做一个多肉网站可以做哪些内容搜索引擎营销包括
一、
随机创建不同二维数据集作为训练集 ,并结合k-means算法将其聚类 ,你可以尝试分别聚类不同数量的簇 ,并观察聚类 效果:
聚类参数n_cluster传值不同 ,得到的聚类结果不同
代码展示:
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
import matplotlib.pyplot as pltplt.rcParams["font.sans-serif"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = Falsex,_ = make_blobs(n_samples=1000,centers=[[-1,-1],[0,0],[1,1],[2,2]],cluster_std=[0.4,0.2,0.2,0.2],random_state=42
)plt.subplot(221)
plt.scatter(x[:,0],x[:,1],s=5,marker="o")kmeans_2 = KMeans(n_clusters=2)
kmeans_3 = KMeans(n_clusters=3)
kmeans_4 = KMeans(n_clusters=4)kmeans_2.fit(x)
y_pred = kmeans_2.predict(x)
plt.subplot(222)
plt.scatter(x[:,0],x[:,1],c=y_pred,s=5,marker="o")kmeans_3.fit(x)
y_pred = kmeans_3.predict(x)
plt.subplot(224)
plt.scatter(x[:,0],x[:,1],c=y_pred,s=5,marker="o")kmeans_4.fit(x)
y_pred = kmeans_4.predict(x)
plt.subplot(223)
