南昌网站做网站排名优化怎么做
Python 数据分析重点知识点
本系列不同其他的知识点讲解,力求通过例子让新同学学习用法,帮助老同学快速回忆知识点
可视化系列:
- Python基础
- 数据分析工具
- 数据处理与分析
- 数据可视化
- 机器学习基础
二、数据分析工具
以下这些工具使用较为频繁,所以设计的例子也比较多,比较详细的,但是实际实用可能用不到这么全面,但是还是尽可能多列举一些
- NumPy
- 高性能数值计算和数组操作库,掌握数组相关操作。
import numpy as np# 创建一个一维数组
array_1d = np.array([1, 2, 3, 4, 5])
print("一维数组:", array_1d)# 创建一个二维数组
array_2d = np.array([[1, 2, 3], [4, 5, 6]])
print("二维数组:\n", array_2d)# 数组的基本操作
sum_array = np.sum(array_1d)
mean_array = np.mean(array_1d)
print("数组求和:", sum_array)
print("数组均值:", mean_array)# 数组变形
reshaped_array = array_2d.reshape(3, 2)
print("变形后的数组:\n", reshaped_array)# 数组切片
sliced_array = array_1d[1:4]
print("切片后的数组:", sliced_array)# 数组运算
added_arrays = array_1d + array_1d
print("数组相加:", added_arrays)- Pandas
- 强大的数据分析和处理库,重点掌握 DataFrame 和 Series 对象功能。
Series专注于一维数据的高效处理与分析,而DataFrame则擅长于二维表格数据的复杂操作与管理。DataFrame一般从CSV文件、Excel文件、SQL数据库等外部数据源读取数据来创建。
import pandas as pd# 创建一个包含整数的Series对象
data = [1, 2, 3, 4, 5]
series = pd.Series(data)
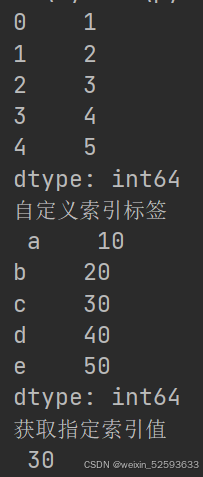
print(series)# 创建一个带有自定义索引标签的Series对象
data = [10, 20, 30, 40, 50]
index_labels = ['a', 'b', 'c', 'd', 'e']
series = pd.Series(data, index=index_labels)
print('自定义索引标签\n',series)# 获取指定索引处的值
value = series['c']
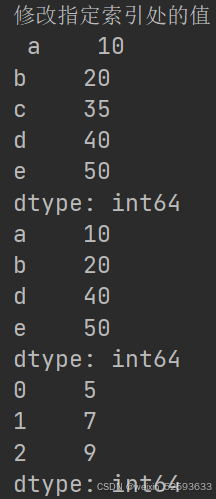
print('获取指定索引值\n',value) # 输出:30# 修改指定索引处的值
series['c'] = 35
print('修改指定索引处的值\n',series)# 删除指定索引处的元素
series = series.drop('c')
print(series)# 两个Series对象相加
series1 = pd.Series([1, 2, 3])
series2 = pd.Series([4, 5, 6])
result = series1 + series2
print(result)
# 结合以上series数据
# 获取索引、数据类型和元素个数
print(series.index) # 输出:Index(['a', 'b', 'd', 'e'], dtype='object')
print(series.dtype) # 输出:int64
print(series.size) # 输出:4
print(series.ndim) # 输出:1# 数据统计方法
print(series.count()) # 输出:4
print(series.mean()) # 输出:28.75
print(series.median()) # 输出:28.75
print(series.std()) # 输出:11.180339887498949import pandas as pd# 创建一个 DataFrame
data = {'Name': ['Alice', 'Bob', 'Charlie'],'Age': [25, 30, 35],'Salary': [50000, 60000, 70000]
}
df = pd.DataFrame(data)
print("DataFrame:\n", df)# 访问 DataFrame 的列
print("Names:\n", df['Name'])# 基本的数据操作
df['Age'] = df['Age'] + 1 # 增加年龄
print("增加年龄后的 DataFrame:\n", df)# 描述性统计
print("描述性统计:\n", df.describe())# 数据过滤
filtered_df = df[df['Age'] > 30] #python语法形式非常灵活
print("过滤后的数据:\n", filtered_df)# 数据排序 常使用
sorted_df = df.sort_values(by='Salary', ascending=False)
print("按工资排序后的数据:\n", sorted_df)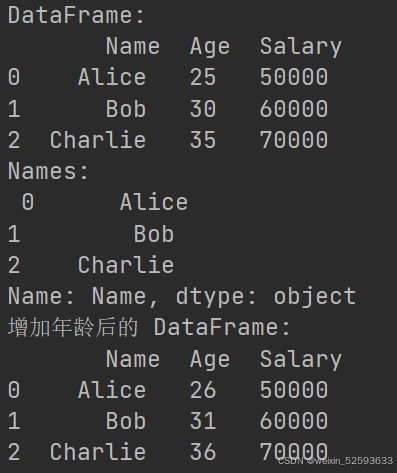
