购买网站模版可以自己做吗哪项属于网页制作工具
什么是RAG
RAG(检索增强生成)是一种将语言模型与可搜索知识库结合的方法,主要包含以下关键步骤:
-
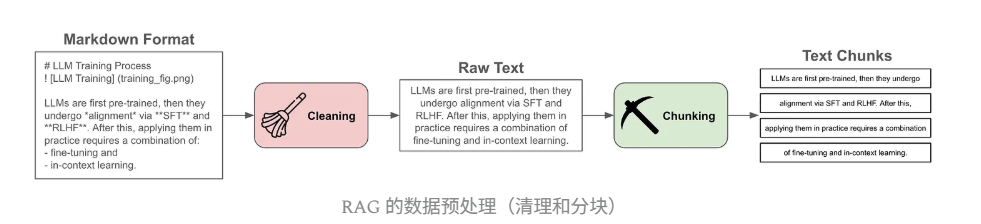
数据预处理
- 加载:从不同格式(PDF、Markdown等)中提取文本
- 分块:将长文本分割成短序列(通常100-500个标记),作为检索单元
-
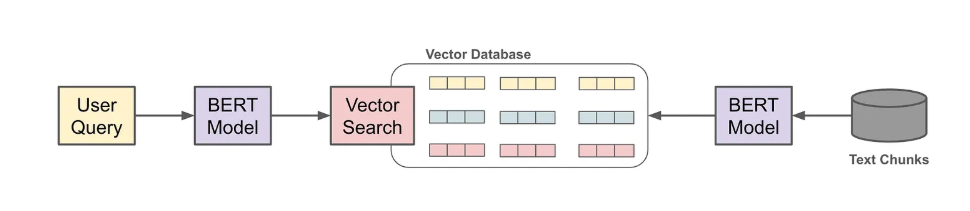
检索系统构建
- embedding:使用embedding模型为每个文本块生成向量表示
- 存储:将这些向量索引到向量数据库中
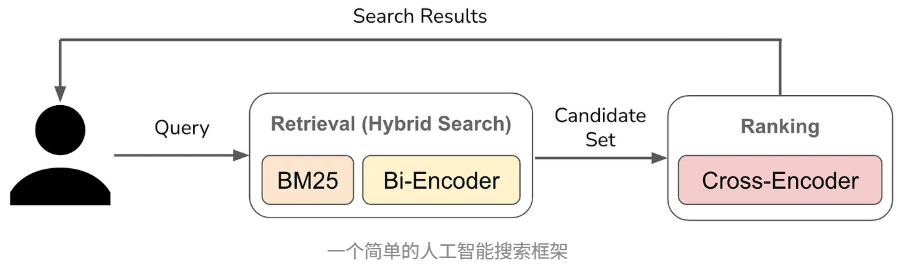
- 可选-重排:结合关键词搜索构建混合搜索系统,并添加重排序步骤
-
查询处理流程
- 接收用户查询并评估其相关性
- 对查询进行嵌入,在向量库中查找相关块
-
生成输出
- 将检索到的相关内容与原始查询一起传递给LLM
- LLM根据这些上下文信息生成更准确、更符合事实的回答
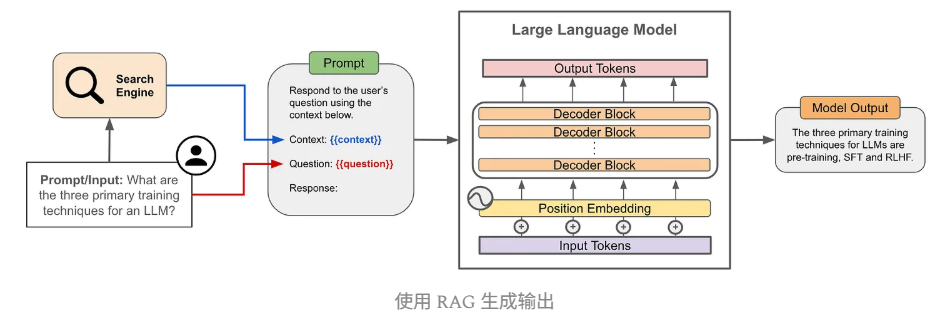
RAG的核心价值在于通过非参数数据源为模型提供正确、具体且最新的信息,从而改进传统LLM的回答质量。
RAG vs 超长上下文
随着模型如Claude、GPT-4和Gemini 1.5等能够处理高达100万tokens甚至200万tokens的输入,业界开始思考一个关键问题:在如此长的上下文支持下,我们未来是否还需要检索增强生成(RAG)技术。
下表将会对比RAG与超长文本优缺点
| 特点 | 超长上下文 | RAG技术 | 实际影响 |
|---|---|---|---|
| 成本 | ⚠️ 高 | ✅ 低 | 200万tokens API调用vs.数千tokens |
| 安全性 | ⚠️ 全部暴露 | ✅ 按需暴露 | 敏感信息保护程度 |
| 检索精度 | ⚠️ 随文档长度降低,AI对更近的文本记忆力更好 | ✅ 相对稳定 | 问答准确率差异 |
| 容量限制 | ⚠️ 有上限(~200万tokens) | ✅ 基本无限 | 可处理知识库规模 |
RAG综合实操
由于本系列已经提到有关RAG的各个细节理论与代码,因此这里有些细节不再重复。
RAG入门篇
环境准备
本机Ollama需要下载了模型,若未下载使用ollama run deepseek-r1:7b
# 安装必要依赖
pip install langchain langchain-community chromadb beautifulsoup4 sentence-transformers langchain-ollama
一个RAG分为一下5个部分
- 加载: 通过
document_loaders完成数据加载 - 分割:
text_splitter将大型文档分割成更小的块,便于索引和模型处理 - 存储: 使用
vectorstores和embeddings模型存储和索引分割的内容 - 检索: 使用
RetrievalQA基于用户输入,使用检索器从存储中检索相关分割 - 生成:
llms使用包含问题和检索数据的提示生成答案
from langchain.document_loaders import WebBaseLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
from langchain.llms import Ollama
import os
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'loader = WebBaseLoader("https://blog.csdn.net/ngadminq/article/details/147687050")
documents = loader.load()text_splitter = RecursiveCharacterTextSplitter(chunk_size=500,chunk_overlap=50
)
chunks = text_splitter.split_documents(documents)embedding_model = HuggingFaceEmbeddings(model_name="BAAI/bge-small-zh"
)vectorstore = Chroma.from_documents(documents=chunks,embedding=embedding_model,persist_directory="./chroma_db"
)# 创建检索器
retriever = vectorstore.as_retriever()template = """
根据以下已知信息,简洁并专业地回答用户问题。
如果无法从中得到答案,请说"我无法从已知信息中找到答案"。已知信息:
{context}用户问题:{question}回答:
"""
prompt = PromptTemplate(template=template,input_variables=["context", "question"]
)#
llm = Ollama(model="deepseek-r1:7b") # 本地部署的模型qa_chain = RetrievalQA.from_chain_type(llm=llm,chain_type="stuff",retriever=retriever,chain_type_kwargs={"prompt": prompt}
)question = "图灵的论文叫什么?"
result = qa_chain.invoke({"query": question})
print(result["result"])

RAG进阶篇
该进阶场景更贴近工业开发需求,比原本RAG增加了如下功能
不同用户的多轮对话
使用ConversationBufferMemory实现记忆功能,同时采用类用session_id来拆分独立chain从而保证用户会话隔离。
from langchain.document_loaders import WebBaseLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.chains import ConversationalRetrievalChain
from langchain.memory import ConversationBufferMemory
from langchain.prompts import PromptTemplate
from langchain.llms import Ollama
import os
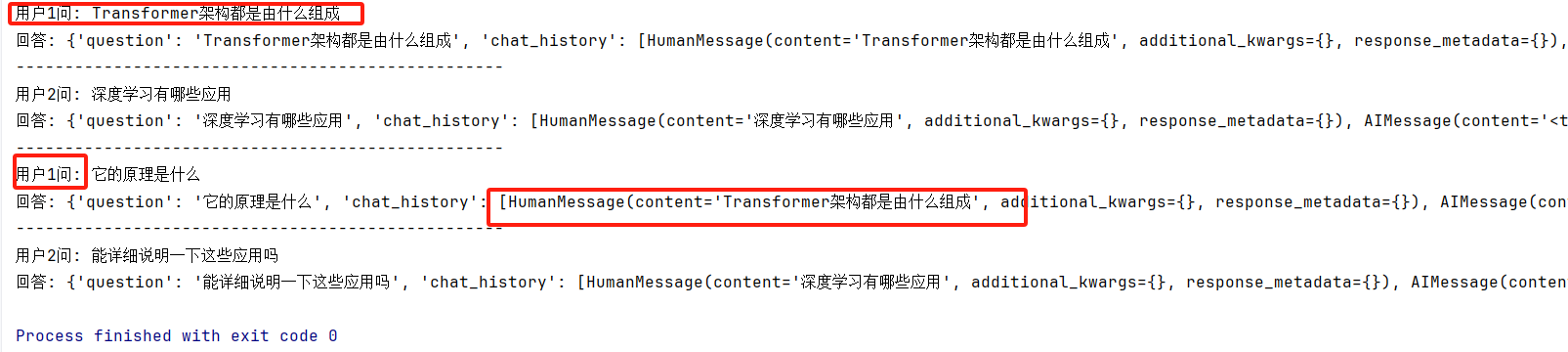
from typing import Dictos.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'class ConversationManager:def __init__(self):# 加载和准备数据(只需执行一次)self.retriever = self._prepare_retriever()self.llm = Ollama(model="deepseek-r1:7b")# 用于存储每个用户会话的记忆self.user_memories: Dict[str, ConversationBufferMemory] = {}# 用于存储每个用户会话的对话链self.user_chains: Dict[str, ConversationalRetrievalChain] = {}# 提示模板self.qa_prompt = PromptTemplate(template="""根据以下已知信息和对话历史,简洁并专业地回答用户当前问题。如果无法从中得到答案,请说"我无法从已知信息中找到答案"。已知信息:{context}对话历史:{chat_history}当前问题:{question}回答:""",input_variables=["context", "chat_history", "question"])def _prepare_retriever(self):"""准备检索器和向量存储"""# 加载文档loader = WebBaseLoader("https://blog.csdn.net/ngadminq/article/details/147687050")documents = loader.load()# 分割文档text_splitter = RecursiveCharacterTextSplitter(chunk_size=500,chunk_overlap=50)chunks = text_splitter.split_documents(documents)# 创建嵌入模型embedding_model = HuggingFaceEmbeddings(model_name="BAAI/bge-small-zh")# 创建向量存储vectorstore = Chroma.from_documents(documents=chunks,embedding=embedding_model,persist_directory="./chroma_db")return vectorstore.as_retriever()def get_user_chain(self, session_id: str):"""获取或创建指定session_id的对话链"""if session_id not in self.user_chains:# 为新用户创建新的记忆组件memory = ConversationBufferMemory(memory_key="chat_history",return_messages=True)self.user_memories[session_id] = memory# 为新用户创建新的对话链chain = ConversationalRetrievalChain.from_llm(llm=self.llm,retriever=self.retriever,memory=memory,combine_docs_chain_kwargs={"prompt": self.qa_prompt})self.user_chains[session_id] = chainreturn self.user_chains[session_id]def process_query(self, session_id: str, query: str):"""处理用户查询并返回响应"""chain = self.get_user_chain(session_id)result = chain.invoke({"question": query})return result["answer"]def clear_history(self, session_id: str):"""清除指定用户的对话历史"""if session_id in self.user_memories:self.user_memories[session_id].clear()def remove_user(self, session_id: str):"""完全移除用户会话数据"""if session_id in self.user_chains:del self.user_chains[session_id]if session_id in self.user_memories:del self.user_memories[session_id]# 演示:如何在命令行中测试多用户功能
def test_multi_user():manager = ConversationManager()# 模拟两个不同用户的会话session1 = "user1"session2 = "user2"# 用户1的对话print(f"用户1问: Transformer架构都是由什么组成")print(f"回答: {manager.process_query(session1, 'Transformer架构都是由什么组成')}")# 用户2的对话print(f"用户2问: 深度学习有哪些应用")print(f"回答: {manager.process_query(session2, '深度学习有哪些应用')}")# 用户1的后续问题(应该能理解上下文)print(f"用户1问: 它的原理是什么")print(f"回答: {manager.process_query(session1, '它的原理是什么')}")# 用户2的后续问题(应该能理解不同的上下文)print(f"用户2问: 能详细说明一下这些应用吗")print(f"回答: {manager.process_query(session2, '能详细说明一下这些应用吗')}")if __name__ == "__main__":test_multi_user()