plt.scatter(x[:,0],x[:,1],c=y_pred,s=5,marker="o")plt.show()结果展示:
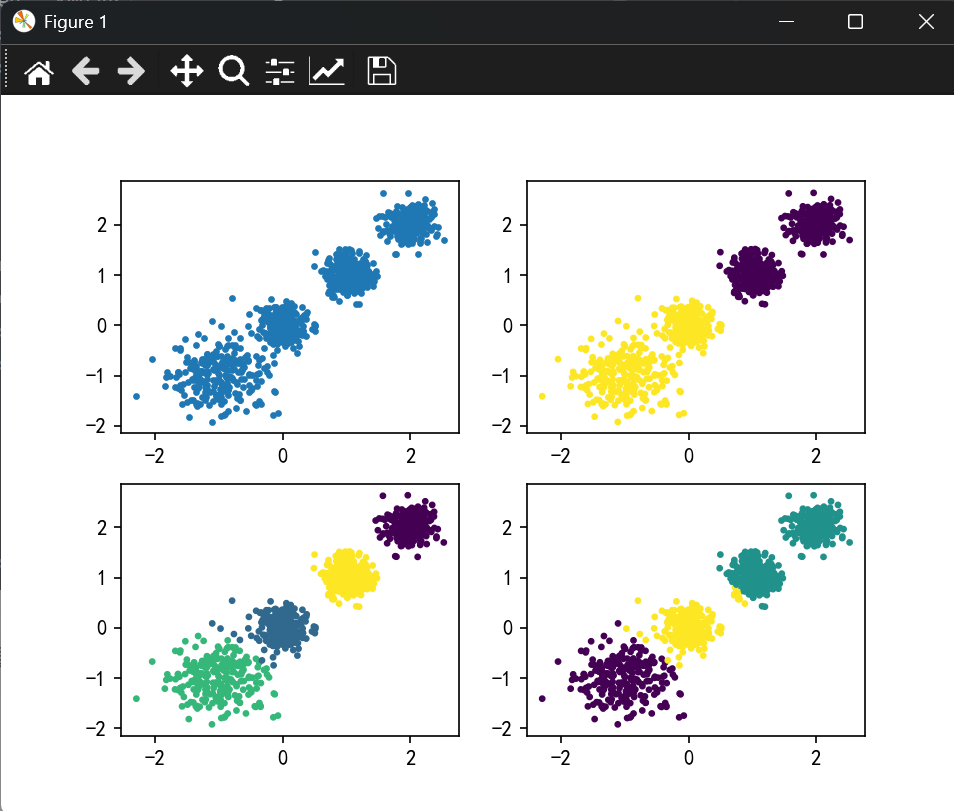
二、
K-means 练习题
数据集:
(2,10), (2,5), (8,4), (5,8), (7,5), (6,4), (1,2), (4,9)
- 使用K-means算法将上述点分为2个簇,初始中心点选择(2,10)和(5,8)
- 进行两次迭代并展示每次的簇分配和中心点更新
代码展示:
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import numpy as np
import os
os.environ["LOKY_MAX_CPU_COUNT"] = "8" # 设置为你想要使用的核心数plt.rcParams["font.sans-serif"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = Falsepoits = np.array([[2,10],[2,5],[8,4],[5,8],[7,5],[6,4],[1,2],[4,9]])centers = np.array([[2,10],[5,8]])kmeans_1 = KMeans(n_clusters=2,init=centers,n_init=1,max_iter=1)
kmeans_1.fit(poits)
centers_iter1 = kmeans_1.cluster_centers_plt.scatter(poits[:,0],poits[:,1],c=kmeans_1.labels_,cmap="viridis"
)# plt.scatter(
# centers[:,0],
# centers[:,1],
# c="red"
# )plt.scatter(centers_iter1[:,0],centers_iter1[:,1],c="orange"
)
