dedecms 手机网站模板营销型网站设计制作
目录
一、实验内容
二、实验过程
2.1 准备数据集
2.2 SIFT特征提取
2.3 学习“视觉词典”(vision vocabulary)
2.4 建立图像索引并保存到数据库中
2.5 用一幅图像查询
三、实验小结
一、实验内容
- 实现基于颜色直方图、bag of word等方法的以图搜图,打印图片特征向量、图片相似度等
- 打印视觉词典大小、可视化部分特征基元、可视化部分图片的频率直方图
二、实验过程
2.1 准备数据集
如图1所示,这里准备的文件夹中含有100张实验图片。
2.2 SIFT特征提取
2.2.1 实验代码
import os
import cv2
import numpy as np
from PCV.tools.imtools import get_imlist
#获取图像列表
imlist = get_imlist(r'D:\Computer vision\20241217dataset')
nbr_images = len(imlist)
#生成特征文件路径
featlist = [os.path.splitext(imlist[i])[0] + '.sift' for i in range(nbr_images)]
#创建sift对象
sift = cv2.SIFT_create()
#提取sift特征并保存
for i in range(nbr_images):try:img = cv2.imread(imlist[i], cv2.IMREAD_GRAYSCALE)if img is None:raise ValueError(f"Image {imlist[i]} could not be read")keypoints, descriptors = sift.detectAndCompute(img, None)locs = np.array([[kp.pt[0], kp.pt[1], kp.size, kp.angle] for kp in keypoints])np.savetxt(featlist[i], np.hstack((locs, descriptors)))print(f"Processed {imlist[i]} to {featlist[i]}")except Exception as e:print(f"Failed to process {imlist[i]}: {e}")
#可视化sift特征
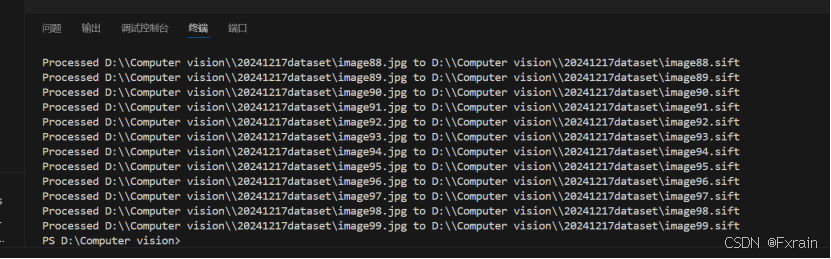
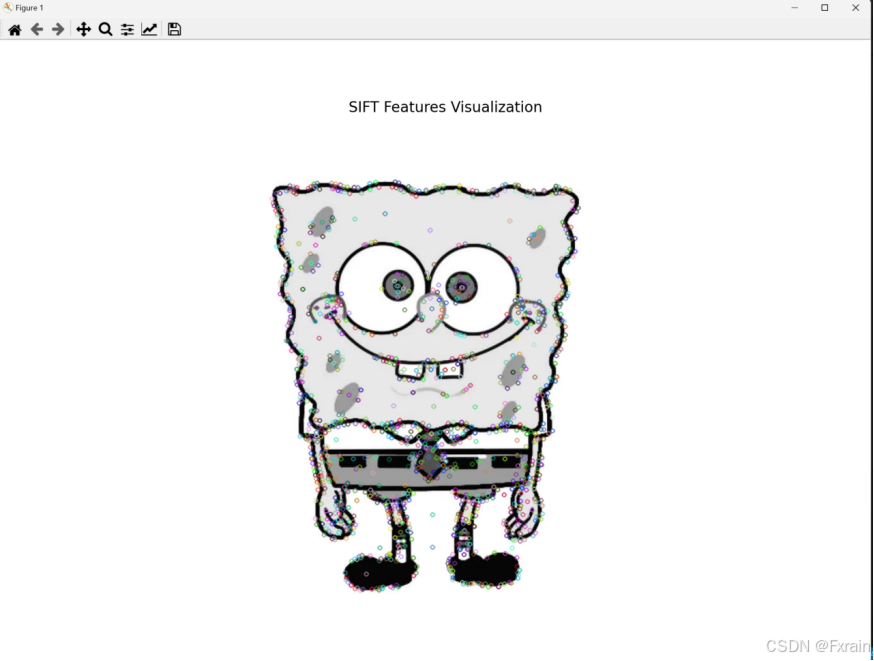
def visualize_sift_features(image_path, feature_path):img = cv2.imread(image_path, cv2.IMREAD_GRAYSCALE)if img is None:raise ValueError(f"Image {image_path} could not be read")features = np.loadtxt(feature_path)locs = features[:, :4]descriptors = features[:, 4:]img_with_keypoints = cv2.drawKeypoints(img, [cv2.KeyPoint(x=loc[0], y=loc[1], _size=loc[2], _angle=loc[3]) for loc in locs], outImage=np.array([]))plt.figure(figsize=(10, 10))plt.imshow(img_with_keypoints, cmap='gray')plt.title('SIFT Features Visualization')plt.axis('off')plt.show()visualize_sift_features(imlist[0], featlist[0])2.2.2 结果展示
如图2所示,对文件夹中的所有图片使用sift特征描述子,图3展示了对第一个图像的SIFT特征的可视化。
2.3 学习“视觉词典”(vision vocabulary)
2.3.1 实验代码
(1)vocabulary.py文件
from numpy import *
from scipy.cluster.vq import *
from PCV.localdescriptors import sift
#构建视觉词汇表
class Vocabulary(object):#初始化方法def __init__(self,name):self.name = nameself.voc = []self.idf = []self.trainingdata = []self.nbr_words = 0#训练过程def train(self,featurefiles,k=100,subsampling=10):nbr_images = len(featurefiles)descr = []descr.append(sift.read_features_from_file(featurefiles[0])[1])descriptors = descr[0] for i in arange(1,nbr_images):descr.append(sift.read_features_from_file(featurefiles[i])[1])descriptors = vstack((descriptors,descr[i]))#使用K-means聚类生成视觉单词self.voc,distortion = kmeans(descriptors[::subsampling,:],k,1)self.nbr_words = self.voc.shape[0]#生成视觉单词的直方图imwords = zeros((nbr_images,self.nbr_words))for i in range( nbr_images ):imwords[i] = self.project(descr[i])nbr_occurences = sum( (imwords > 0)*1 ,axis=0)#计算每个视觉单词的逆文档频率self.idf = log( (1.0*nbr_images) / (1.0*nbr_occurences+1) )self.trainingdata = featurefiles#投影方法def project(self,descriptors):imhist = zeros((self.nbr_words))words,distance = vq(descriptors,self.voc)for w in words:imhist[w] += 1return imhistdef get_words(self,descriptors):return vq(descriptors,self.voc)[0](2)visual vocabulary.py文件
import pickle
from PCV.imagesearch import vocabulary
from PCV.tools.imtools import get_imlistimlist = get_imlist(r'D:\Computer vision\20241217dataset')
nbr_images = len(imlist)featlist = [imlist[i][:-3] + 'sift' for i in range(nbr_images)]
voc = vocabulary.Vocabulary('bof_test')
voc.train(featlist, 50, 10)with open(r'D:\Computer vision\20241217dataset\vocabulary50.pkl', 'wb') as f:pickle.dump(voc, f)
print('vocabulary is:', voc.name, voc.nbr_words)2.3.2 结果展示
如图4所示,打印视觉词典的名称和长度

2.4 建立图像索引并保存到数据库中
2.4.1 实验代码
(1)imagesearch.py文件
from numpy import *
import pickle
import sqlite3 as sqlite
from functools import cmp_to_keyclass Indexer(object):def __init__(self,db,voc):self.con = sqlite.connect(db)self.voc = vocdef __del__(self):self.con.close()def db_commit(self):self.con.commit()def get_id(self,imname):cur = self.con.execute("select rowid from imlist where filename='%s'" % imname)res=cur.fetchone()if res==None:cur = self.con.execute("insert into imlist(filename) values ('%s')" % imname)return cur.lastrowidelse:return res[0] def is_indexed(self,imname):im = self.con.execute("select rowid from imlist where filename='%s'" % imname).fetchone()return im != Nonedef add_to_index(self,imname,descr):if self.is_indexed(imname): returnprint ('indexing', imname)imid = self.get_id(imname)imwords = self.voc.project(descr)nbr_words = imwords.shape[0]for i in range(nbr_words):word = imwords[i]self.con.execute("insert into imwords(imid,wordid,vocname) values (?,?,?)", (imid,word,self.voc.name))self.con.execute("insert into imhistograms(imid,histogram,vocname) values (?,?,?)", (imid,pickle.dumps(imwords),self.voc.name))def create_tables(self): self.con.execute('create table imlist(filename)')self.con.execute('create table imwords(imid,wordid,vocname)')self.con.execute('create table imhistograms(imid,histogram,vocname)') self.con.execute('create index im_idx on imlist(filename)')self.con.execute('create