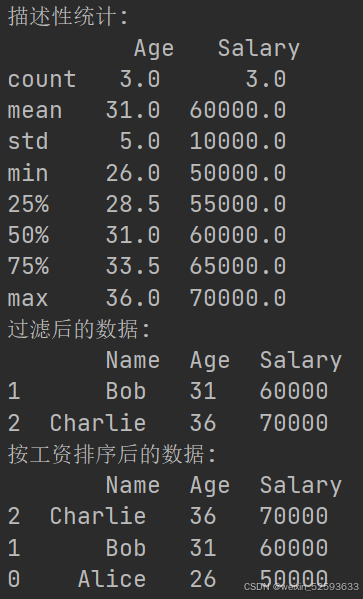
df.describe() 是 pandas 库中的一个方法,用于生成数据框(DataFrame)中数值列的统计摘要。具体来说,它会计算并返回以下统计量:
count: 非空值的数量。
mean: 平均值。
std: 标准差。
min: 最小值。
25%: 第一四分位数(25th percentile)。
50%: 中位数(50th percentile),即第二四分位数。
75%: 第三四分位数(75th percentile)。
max: 最大值。这些统计量可以帮助你快速了解数据的基本特征和分布情况。例如,通过查看均值和标准差,你可以了解数据的集中趋势和离散程度;通过查看最小值和最大值,你可以了解数据的取值范围;通过查看四分位数,你可以了解数据的分布情况。
- Matplotlib
- 常用数据可视化库,绘制各种类型图表。
import matplotlib.pyplot as plt
## 这里列举了常用图表的绘制,如果是图表设置的各种细节,如果评论需要的话我再补一下具体例子
# 创建一些数据
x = [1, 2, 3, 4, 5]
y = [10, 20, 25, 30, 40]# 绘制折线图
plt.plot(x, y)
plt.title('Line Plot')
plt.xlabel('X-axis')
plt.ylabel('Y-axis')
plt.show()# 绘制散点图
plt.scatter(x, y)
plt.title('Scatter Plot')
plt.xlabel('X-axis')
plt.ylabel('Y-axis')
plt.show()# 绘制柱状图
categories = ['A', 'B', 'C', 'D', 'E']
values = [5, 7, 3, 8, 6]
plt.bar(categories, values)
plt.title('Bar Chart')
plt.xlabel('Categories')
plt.ylabel('Values')
plt.show()- Seaborn
- 基于 Matplotlib 的高级可视化库,绘制复杂统计图表。
tips数据集是Seaborn库中自带的一个示例数据集,包含了人们在餐厅消费时的一些信息,具体如下:
数据集来源:该数据集来源于餐厅侍者收集的关于小费的数据。
数据列说明:
total_bill:总账单金额(美元),即顾客在餐厅消费的总金额。
tip:小费金额(美元),顾客给餐厅侍者的服务费。
sex:服务员性别,分为男性和女性。
smoker:是否吸烟,分为是(Yes)和否(No)。
day:周几,例如Sun(周日)、Sat(周六)等。
time:午餐、晚餐,表示顾客就餐的时间段。
size:就餐人数,即一起就餐的顾客数量。
- 数据集下载
- 散点图(Scatter Plot)
import seaborn as sns
import pandas as pd
import matplotlib
import matplotlib.pyplot as plt# 设置中文字体
#matplotlib.rcParams['font.sans-serif'] = ['SimHei']
#matplotlib.rcParams['font.family']='sans-serif'
# 尝试从本地加载数据集
tips = pd.read_excel('./tips.xls')
#tips = sns.load_dataset('tips')# 使用 Seaborn 绘制散点图
sns.scatterplot(x='total_bill', y='tip', data=tips)
plt.title('Scatter Plot of Total Bill vs Tip')
plt.show()

- 散点图显示了
total_bill(总账单金额)和tip(小费金额)之间的关系。 - 通过观察散点图,可以了解不同账单金额对应的小费金额分布情况。
结论
- 从图中可以看出,账单金额与小费金额之间可能存在某种关系。
- 箱线图(Box Plot)
import seaborn as sns
import pandas as pd
import matplotlib
import matplotlib.pyplot as plt# 设置中文字体
#matplotlib.rcParams['font.sans-serif'] = ['SimHei']
#matplotlib.rcParams['font.family']='sans-serif'# 尝试从本地加载数据集
tips = pd.read_excel('./tips.xls')
#tips = sns.load_dataset('tips')# 使用 Seaborn 绘制箱线图
sns.boxplot(x='day', y='total_bill', data=tips)
plt.title('Box Plot of Total Bill by Day')
plt.show()

- 箱线图显示了不同天(星期几)的总账单金额的分布情况。
- 通过箱线图,可以观察到不同天的总账单金额的中位数、四分位数以及异常值。
结论
- 从图中可以看出,某些天的总账单金额分布可能与其他天有所不同,这可能与顾客的消费习惯或特定日子的促销活动有关。
综上: 可以说tips 数据集为研究餐厅消费行为提供了丰富素材,有助于洞察顾客的消费习惯和小费给付倾向,从而为餐厅经营策略的制定提供数据支持。