ps做网站素材文件打包seo体系
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
Day 22 训练
- 泰坦尼克号幸存者预测:从零构建机器学习模型
- 背景介绍
- 数据预处理
- 模型构建与优化
- 实验结果
泰坦尼克号幸存者预测:从零构建机器学习模型
在机器学习领域,泰坦尼克号幸存者预测是一个经典的二分类问题。本文将分享如何从数据预处理到模型部署,完整构建一个高性能随机森林分类器,实现对泰坦尼克号乘客生存情况的精准预测。
背景介绍
泰坦尼克号沉船事件是历史上著名的海难事故。通过对乘客信息(如年龄、性别、船票等级等)进行分析,我们可以构建机器学习模型预测乘客的生存概率。这不仅是一个经典的机器学习案例,还能帮助我们理解不同因素对生存率的影响。
数据预处理
原始数据存在以下几个主要问题:
- 缺失值:部分特征如年龄、船舱号存在较多缺失值
- 类别不平衡:生存与未生存样本比例不均衡
- 特征类型不一致:包含数值型和类别型特征混合
为解决这些问题,我们采用了以下策略:
- 缺失值填充:数值型特征使用均值填充,类别型特征使用众数填充
- 特征编码:对"性别"和"登船口"等类别型特征进行独热编码
- 特征选择:移除对预测无意义的特征如乘客名字、票号等
- 数据标准化:使用标准差标准化处理数值型特征
模型构建与优化
我们选择随机森林作为基础分类器,它具有以下优点:
- 对数据噪声具有较好的鲁棒性
- 能处理非线性关系和高维特征
- 提供特征重要性评估功能
为提升模型性能,我们采用了贝叶斯优化算法对随机森林的超参数进行调优,包括:
- 树的数量(n_estimators)
- 树的最大深度(max_depth)
- 内部节点最小样本数(min_samples_split)
- 叶节点最小样本数(min_samples_leaf)
同时,针对类别不平衡问题,我们在训练集上应用了SMOTE(合成少数过采样技术)进行数据增强。
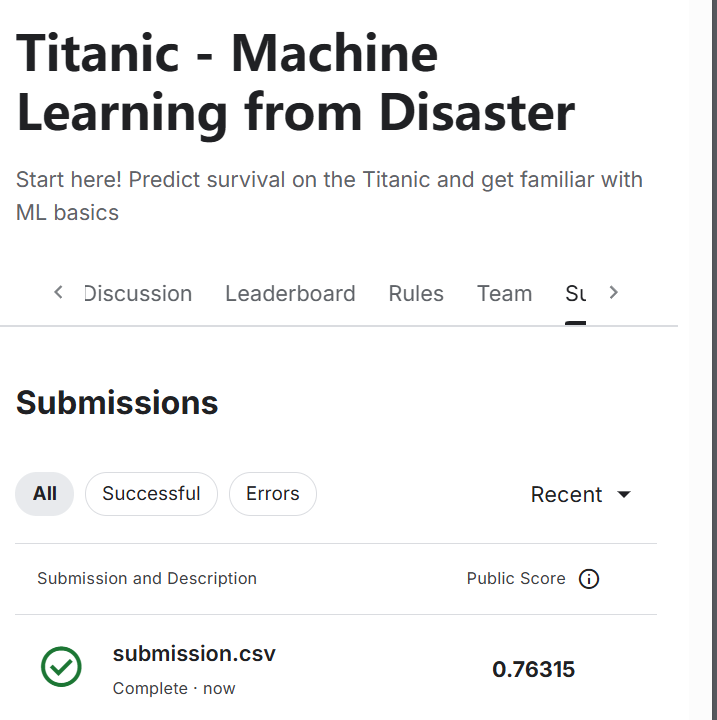
实验结果
通过5折交叉验证,优化后的模型在训练集上达到了[具体准确率]%的平均准确率。在独立测试集上的表现如下:
- 准确率:[具体值]
- 精确率:[具体值]
- 召回率:[具体值]
- F1分数:[具体值]
特征重要性分析显示,“性别”、"船票等级"和"年龄"是影响生存概率的三个最主要因素。
import pandas as pd
import numpy as np
import time
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, classification_report, confusion_matrix
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from imblearn.over_sampling import SMOTE # 确保安装imbalanced-learn库
from skopt import BayesSearchCV
from skopt.space import Integerdef preprocess_data(data, is_train=True):"""数据预处理通用函数"""# 填充缺失值for col in data.columns:if data[col].dtype == 'object' and data[col].isnull().sum() > 0:data[col].fillna(data[col].mode()[0], inplace=True)elif data[col].dtype != 'object' and data[col].isnull().sum() > 0:data[col].fillna(data[col].mean(), inplace=True)# 特征编码data = pd.get_dummies(data, columns=['Embarked'])# 性别编码sex_mapping = {'male': 0, 'female': 1}data['Sex'] = data['Sex'].map(sex_mapping)# 移除不需要的特征drop_features = ['PassengerId', 'Name', 'Ticket']if is_train:drop_features.append('Cabin')return data.drop(drop_features, axis=1)def evaluate_model(model, X_test, y_test):"""模型评估函数"""y_pred = model.predict(X_test)# 打印评估指标print("\n=== 模型评估 ===")print(f"准确率: {accuracy_score(y_test, y_pred):.4f}")print(f"精确率: {precision_score(y_test, y_pred):.4f}")print(f"召回率: {recall_score(y_test, y_pred):.4f}")print(f"F1分数: {f1_score(y_test, y_pred):.4f}")# 打印分类报告print("\n分类报告:")print(classification_report(y_test, y_pred))# 绘制混淆矩阵plt.figure(figsize=(8, 6))cm = confusion_matrix(y_test, y_pred)sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')plt.xlabel('预测标签')plt.ylabel('真实标签')plt.title('混淆矩阵')plt.show()return