index wordid_idx on imwords(wordid)')self.con.execute('create index imid_idx on imwords(imid)')self.con.execute('create index imidhist_idx on imhistograms(imid)')self.db_commit()def cmp_for_py3(a, b):return (a > b) - (a < b)class Searcher(object):def __init__(self,db,voc):self.con = sqlite.connect(db)self.voc = vocdef __del__(self):self.con.close()def get_imhistogram(self, imname):cursor = self.con.execute("select rowid from imlist where filename='%s'" % imname)row = cursor.fetchone()if row is None:raise ValueError(f"No entry found in imlist for filename: {imname}")im_id = row[0]cursor = self.con.execute("select histogram from imhistograms where rowid=%d" % im_id)s = cursor.fetchone()if s is None:raise ValueError(f"No histogram found for rowid: {im_id}")return pickle.loads(s[0])def candidates_from_word(self,imword):im_ids = self.con.execute("select distinct imid from imwords where wordid=%d" % imword).fetchall()return [i[0] for i in im_ids]def candidates_from_histogram(self,imwords):words = imwords.nonzero()[0]candidates = []for word in words:c = self.candidates_from_word(word)candidates+=ctmp = [(w,candidates.count(w)) for w in set(candidates)]tmp.sort(key=cmp_to_key(lambda x,y:cmp_for_py3(x[1],y[1])))tmp.reverse()return [w[0] for w in tmp] def query(self, imname):try:h = self.get_imhistogram(imname)except ValueError as e:print(e)return []candidates = self.candidates_from_histogram(h)matchscores = []for imid in candidates:cand_name = self.con.execute("select filename from imlist where rowid=%d" % imid).fetchone()cand_h = self.get_imhistogram(cand_name)cand_dist = sqrt(sum(self.voc.idf * (h - cand_h) ** 2))matchscores.append((cand_dist, imid))matchscores.sort()return matchscoresdef get_filename(self,imid):s = self.con.execute("select filename from imlist where rowid='%d'" % imid).fetchone()return s[0]def tf_idf_dist(voc,v1,v2):v1 /= sum(v1)v2 /= sum(v2)return sqrt( sum( voc.idf*(v1-v2)**2 ) )def compute_ukbench_score(src,imlist):nbr_images = len(imlist)pos = zeros((nbr_images,4))for i in range(nbr_images):pos[i] = [w[1]-1 for w in src.query(imlist[i])[:4]]score = array([ (pos[i]//4)==(i//4) for i in range(nbr_images)])*1.0return sum(score) / (nbr_images)from PIL import Image
from pylab import *def plot_results(src,res):figure()nbr_results = len(res)for i in range(nbr_results):imname = src.get_filename(res[i])subplot(1,nbr_results,i+1)imshow(array(Image.open(imname)))axis('off')show()(2)quantizeSet.py文件
