wordpress图片页面模板唐山网站建设方案优化
目录
一、使用sklearn转换器处理数据
(一)、加载datasets模块中的数据集
(二)、将数据集划分为训练集和测试集
编辑 train_test_spli
(三)、使用sklearn转换器进行数据预处理与降维
PCA
二、 构建并评价聚类模型
(一)、使用sklearn估计器构建聚类模型
(二)、使用sklearn转换器进行数据预处理与降维
TSNE类
(三)、评价聚类模型
一、使用sklearn转换器处理数据
(一)、加载datasets模块中的数据集
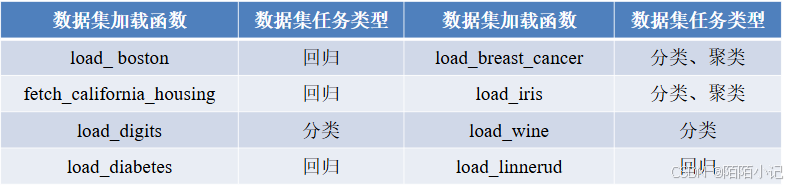
sklearn库的datasets模块集成了部分数据分析的经典数据集,读者可以使用这些数据集进行数据预处理、建 模等操作,以及熟悉sklearn的数据处理流程和建模流程。
datasets模块常用数据集的加载函数及其解释,如下表所示。
 使用sklearn进行数据预处理需要用到sklearn提供的统一接口——转换器(Transformer)。
使用sklearn进行数据预处理需要用到sklearn提供的统一接口——转换器(Transformer)。
如果需要加载某个数据集,那么可以将对应的函数赋值给某个变量。加载diabetes数据集,如以下代码


(二)、将数据集划分为训练集和测试集

 train_test_spli
train_test_spli
在sklearn的model_selection模块中提供了train_test_split函数,可实现对数据集进行拆分,train_test_split函数 的基本使用格式如下。
sklearn.model_selection.train_test_split(*arrays, test_size=None, train_size=None, random_state=None, shuffle=True, stratify=None)
train_test_split函数是最常用的数据划分方法,在model_selection模块中还提供了其他数据集划分的函数,如PredefinedSplit函数、ShuffleSplit函数等。读者可以通过查看官方文档学习其使用方法。
| 数值型数据类型 | 说明 |
| *arrays | 接收list、numpy数组、scipy-sparse矩阵、Pandas数据帧。表示需要划分的数据集。若为分类回归,则分别传入数据和标签;若为聚类,则传入数据。无默认值 |
| test_size | 接收float、int。表示测试集的大小。若传入为float型参数值,则应介于0~1之间,表示测试集在总数据集中的占比;若传入为int型参数值,则表示测试样本的绝对数量。默认为None |
| train_size | 接收float、int。表示训练集的大小,传入的参数值说明与test_size参数的参数值说明相似。默认为None |
| random_state | 接收int。表示用于随机抽样的伪随机数发生器的状态。默认为None |
