今傲网站做的怎么样自己怎么制作一个网站

Stable Diffusion从理论到实践——保姆级教程博客收到大家的一致好评,今天又来更新了。
一. 理论部分
论文:https://arxiv.org/pdf/2302.05543
代码:https://github.com/lllyasviel/ControlNet
1. 概述
传统的文本到图像模型往往在精确表达复杂布局、姿势、形状和形态方面受限,特别是当这些要求必须通过简单的文本提示来传达时。为了解决这一挑战,提出了一种名为ControlNet的神经网络结构,它旨在为大型预训练文本到图像扩散模型提供条件控制。ControlNet通过将额外的条件融入现有的神经网络结构中,赋予了模型处理更为复杂和多样化任务的能力。它利用零卷积层连接技术,巧妙地结合了可训练的副本和原始模型,有效地消除了训练过程中可能产生的有害噪声。
contorlnet的主要贡献如下:
• “零卷积”连接: 该架构通过“零卷积”(零初始化的卷积层)连接,这些卷积层逐渐从零增长参数,以确保微调过程中不受有害噪声影响。
• 条件控制的测试: 测试了各种条件控制,例如边缘、深度、分割、人体姿势等,与Stable Diffusion结合使用,可以应用单个或多个条件,有或无提示。展示了ControlNet在小型(小于50k)和大型(超过1m)数据集上的训练具有强大的鲁棒性。
• 广泛应用可能性: 广泛的实验结果表明,ControlNet可能促进控制图像扩散模型的更广泛应用。

图一:如上图所示:ControlNet 允许用户添加条件(如上图中的 Canny 边缘图,下图中的 人体姿态 等),从而控制大规模预训练扩散模型的图像生成过程。默认情况下,使用的文本提示为:“一张高质量、细致且专业的图像”。用户也可以选择输入自定义提示词,例如:“厨房里的厨师”。
2. 解决的问题,使扩散模型的大规模应用成为可能
视觉灵感与图像控制的限制: 许多人都经历过想要以独特图像捕捉视觉灵感的时刻。随着文本到图像扩散模型的出现,现在可以通过输入文本提示来创造视觉上令人惊叹的图像。然而,文本到图像模型在控制图像的空间构成上受到限制;通过文本提示单独精确表达复杂布局、姿势、形状和形态可能是困难的。
提高图像生成的空间控制: 是否能够通过让用户提供额外的图像来直接指定其所需的图像组合来实现更精细的空间控制?在计算机视觉和机器学习领域,这些额外的图像(例如边缘图、人体姿势骨架、分割图、深度、法线等)通常被视为图像生成过程的条件。图像到图像的转换模型学习从条件图像到目标图像的映射。
实验与验证: 实验显示ControlNet可以使用各种条件输入控制Stable Diffusion,包括Canny边缘、霍夫线、用户涂鸦、人体关键点、分割图、形状法线、深度等。探索了使用单个条件图像、有无文本提示的方法,并展示了如何支持多条件组合的应用。报告表明,ControlNet的训练在不同大小的数据集上稳健可扩展。
3. 技术实现
ControlNet是一种神经网络架构,能够增强大型预训练的文本到图像扩散模型,使其具备空间定位的、特定任务的图像条件。
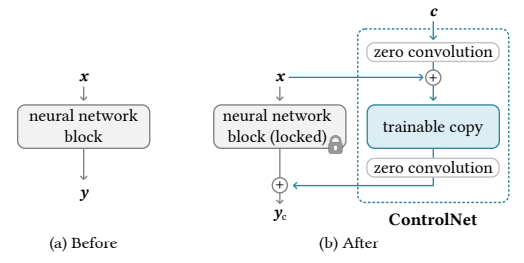
图二:神经块将特征图 x 作为输入,并输出另一个特征图 y,如图 (a) 所示。要向这样的块添加 ControlNet,锁定原始块并创建一个可训练的副本,然后使用零卷积层将它们连接在一起,即使用权重和偏差都初始化为零的 1 × 1 卷积。这里的 c 是希望添加到网络中的条件向量,如图 (b) 所示。
注入额外条件: ControlNet将额外的条件注入到神经网络的各个模块中(参见图三)。这里的网络模块指的是组合成神经网络单元的一组神经层,如resnet块、conv-bn-relu块、多头注意力块、变压器块等。
零卷积连接: 可训练副本通过零卷积层与锁定模型连接 ,具体来说,使用一个 1 × 1 卷积层,其权重和偏置初始化为零。

