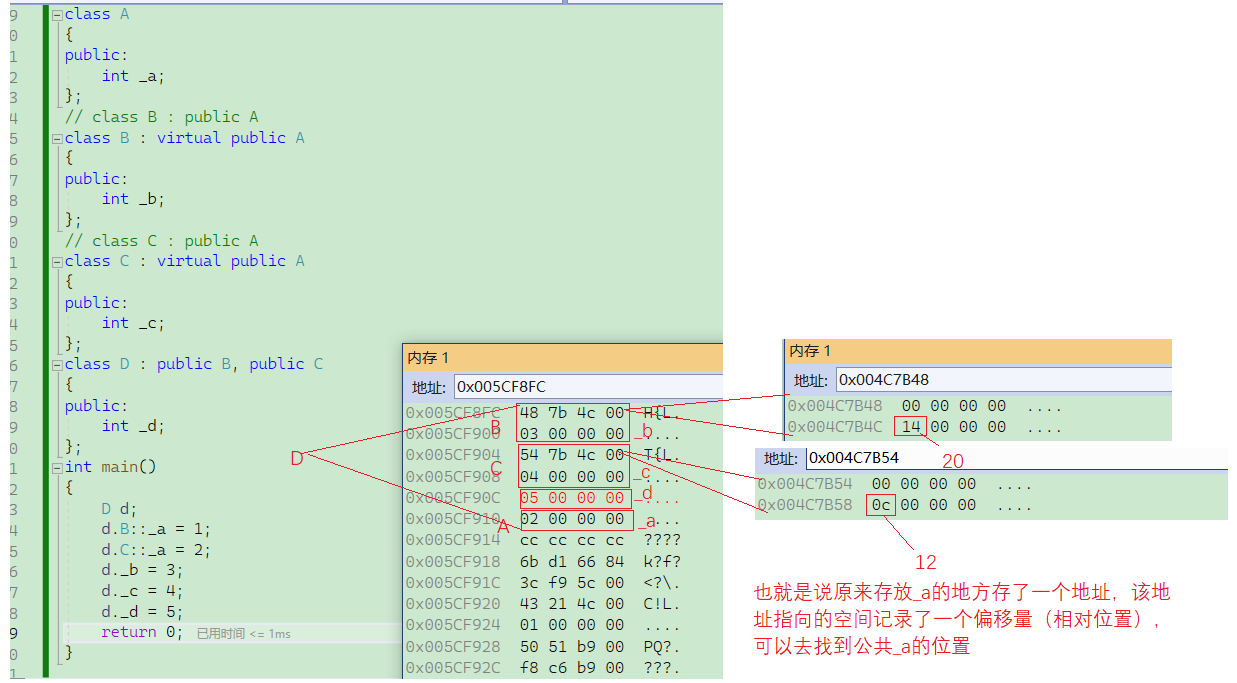
不是为了解决冗余问题吗??为什么这边的空间反而变大了??
解决数据冗余要付出存指针的代价,但是如果冗余的对象超过指针的大小的话,那么就赚了。哪怕真的损耗了一点空间。。至少二义性解决了!!
存的地址指向的空间难道不算空间消耗么??
动态布局的灵活:虚基类的位置是在最终派生类中才确定的,当存在多层虚继承时,不同中间类对同一虚基类的相对偏移可能不同,通过指针可以在运行时进行动态计算,避免了编译时固定偏移的局限。
共享基类的唯一性:虚基类在对象中仅存在一份实例时,若直接存储偏移量,那么每个中间派生类都要维护自己的偏移量,导致冗余,而通过指针可以指向一个共享位置,保证所有访问路径指向同一个实例!
