淘客网站如果做优化推广公司
- 🍨 本文为🔗365天深度学习训练营中的学习记录博客
- 🍖 原作者:K同学啊
Transformer通过自注意力机制,改变了序列建模的方式,成为AI领域的基础架构
编码器:理解输入,提取上下文特征。
解码器:基于编码特征,按顺序生成输出。
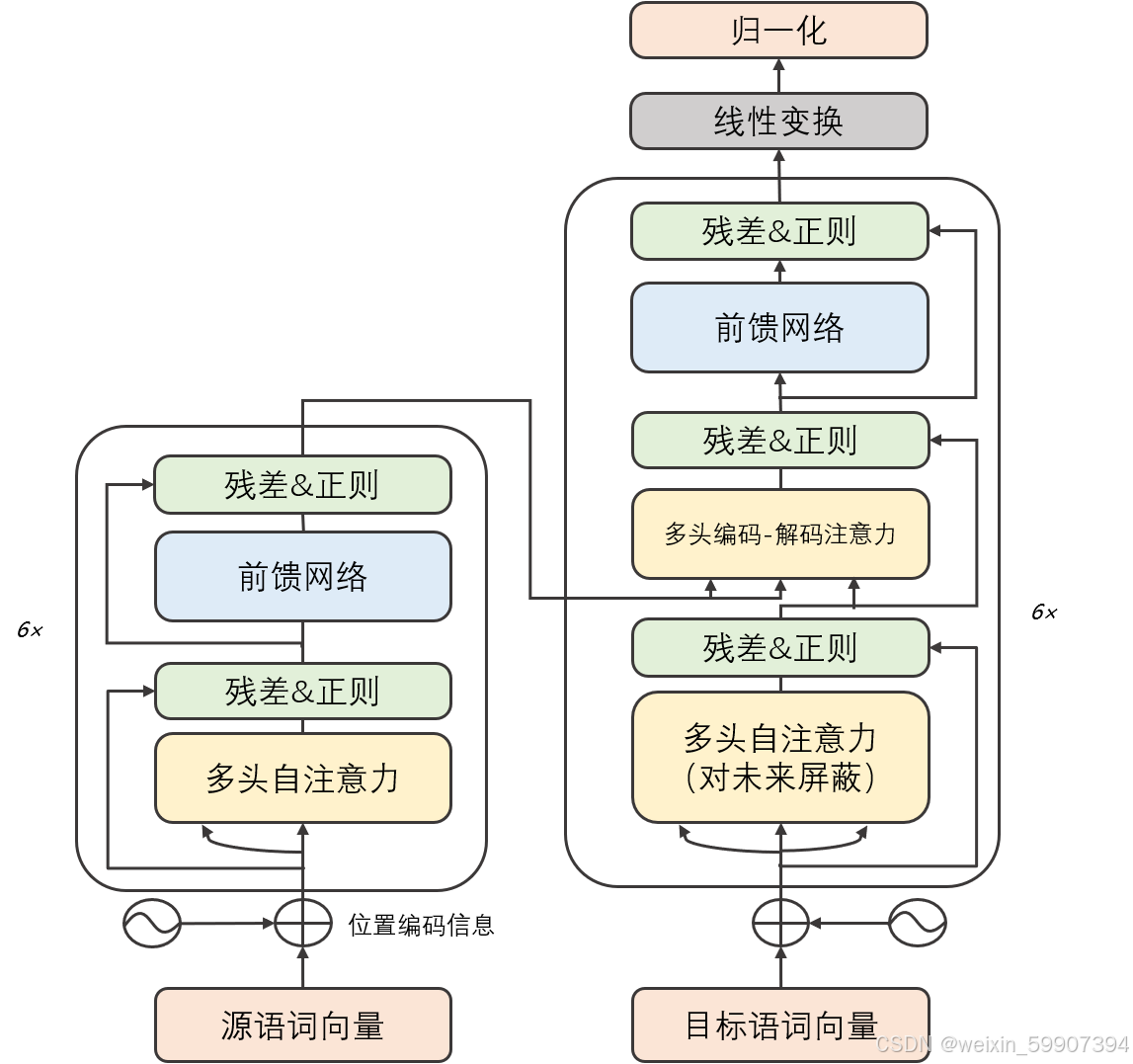
1.多头注意力机制
import math
import torch
import torch.nn as nndevice=torch.device('cuda' if torch.cuda.is_available() else 'cpu')class MultiHeadAttention(nn.Module):# n_heads:多头注意力的数量# hid_dim:每个词输出的向量维度def __init__(self,hid_dim,n_heads):super(MultiHeadAttention,self).__init__()self.hid_dim=hid_dimself.n_heads=n_heads#强制hid_dim必须整除 hassert hid_dim % n_heads == 0#定义W_q矩阵ceself.w_q=nn.Linear(hid_dim,hid_dim)#定义W_k矩阵self.w_k=nn.Linear(hid_dim,hid_dim)#定义W_v矩阵self.w_v=nn.Linear(hid_dim,hid_dim)self.fc =nn.Linear(hid_dim,hid_dim)#缩放self.scale=torch.sqrt(torch.FloatTensor([hid_dim//n_heads]))def forward(self,query,key,value,mask=None):#Q,K,V的在句子这长度这一个维度的数值可以不一样,可以一样#K:[64,10,300],假设batch_size为64,有10个词,每个词的Query向量是300维bsz=query.shape[0]Q =self.w_q(query)K =self.w_k(key)V =self.w_v(value)#这里把K Q V 矩阵拆分为多组注意力#最后一维就是是用self.hid_dim // self.n_heads 来得到的,表示每组注意力的向量长度,每个head的向量长度是:300/6=50#64表示batch size,6表示有6组注意力,10表示有10词,50表示每组注意力的词的向量长度#K: [64,10,300] 拆分多组注意力 -> [64,10,6,50] 转置得到 -> [64,6,10,50]#转置是为了把注意力的数量6放在前面,把10和50放在后面,方便下面计算Q=Q.view(bsz,-1,self.n_heads,self.hid_dim//self.n_heads).permute(0,2,1,3)K=K.view(bsz,-1,self.n_heads,self.hid_dim//self.n_heads).permute(0,2,1,3)V=V.view(bsz,-1,self.n_heads,self.hid_dim//self.n_heads).permute(0,2,1,3)#Q乘以K的转置,除以scale#[64,6,12,50]*[64,6,50,10]=[64,6,12,10]#attention:[64,6,12,10]attention=torch.matmul(Q,K.permute(0,1,3,2)) / self.scale#如果mask不为空,那么就把mask为0的位置的attention分数设置为-1e10,这里用‘0’来指示哪些位置的词向量不能被attention到,比如padding位置if mask is not None:attention=attention.masked_fill(mask==0,-1e10)#第二步:计算上一步结果的softmax,再经过dropout,得到attention#注意,这里是对最后一维做softmax,也就是在输入序列的维度做softmax#attention: [64,6,12,10]attention=torch.softmax(attention,dim=-1)#第三步,attention结果与V相乘,得到多头注意力的结果#[64,6,12,10] * [64,6,10,50] =[64,6,12,50]# x: [64,6,12,50]x=torch.matmul(attention,V)#因为query有12个词,所以把12放在前面,把50和6放在后面,方便下面拼接多组的结果#x: [64,6,12,50] 转置 -> [64,12,6,50]x=x.permute(0,2,1,3).contiguous()#这里的矩阵转换就是:把多头注意力的结果拼接起来#最后结果就是[64,12,300]# x:[64,12,6,50] -> [64,12,300]x=x.view(bsz,-1,self.n_heads*(self.hid_dim//self.n_heads))x=self.fc(x)return x
