中国建设银行官网网站首页网站首页快速收录
Java面向对象进阶
- 泛型
- 1.是什么
- 2.怎么用
- 补充:自动装箱
- 3.实现
- 4.通配符
- 注解
- 是什么
- 怎么用
- Exception异常处理
- 1.是什么
- 2.自定义异常
- 总结
- 多线程
- 1.是什么
- 2.怎么用
- 线程方法比较少不写了
- 线程安全
- File类
- IO流文件
- 反射
- 1.是什么
- 2.怎么用
- 设计模式
- 1.是什么
- 2.单例模式
- 3.单例模式实现
泛型
1.是什么
我的理解:
学习到这之前,写一个参数列表,我们需要指定形参的数据类型。
这可能不太方便。
如果平台更大,我们并不能知道用户传递的数据类型到底是什么,只有数据的内容是受限的。比如中英文其实就是生活中的两种数据类型。
但是在String中,两者是等价的字符。
同理,泛型就是使输入类型广泛化的参数类型。也就是在接受输入之前,参数类型并不确定。这就可以使得一个数据结构初始化的时候接受各种类型的参数。但是,一旦初始化,参数类型也就随之确定了。
2.怎么用
直接上代码:
import java.utils.*;public class{public static void main(String [] args){//1.不指定类型List arr = new ArrayList(); // List arr = new ArrayList<>();//此时,arr数组由于没有指定类型,对输入数据不会进行泛型检查,所有输入数据都被自动包装为Object类arr.add(1); //自动装箱为Integer,下面同理;arr.add('a');arr.add("字符串");for(Object o : arr){System.out.print(o);}//2.指定类型List <String> arr = new ArrayList<>();//此时,只能接收String类型数据,否则会报错}
}
补充:自动装箱
在Java中,自动装箱(autoboxing)是编译器自动将基本数据类型——>对应的包装类对象的过程。
这个过程通常发生在你将基本数据类型值赋给一个需要引用类型的变量或参数时。具体到你的代码示例中,自动装箱操作发生在向 ArrayList 添加基本数据类型值的时候。
自动装箱的具体位置代码:
public class Main {public static void main(String[] args) {List arr = new ArrayList<>();arr.add("aaa"); // 直接添加 String 对象arr.add("bbb"); // 直接添加 String 对象arr.add('c'); // 自动装箱:char -> Characterarr.add(1); // 自动装箱:int -> Integerfor (Object s : arr) {System.out.print(s);}}
}
自动装箱的细节
arr.add('c');:
'c' 是一个 char 类型的基本数据类型。ArrayList 的 add 方法期望传入的是一个 Object 类型的对象。编译器在这里会自动将 char 类型的值 'c' 装箱为 Character 对象。这个过程等价于手动调用 new Character('c')。
arr.add(1);:
1 是一个 int 类型的基本数据类型。同样地,ArrayList 的 add 方法期望传入的是一个 Object 类型的对象。编译器会自动将 int 类型的值 1 装箱为 Integer 对象。这个过程等价于手动调用 Integer.valueOf(1)。
编译器生成的字节码
为了更清楚地理解自动装箱的过程,可以通过查看编译后的字节码来确认。以下是一个简化版的字节码解释(使用 javap -c 命令可以查看具体的字节码):
public static void main(java.lang.String[]);Code:0: new #2 // class java/util/ArrayList3: dup 4: invokespecial #3 // Method java/util/ArrayList."<init>":()V7: astore_1 8: aload_1 9: ldc #4 // String aaa11: invokeinterface #5, 2 // InterfaceMethod java/util/List.add:(Ljava/lang/Object;)Z16: pop 17: aload_1 18: ldc #6 // String bbb20: invokeinterface #5, 2 // InterfaceMethod java/util/List.add:(Ljava/lang/Object;)Z25: pop 26: aload_1 27: bipush 99 // ASCII code for 'c'29: invokestatic #7 // Method java/lang/Character.valueOf:(C)Ljava/lang/Character;32: invokeinterface #5, 2 // InterfaceMethod java/util/List.add:(Ljava/lang/Object;)Z37: pop 38: aload_1 39: iconst_1 40: invokestatic #8 // Method java/lang/Integer.valueOf:(I)Ljava/lang/Integer;43: invokeinterface #5, 2 // InterfaceMethod java/util/List.add:(Ljava/lang/Object;)Z48: pop ...