| shuffle | 接收bool。表示在拆分数据集前是否对数据进行混洗。默认为True |
| stratify | 接收array。表示用于保持拆分前类的分布平衡。默认为None |
train_test_split函数可分别将传入的数据集划分为训练集和测试集。
如果传入的是一组数据集,那么生成的就是这一组数据集随机划分后的训练集和测试集,总共两组。
如果传入的是两组数据集,则生成的训练集和测试集分别两组,总共4组。
将breast_cancer数据集划分为训练集和测试集,如以下代码。

(三)、使用sklearn转换器进行数据预处理与降维
为了帮助用户实现大量的特征处理相关操作,sklearn将相关的功能封装为转换器。 转换器主要包括3个方法:fit()、transform()和fit_transform()。转换器的3种方法及其说明如下表所示。
| 方法名称 | 方法说明 |
| fit() | 主要通过分析特征和目标值提取有价值的信息,这些信息可以是统计量、权值系数等。fit() 方法用于从数据中学习参数,不进行实际的数据转换。 |
| transform() | 主要用于对特征进行转换。transform() 方法使用已经学习到的参数对数据进行转换,因此在调用 transform() 之前必须先调用 fit()。 |
| fit_transform() | 即先调用fit()方法,然后调用transform()方法 |

sklearn除了提供离差标准化函数MinMaxScaler外,还提供了一系列数据预处理函数,如下表所示。
| 函数名称 | 函数说明 |
| StandardScaler | 对特征进行标准差标准化 |
| Normalizer | 对特征进行归一化 |
| Binarizer | 对定量特征进行二值化处理 |
| OneHotEncoder | 对定性特征进行独热编码处理 |
| FunctionTransformer | 对特征进行自定义函数变换 |
PCA
sklearn除了提供基本的特征变换函数外,还提供了降维算法、特征选择算法,这些算法的使用也是通过转换器的方式进行的。
sklearn的decomposition模块中提供了PCA类,可实现对数据集进行PCA降维,PCA类的基本使用格式如下。
class sklearn.decomposition.PCA(n_components=None, *, copy=True, whiten=False, svd_solver='auto', tol=0.0, iterated_power='auto', random_state=None)
| 参数名称 | 参数说明 |
| n_components | 接收int、float、'mle'。表示降维后要保留的特征纬度数目。若未指定参数值,则表示所有特征均会被保留下来;若传入为int型参数值,则表示将原始数据降低到n个维度;若传入为float型参数值,则将根据样本特征方差来决定降维后的维度数;若赋值为“mle”,则将会使用MLE算法来根据特征的方差分布情况自动选择一定数量的主成分特征来降维。默认为None |