2.前馈传播
class Feedforward(nn.Module):def __init__(self,d_model,d_ff,dropout=0.1):super(Feedforward,self).__init__()#两层线性映射和激活函数self.linear1=nn.Linear(d_model,d_ff)self.dropout=nn.Dropout(dropout)self.linear2=nn.Linear(d_ff,d_model)def forward(self,x):x=torch.nn.functional.relu(self.linear1(x))x=self.dropout(x)x=self.linear2(x)return x
3.位置编码
class PositionalEncoding(nn.Module):"实现位置编码"def __init__(self, d_model, dropout=0.1, max_len=5000):super(PositionalEncoding, self).__init__()self.dropout = nn.Dropout(p=dropout)# 初始化Shape为(max_len, d_model)的PE (positional encoding)pe = torch.zeros(max_len, d_model).to(device)# 初始化一个tensor [[0, 1, 2, 3, ...]]position = torch.arange(0, max_len).unsqueeze(1)# 这里就是sin和cos括号中的内容,通过e和ln进行了变换div_term = torch.exp(torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model))pe[:, 0::2] = torch.sin(position * div_term) # 计算PE(pos, 2i)pe[:, 1::2] = torch.cos(position * div_term) # 计算PE(pos, 2i+1)pe = pe.unsqueeze(0) # 为了方便计算,在最外面在unsqueeze出一个batch# 如果一个参数不参与梯度下降,但又希望保存model的时候将其保存下来# 这个时候就可以用register_bufferself.register_buffer("pe", pe)def forward(self, x):"""x 为embedding后的inputs,例如(1,7, 128),batch size为1,7个单词,单词维度为128"""# 将x和positional encoding相加。x = x + self.pe[:, :x.size(1)].requires_grad_(False)return self.dropout(x)
4.编码层
class EncoderLayer(nn.Module):def __init__(self,d_model,n_heads,d_ff,dropout=0.1):super(EncoderLayer,self).__init__()#编码器层包含自注意机制和前馈神经网络self.self_attn=MultiHeadAttention(d_model,n_heads)self.feedforward=Feedforward(d_model,d_ff,dropout)self.norm1=nn.LayerNorm(d_model)self.norm2=nn.LayerNorm(d_model)self.dropout=nn.Dropout(dropout)def forward(self,x,mask):#自注意力机制atten_output=self.self_attn(x,x,x,mask)x=x+self.dropout(atten_output)x=self.norm1(x)#前馈神经网络ff_output=self.feedforward(x)x=x+self.dropout(ff_output)x=self.norm2(x)return x
5.解码层
