计算机入门基础知识seo整站优化方案案例
生活应该是美好而温柔的,你也是
—— 25.4.1
一、模态 modalities
常见: 文本、图像、音频、视频、表格数据等
罕见: 3D模型、图数据、气味、神经信号等
二、多模态
1、Input and output are of different modalities (eg: text-to-image, image-to-text)
输入和输出具有不同的模态(例如文本到图像、图像到文本)
2、Inputs are multimodal (eg:a system that can process both text and images)
输入同时是多模态的(例如可以处理文本和图像的系统)
3、Outputs are multimodal (eg: a system that can generate both text and images)
输出是多模式的(例如可以生成文本和图像的系统)
三、为什么需要多模态
1.许多现实任务是天然的多模态任务
2.加入不同模态有助于模型提升表现(加强模型对世界的理解)
3.更加灵活的使用方式和广阔的应用场景

四、GPT-4V
接收图像 + 提示词,给出一些回答

五、多模态模型要点
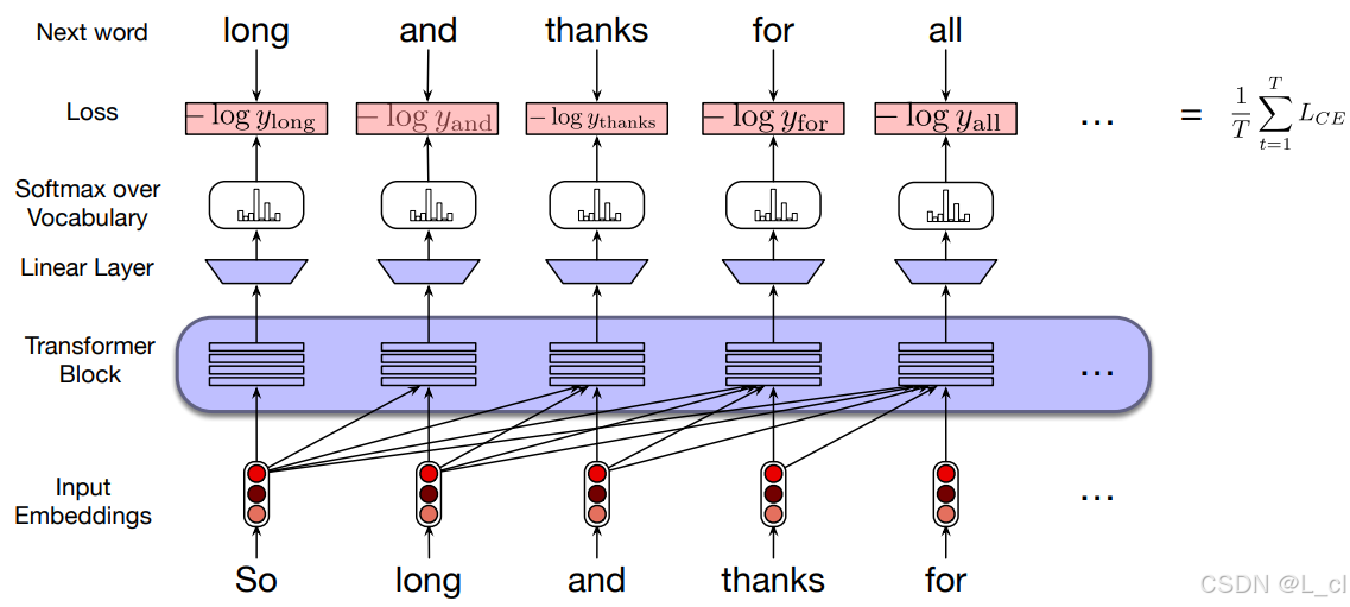
1.文本如何编码
Transformer 文本编码器