import pickle
from PCV.imagesearch import imagesearch
from PCV.localdescriptors import sift
import sqlite3
from PCV.tools.imtools import get_imlist
import cv2
import matplotlib.pyplot as pltimlist = get_imlist(r'D:\Computer vision\20241217dataset')
nbr_images = len(imlist)featlist = [imlist[i][:-3] + 'sift' for i in range(nbr_images)]with open(r'D:\Computer vision\20241217dataset\vocabulary50.pkl', 'rb') as f:voc = pickle.load(f)
indx = imagesearch.Indexer('D:\\Computer vision\\20241217CODES\\testImaAdd.db', voc)
indx.create_tables()
for i in range(nbr_images)[:100]:locs, descr = sift.read_features_from_file(featlist[i])indx.add_to_index(imlist[i], descr)
indx.db_commit()
con = sqlite3.connect('D:\\Computer vision\\20241217CODES\\testImaAdd.db')
print(con.execute('select count (filename) from imlist').fetchone())
print(con.execute('select * from imlist').fetchone())
searcher = imagesearch.Searcher('D:\\Computer vision\\20241217CODES\\testImaAdd.db', voc)image_files = imlist[:5]for image_file in image_files:histogram = searcher.get_imhistogram(image_file)plt.figure()plt.title(image_file)plt.bar(range(len(histogram)), histogram)plt.xlabel('Word ID')plt.ylabel('Frequency')plt.show()2.4.2 结果展示
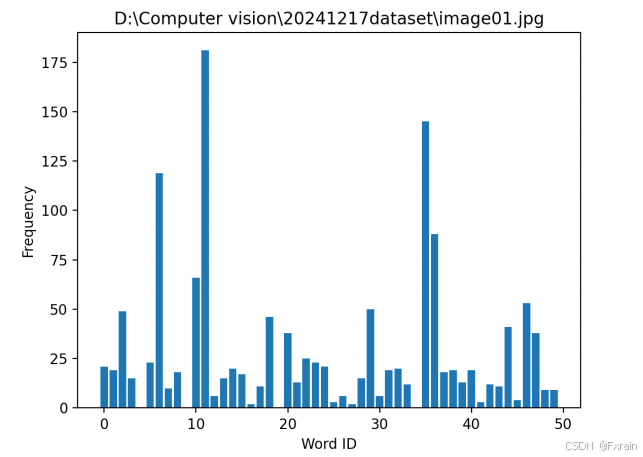
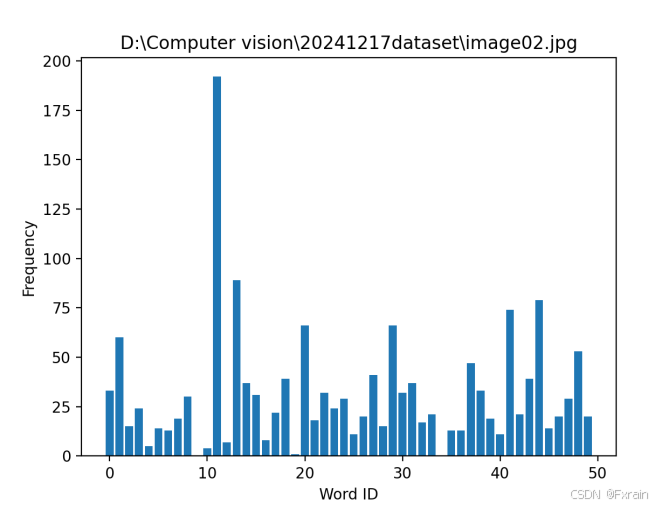
如图5所示,对数据集中的所有图像进行量化,为所有图像创建索引,再遍历所有的图像,将它们的特征投影到词汇上,最终提交到数据库保存下来(如图6)。图7、图8展示了部分图像的频率直方图。

2.5 用一幅图像查询
2.5.1 实验代码
import pickle
from PCV.imagesearch import imagesearch
from PCV.geometry import homography
from PCV.tools.imtools import get_imlist
import numpy as np
import cv2
import warnings
warnings.filterwarnings("ignore")imlist = get_imlist(r'D:\Computer vision\20241217dataset')
nbr_images = len(imlist)
featlist = [imlist[i][:-3] + 'sift' for i in range(nbr_images)]with open(r'D:\Computer vision\20241217dataset\vocabulary50.pkl', 'rb') as f:voc = pickle.load(f, encoding='iso-8859-1')src = imagesearch.Searcher(r'D:\Computer vision\20241217CODES\testImaAdd.db', voc)q_ind = 3
nbr_results = 10res_reg = [w[1] for w in src.query(imlist[q_ind])[:nbr_results]]
print('top matches (regular):', res_reg)img = cv2.imread(imlist[q_ind])
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
sift = cv2.SIFT_create()
kp, q_descr = sift.detectAndCompute(gray, None)
q_locs = np.array([[kp[i].pt[0], kp[i].pt[1]] for i in range(len(kp))])
fp = homography.make_homog(q_locs[:, :2].T)model = homography.RansacModel()
rank = {}bf = cv2.BFMatcher()
