图片叠加网站企业品牌营销推广
一、引言
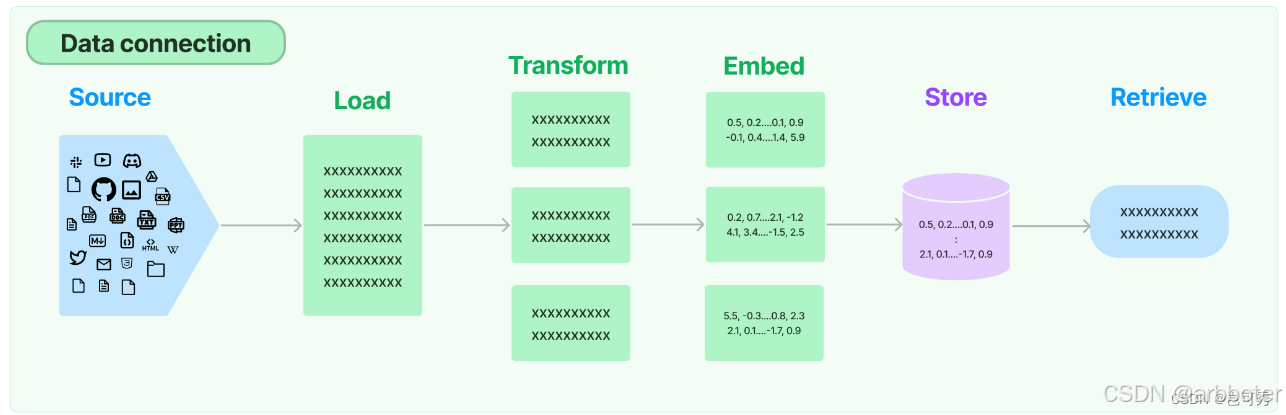
在当今人工智能技术高速发展的浪潮中,文档加载模块作为连接原始数据与智能应用的桥梁,正发挥着不可替代的作用。以LangChain为代表的框架,通过其强大的文档加载器(Document Loaders)模块,为开发者提供了一套标准化、可扩展的数据处理解决方案。
该模块不仅支持从本地文件、网页到云端数据库等20+种数据源的加载能力,更通过统一的Document对象实现了异构数据格式的归一化处理。无论是简单的TXT文本还是包含复杂表格的PDF文档,亦或是嵌入代码段的Markdown文件,该模块都能通过自动识别文件类型、智能解析内容结构,将原始数据转化为携带语义信息和元数据特征的标准化对象。
这种将非结构化数据转化为机器可理解格式的能力,为后续的文本分割、向量化存储和语义检索等RAG(检索增强生成)流程奠定了坚实基础。
二、安装与导入
安装库:
pip install langchain-community # 安装依赖
验证安装:
from langchain_community.document_loaders import DirectoryLoader
三、基本用法
(一)加载目录下的所有文件(需指定文档类型)
loader = DirectoryLoader(path="./data", # 目录路径glob="**/*.txt", # 匹配所有txt文件show_progress=True, # 显示加载进度use_multithreading=True, # 多线程加速loader_cls=TextLoader # 指定文本加载器
)
documents = loader.load()
(二)递归子目录
loader = DirectoryLoader(path="./data",glob="**/*.pdf", # 递归匹配所有子目录的PDF文件recursive=True
)
四、支持的文档格式
(一)文本文件(TXT)
from langchain_community.document_loaders import TextLoaderloader = DirectoryLoader(path="./data", glob="**/*.txt",loader_cls=TextLoader
)
(二)PDF文件
from langchain_community.document_loaders import PyPDFLoaderloader = DirectoryLoader(path="./data",glob="**/*.pdf",loader_cls=PyPDFLoader,loader_kwargs={"password": "1234"} # 可选:加密PDF的密码
)
(三)Word文档(DOCX):不兼容DOC文件,建议DOC文档先转为DOCX格式
from langchain_community.document_loaders import Docx2txtLoaderloader = DirectoryLoader(path="./data",glob="**/*.docx",loader_cls=Docx2txtLoader
)
(四)CSV文件
from langchain_community.document_loaders import CSVLoaderloader = DirectoryLoader(path="./data",glob="**/*.csv",loader_cls=CSVLoader,loader_kwargs={"source_column": "text"} # 指定文本来源列
)
(五)Markdown(MD)
from langchain_community.document_loaders import UnstructuredMarkdownLoaderloader = DirectoryLoader(path="./data",glob="**/*.md",loader_cls=UnstructuredMarkdownLoader
)
(六)HTML文件
from langchain_community.document_loaders import BSHTMLLoaderloader = DirectoryLoader(path="./data",glob="**/*.html",loader_cls=BSHTMLLoader
)
(七)JSON文件
from langchain_community.document_loaders import JSONLoaderloader = DirectoryLoader(path="./data",glob="**/*.json",loader_cls=JSONLoader,loader_kwargs={"jq_schema": ".content", # 使用jq语法提取内容"text_content": False}
)
五、高级用法
(一)混合格式文档处理
若目录包含多种格式,需自定义逻辑:
import os
from langchain_community.document_loaders import (PyPDFLoader, Docx2txtLoader, TextLoader
)loaders = {".pdf": PyPDFLoader,".docx": Docx2txtLoader,".txt": TextLoader