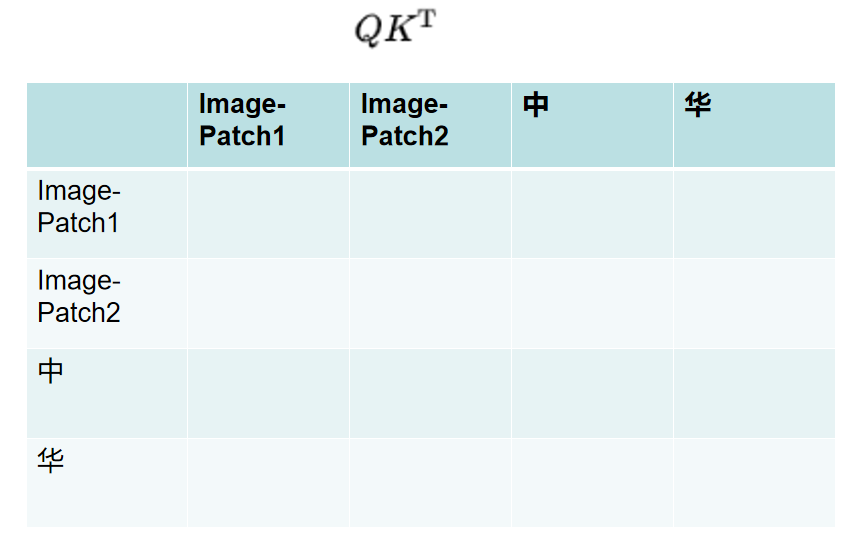
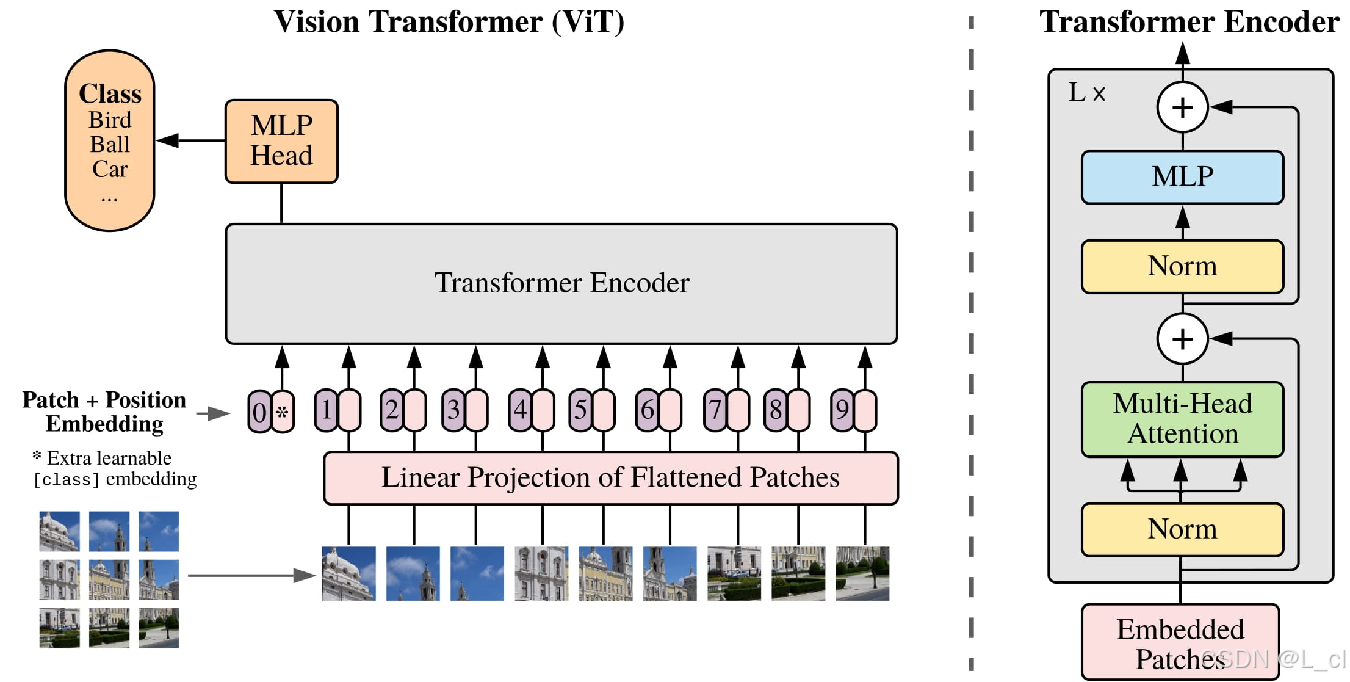
2.图像如何编码
ViT 图像编码器
把一张图像切分成n份,把每份切分后的图像展平为一个向量,在这些向量中可以加入位置编码(位置编码也可以换做ROPE相对位置编码)进行定位,每一小份图像相当于NLP领域中的每个字,输入的图像就是一个矩阵
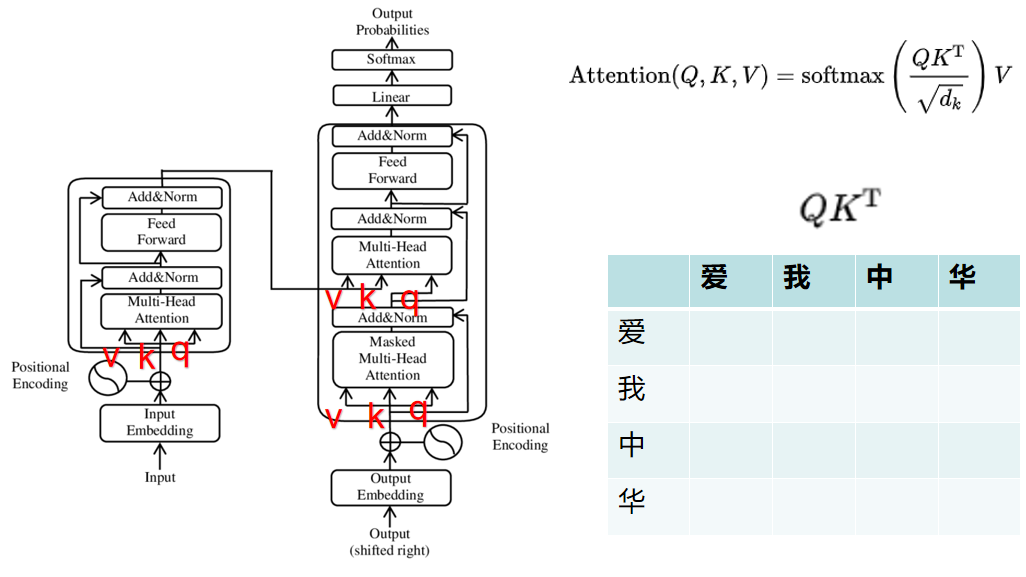
图像self-attention
图像的self-attention可以看作是图像的每一部分 与 图像的其余部分在交互做计算