| copy | 接收bool。表示是否在运行算法时将原始训练数据进行复制。若为True,则运行算法后原始训练数据的值不会有任何改变;若为False,则运行算法后原始训练数据的值将会发生改变。默认为True |
| whiten | 接收bool。表示对降维后的特征进行标准化处理,使得具有相同的方差。默认为False |
| svd_solver | 接收str。表示使用的SVD算法,可选randomized、full、arpack、auto。randomized一般适用于数据量大,数据维度多,同时主成分数目比例又较低的PCA降维。full是使用SciPy库实现的传统SVD算法。arpack和randomized的适用场景类似,区别在于,randomized使用的是sklearn自己的SVD实现,而arpack直接使用了SciPy库的sparse SVD实现。auto则代表PCA类会自动在上述3种算法中去权衡,选择一个合适的SVD算法来降维。默认为auto |
二、 构建并评价聚类模型
(一)、使用sklearn估计器构建聚类模型
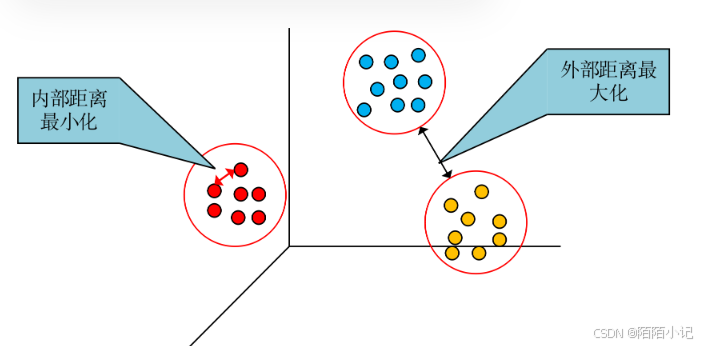
聚类的输入是一组未被标记的样本,聚类根据数据自身的距离或相似度将它们划分为若干组,划分的原则是组内(内部)距离最小化,而组间(外部)距离最大化,如图所示。
常用的聚类算法及其类别如下表所示。
| 算法类别 | 包括的主要算法 |
| 划分(分裂)方法 | K-Means算法(K-平均)、K-MEDOIDS算法(K-中心点)和CLARANS算法(基于选择的算法) |
| 层次分析方法 | BIRCH算法(平衡迭代规约和聚类)、CURE算法(代表点聚类)和CHAMELEON算法(动态模型) |
| 基于密度的方法 | DBSCAN算法(基于高密度连接区域)、DENCLUE算法(密度分布函数)和OPTICS算法(对象排序识别) |
| 基于网格的方法 | STING算法(统计信息网络)、CLIOUE算法(聚类高维空间)和WAVE-CLUSTER算法(小波变换) |
sklearn常用的聚类算法模块cluster提供的聚类算法及其适用范围如下表所示。
| 算法名称 | 参数 | 适用范围 | 距离度量 |
| K-Means | 簇数 | 可用于样本数目很大、聚类数目中等的场景 | 点之间的距离 |
| Spectral clustering | 簇数 | 可用于样本数目中等、聚类数目较小的场景 | 图距离 |
| Ward hierarchical clustering | 簇数 | 可用于样本数目较大、聚类数目较大的场景 | 点之间的距离 |
| Agglomerative clustering | 簇数、链接类型、距离 | 可用于样本数目较大、聚类数目较大的场景 | 任意成对点线图间的距离 |
聚类算法模块cluster提供的聚类算法及其适用范围续表。
| 算法名称 | 参数 | 适用范围 | 距离度量 |
| DBSCAN | 半径大小、最低成员数目 | 可用于样本数目很大、聚类数目中等的场景 | 最近的点之间的距离 |
