秦皇岛营销式网站制作外贸企业网站推广
一、认识ONNX
ONNX(Open Neural Network Exchange)是一种开放的模型表示格式,由微软和Facebook(现Meta)在2017年共同推出,旨在解决深度学习模型在不同框架之间的互操作性问题。ONNX的主要优势包括:
-
跨框架兼容性:
- 支持主流深度学习框架间的模型转换,包括PyTorch、TensorFlow、MXNet、CNTK等
- 例如,可以将PyTorch训练的ResNet模型导出为ONNX格式,然后在TensorRT上进行推理加速
- 提供丰富的转换工具链(如onnx-tf、onnx-tensorrt等)
-
高效推理:
- 支持多种运行时环境,包括ONNX Runtime、TensorRT、OpenVINO等
- 针对不同硬件平台(CPU/GPU/TPU)提供优化后的推理实现
- 支持量化、图优化等加速技术
-
标准化:
- 使用统一的.proto文件定义模型结构
- 包含完整的计算图表示(operators、tensors等)
- 支持模型版本化管理
ONNX模型本质上是一个包含神经网络计算图和参数的序列化文件:
- 采用Protocol Buffers(protobuf)二进制格式存储
- 文件结构包含:
- ModelProto:顶层容器,包含模型元数据
- GraphProto:定义计算图结构(节点、输入输出等)
- TensorProto:存储权重参数
- 典型文件扩展名为.onnx
实际应用场景示例:
- 训练-部署解耦:在PyTorch训练后转为ONNX,部署到不支持PyTorch的嵌入式设备
- 多框架验证:通过ONNX在不同框架间验证模型一致性
- 生产环境优化:使用ONNX Runtime实现高性能推理服务
二、导出ONNX模型
2.1 安装依赖包
首先需要安装必要的Python包:
# 安装PyTorch(如果尚未安装)
# pip install torch torchvision# 安装ONNX相关包
pip install onnx onnxruntime #(和下面加-gpu的二选一就行了,因为GPU版本需要CUDA支持)
# pip install onnxruntime-gpu
pip install onnxruntime-tools # 用于模型优化使用清华源下载链接更快哟~
pip install onnx -i https://pypi.tuna.tsinghua.edu.cn/simple2.2 导出ONNX模型
下面是一个完整的PyTorch模型导出为ONNX的示例:
import torch
import torch.nn as nn
import torch.nn.functional as F# 定义一个简单的PyTorch模型
class SimpleModel(nn.Module):def __init__(self):super(SimpleModel, self).__init__()self.conv1 = nn.Conv2d(1, 32, 3, padding=1)self.conv2 = nn.Conv2d(32, 64, 3, padding=1)self.fc1 = nn.Linear(64*7*7, 128)self.fc2 = nn.Linear(128, 10)def forward(self, x):x = F.relu(self.conv1(x))x = F.max_pool2d(x, 2)x = F.relu(self.conv2(x))x = F.max_pool2d(x, 2)x = x.view(-1, 64*7*7)x = F.relu(self.fc1(x))x = self.fc2(x)return F.log_softmax(x, dim=1)# 实例化模型并设置为评估模式
model = SimpleModel()
model.eval()# 创建一个虚拟输入(用于跟踪模型计算图)
dummy_input = torch.randn(1, 1, 28, 28) # batch_size=1, channels=1, height=28, width=28# 导出模型为ONNX格式
torch.onnx.export(model, # 要导出的模型dummy_input, # 模型输入(用于跟踪计算图)"simple_model.onnx", # 输出ONNX文件名export_params=True, # 是否导出模型参数opset_version=11, # ONNX算子集版本do_constant_folding=True, # 是否优化常量input_names=['input'], # 输入节点名称output_names=['output'], # 输出节点名称dynamic_axes={'input': {0: 'batch_size'}, # 动态维度:批处理大小'output': {0: 'batch_size'}}
)关键参数解释:
-
model: 要导出的PyTorch模型实例 -
args: 模型的输入参数(可以是元组或单个Tensor) -
f: 输出文件名或文件类对象 -
export_params: 是否导出模型参数(默认True) -
opset_version: ONNX算子集版本(推荐11或更高) -
do_constant_folding: 是否进行常量折叠优化 -
input_names: 输入节点的名称列表 -
output_names: 输出节点的名称列表 -
dynamic_axes: 指定哪些维度是动态的(如可变batch_size)
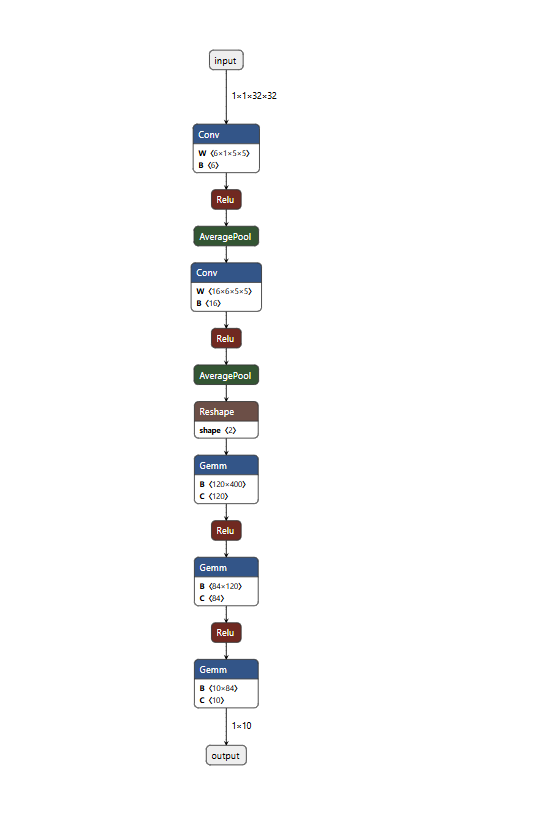
2.3 ONNX结构可视化
可以直接在线查看:Netron
浏览器里面点击上面的网址,选择onnx模型打开就可以了
打不开就复制网址
也可以下载桌面版:https://github.com/lutzroeder/netron
还可以使用Netron工具可视化ONNX模型结构:
1.安装Netron:
pip install netron2.启动可视化:
import netron
netron.start("simple_model.onnx")三、ONNX推理
3.1 简单推理(CPU)
import onnxruntime
import numpy as np# 创建ONNX运行时会话
ort_session = onnxruntime.InferenceSession("simple_model.onnx")# 准备输入数据(与导出时的形状一致)
input_data = np.random.randn(1, 1, 28, 28).astype(np.float32)# 运行推理
ort_inputs = {ort_session.get_inputs()[0].name: input_data}
ort_outs = ort_session.run(None, ort_inputs)# 输出结果
print("Output shape:", ort_outs[0].shape)
print("Predicted class:", np.argmax(ort_outs[0]))关键API解释:
-
onnxruntime.InferenceSession: 创建ONNX模型推理会话-
参数:
-
path_or_bytes: ONNX模型路径或字节流 -
providers: 执行提供者列表(如['CPUExecutionProvider']) -
sess_options: 会话选项(可配置线程数等)
-
-
-
session.run:-
参数:
-
output_names: 需要获取的输出节点名称列表(None表示所有输出) -
input_feed: 输入数据字典(名称到数据的映射)
-
-
3.2 使用GPU推理
import onnxruntime as ort# 检查可用提供者
print("Available providers:", ort.get_available_providers())# 创建GPU会话
ort_session = ort.InferenceSession("simple_model.onnx",providers=['CUDAExecutionProvider'] # 使用CUDA执行提供者
)# 准备输入数据
input_data = np.random.randn(1, 1, 28, 28).astype(np.float32)# 运行GPU推理
ort_inputs = {ort_session.get_inputs()[0].name: input_data}
ort_outs = ort_session.run(None, ort_inputs)# 输出结果
print("GPU inference output:", ort_outs[0])GPU推理注意事项:
-
确保安装了
onnxruntime-gpu而不是onnxruntime -
确认CUDA和cuDNN已正确安装
-
可以通过设置环境变量控制GPU行为:
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0" # 指定使用哪块GPU四、高级主题:动态轴与批处理
ONNX支持动态维度,这在处理可变批量大小或可变序列长度时非常有用:
# 导出时指定动态维度
torch.onnx.export(model,dummy_input,"dynamic_model.onnx",input_names=['input'],output_names=['output'],dynamic_axes={'input': {0: 'batch_size', 2: 'height', 3: 'width'},'output': {0: 'batch_size'}}
)# 推理时可以使用不同形状的输入
ort_session = ort.InferenceSession("dynamic_model.onnx")# 批处理大小为4的输入
batch_input = np.random.randn(4, 1, 28, 28).astype(np.float32)
ort_inputs = {ort_session.get_inputs()[0].name: batch_input}
ort_outs = ort_session.run(None, ort_inputs)
print("Batch output shape:", ort_outs[0].shape) # 应为(4, 10)五、常见问题与解决方案
-
导出失败:不支持的算子
解决方案:检查ONNX opset版本,或自定义符号实现不支持的算子 -
推理结果与原始框架不一致
解决方案:确保导出时的opset版本兼容,检查输入数据预处理是否一致 -
GPU推理性能不佳
解决方案:尝试启用CUDA图捕获(如果ORT版本支持),或使用TensorRT优化 -
模型太大
解决方案:使用ONNX的量化工具减小模型尺寸
六、性能优化技巧
1.使用TensorRT优化ONNX模型
pip install tensorrt
# 使用trtexec工具转换ONNX到TensorRT引擎2.量化模型减小尺寸
from onnxruntime.quantization import quantize_dynamic
quantize_dynamic("simple_model.onnx","quantized_model.onnx",weight_type=QuantType.QUInt8
)3.启用ORT性能调优
sess_options = ort.SessionOptions()
sess_options.enable_profiling = True
sess_options.intra_op_num_threads = 4
ort_session = ort.InferenceSession("model.onnx", sess_options=sess_options)七、总结
本教程详细介绍了如何将PyTorch模型导出为ONNX格式,并展示了如何在CPU和GPU上进行推理。通过ONNX,我们可以轻松实现模型的跨框架部署,为生产环境中的模型服务提供了极大的灵活性。
实际应用中,还需要考虑:
-
模型验证:确保ONNX模型与原始模型行为一致
-
性能基准测试:比较不同运行时和硬件的性能
-
持续集成:将模型导出和验证纳入CI/CD流程
希望这篇教程能帮助你顺利实现模型移植!如果有任何问题,欢迎在评论区讨论。