威联通如何做网站宝塔做网站安全吗
生信碱移
贝叶斯网络聚类
CANclust是一种基于贝叶斯的聚类方法,系统性地对基因突变、细胞遗传学信息和临床指标进行联合建模,用于多种模态数据的联合聚类分析,并识别在患者群体中反复出现的特征模式。
个体的遗传与环境背景决定其应对疾病的反应状态,进而产生单一疾病的不同疾病分型。不同疾病分型的病人具有高度异质性,但在临床表现和基因特征上可能存在显著重叠。比如,髓系肿瘤包括急性髓系白血病(AML)、骨髓增生异常综合征(MDS)、慢性髓单核细胞白血病(CMML)和骨髓增殖性肿瘤(MPN)等多个疾病类型,他们之间并非截然分离,而是构成一个连续谱系,其中MDS、CMML 和 MPN 等可进一步进展为AML。
尽管近年来临床分型方法已经逐步由传统临床指标向突变特征转变,但当前分类体系仍面临三大问题:
-
异质性显著:即使是同一疾病,患者在临床表现、预后以及治疗响应方面存在广泛的差异;
-
变量组合十分复杂:基因组层面驱动突变数量众多、相互组合多样,临床协变量(如血液、骨髓指标)与遗传因素的联合分析复杂度极高;
-
聚类方法有限:多数已有聚类研究仅关注基因层面,忽略了临床协变量在亚型识别中的重要性,同时现有的方法在建模中无法体现不同变量类型的差异角色。
为此,来自瑞士生物信息学研究所的研究人员开发了一种基于贝叶斯网络的协变量校正聚类方法(CANclust),于2025年4月30日发表于Nature Communications[IF: 14.7]。CANclust从数据整体视角出发,系统性地对基因突变、细胞遗传学信息和临床指标进行联合建模,用于多种模态数据的联合聚类分析。作者在正文中利用模拟、TCGA、自测数据进行了验证分析,不过像聚类结果出来以后一些套路性的分析比如免疫治疗那些都可以做起来了

▲ DOI:10.1038/s41467-025-59374-1。
简单来讲,CANclust通过建模变量之间的概率关系,识别在患者群体中反复出现的特征模式。对于每一个潜在的患者亚型(聚类结果),该方法都会用一个贝叶斯网络来描述变量间的特征组合,所以不仅考虑了单个特征,也关注了特征变量之间的协同变化。不理解也没关系,反正使用这个聚类方法我们可以除了获得样本聚类结果以外,还能够获得不同聚类特异性的特征交互网络。
