黄骅贴吧招聘2022年seo优化是啥
文章目录
- 一、测试环境
- 1.conda
- 2.其他环境
- 二、获取embedding
- 三、构建faiss索引库
- 四、检索
- website ref
本次测试目标为跑通基于embedding的语义相似度检索的基本流程,测试流程主要分为:
=> 1)通过预训练模型生成embedding
=> 2)保存embedding到文件
=> 3)基于embedding文件构建faiss索引并持久化保存
=> 4)加载faiss索引进行语义相似度检索
一、测试环境
1.conda
conda create --name faiss_cpu python=3.11创建3.11版本的python虚拟环境,默认conda会安装该大版本下最新的小版本,当前是Python 3.11.11。
2.其他环境
conda activate faiss_cpu进入该环境:
1)pip install -U sentence-transformers(doc、github)
2)conda install -c pytorch faiss-cpu(doc、github)
2的安装过程中可能会出现

yes替换。
二、获取embedding
在https://huggingface.co/models?library=sentence-transformers&sort=likes选择合适的预训练模型,无法连接外网的话可以通过镜像网站https://hf-mirror.com/models?pipeline_tag=sentence-similarity&sort=likes选择。
本次选择的是

import os
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com" # 镜像配置
import numpy as np
from sentence_transformers import SentenceTransformer# 下载模型到指定目录,后续已有不会再重复下载
model = SentenceTransformer("sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2",cache_folder='/mnt/workspace/model')tags_list = ['河南人爱喝的胡辣汤', '亲子好去处', '适合户外', '24小时营业', '春日赏花好去处', '免费停车', '深夜食堂', '男士爱吃', '晚上人气旺', '回头率高'
]
embeddings = model.encode(tags_list, batch_size=5, show_progress_bar=True)# L2归一化
embeddings = embeddings / np.linalg.norm(embeddings, axis=1, keepdims=True)
print(embeddings)
print(embeddings.shape)# 保存embedding到文件
with open('../data/embedding.emb', 'w', encoding='utf-8') as fin:for tag, vec in zip(tags_list, embeddings):vec_str = ",".join([f"{x:.10f}" for x in vec]) fin.write(f"{tag}\t{vec_str}\n")
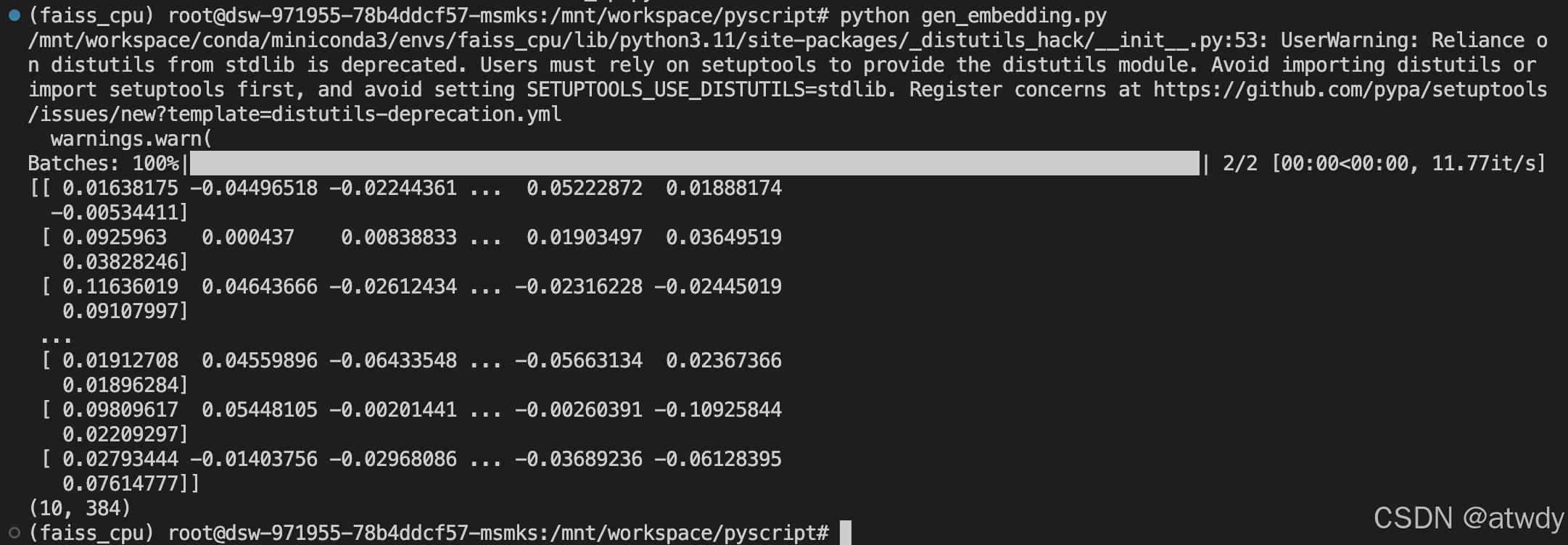
结果文件,10个384维的向量:
三、构建faiss索引库
import numpy as np
import faiss# 读取embedding文件
tags, embeddings = [], []
with open('../data/embedding.emb', 'r', encoding='utf-8') as f:for line in f:tag, vec_str = line.strip().split('\t') vec = np.fromstring(vec_str, sep=',', dtype=np.float32)tags.append(tag)embeddings.append(vec)
embeddings = np.array(embeddings)# 构建索引
dim = embeddings.shape[1]
index = faiss.IndexFlatIP(dim) # 内积索引(暴力搜索),数据量大可使用ANN
index.add(embeddings) # 添加数据
faiss.write_index(index, "../data/index.faiss") # 保存索引# 保存标签映射文件
with open('../data/tag_mapping.txt', 'w', encoding='utf-8') as f:f.write('\n'.join(tags))
执行完在指定目录下会生成faiss索引文件和tags映射文件:

四、检索
import faiss
import os
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"
from sentence_transformers import SentenceTransformer# 使用相同的模型生成待检索标签的embedding
model = SentenceTransformer("sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2",cache_folder='/mnt/workspace/model')query_text = "附近美食"
query_embedding = model.encode([query_text], show_progress_bar=False)[0]# L2归一化(必须与索引构建时的归一化方式一致)
faiss.normalize_L2(query_embedding.reshape(1, -1))# 加载faiss索引
index = faiss.read_index("../data/index.faiss")# 加载标签映射
with open('../data/tag_mapping.txt', 'r', encoding='utf-8') as f:tags = [line.strip() for line in f]# 进行语义匹配,搜索语义最近的三个标签
distances, indices = index.search(query_embedding.reshape(1, -1), k=3)print(f"与【{query_text}】最相似的3个标签:")
for rank, (idx, score) in enumerate(zip(indices[0], distances[0]), 1):print(f"第{rank}名:{tags[idx]} (相似度:{score:.4f})")

从结果来看前两名比较符合美食类的语义范畴,第3名“适合户外”不太搭边,可以对下载的模型微调优化embedding的生成质量以及设置合适的相似度阈值。
website ref
https://www.sbert.net/index.html
https://github.com/facebookresearch/faiss/wiki
https://huggingface.co/models?library=sentence-transformers
https://hf-mirror.com/(国内镜像)