plt.title("第一次迭代后")
plt.show()kmeans_2 = KMeans(n_clusters=2,init=centers_iter1,n_init=1,max_iter=1)
kmeans_2.fit(poits)
centers_iter2 = kmeans_2.cluster_centers_plt.scatter(poits[:,0],poits[:,1],c=kmeans_2.labels_,cmap="viridis"
)plt.scatter(centers_iter1[:,0],centers_iter1[:,1],c="orange"
)plt.scatter(centers_iter2[:,0],centers_iter2[:,1],c="green"
)print("第二次迭代后")
plt.show()结果展示:
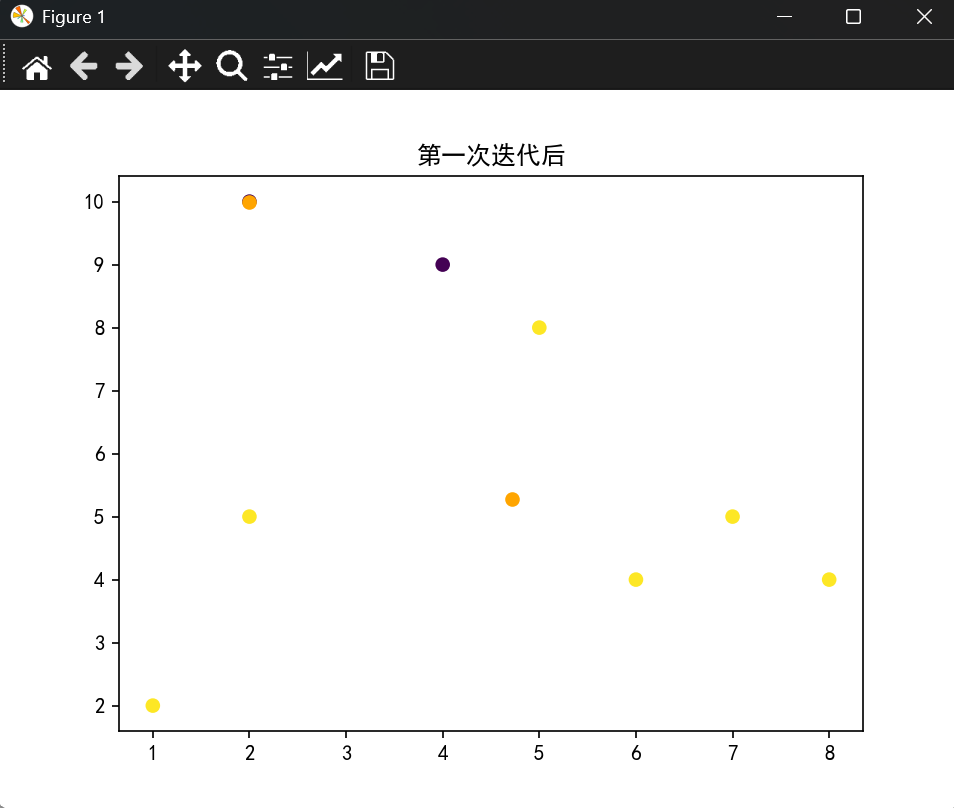
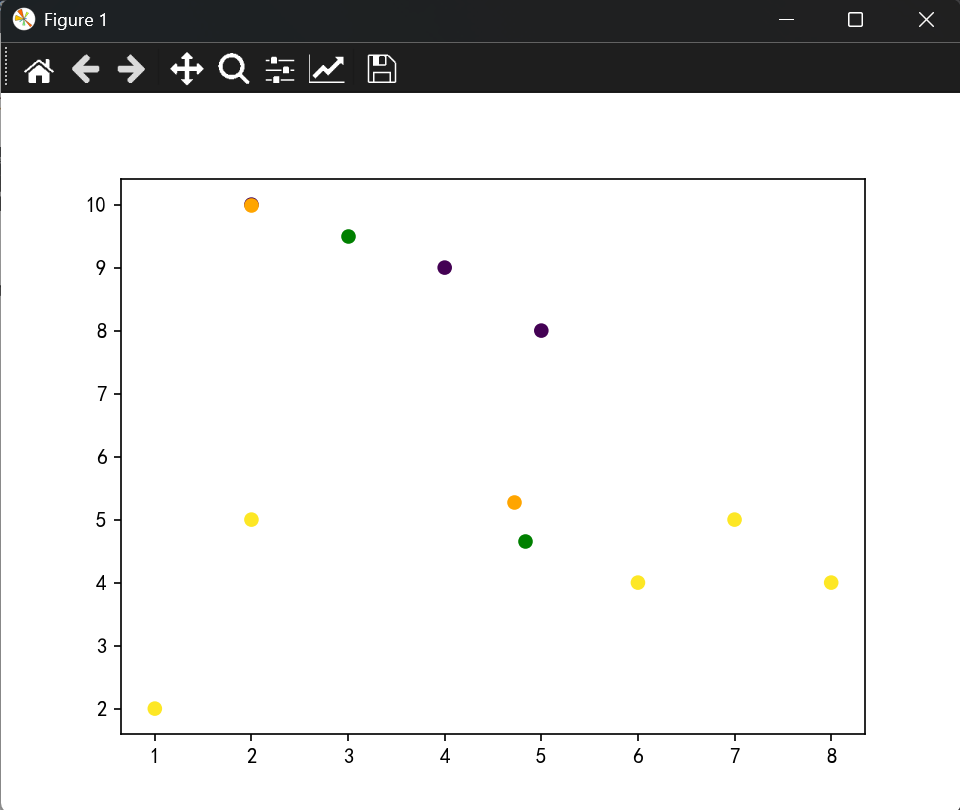
三、
项目背景
假设你是一家电子商务公司的数据分析师,公司希望根据客户的购买行为数据进行客户细分,以便制定更有针对性的营销策略。你需要使用K-means聚类算法对客户进行分组,并使用轮廓系数确定最佳K值。
数据集
我们将使用Kaggle上的"Customer Segmentation"数据集:
- 数据集链接: Mall Customer Segmentation Data | Kaggle
- 数据集包含客户ID、性别、年龄、年收入(千美元)和消费分数(1-100)
代码展示:
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs
from sklearn.metrics import silhouette_score