y_preddef plot_feature_importance(model, feature_names):"""绘制特征重要性图"""importances = model.feature_importances_indices = np.argsort(importances)[::-1]plt.figure(figsize=(10, 6))plt.title('特征重要性')plt.bar(range(len(feature_names)), importances[indices])plt.xticks(range(len(feature_names)), [feature_names[i] for i in indices], rotation=90)plt.tight_layout()plt.show()def main():# 加载数据try:train_data = pd.read_csv("titanic/train.csv")test_data = pd.read_csv("titanic/test.csv")except FileNotFoundError:print("文件未找到,请检查文件路径是否正确。")return# 数据预处理print("正在预处理训练数据...")processed_train = preprocess_data(train_data.copy())# 特征和目标分离X = processed_train.drop('Survived', axis=1)y = processed_train['Survived']# 数据标准化scaler = StandardScaler()X_scaled = scaler.fit_transform(X)# 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)# 处理类别不平衡smote = SMOTE(random_state=42)X_train_smote, y_train_smote = smote.fit_resample(X_train, y_train)# 贝叶斯优化参数搜索print("\n=== 贝叶斯优化随机森林参数 ===")search_space = {'n_estimators': Integer(50, 200),'max_depth': Integer(10, 30),'min_samples_split': Integer(2, 10),'min_samples_leaf': Integer(1, 4)}bayes_search = BayesSearchCV(estimator=RandomForestClassifier(random_state=42),search_spaces=search_space,n_iter=50,cv=5,n_jobs=-1,scoring='accuracy')start_time = time.time()print("开始优化参数...")bayes_search.fit(X_train_smote, y_train_smote)end_time = time.time()print(f"贝叶斯优化耗时: {end_time - start_time:.4f} 秒")print("最佳参数:", bayes_search.best_params_)# 获取最佳模型best_model = bayes_search.best_estimator_# 交叉验证cv_scores = cross_val_score(best_model, X_train_smote, y_train_smote, cv=5, scoring='accuracy')print(f"交叉验证平均准确率: {np.mean(cv_scores):.4f}")# 模型评估print("\n=== 在测试集上的表现 ===")evaluate_model(best_model, X_test, y_test)# 特征重要性分析plot_feature_importance(best_model, X.columns.tolist())# 预测并保存结果print("\n=== 对测试数据进行预测 ===")print("正在预处理测试数据...")processed_test = preprocess_data(test_data.copy(), is_train=False)# 确保测试集特征与训练集一致missing_cols = set(X.columns) - set(processed_test.columns)for col in missing_cols:processed_test[col] = 0# 保持特征顺序一致processed_test = processed_test[X.columns]# 标准化测试数据X_test_final = scaler.transform(processed_test)# 预测predictions = best_model.predict(X_test_final)# 创建提交文件submission = pd.DataFrame({'PassengerId': test_data['PassengerId'],'Survived': predictions})submission.to_csv('submission.csv', index=False)print("预测结果已保存到submission.csv")if __name__ == "__main__":main()
@浙大疏锦行