网站一般用什么做的html简单网页代码
定义
1. 大数据(Big Data)
- 指传统数据处理工具难以处理的海量、高速、多样的数据集合,通常具备3V特性(Volume体量大、Velocity速度快、Variety多样性)。扩展后还包括Veracity(真实性)和Value(价值)。
2. Hadoop
- 一个开源的分布式计算框架,用于存储和处理大规模数据集。核心组件包括HDFS(存储)和MapReduce(计算),具有高容错性和横向扩展能力。
3. HDFS(Hadoop Distributed File System)
- Hadoop的分布式文件系统,设计用于**廉价硬件集群**。特点:
- 分块存储(默认128MB/块)
- 多副本机制(默认3副本)
- 主从架构(NameNode管理元数据,DataNode存储实际数据)
4. MapReduce
- 一种批处理编程模型,分为两个阶段:
- Map阶段:将任务分割成更小任务交给每台服务器分别运行,也就是并行处理输入数据(映射)
- Reduce阶段:聚合Map结果(归约)
- 适合离线大规模数据处理,但磁盘I/O开销较大。
5. Spark
- 基于内存的分布式计算引擎,相比MapReduce优势:
- 内存计算(比Hadoop快10-100倍)
- 支持DAG(有向无环图)优化执行计划
- 提供SQL、流处理、图形处理、机器学习等统一API(Spark SQL/Streaming/GraphX/MLlib)
6. 机器学习(Machine Learning)
- 通过算法让计算机从数据中自动学习规律并做出预测/决策,主要分为:
- 监督学习(如分类、回归)
- 无监督学习(如聚类、降维)
- 强化学习(通过奖励机制学习)
关键区别:Hadoop基于磁盘批处理,Spark基于内存迭代计算,机器学习则是数据分析的高级应用方法。
安装Hadoop
1.虚拟机软件安装(搭建Hadoop cluster集群时需要很多台虚拟机)
2.安装Ubuntu操作系统(hadoop最主要在Linux操作系统环境下运行)
3.安装Hadoop Single Node Cluster(只以一台机器来建立Hadoop环境)
- 安装JDK(Hadoop是java开发的,必须先安装JDK)