import osfrom sklearn.preprocessing import StandardScaleros.environ["LOKY_MAX_CPU_COUNT"] = "8" # 设置为你想要使用的核心数plt.rcParams["font.sans-serif"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = Falsedata = pd.read_csv("./data/Mall_Customers.csv",encoding="utf-8")
print(data.head())data['Gender'] = data['Gender'].map({'Male':0,'Female':1})X = data[["Annual Income (k$)","Spending Score (1-100)"]]# transform = StandardScaler()
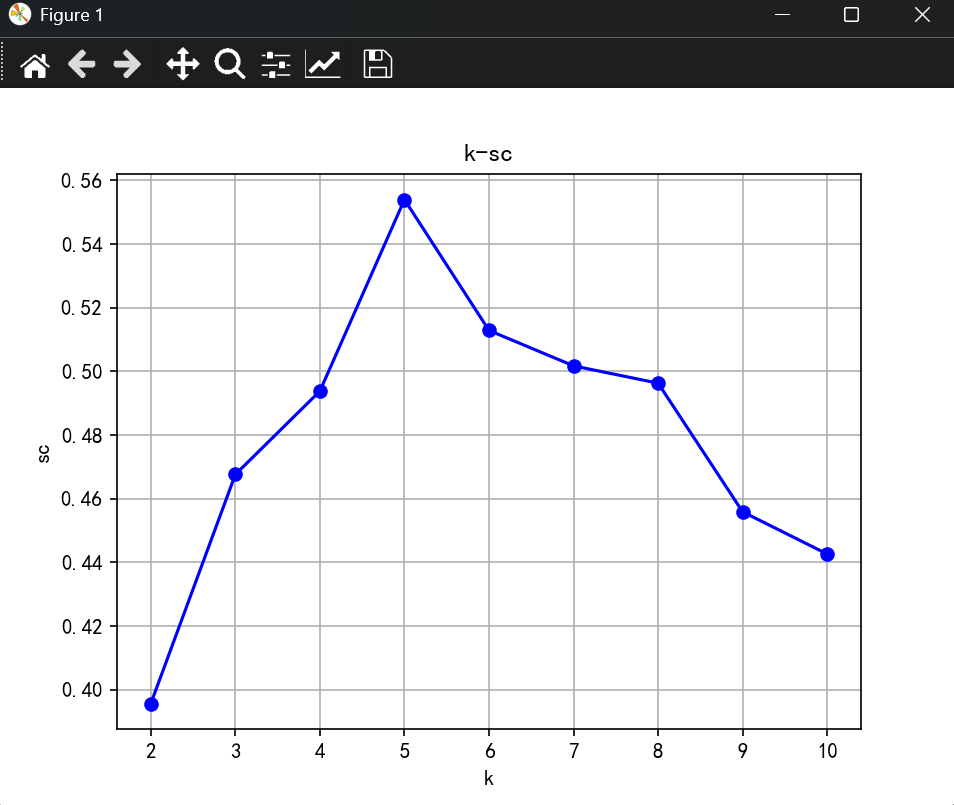
# X = transform.fit_transform(X)range_k = range(2,11)sc_list = []for i in range_k:kmeans = KMeans(n_clusters=i,random_state=42)pred = kmeans.fit_predict(X)sc = silhouette_score(X,pred)sc_list.append(sc)plt.plot(range_k,sc_list,"bo-")
plt.xlabel("k")
plt.ylabel("sc")
plt.title("k-sc")
plt.grid()
plt.show()kmeans = KMeans(n_clusters=5,random_state=42)
kmeans.fit(X)
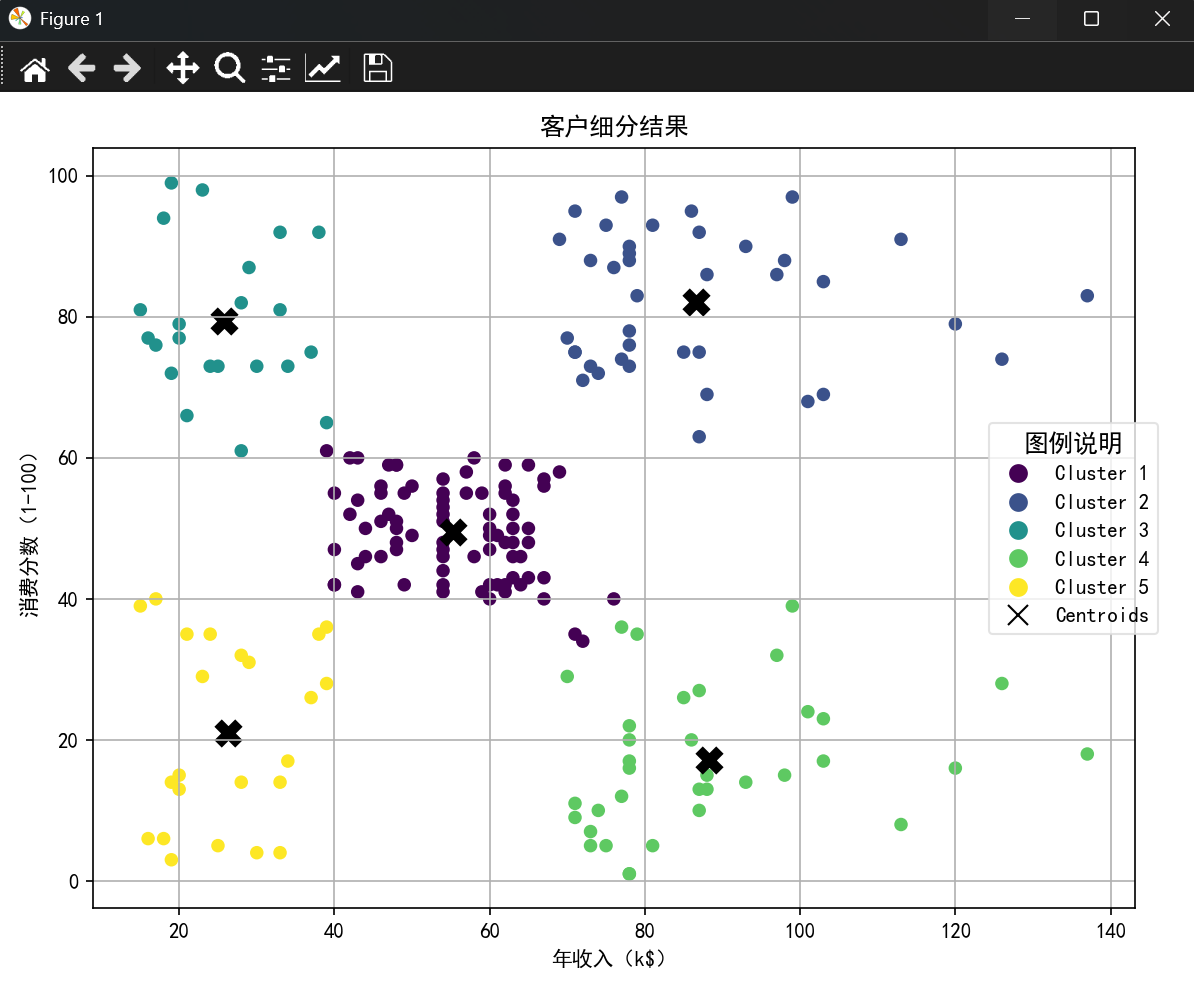
y_means = kmeans.predict(X)plt.figure(figsize=(8,6))scatter = plt.scatter(X.iloc[:,0],X.iloc[:,1],c=y_means,s=30,cmap="viridis"
)centers = kmeans.cluster_centers_center_scatter = plt.scatter(centers[:,0],centers[:,1],c="black",s=100,marker="x",linewidths=5,label="Centroids"
)# 创建自定义图例元素
legend_elements = [# 添加各簇颜色说明plt.Line2D([0], [0],marker='o',color='w',label=f'Cluster {i+1}',markerfacecolor=plt.cm.viridis(i/4), # 保持viridis颜色映射markersize=10)for i in range(5)
] + [# 添加中心点说明plt.Line2D([0], [0],marker='x',color='black',markersize=10,label='Centroids',linestyle='None')
]# 添加右侧图例
plt.legend(handles=legend_elements,title="图例说明",loc='center left',bbox_to_anchor=(0.85, 0.5), # 定位到画布右侧frameon=True,title_fontsize=12,fontsize=10,edgecolor='#DDDDDD'
)plt.xlabel("年收入(k$)")
plt.ylabel("消费分数(1-100)")
plt.title("客户细分结果")
plt.grid()
plt.tight_layout()
plt.show()
结果展示: