个人网站收款app开发公司组织结构图
全文摘要
本论文提出了一种大型时间序列模型(Timer),旨在解决数据稀缺场景下时间序列分析的性能瓶颈。通过对高达10亿时间点的统一时间序列数据集进行预训练,Timer采用生成式预训练Transformer架构,能够处理预测、插补和异常检测等多种任务。研究表明,Timer在少量样本下表现出色,具备良好的可扩展性和任务通用性,超越了现有的任务特定模型。
研究背景
-
时间序列分析的挑战
- 时间序列分析在许多实际应用中至关重要,包括预测、缺失值填补和异常检测等。然而,许多深度学习模型在数据稀缺的情况下表现不佳,尤其是在特定应用场景中,训练样本往往非常有限。
-
小模型的性能瓶颈
- 尽管当前的基准测试显示小模型在某些任务上表现良好,但在数据稀缺的情况下,这些模型的性能会显著下降,无法满足实际应用的需求。
-
大型模型的潜力
- 大型模型在处理数据稀缺场景时展现出强大的能力,尤其是通过大规模预训练,能够实现少量样本的泛化能力和任务通用性。这种能力在小型深度模型中是缺乏的。
-
数据集基础设施的不足
- 当前时间序列领域的数据集基础设施相对滞后,缺乏统一的处理方法,导致现有的无监督预训练方法通常规模较小,主要集中在数据集内部的迁移学习。
-
任务统一性缺失
- 现有的大规模预训练模型通常专注于单一任务(如预测),而很少考虑任务的统一性,这限制了大型时间序列模型的适用性和灵活性。
-
生成预训练方法的缺乏
- 尽管无监督预训练在时间序列数据上已有一定探索,但生成预训练方法在该领域的应用相对较少,未能充分利用其在多步生成和灵活性方面的优势。
-
对大型时间序列模型的需求
- 随着对时间序列分析需求的增加,开发大型时间序列模型(LTSM)以应对数据稀缺场景的挑战,成为了一个重要的研究方向。
研究方法
-
大规模数据集的构建
- 本研究构建了一个统一的时间序列数据集(UTSD),包含高达10亿个时间点,旨在为大规模时间序列模型的预训练提供丰富的数据基础。
- 数据集涵盖了七个领域,确保了数据的多样性和复杂性,以便于后续的模型训练和评估。
-
单系列序列(S3)格式的提出
- 为了处理异构时间序列数据,论文提出了单系列序列(S3)格式,将多变量时间序列转换为统一的令牌序列。这种格式保留了时间序列的变化模式,并且不需要时间对齐,适用于广泛的单变量和不规则时间序列。
- 通过这种方式,模型能够更好地捕捉时间序列中的时序依赖性和变化特征。
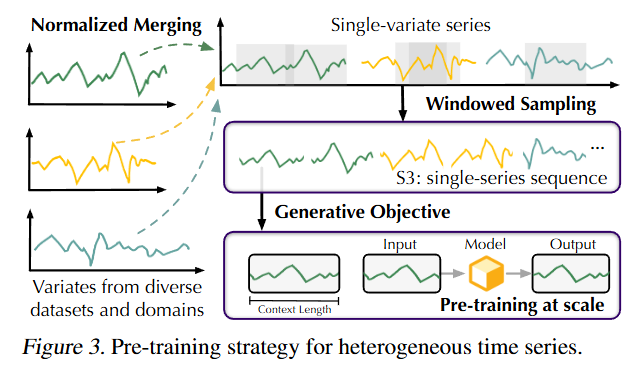
-
生成预训练(GPT)策略
- 采用生成预训练的目标,模型通过预测下一个时间序列令牌进行训练。这种方法使得模型能够在推理时处理不固定的上下文长度,并在多步生成中表现出色。
- 生成预训练的策略使得模型具备了更强的泛化能力和适应性,能够在不同的下游任务中表现出色。
-
模型架构的设计
- 本研究采用了解码器-only的Transformer架构,灵感来源于大型语言模型的成功。与传统的编码器-only架构相比,解码器-only架构在处理时间序列时能够更好地捕捉序列的自回归特性。
- 该架构允许模型在不同的序列长度上进行灵活的预测,增强了模型的适应性和通用性。
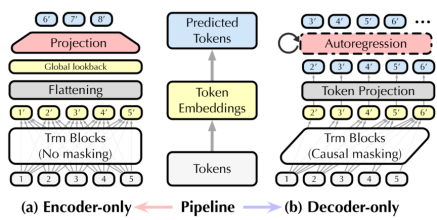