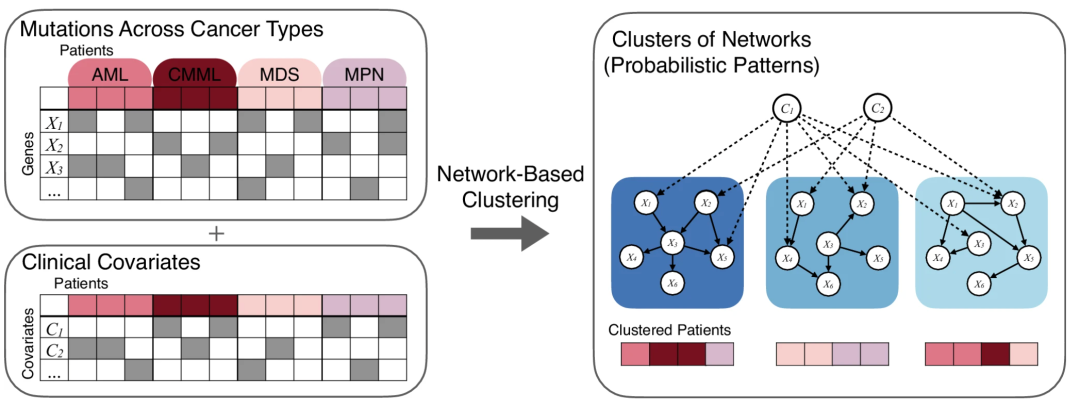
▲ CANcluster原理。该方法以患者在确诊时的基线数据为输入(图左),包括不同癌症类型(左侧颜色区分)、基因突变信息(左上)和临床协变量(左下)。在建模过程中,通过区分协变量类型:Cluster-independent 协变量(如年龄、性别)被设定为仅向突变变量发出边(图右虚线),用于建模其对突变发生的影响,并在聚类时进行统计校正;Cluster-dependent 协变量(如癌症类型)则被视为可能由突变决定的结果变量,可与突变变量共同参与聚类建模。随后贝叶斯网络对不同潜在亚型中的变量依赖结构进行建模(右侧蓝色图结构),每个亚型对应一个特有的网络模型,反映其内在的突变模式与协变量关联结构(图右实线)。通过联合学习网络结构与患者归属(图右下),该方法能够在控制已知协变量影响的基础上,识别出具有生物学一致性和临床解释力的全新患者亚群。
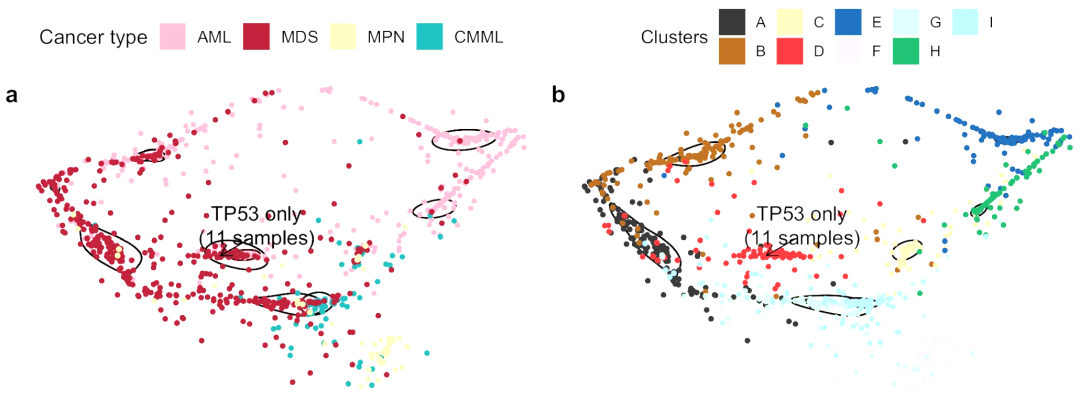
▲ 样本聚类结果演示。一个点代表一个样本,左图为样本真实的癌症类型;右图为对应的聚类结果,总共有A,B,C,D,E,F,G,H,I九个聚类簇。上图为作者NC文章中的结果,表明该方法能够发现新的临床亚型。
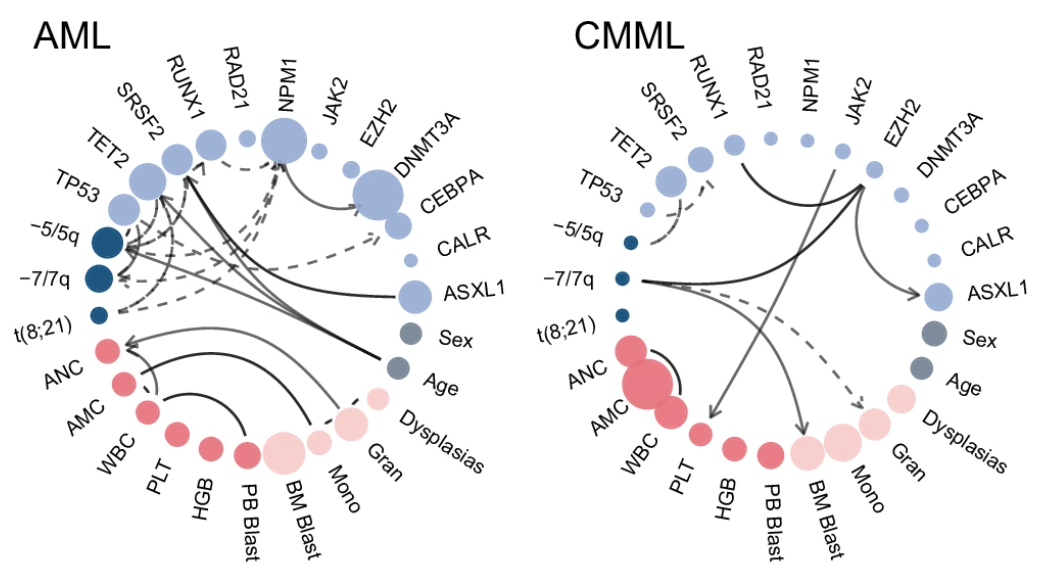
▲ 两种癌症中的特异性网络。除了突变特征以外,还有性别、年龄等临床信息。实线代表正相关,而虚线代表负相关。
01.R包安装
该R包在CRAN中提供,可以使用以下代码进行安装:
install.packages("clustNet")
02.使用示例
①示例数据加载:
library(clustNet)# 模拟数据
ss <- c(400, 500, 600) # samples in each cluster
simulation_data <- sampleData(k_clust = k_clust, n_vars = 20, n_samples = ss)