for ndx in res_reg[1:]:if ndx >= len(imlist):print(f"Index {ndx} is out of range for imlist with length {len(imlist)}")continueimg = cv2.imread(imlist[ndx])gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)kp, descr = sift.detectAndCompute(gray, None)locs = np.array([[kp[i].pt[0], kp[i].pt[1]] for i in range(len(kp))])matches = bf.knnMatch(q_descr, descr, k=2)good_matches = []for m, n in matches:if m.distance < 0.75 * n.distance:good_matches.append(m)ind = [m.queryIdx for m in good_matches]ind2 = [m.trainIdx for m in good_matches]tp = homography.make_homog(locs[:, :2].T)try:H, inliers = homography.H_from_ransac(fp[:, ind], tp[:, ind2], model, match_theshold=4)except:inliers = []# store inlier countrank[ndx] = len(inliers)sorted_rank = sorted(rank.items(), key=lambda t: t[1], reverse=True)
res_geom = [res_reg[0]] + [s[0] for s in sorted_rank]
print('top matches (homography):', res_geom)def calculate_similarity(query_index, result_indices, imlist):similarities = []for res_index in result_indices:if res_index >= len(imlist):print(f"Index {res_index} is out of range for imlist with length {len(imlist)}")continueimg1 = cv2.imread(imlist[query_index])img2 = cv2.imread(imlist[res_index])gray1 = cv2.cvtColor(img1, cv2.COLOR_BGR2GRAY)gray2 = cv2.cvtColor(img2, cv2.COLOR_BGR2GRAY)sift = cv2.SIFT_create()kp1, des1 = sift.detectAndCompute(gray1, None)kp2, des2 = sift.detectAndCompute(gray2, None)bf = cv2.BFMatcher()matches = bf.knnMatch(des1, des2, k=2)good_matches = []for m, n in matches:if m.distance < 0.75 * n.distance:good_matches.append(m)similarity = len(good_matches) / min(len(kp1), len(kp2))similarities.append((res_index, similarity))return similaritiesquery_index = q_ind
result_indices = res_reg + res_geom
similarities = calculate_similarity(query_index, result_indices, imlist)print("Similarity scores:")
for index, score in similarities:print(f"Image {index}: {score:.4f}")imagesearch.plot_results(src, res_reg)
imagesearch.plot_results(src, res_geom)
imagesearch.plot_results(src, res_reg[:6])
imagesearch.plot_results(src, res_geom[:6]) 2.5.2 结果展示
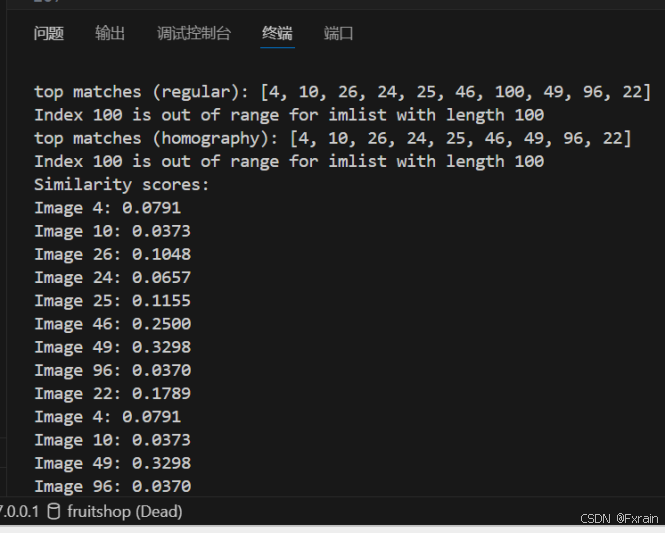
如图9所示,根据给定的查询图像索引q_ind,执行常规查询,返回前nbr_results个匹配结果,并打印这些结果以及可视化图片。

如图10所示,使用 RANSAC 模型拟合单应性找到与查询图像几何一致的候选图像。

如图11所示,计算查询图像与候选图像之间的相似度分数,并返回一个包含相似度分数的列表。
当生成不同维度视觉词典时,常规排序结果如图12所示。

三、实验小结
图像检索是一项重要的计算机视觉任务,它在根据用户的输入(如图像或关键词),从图像数据库中检索出最相关的图像。Bag of Feature 是一种图像特征提取方法,参考Bag of Words的思路,把每幅图像描述为一个局部区域/关键点(Patches/Key Points)特征的无序集合。同时从图像抽象出很多具有代表性的「关键词」,形成一个字典,再统计每张图片中出现的「关键词」数量,得到图片的特征向量。