}documents = []
for root, _, files in os.walk("./data"):for file in files:ext = os.path.splitext(file)[1].lower()if ext in loaders:path = os.path.join(root, file)loader = loaders[ext](path)documents.extend(loader.load())
(二)元数据处理
大多数加载器会自动提取元数据(如文件名、路径):
for doc in documents:print(doc.page_content) # 文档内容print(doc.metadata["source"]) # 文件路径
六、注意事项
(一)依赖安装
- PDF:
pip install pypdf - Word:
pip install docx2txt - HTML:
pip install beautifulsoup4 - Markdown/通用格式:
pip install unstructured
(二)大文件处理
- 使用
use_multithreading=True加速加载。 - 对超大PDF或HTML,分块加载避免内存溢出。
(三)错误处理
loader = DirectoryLoader(path="./data",glob="**/*.pdf",silent_errors=True # 忽略错误文件
)
七、通用加载器(Unstructured)
对未明确支持的格式,可使用 UnstructuredFileLoader 处理多种类型(需安装 unstructured):
from langchain_community.document_loaders import UnstructuredFileLoaderloader = DirectoryLoader(path="./data",glob="**/*",loader_cls=UnstructuredFileLoader,loader_kwargs={"mode": "elements"} # 分块模式
)
八、类CSVLoader与UnstructuredCSVLoader的区别及适用场景
(一)核心区别
| 特性 | CSVLoader | UnstructuredCSVLoader |
|---|---|---|
| 底层依赖 | 基于 pandas 库 | 基于 unstructured 库 |
| 数据结构处理 | 将 CSV 解析为结构化 DataFrame | 按非结构化文本处理,保留原始表格结构 |
| 输出格式 | 每行转为纯文本(如 "列名: 值") | 保留行列索引、合并单元格等元数据 |
| 性能 | 高效(适合大型文件) | 较慢(逐行解析非结构化数据) |
| 适用场景 | 结构化数据分析需求 | 复杂表格解析或元数据管理需求 |
(二)场景选择建议
1. 使用 CSVLoader 的场景
• 需求简单:仅需提取 CSV 中的纯文本内容,无需保留表格结构。
• 数据分析导向:需要对 CSV 进行统计、过滤或聚合操作(利用 pandas 的功能)。
• 大文件处理:处理百万行级 CSV 文件时性能更优。
示例代码:
from langchain_community.document_loaders import CSVLoader# 按列名映射提取文本
loader = CSVLoader("data.csv", csv_args={"fieldnames": ["日期", "销售额"]})
docs = loader.load()
# 输出示例:Document(page_content="日期: 2023-01, 销售额: 150万", metadata={"source": "data.csv"})
2. 使用 UnstructuredCSVLoader 的场景
• 复杂表格结构:处理合并单元格、多级表头或非标准分隔符的 CSV。
• 元数据保留:需记录行列索引、表格标题等附加信息。
• 编码兼容性:自动处理未知编码或非 UTF-8 格式的文件。
示例代码:
from langchain_community.document_loaders import UnstructuredCSVLoader# 保留表格结构元数据
loader = UnstructuredCSVLoader("complex_data.csv")
docs = loader.load()
# 输出示例:Document(page_content="Alice", metadata={"source": "complex_data.csv", "row": 0, "col": 0})
(三)性能优化与注意事项
• 依赖安装:
• CSVLoader:需 pip install pandas。
• UnstructuredCSVLoader:需 pip install "unstructured[csv]"。
• 编码处理:对中文文件,建议在 CSVLoader 中显式指定 encoding="utf-8" 。
• 错误处理:使用 try-except 捕获加载异常,避免单文件失败影响整体流程 。
通过灵活配置 DirectoryLoader,可高效加载多种文档格式,适合RAG应用、数据分析等场景,可根据具体需求调整加载策略和参数。