- 设置SSH无密码登录(Hadoop必须通过SSH与本地计算机以及其他主机连接,所以必须设置SSH)
- 下载安装Hadoop(官网下载Hadoop,安装到Ubuntu中)
- 设置Hadoop环境变量(设置每次用户登录时必须要设置的环境变量)
- Hadoop配置文件的设置(在Hadoop的/usr/local/hadoop/etc/hadoop的目录下,有很多配置设置文件)
- 创建并格式化HDFS目录(HDFS目录是存储HDFS文件的地方,在启动Hadoop之前必须先创建并格式化HDFS目录)
- 启动Hadoop(全部设置完成后启动Hadoop,并查看Hadoop相关进程是否已经启动)
- 打开Hadoop Web界面(Hadoop界面可以查看当前Hadoop的状态:Node节点、应用程序、任务运行状态)
常用命令:
启动HDFS
start-dfs.sh启动YARN(启动Hadoop MapReduce框架YARN)
start-yarn.sh同时启动HDFS和YARN
start-all.sh使用jps查看已经启动的进程(查看NameNode、DataNode进程是否启动)
PS:因为只有一台服务器,所以所有功能都集中在一台服务器中,可以看到:
- HDFS功能:NameNode、Secondary NameNode、DataNode已经启动
- MapReduce2(YARN):Resource Manager、NodeManager已经启动
jps
监听端口上的网络服务:
打开Hadoop Resource-Manager Web界面
http://localhost:8088/NameNode HDFS Web界面
http://localhost:50070/
4.Hadoop Multi Node Cluster的安装(至少有四台服务器,才能发挥多台计算机并行的优势。不过我只有一个电脑,只能创建四台虚拟主机演练)
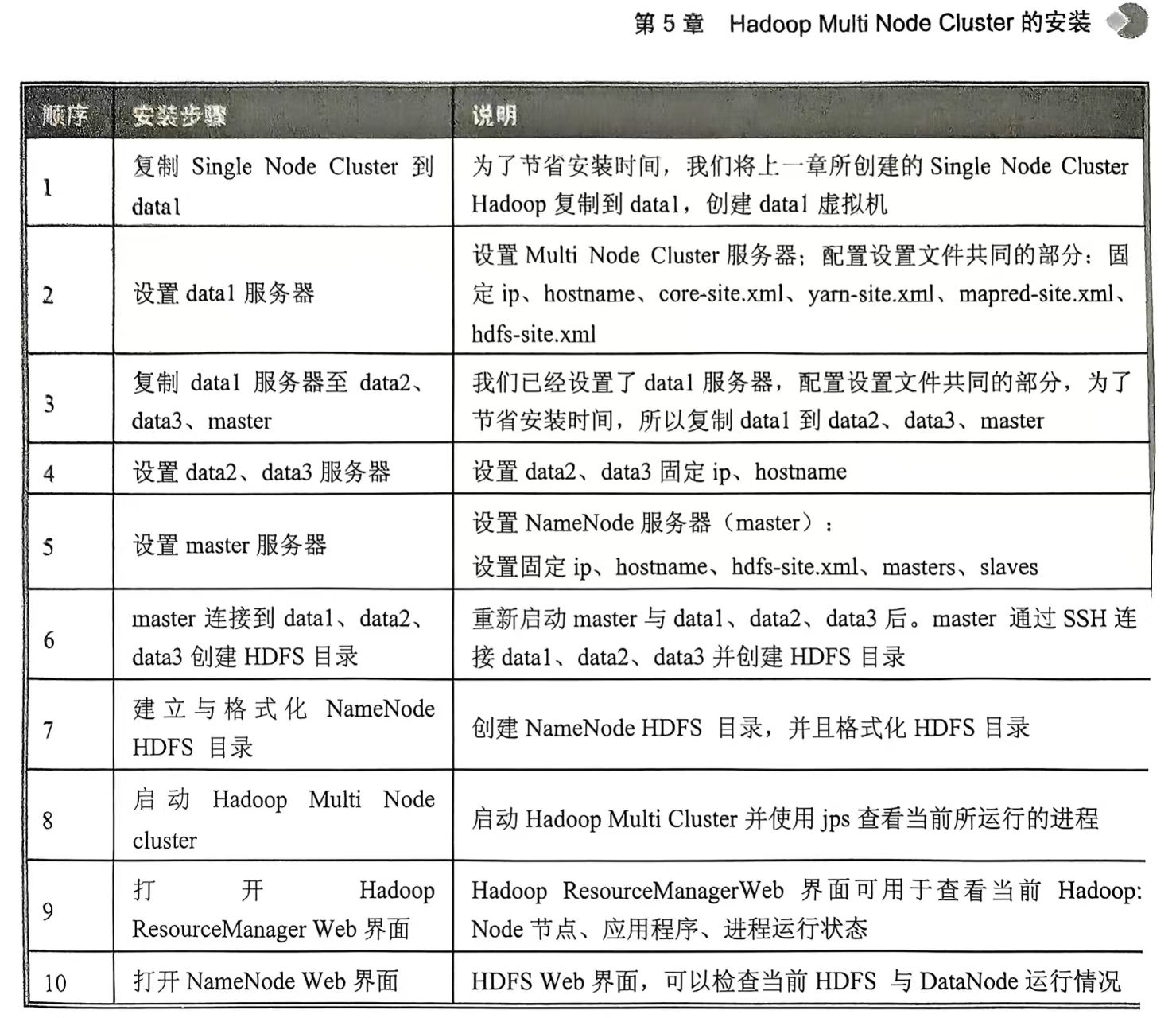
Hadoop的基本功能
1.HDFS
常用HDFS命令:

HDFS 常见命令 -CSDN博客
回头再写那些常用命令
2.MapReduce
Spark的基本功能
机器学习(推荐引擎)
机器学习(二元分类)
机器学习(多元分类)
机器学习(回归分析)
数据可视化
使用Apache Zeppelin数据可视化。