sampled_data <- simulation_data$sampled_data
模拟了一个基因突变的数据,行是样本共1500个,列是基因共20个。这个数据可以换成其它类型的数据,但是必须是0或1的类别变量。下面简单来看一下:
dim(sampled_data)
#[1] 1500 20# 因为是基因突变数据,所以0/1分别代表无或有突变
sampled_data[1:5, 1:5][,1] [,2] [,3] [,4] [,5]
[1,] 1 0 0 0 1
[2,] 0 1 1 1 0
[3,] 1 0 0 0 0
[4,] 1 0 1 0 0
[5,] 0 0 1 0 0
② 使用get_clusters函数进行聚类,可以指定聚类数量(下面是指定聚为3类)。需要注意一下,sampled_data必须是0/1的变量;n_bg参数默认为0,可以用于指定需要调整的协变量如性别年龄等,但是需要放在sample_data的最后n_bg列(所以默认的0则意味着不需要考虑任何的协变量)。
k_clust <- 3 # 选定聚类为3类
cluster_results <- get_clusters(sampled_data, k_clust = k_clust, n_bg = 0)
可视化一下聚类的结果图:
library(car)
library(ks)
library(graphics)
library(stats)# 2D降维结果
density_plot(cluster_results)
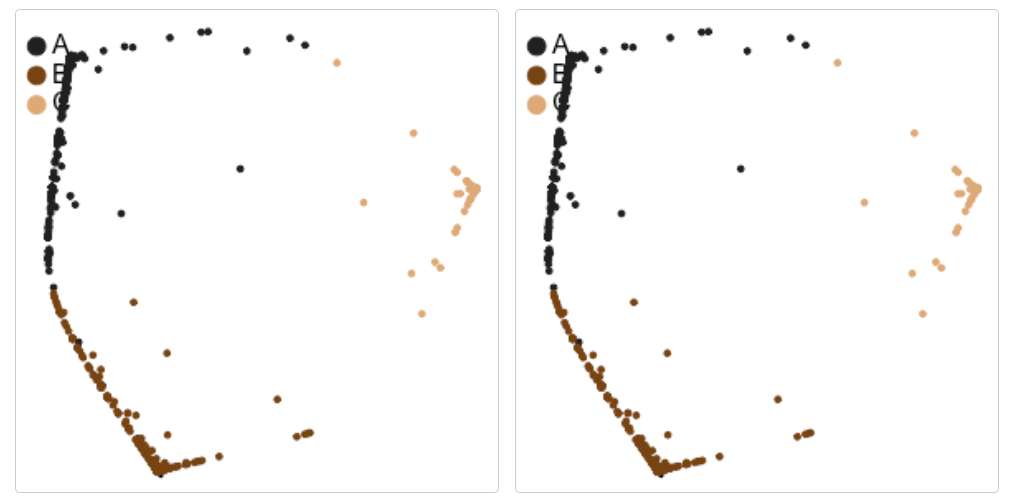
③ 可视化一下聚类特异性特征网络:
library(ggplot2)
library(ggraph)
library(igraph)
library(ggpubr)# 可视化
plot_clusters(cluster_results)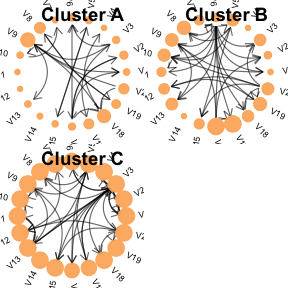
各位老铁51快乐啊
得到工作日了