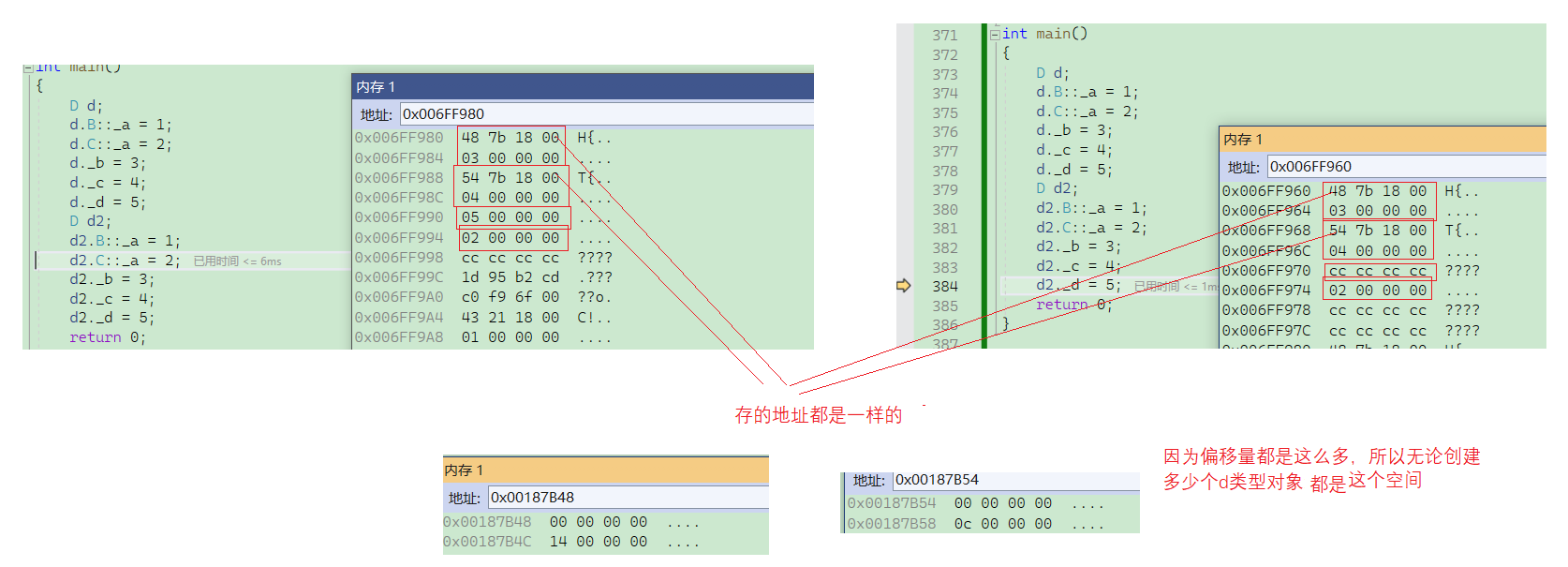
所以如果我们创建了多个d对象,那么存地址的优势就更突出了!!因为偏移量都是一样的
A有一个_a对象,所以有一个指针,如果A有多个对象是存多个指针吗?
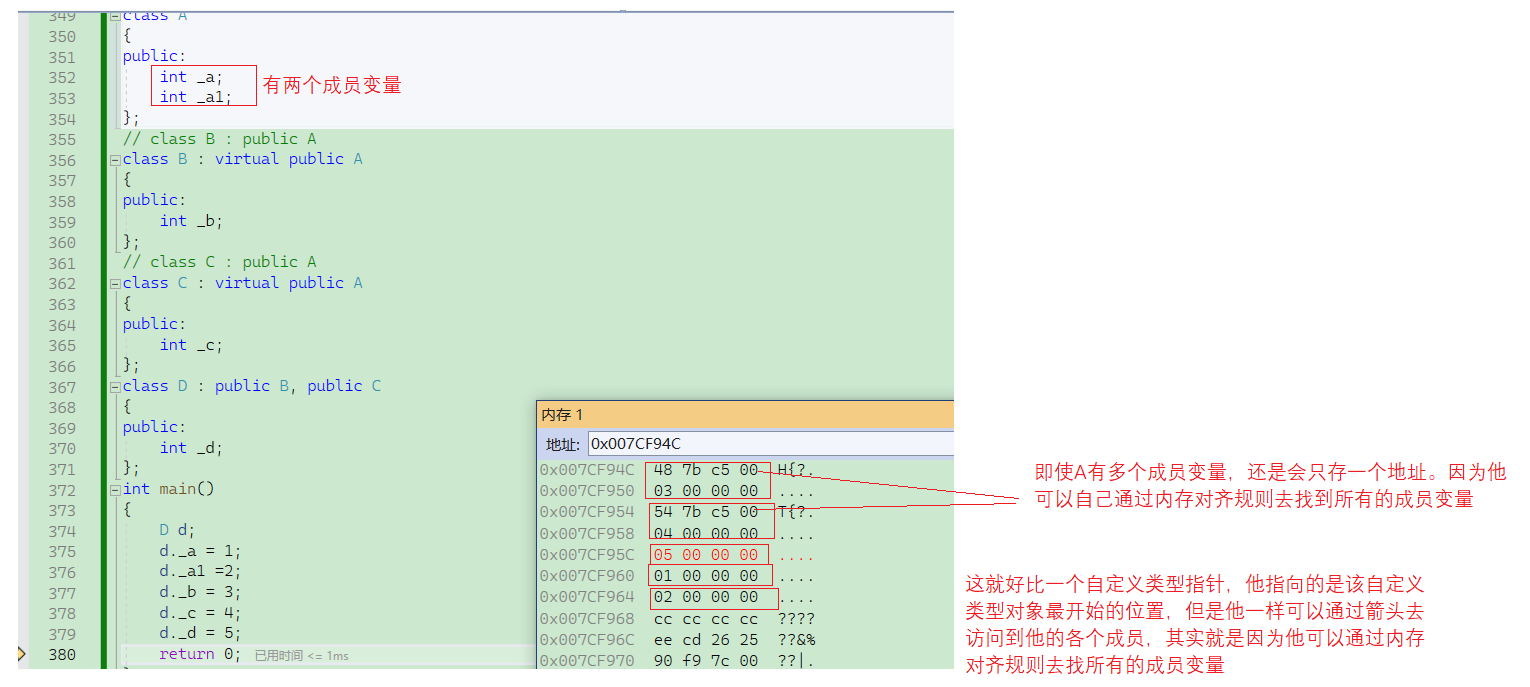
所以哪怕A对象成员变量很多,也只会存一个地址。综合2和3我们可以得到一个结论,无论是创建特别多的d对象,还是说这个a的成员变量非常多,都只会存一个地址。所以虚继承显然能够解决数据冗余的问题。
既然原来b中的a空间存的是一个地址,那如果用b类型或者c类型的指针存d的地址,然后再分别访问_a 或者是用d赋值给b和c类型的对象得到的会是地址吗?