-
多任务统一处理
- 论文将时间序列的预测、插补和异常检测等任务转化为统一的生成任务,利用相同的模型架构和预训练策略来处理不同的任务。这种方法提高了模型的通用性和可扩展性。
- 通过这种统一的处理方式,模型能够在数据稀缺的情况下展现出良好的少样本学习能力。
-
模型的可扩展性研究
- 研究探讨了模型规模和数据规模对性能的影响,验证了随着模型参数和预训练数据的增加,模型性能的提升。这一发现强调了在时间序列分析中,数据基础设施的建设和模型规模的同步扩展的重要性。
通过以上方法,论文展示了如何利用大规模数据和先进的模型架构来推动时间序列分析的研究进展。
实验结果
-
时间序列预测
- 实验设置:使用了多个基准数据集,包括ETT、ECL、Traffic、Weather和PEMS,采用统一的回溯长度672和预测长度96。Timer在UTSD-12G上进行预训练,段长度S为96,令其能够处理上下文长度高达1440的时间序列。
- 结果:Timer在数据稀缺的情况下表现出色,尤其是在仅使用1%到25%的样本时,仍能与先进的小型深度预测模型竞争。与从头开始训练的Timer相比,预训练的Timer在所有样本可用时的预测误差显著降低,表明预训练带来的知识转移效果。
-
插补
- 实验设置:针对段级插补任务,将每个时间序列分为8个段,每个段长度为24,可能完全被掩盖。Timer在UTSD-4G上进行预训练,段长度S为24,令其能够进行生成式插补。
- 结果:Timer在44个插补场景中分别在5%、20%和100%的数据稀缺情况下表现优异,分别在100%、86.4%和56.8%的场景中超越了现有的最先进插补模型,验证了Timer在复杂插补任务中的有效性。
-
异常检测
- 实验设置:使用UCR异常档案库进行实验,包含250个任务,每个任务提供一个正常时间序列用于训练。Timer通过预测未来段来进行异常检测。
- 结果:Timer在检测异常方面表现优于其他先进模型,展示了其生成模型的多功能性。预训练的Timer在检测性能上也优于从头开始训练的模型,表明预训练对提高检测准确性的重要性。
-
可扩展性
- 实验设置:通过增加模型大小和数据规模来评估Timer的可扩展性,使用UTSD-4G作为预训练集。
- 结果:随着模型参数从1M增加到4M,预测误差平均下降了14.7%到20.6%。进一步增加模型维度从3M到50M,性能提升了25.1%和18.2%。数据规模的增加也带来了稳定的性能提升,尽管相较于模型规模的提升,数据规模的提升效果较小。
-
模型分析
- 实验设置:比较Timer与其他四种候选模型(MLP、CNN、RNN和编码器-解码器Transformer)在相同的预训练规模下的表现。
- 结果:Transformer作为LTSM的骨干网络表现出色,能够有效处理多样化的时间序列数据。尽管编码器-解码器模型在训练样本不足时表现较好,但经过预训练的Timer在大多数下游任务中表现最佳,显示出更强的泛化能力。
-
零-shot预测
- 实验设置:建立了首个零-shot预测基准,评估Timer在未见数据集上的表现。
- 结果:Timer在多个未见数据集上表现出色,展示了其在零-shot场景下的强大能力,进一步验证了大模型在时间序列分析中的潜力。