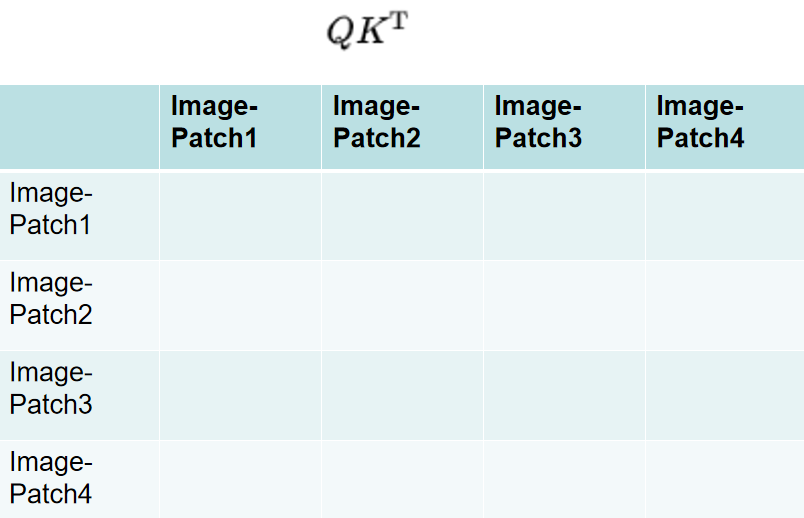
3.文本编码与图像编码之间如何交互【计算关系】
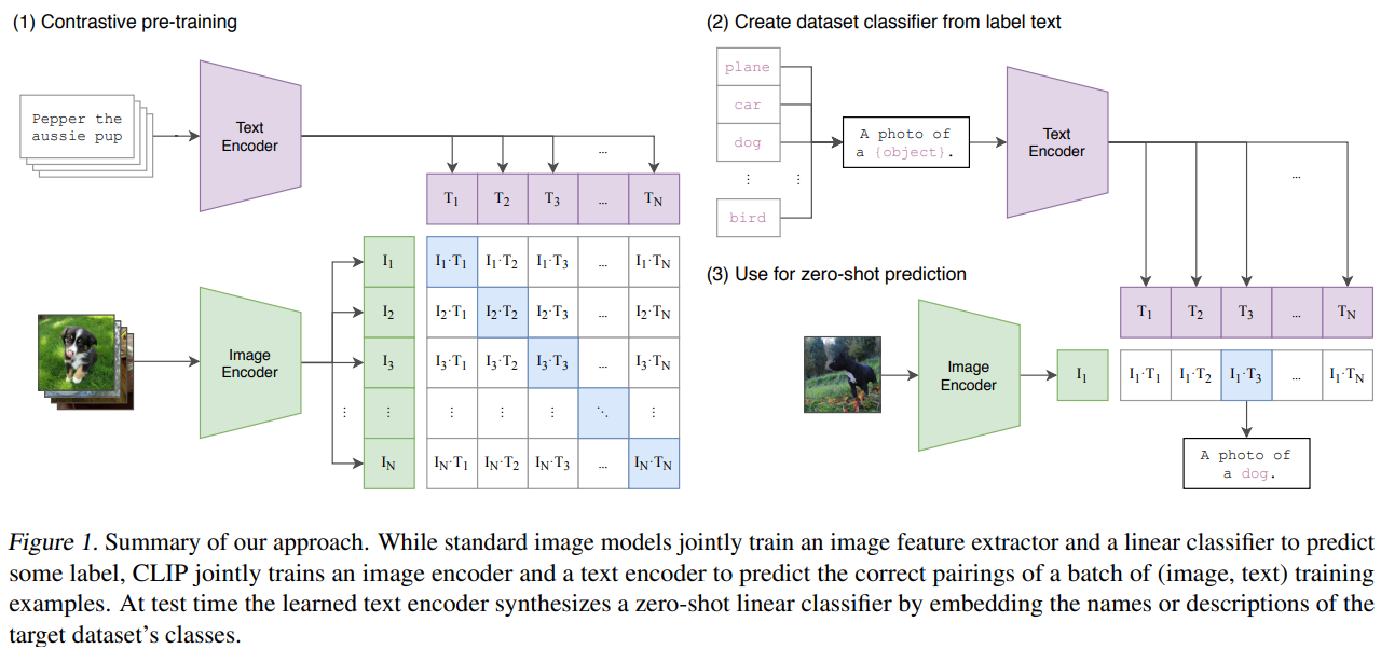
Ⅰ、CLIP 图文交互
分别对文本(Text encoder)和图像(Image encoder)进行编码,两者经过编码后分别得到一个向量,然后对这两个得到的向量做一种类似于Triplet Loss 或 Cosine的训练
训练目标:如果这段文本是用来描述这张图的,则让二者的向量比较接近,反之则差距较远
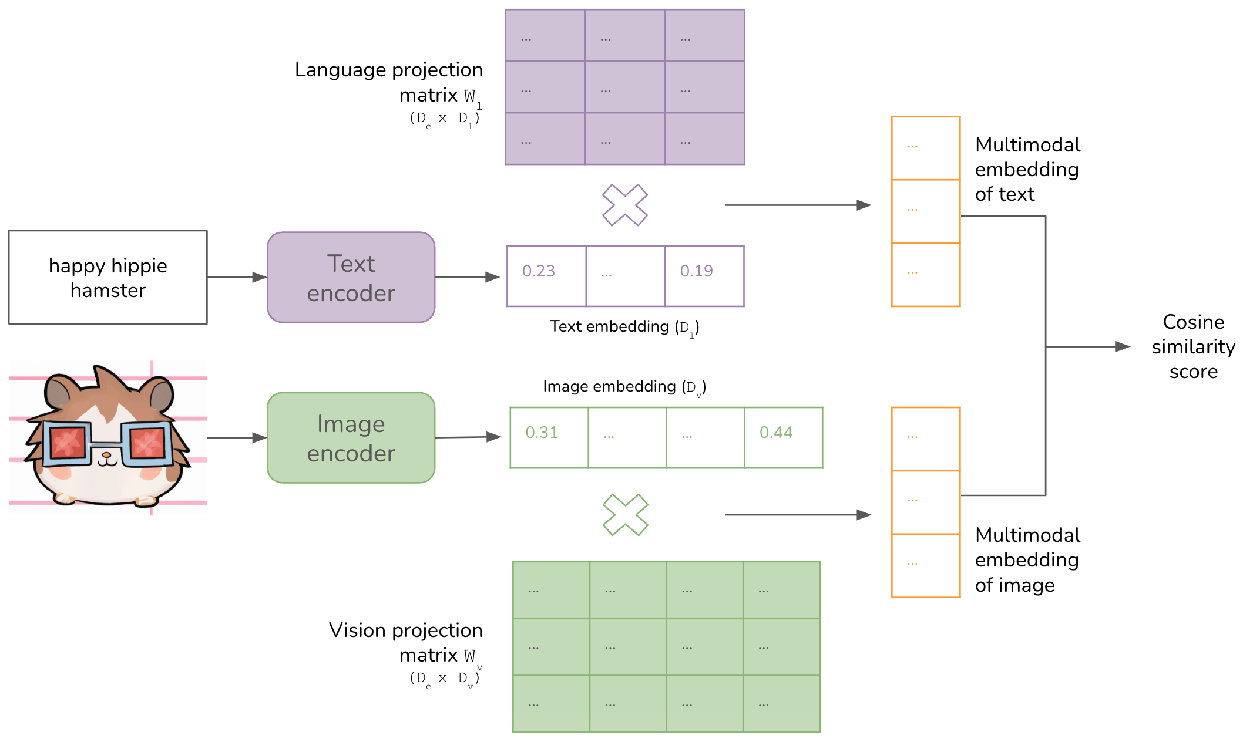
CLIP图文交互:使用对比学习的训练方式