图三:稳定扩散的U-net架构与一个连接在编码器块和中间块上的ControlNet。锁定的灰色块显示稳定扩散V1.5(或V2.1,因为它们使用相同的U-net架构)的结构。可训练的蓝色块和白色的零卷积层被添加以构建一个ControlNet。
实现ControlNet及条件测试: 实现了ControlNet与Stable Diffusion的结合,测试了包括Canny边缘、深度图、法线图、M-LSD线、HED软边缘、ADE20K分割、Openpose和用户素描等各种条件。

图四:使用各种条件控制稳定扩散而无需提示。顶部一行是输入条件,而所有其他行都是输出。我们使用空字符串作为输入提示。所有模型都是使用通用领域数据进行训练的。模型必须识别输入条件图像中的语义内容以生成图像。
ControlNet模型是让AI绘画领域无比繁荣的关键一环,它让AI绘画的生成过程更加的可控,更有助于广泛地将AI绘画应用到各行各业中,为AI绘画的商业落地奠定坚实的基础。
二. 实践部分
前置条件,下载SD3模型并验证:Stable Diffusion从理论到实践——保姆级教程
1. 数据集准备
controlNet系列模型的训练流程主要分成以下几个步骤:
• 设计我们想要的生成条件:我们根据实际需求自定义一些条件,从而使用ControlNet控制Stable Diffusion朝着我们想要的方向生成内容。
• 构建数据集:确定好生成条件后,我们就可以开始构建数据集了。ControlNet数据集中需要包含三个维度的信息:Ground Truth图片、作为条件(Conditional)的图片,以及Prompt标签。
• 训练我们自己的ControlNet模型:数据集构建好后,我们就可以开始训练自己的ControlNet模型了。
由于训练模型需要大量的数据,因此必须能用算法获得大量的数据对,需要构建的数据主要包括三个方面:
• 构建ground truth 图片 (image):这里指的就是真实图片;
• 构建条件图片 (conditioning_image):对应的条件图像(用算法处理真实图片获得);
• 构建图片标签 (caption):描述图片的文字(用算法获得);
这里我们用开源的数据集fill50k,下载地址:https://huggingface.co/datasets/fusing/fill50k,数据集如下,包含image,conditioning_image, text(描述图片的文字):
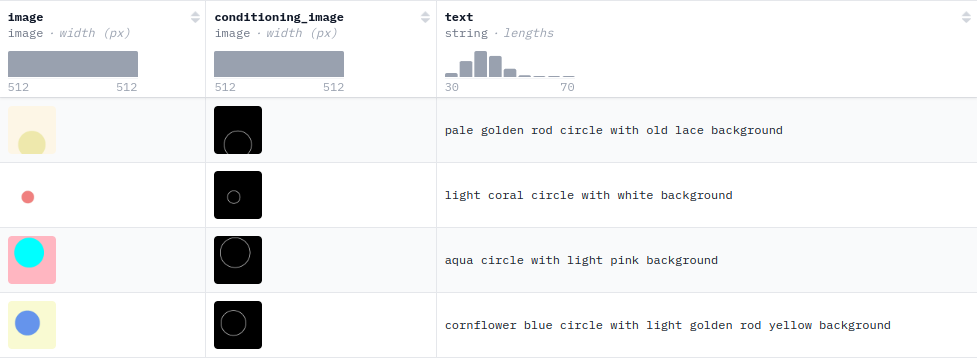 训练数据的组织如下图所示:
训练数据的组织如下图所示:

2. 模型训练
代码与训练环境准备
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install -e .pip install -r requirements_sd3.txtaccelerate config
将下载的数据fill50k放在examples/controlnet目录下
下载两张条件图片,用作训练过程中的验证
wget https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/controlnet_training/conditioning_image_1.png
wget https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/controlnet_training/conditioning_image_2.png
开始训练模型
# 路径最好都写绝对路径,关注微信公众号:AIWorkshopLab
export MODEL_DIR="stabilityai/stable-diffusion-3-medium-diffusers"
export OUTPUT_DIR="sd3-controlnet-out"accelerate launch train_controlnet_sd3.py \--pretrained_model_name_or_path=$MODEL_DIR \--output_dir=$OUTPUT_DIR \--train_data_dir="fill50k" \--resolution=1024 \--learning_rate=1e-5 \--max_train_steps=15000 \--validation_image "./conditioning_image_1.png" "./conditioning_image_2.png" \--validation_prompt "red circle with blue background" "cyan circle with brown floral background" \--validation_steps=100 \--train_batch_size=1 \--gradient_accumulation_steps=4
3. 模型推理
# 路径最好都写绝对路径,关注微信公众号:AIWorkshopLab
from diffusers import StableDiffusion3ControlNetPipeline, SD3ControlNetModel
from diffusers.utils import load_image
import torchbase_model_path = "./stabilityai/stable-diffusion-3-medium-diffusers"
controlnet_path = "AIWorkshopLab/sd3-controlnet-out/checkpoint-15000/controlnet"controlnet = SD3ControlNetModel.from_pretrained(controlnet_path, torch_dtype=torch.float16)
pipe = StableDiffusion3ControlNetPipeline.from_pretrained(base_model_path, controlnet=controlnet
)
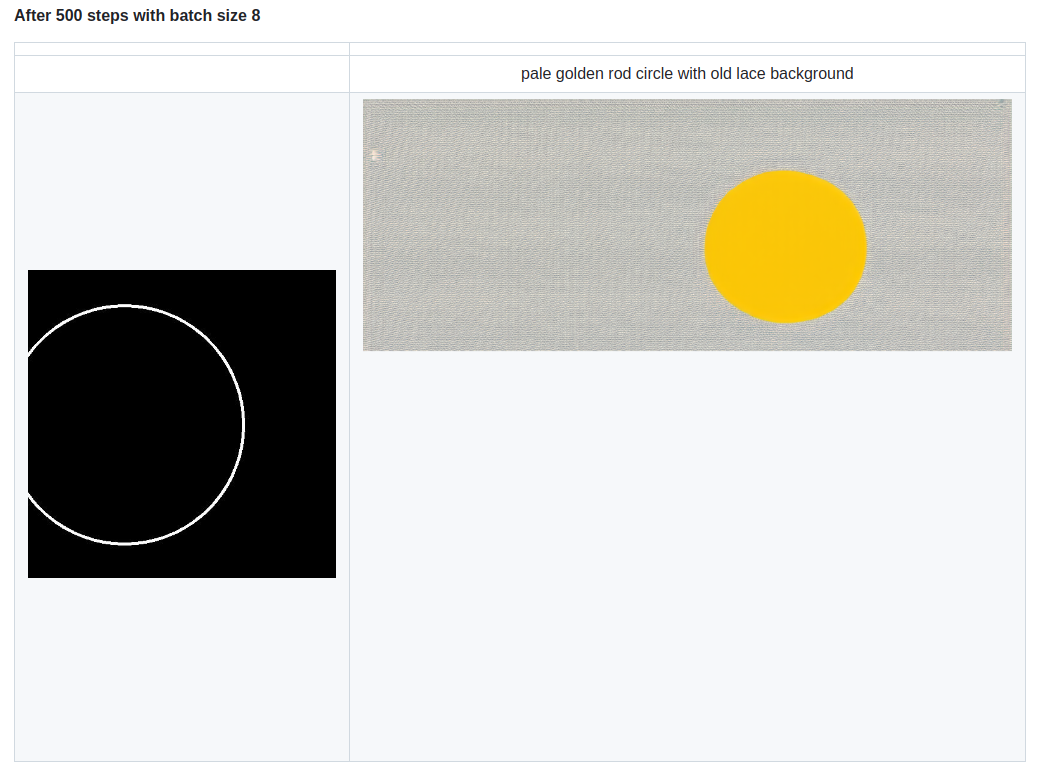
pipe.to("cuda", torch.float16)control_image = load_image("./conditioning_image_1.png").resize((1024, 1024))
prompt = "pale golden rod circle with old lace background"# generate image
generator = torch.manual_seed(0)
image = pipe(prompt, num_inference_steps=20, generator=generator, control_image=control_image
).images[0]
image.save("./AIWorkshopLab.png")
生成效果:
推荐阅读:Stable Diffusion从理论到实践——保姆级教程
参考:https://github.com/huggingface/diffusers/blob/main/examples/controlnet/README_sd3.md