| Birch | 分支因子、阈值、可选全局集群 | 可用于样本数目很大、聚类数目较大的场景 | 点之间的欧式距离 |
聚类算法实现需要使用sklearn估计器(estimator)。
sklearn估计器拥有fit()和predict()两个方法,其说明如下表所示。
| 方法名称 | 方法说明 |
| fit() | fit()方法主要用于训练算法。该方法可接收用于有监督学习的训练集及其标签两个参数,也可以接收用于无监督学习的数据 |
| predict() | predict()方法用于预测有监督学习的测试集标签,亦可以用于划分传入数据的类别 |
(二)、使用sklearn转换器进行数据预处理与降维
TSNE类
使用customer数据集,通过sklearn估计器构建K-Means聚类模型,对客户群体进行划分。
并使用sklearn的manifold模块中的TSNE类可实现多维数据的可视化展现功能,查看聚类效果,TSNE类的基本使用格式如下。
class sklearn.manifold.TSNE(n_components=2, *, perplexity=30.0, early_exaggeration=12.0, learning_rate=200.0, n_iter=1000, n_iter_without_progress=300, min_grad_norm=1e-07, metric='euclidean', init='random', verbose=0, random_state=None, method='barnes_hut', angle=0.5, n_jobs=None, square_distances='legacy')
import pandas as pd
from sklearn.manifold import TSNE
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt# 读取数据集
filepath = 'D:\Desktop\data\customer.csv'
customer = pd.read_csv(filepath, encoding='gbk')
customer_data = customer.iloc[:, :-1]
customer_target = customer.iloc[:, -1]
# Kmeans聚类
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=6,random_state=6).fit(customer_data)
# 使用TSNE进行数据降维,降成两维
tsne = TSNE(n_components=2, init='random',random_state=2).fit(customer_data)
df = pd.DataFrame(tsne.embedding_) # 将原始数据转
df['labels'] = kmeans.labels_ # 将聚类结果存储进df
