专业网站定制团队做网站设计怎么样
基于LangChain构建一个RAG对话问答应用
- 前言
- 构建本地代理服务器
- 构建RAG对话问答应用
- 数据加载和拆分
- 集成ChatOpenAI和ModelScope构建文本生成模型实例
- Prompting
- 消息链
- 对话问答流
- 对话演示
- Github
- 参考内容
前言
在上一篇文章中,我们介绍了如何使用OpenAI的ChatOpenAI构建文本生成,但由于囊中羞涩,没有进一步探索。转而使用Hugging Face中的免费模型构建RAG。在本文中,我们采用OpenAI的聊天接口客户端ChatOpenAI,但并未直接使用GPT模型。而是通过本地代理的服务器,调用ModelScope社区中的模型完成RAG应用构建。
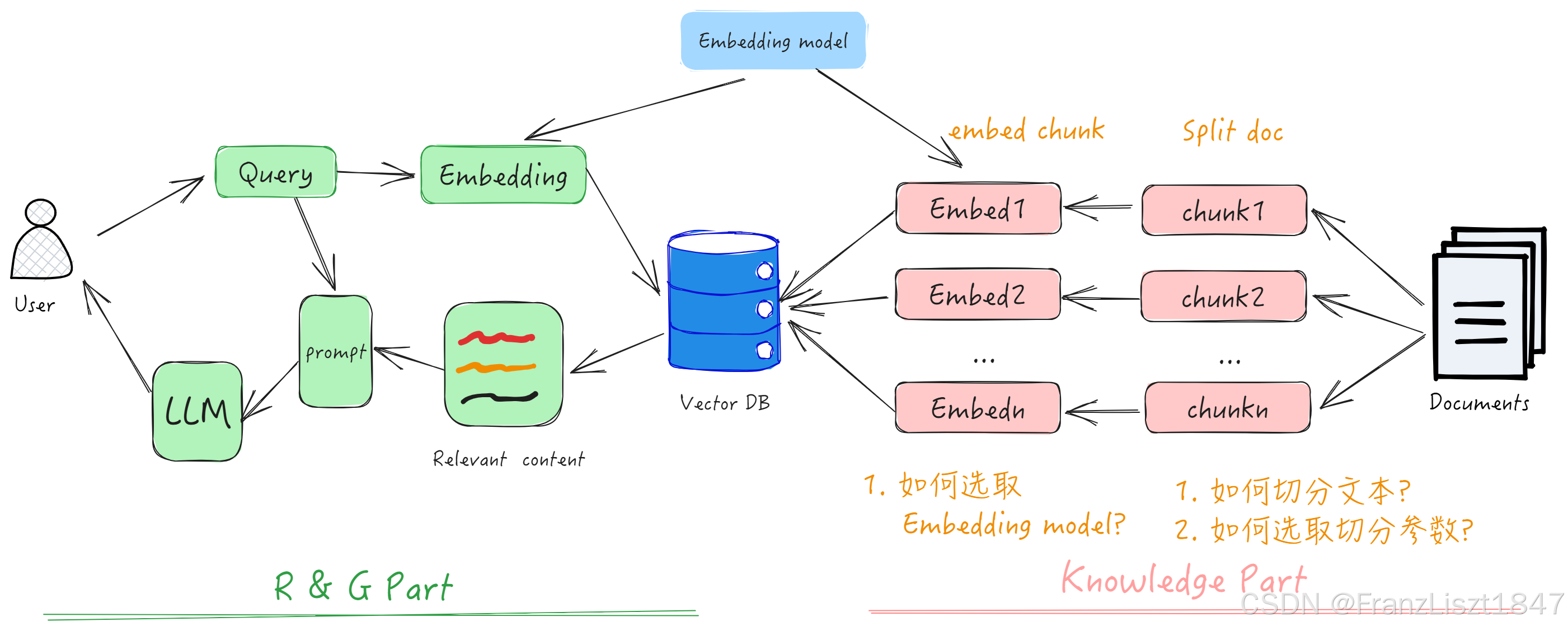
Fig .1 RAG整体框架图
构建本地代理服务器
我们通过下列三句代码构建本地推理服务器。其中,第一句表示:使用ModelScope作为模型的推理后端,同时,程序会将模型推理请求路由到 ModelScope 提供的服务。第二句表示:在 CPU 上,为模型推理分配 8 GB 的 KV 缓存空间(用于存储模型的键值对数据 )。第三句表示:启动了一个本地的推理服务器,通过vLLM框架提供的api_server启动接口,并使用指定的模型进行推理。具体参数解释如下。
- model ‘Qwen/Qwen3-0.6B’:指定使用的模型名称。
- trust-remote-code:允许从远程服务器加载代码,并信任该代码(需要在安全的环境下使用)。
- dtype float16:指定使用 float16 数据类型进行推理,以节省内存和计算资源。
- gpu-memory-utilization 0.6:设置 GPU 内存的使用比例为 60%(如果 GPU 可用)。
export VLLM_USE_MODELSCOPE=True
export VLLM_CPU_KVCACHE_SPACE=8
python -m vllm.entrypoints.openai.api_server --model 'Qwen/Qwen3-0.6B' --trust-remote-code --dtype float16 --gpu-memory-utilization 0.6
构建RAG对话问答应用
数据加载和拆分
在上一篇文章中详细解释了数据加载和拆分的过程,并分析了RecursiveCharacterTextSplitter递归分块的源码。因此,此处不在赘述。值得注意的是,chunk_size默认为4000,而chunk_size越小代表切的块越多,则构建向量相似度时,更能体现词元平均相似度。在综合切割的文本大小和电脑显存可以适当降低chunk_size。
file_path = os.path.abspath('../docs/PatchTST.pdf')
loader = PyPDFLoader(file_path=file_path, extract_images=True)pages = loader.load_and_split()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=50,chunk_overlap=10
)
docs = text_splitter.split_documents(pages)# ?English通用文本表示模型英
embedding = ModelScopeEmbeddings(model_id='iic/nlp_corom_sentence-embedding_english-base')
vectorstore = Chroma.from_documents(documents=docs, embedding=embedding, collection_name='ModelScope')retriever = vectorstore.as_retriever(search_kwargs={'k': 3})
集成ChatOpenAI和ModelScope构建文本生成模型实例
第一句环境变量声明使用ModelScope作为模型的推理后端。我们采用ChatOpenAI聊天接口客户端,但不适用GPT模型。通过将openai_api_key置为EMPTY和将openai_api_base指向本地接口。使得ChatOpenAI在发送请求时,并不会发送到 OpenAI 的服务器,而是本地代理的服务器。stop表示模型在生成响应时应该停止的标记或条件。
os.environ['VLLM_USE_MODELSCOPE'] = 'True'
chat = ChatOpenAI(model='Qwen/Qwen3-0.6B',openai_api_key="EMPTY",openai_api_base='http://localhost:8000/v1',stop=['<|im_end|>']
)
Prompting
SystemMessage、HumanMessage和AIMessage是标准会话类型。用于构建和管理与对话系统相关的消息流程。在现有的LLM模型中,消息流通常由这三类类型构成。下列构建一个简单的Prompt模版,其中MessagesPlaceholder表示为一个占位符,声明为history_messages。而full_prompt代表完整的消息流。首先系统消息,然后中间穿插历史聊天信息,最后加上你最新提问的消息。
system_prompt = SystemMessagePromptTemplate.from_template('You are a helpful assistant!')
user_prompt = HumanMessagePromptTemplate.from_template("""Using the context below, answer the query.context:{context}query:{query}""")
history_messages = MessagesPlaceholder(variable_name='history_messages')
full_prompt = ChatPromptTemplate.from_messages(messages=[system_prompt, history_messages, user_prompt])
消息链
下列字典中的三个key分别对应上述Prompt模版中定义的变量名。而itemgetter 是 Python 标准库 operator 模块中的一个函数,主要用于从对象中提取特定的元素。通常用于从字典或对象中获取值,或者从一个元组中按索引提取元素。
值得注意的是,|被称为管道运算符,在langchain中被用作数据流的连接运算符。简而言之,将上一个流的输出作为下一个流的输入。
- 比如,
itemgetter('query')从字典中取出query的值,然后将此值传入retriever,从向量数据库中检测相似度中的top-k个选项,作为prompt。 - 当字典中的三个元素全部填充完毕之后,将此字典传入
full_prompt中,得到完整的消息流。此消息流作为上下文传入文本生成模型中,可以有效保证答案的上下文。
chat_chain = {'context': itemgetter('query') | retriever,'query': itemgetter('query'),'history_messages': itemgetter('history_messages'),
} | full_prompt | chat
对话问答流
下列实现了一个多轮对话模型。
- 首先,从键盘输入所需要提出的问题,并结合历史消息,传入消息链中,最后由文本生成模型给出答案。
- 将问题和答案依次添加到历史消息中,保证上下文的完整性。
- 只保存最新的10轮对话。因此一次对话由AI和用户构成,因此切片最后20条。
history_messages = []
while True:query = input('query: ')response = chat_chain.invoke({'query': query,'history_messages': history_messages,})history_messages.extend([HumanMessage(content=query), response])print(response.content)# 保存最新的10轮对话history_messages = history_messages[-20:]
对话演示
下列演示了两轮对话结果
query: What is time series forecasting?