将图像和文本编码到统一特征空间,并通过最大化匹配对的相似度、最小化非匹配对的相似度来对齐两种模态。
CLIP 采用文本编码器和图像编码器的双塔结构,分别处理文本和图像输入,并将两者的特征映射到同一向量空间。
文本编码器:基于 Transformer,输入文本通过词嵌入和位置编码后,经多层自注意力机制提取语义特征,最终输出固定长度的文本嵌入向量(如 512 维)。
图像编码器:支持 ResNet 或 Vision Transformer(ViT)。以 ViT 为例,图像被分割为 16×16 的图像块,通过线性投影和位置编码后,经多层 Transformer 层提取视觉特征,输出图像嵌入向量。
联合嵌入空间:通过共享投影层(如全连接层)将文本和图像嵌入归一化为单位向量,确保两者在同一空间中可计算相似度。
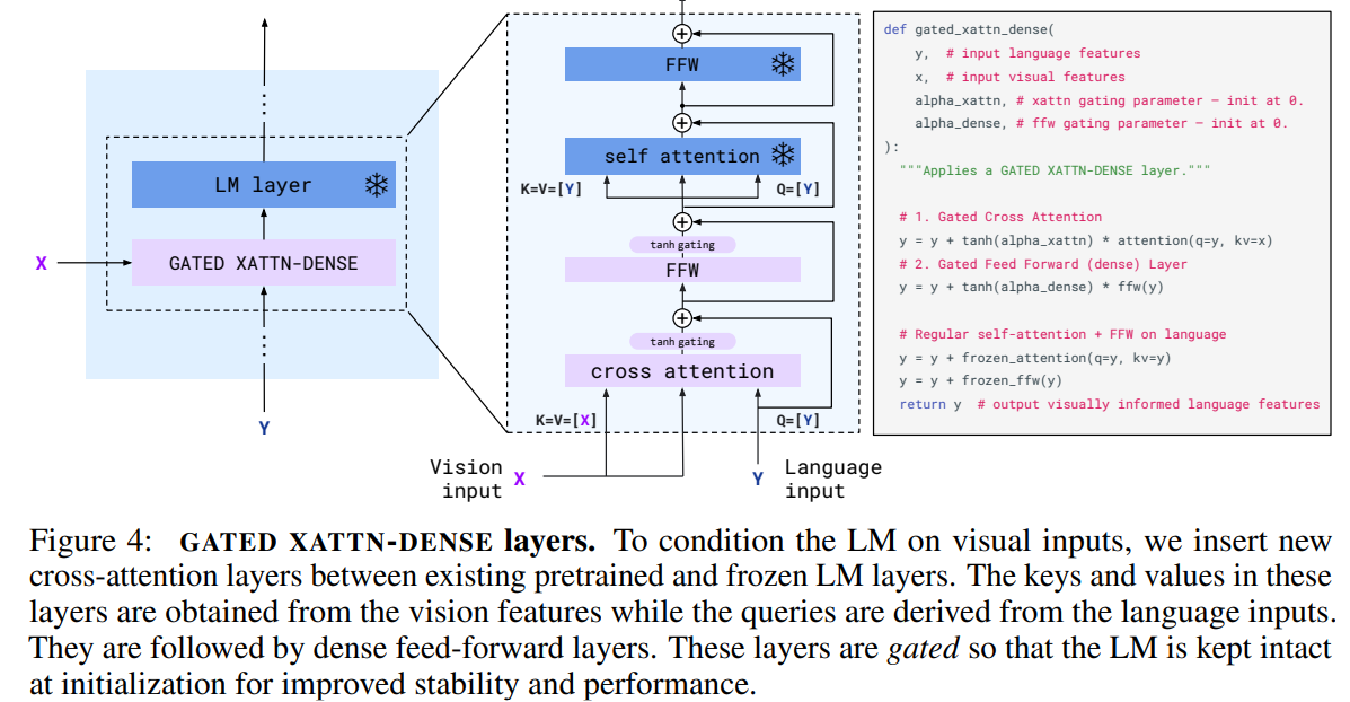
Ⅲ、flamingo 图文交互
Flamingo 是 DeepMind 提出的多模态视觉语言模型,通过冻结预训练模型 + 新型交叉注意力机制的架构设计,实现了少样本学习(Few-Shot Learning)和上下文学习(In-Context Learning)能力。
flamingo gated xatten
Attention同时输入一个x 和 y,输入的图像矩阵 x 过所谓的 K 和 V,输入的文本编码 y 过 Q,然后以 Q、K、V的形式计算交叉注意力cross attention