# 提取不同标签的数据
df1 = df[df['labels'] == 0]
df2 = df[df['labels'] == 1]
df3 = df[df['labels'] == 2]
df4 = df[df['labels'] == 3]
df5 = df[df['labels'] == 4]
df6 = df[df['labels'] == 5]# 绘制图形
fig = plt.figure(figsize=(9, 6)) # 设定空白画布,为
# 用不同的颜色表示不同数据
plt.plot(df1[0], df1[1], 'bo', df2[0], df2[1], 'r*',df3[0], df3[1], 'gD', df4[0], df4[1], 'kD',df5[0], df5[1], 'ms', df6[0], df6[1], 'co' )
plt.show() # 显示图片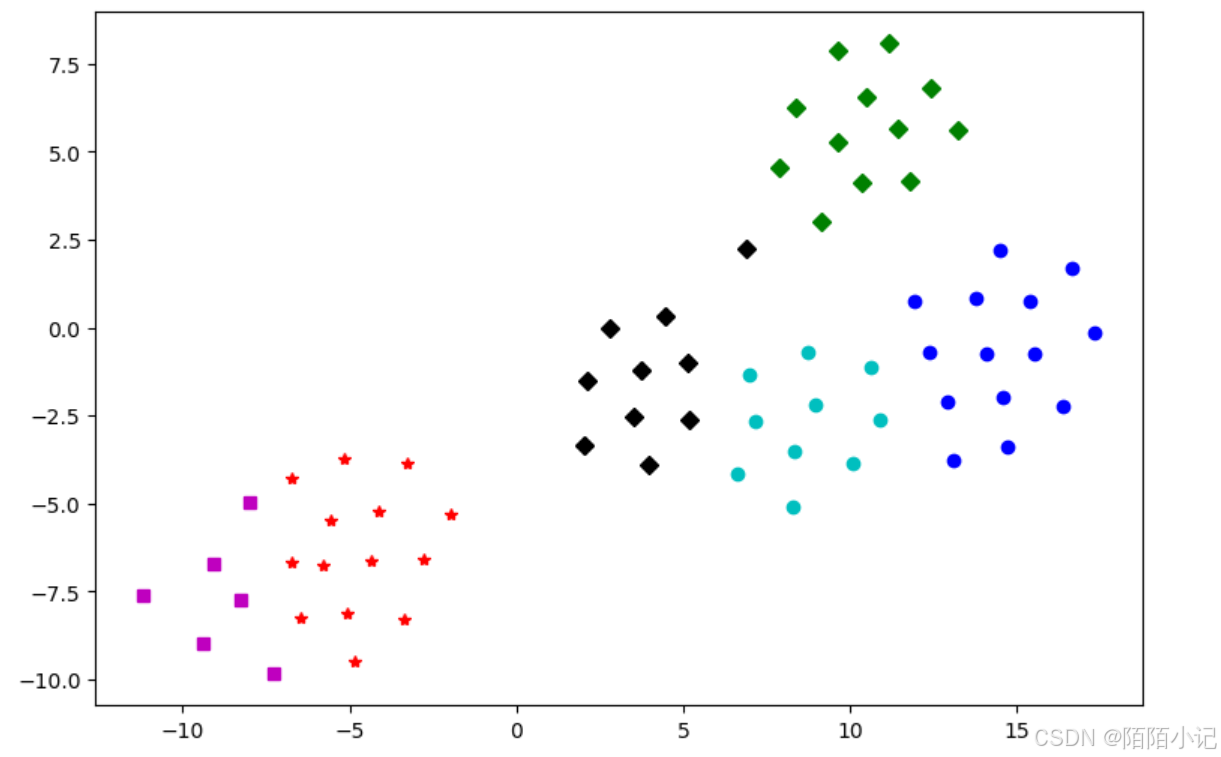
(三)、评价聚类模型
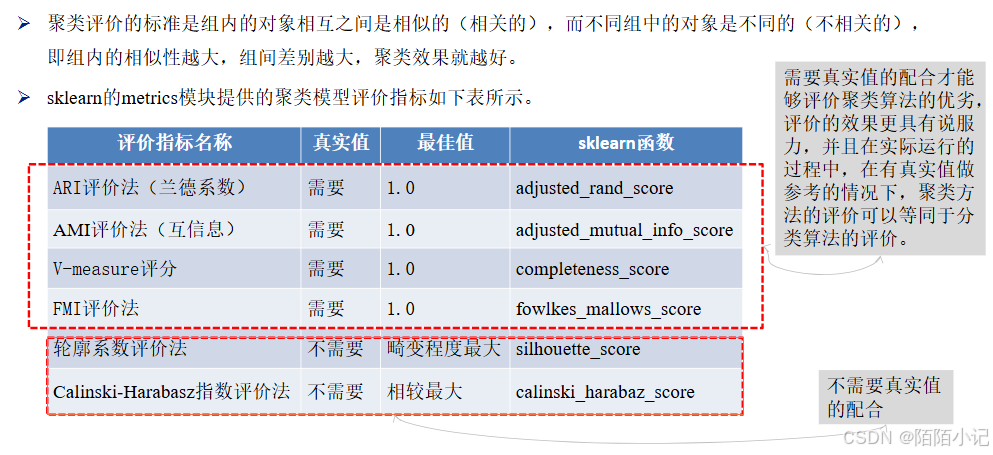
除了轮廓系数评价法以外的评价方法,在不考虑业务场景的情况下都是得分越高,其效果越好,最高分值为1。
而轮廓系数评价法则需要判断不同类别数目情况下的轮廓系数的走势,寻找最优的聚类数目。
综合以上聚类评价方法,在真实值作为参考的情况下,几种方法均可以很好地评估聚类模型。
在没有真实值作为参考的时候,轮廓系数评价法和Calinski-Harabasz指数评价法可以结合使用。
from sklearn.metrics import fowlkes_mallows_score
for i in range(1, 7):# 构建并训练模型kmeans = KMeans(n_clusters=i, random_state=6).fit(customer_data) score = fowlkes_mallows_score(customer_target, kmeans.labels_)print('customer数据聚%d类FMI评价分值为:%f' % (i, score))from sklearn.metrics import silhouette_score
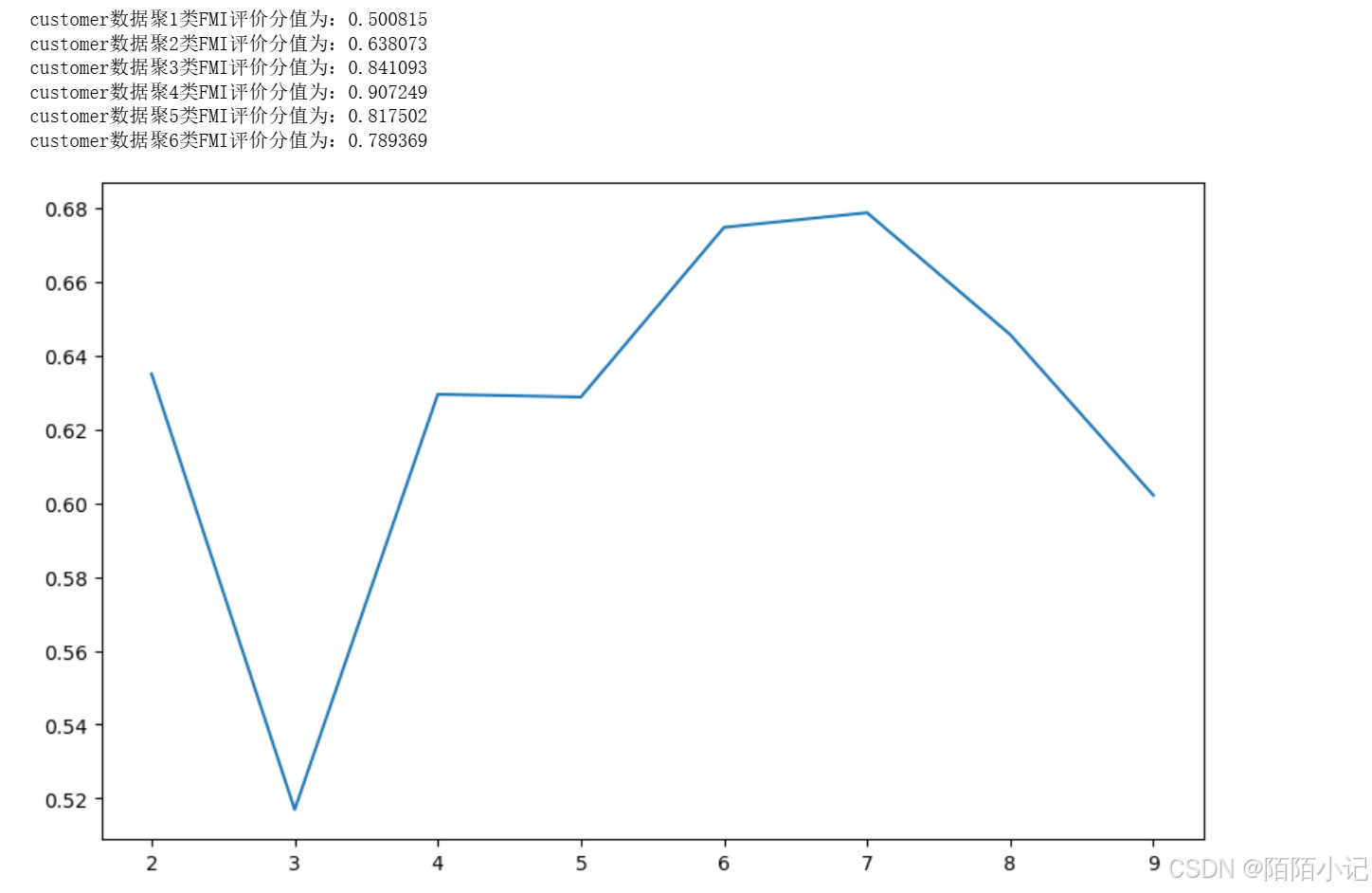
silhouettteScore = []
for i in range(2, 10):# 构建并训练模型kmeans = KMeans(n_clusters=i,random_state=6).fit(customer_data) score = silhouette_score(customer_data, kmeans.labels_)silhouettteScore.append(score)
plt.figure(figsize=(10, 6))
plt.plot(range(2, 10), silhouettteScore,
linewidth=1.5, linestyle='-')plt.show()