/opt/anaconda3/envs/LLM/lib/python3.10/site-packages/transformers/modeling_utils.py:1614: FutureWarning: The `device` argument is deprecated and will be removed in v5 of Transformers.warnings.warn(
<think>
Okay, the user is asking, "What is time series forecasting?" I need to answer based on the provided context. Let me look through the documents.The context has two documents. The first one has a page_content that starts with "for time series forecasting" and mentions "In this paper, we..." and "time series forecasting as metrics." The second document also includes "for time series forecasting" and "time series forecasting as metrics." So, both documents mention time series forecasting. The first one talks about it as a method or a topic in the paper. The second one adds that it's used as metrics. The user just needs a clear answer. Since the context is about the paper, the answer should be based on that information. I should state that time series forecasting is a method used to analyze data over time, possibly as a metric in the paper. Make sure to mention both the description and the usage in the answer.
</think>Time series forecasting is a method used to analyze and predict future values of a variable based on historical data. In the context provided, it is described as a topic in the paper, with the content mentioning "time series forecasting as metrics." This suggests it is used to evaluate or measure time-based patterns in data.
query: What are the current challenges in long-term time series forecasting?
/opt/anaconda3/envs/LLM/lib/python3.10/site-packages/transformers/modeling_utils.py:1614: FutureWarning: The `device` argument is deprecated and will be removed in v5 of Transformers.warnings.warn(
<think>
Okay, the user is asking about the current challenges in long-term time series forecasting based on the provided context. Let me start by looking at the context given.The context has a few documents. The first one mentions "long-term series forecasting" and "in Proc. 39th" as a reference. The second document talks about "for long sequence time-series forecasting" and "in The" for that. The third document is about time series forecasting and mentions "for time series forecasting."Now, the user is specifically asking about challenges in long-term forecasting. The context doesn't explicitly list challenges. However, I can infer based on common challenges in time series forecasting. Long-term forecasting often involves issues like data scarcity, high variability, and the need for accurate models. Also, there might be challenges in handling large datasets, ensuring model accuracy over time, and dealing with non-stationary data.I should check if there's any mention of specific challenges in the documents. The first document talks about "long-term series forecasting" and mentions "metrics," which could relate to evaluation. The third document mentions "time series forecasting" but doesn't delve into challenges. The user's query is about current challenges, so the answer should focus on those areas.Therefore, the current challenges in long-term time series forecasting, based on the context, are likely data scarcity, high variability, model accuracy, handling large datasets, and ensuring non-stationarity. I need to present these points clearly and concisely.
</think>Based on the context provided, the current challenges in long-term time series forecasting include: 1. **Data Scarcity and Limited Historical Data**: Limited availability of historical data can hinder accurate modeling and forecasting.
2. **High Variability and Non-Stationarity**: Time series data often exhibits non-stationary patterns, making it harder to maintain consistent forecasts.
3. **Model Accuracy and Overfitting**: The need for models to generalize well over time can lead to overfitting, especially with limited data.
4. **Data Integration and Complexity**: Combining diverse datasets or integrating with other data sources can increase complexity and require advanced techniques.
5. **Computational Limitations**: Processing large datasets and complex models may pose computational challenges, particularly with real-time or long-term forecasting needs. These challenges highlight the importance of robust data preprocessing, advanced algorithms, and ongoing research to improve forecasting accuracy.Github
项目代码:https://github.com/FranzLiszt-1847/LLM
参考内容
[1] https://www.bilibili.com/video/BV1Cp421R7Y7/?vd_source=49cb02510b110bcee6f8ef1d9d534643
[2] https://www.langchain.com/