计算q * k ^ t,横轴是文本,竖轴是图像,计算图像序列 与 文本序列的注意力
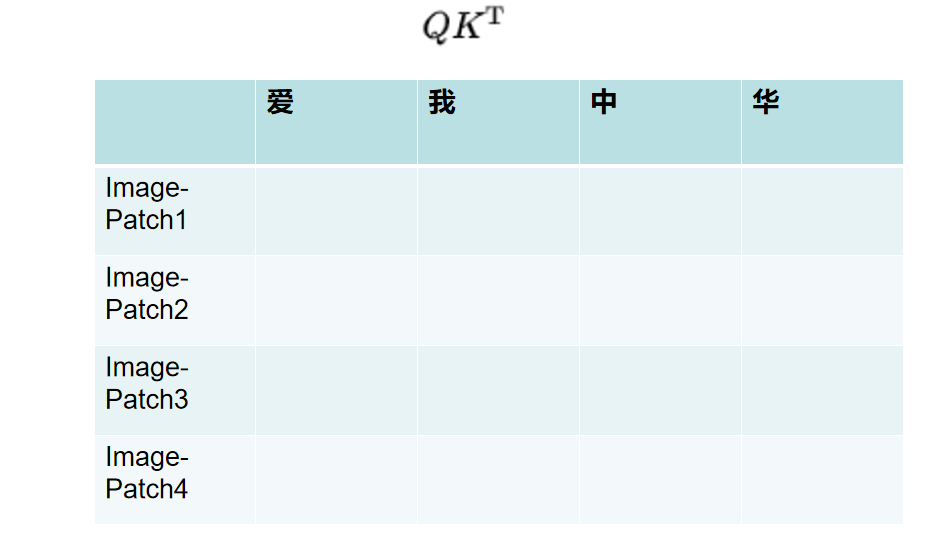
Ⅳ、LLava 图文交互(倾向于主流)
输入时,直接将输入图像的编码与输入文本的编码拼接起来,一起送入语言模型【如传统的Transformer结构】
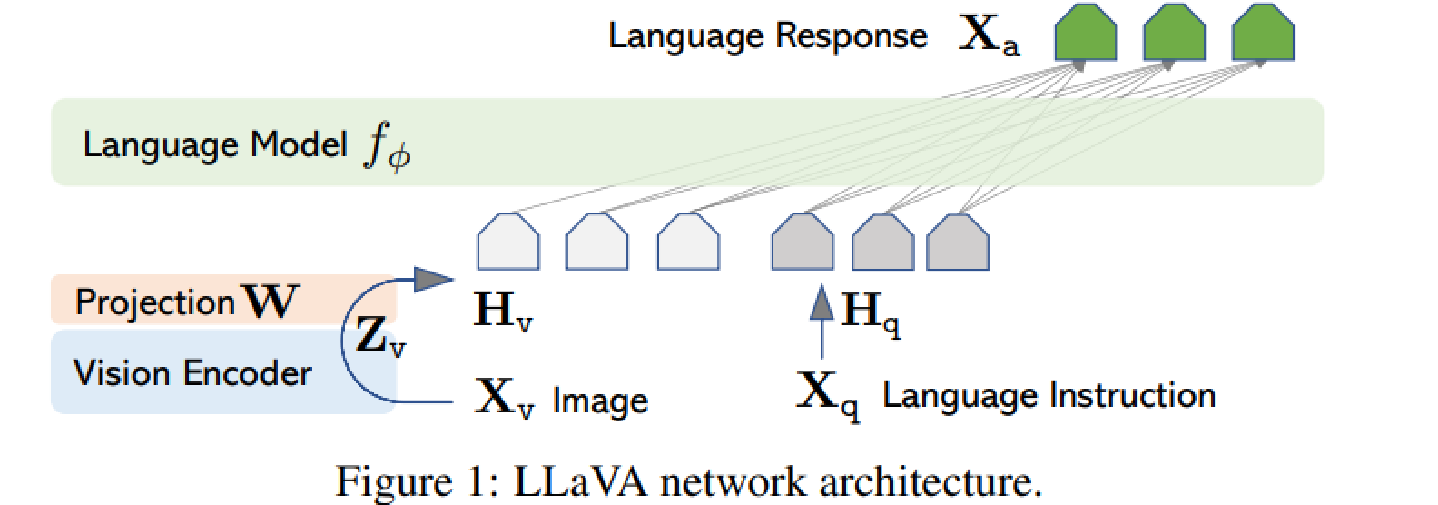
LLava attention (本质上就是普通的self-attention)
文字向量与图像向量拼接起来的序列,与自身逐个计算注意力分数,得到一个拼接序列长度 × 拼接序列长度的注意力矩阵