从该图我们可以看到并不会, d赋值给b和c的时候,他们会先通过这个地址找到存放偏移量的空间,然后再回来找到_a,最后也是按照存地址的方式去展现。而B C类型的指针存放d地址的时候,也会通过这个地址找到偏移量,然后再回过头来找_a。所以在这个过程中他们自己会进行处理。从这里我们也可以看到虚继承的访问会存在一定的时间消耗,因为已经不是单纯地解引用了,而是经过了多一层的解引用和计算。
为什么虚基表的前四个字节位置是空出来的??
这是为了后面的虚函数表做准备的,用来存从虚基表找到虚函数表的偏移量(菱形继承多态)。在多态那一环节会去验证。
继承和组合

public 继承是一种 is-a 的关系。也就是说每个派生类对象都是一个基类对象。
而 组合 是一种 has-a 的关系。假设 B 组合了 A,每个 B对象中都有一个 A对象。
继承允许你根据其他类的实现来定义一个类的实现。这种通过生成子类的复用通常被称为白箱复用(white-box reuse)。术语“白箱”是相对可视性而言:在继承方式中,父类的内部细节对子类可见(可以直接访问被继承对象的成员变量)。
对象组合是类继承之外的另一种复用选择。新的更复杂的功能可以通过组装或组合对象来获得。对象组合要求被组合的对象具有良好定义的接口(只能通过接口去访问被组合对象的成员变量)。这种复用风格被称为黑箱复用(black-box reuse),因为对象的内部细节是不可见的。对象只以“黑箱”的形式出现。
继承就好比是全包的旅游团,组合就好比是半包旅游自由团
举个例子: 轿车和奔驰就构成 is-a 的关系,所以可以使用继承。
// 车类
class Car
{
protected:string _colour = "黑色"; // 颜色string _num = "川A66688"; // 车牌号
};// 奔驰
class Benz : public Car
{
public:void Drive(){cout << "好开-操控" << endl;}
};再举个例子:汽车和轮胎之间就是 has-a 的关系,它们之间则适合使用组合。
// 轮胎
class Tire {
protected:string _brand = "Michelin"; // 品牌size_t _size = 17; // 尺寸};// 汽车
class Car {
protected:string _colour = "黑色"; // 颜色string _num = "川A66688"; // 车牌号Tire _t; // 轮胎
};实际项目中,更推荐使用 组合 的方式,这样可以做到 解耦,避免因父类的改动而直接影响到子类
- 公有继承:
is-a—> 高耦合,可以直接使用父类成员 - 组合:
has-a—> 低耦合,可以间接使用父类成员
继承的缺点有以下几点:
①:父类的内部细节对子类是可见的。
②:子类从父类继承的方法在编译时就确定下来了,所以无法在运行期间改变从父类继承的方法的行为。
③:如果对父类的方法做了修改的话(比如增加了一个参数),则子类的方法必须做出相应的修改。所以说子类与父类是一种高耦合,违背了面向对象思想。
组合的优点:
①:当前对象只能通过所包含的那个对象去调用其方法(只能用接口不能用成员变量),所以所包含的对象的内部细节对当前对象时不可见的。
②:当前对象与包含的对象是一个低耦合关系,如果修改包含对象的类中代码不需要修改当前对象类的代码。
③:对象组合是通过获得对其他对象的引用而在运行时刻动态定义的。组合要求对象遵守彼此的接口约定,进而要求更仔细地定义接口,而这些接口并不妨碍你将一个对象和其他对象一起使用。这还会产生良好的结果:因为对象只能通过接口访问,所以我们并不破坏封装性;只要类型一致,运行时刻还可以用一个对象来替代另一个对象。
组合的缺点:①:容易产生过多的对象。②:为了能组合多个对象,必须仔细对接口进行定义。
结论:优先使用对象组合有助于你保持每个类被封装,并被集中在单个任务上。这样类和类继承层次会保持较小规模,并且不太可能增长为不可控制的庞然大物。另一方面,基于对象组合的设计会有更多的对象 (而有较少的类),且系统的行为将依赖于对象间的关系而不是被定义在某个类中。
这导出了我们的面向对象设计的第二个原则:优先使用对象组合,而不是类继承