class DecoderLayer(nn.Module):def __init__(self, d_model, n_heads, d_ff, dropout=0.1):super(DecoderLayer, self).__init__()# 解码器层包含自注意力机制、编码器-解码器注意力机制和前馈神经网络self.self_attn = MultiHeadAttention(d_model, n_heads)self.enc_attn = MultiHeadAttention(d_model, n_heads)self.feedforward = Feedforward(d_model, d_ff, dropout)self.norm1 = nn.LayerNorm(d_model)self.norm2 = nn.LayerNorm(d_model)self.norm3 = nn.LayerNorm(d_model)self.dropout = nn.Dropout(dropout)def forward(self, x, enc_output, self_mask, context_mask):# 自注意力机制attn_output = self.self_attn(x, x, x, self_mask)x = x + self.dropout(attn_output)x = self.norm1(x)# 编码器-解码器注意力机制attn_output = self.enc_attn(x, enc_output, enc_output, context_mask)x = x + self.dropout(attn_output)x = self.norm2(x)# 前馈神经网络ff_output = self.feedforward(x)x = x + self.dropout(ff_output)x = self.norm3(x)return x
6.Transformer模型构建
class Transformer(nn.Module):def __init__(self, vocab_size, d_model, n_heads, n_encoder_layers, n_decoder_layers, d_ff, dropout=0.1):super(Transformer, self).__init__()# Transformer 模型包含词嵌入、位置编码、编码器和解码器self.embedding = nn.Embedding(vocab_size, d_model)self.positional_encoding = PositionalEncoding(d_model)self.encoder_layers = nn.ModuleList([EncoderLayer(d_model, n_heads, d_ff, dropout) for _ in range(n_encoder_layers)])self.decoder_layers = nn.ModuleList([DecoderLayer(d_model, n_heads, d_ff, dropout) for _ in range(n_decoder_layers)])self.fc_out = nn.Linear(d_model, vocab_size)self.dropout = nn.Dropout(dropout)def forward(self, src, trg, src_mask, trg_mask):# 词嵌入和位置编码src = self.embedding(src)src = self.positional_encoding(src)trg = self.embedding(trg)trg = self.positional_encoding(trg)# 编码器for layer in self.encoder_layers:src = layer(src, src_mask)# 解码器for layer in self.decoder_layers:trg = layer(trg, src, trg_mask, src_mask)# 输出层output = self.fc_out(trg)return output
vocab_size = 10000
d_model = 128
n_heads = 8
n_encoder_layers = 6
n_decoder_layers = 6
d_ff = 2048
dropout = 0.1device = torch.device('cpu')transformer_model = Transformer(vocab_size, d_model, n_heads, n_encoder_layers, n_decoder_layers, d_ff, dropout)# 定义输入
src = torch.randint(0, vocab_size, (32, 10)) # 源语言句子
trg = torch.randint(0, vocab_size, (32, 20)) # 目标语言句子
src_mask = (src != 0).unsqueeze(1).unsqueeze(2) # 掩码,用于屏蔽填充的位置
trg_mask = (trg != 0).unsqueeze(1).unsqueeze(2) # 掩码,用于屏蔽填充的位置# 模型前向传播
output = transformer_model(src, trg, src_mask, trg_mask)
print(output.shape)
![]()