从字节码可以看到:
在 arr.add('c'); 处,编译器生成了 Character.valueOf((char) 99) 来进行装箱操作。
在 arr.add(1); 处,编译器生成了 Integer.valueOf(1) 来进行装箱操作。
通过这种方式,Java 提供了一种方便的方式来处理基本数据类型和对象之间的转换,从而简化了代码编写和维护的工作量。
3.实现
在数组集的创建中,我们可以发现,在创建类(类加载)的过程中我们就已经定义了<>这样一个符号
List <Object> arr = new ArrayList<>();
所以泛型其实是从类开始出现的。类就包括:接口,抽象类,内部类等等。
- 那么它出现在类的哪里?
由于我们需要指定参数类型,那么泛型符号理所应当是用来标记成员变量的参数类型的。
那么成员变量相关的构造函数以及get,set方法等使用到它的方法返回值类型和传入类型也就由泛型指定,泛型接收一个外界的类型输入,默认为Object。那么如果泛型变量依赖于外界创建确定其参数类型,也就是说static修饰的变量与方法是不可以包含外界泛型变量的。但是可以包含自身定义的泛型变量。
因为在类加载的时候,static修饰内容可以被调用。
例如:
public class Test<T>{private T key;public Test(T keyInit){this.key = keyInit;}public T get(){return this.key;}
}public class Test2<T> { // 泛型类定义的类型参数 T 不能在静态方法中使用 public static <E> E show(E one){ // 这是正确的,因为 E 是在静态方法签名中新定义的类型参数 return null; }
} 当你实验完上述代码后,你会发现一个问题,如果我多个成员变量都需要这样的泛型怎么办?
那就是库库往里加,需要新的就往泛型类的泛型声明中加:
public class Test<K,V>{private K key;private V value;}
T :代表一般的任何类。E :代表 Element 元素的意思,或者 Exception 异常的意思。K :代表 Key 的意思。V :代表 Value 的意思,通常与 K 一起配合使用。S :代表 Subtype 的意思,文章后面部分会讲解示意。
4.通配符
我们希望泛型能够处理某个类型范围内的参数,比如泛型类及其子类。
有三种
- 无限定通配符<?>
- 有上界 <? extends T> 泛型取 T的子类~T
- 有下界 <? super T> 泛型取T的父类~T
需要注意的是通配符也是一个数据类型实参,它和 Number、String、Integer 一样都是一种实际的数据类型。
ArrayList< Integer > 和 ArrayList< Number > 之间不存在继承关系。而引入上界通配符的概念后,我们便可以在逻辑上将 ArrayList<? extends Number> 看做是 ArrayList< Integer > 的父类,但实质上它们之间没有继承关系。
注解
是什么
在重写父类方法时候,不难发现很多人都会在方法上加上@Override,而观察源代码,注解的定义是 @interface 也就是一个特殊的接口。上面还有两个注解:@Target 和 @Retention 被称为元注解,专门用来修饰一个注解,比如说该注解的作用范围。
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.SOURCE)
public @interface Override {
}
- 那么这两个元注解有什么用呢?
@Target:(中文:目标)包含一个 ElementType 数组类型的成员变量 , 使用@Target 时必须为该成员变量指定值,可以指定多个值。比如:METHOD,说明该注解用于修饰方法。
@Retention:(中文:保留)说明注解的保留策略,是编译完扔掉,还是写入.class,还是运行时保留。分别对应 SOURCE CLASS RUNTIME
怎么用
当作修饰符一样使用
Exception异常处理
1.是什么
异常:顾名思义,就是不该出现的东西,比如报错或者数组下标越界,又或者除数为0。
- 事实上在操作系统一书中,我们就了解到了这一个概念,并将其分类
在Java中,我们将异常按照严重程度分为Error和Exception,Error会让虚拟机崩溃,而Exception又分为编译时异常或者运行时异常。比较轻,能改。
运行时异常可以不处理,不处理JVM默认throws一个异常。
编译时异常必须处理。
那么程序在各种各样的运行情况下,我们也许会有很多异常,对于可能出现异常的地方,我们就要进行处理,初衷可能是不让机器停下来,资本的万恶。现在对于异常处理机制就有很多玩法。
而Java中提供了一种try-catch机制,当我们在try方法体中捕捉到了某种错误,我们会在catch中处理。
例如:
public class Exception01 {public static void main(String[] args) {System.out.println("程序开始运行....");int num1 = 10;int num2 = 0;try {int res = num1 / num2;} catch (Exception e) {e.printStackTrace();// 这条语句是系统默认有的,可以省略;}finally{//必须执行的}System.out.println("程序继续运行....");// 可以执行该语句;}
}那么观察上述代码,我们发现好像catch是将异常封装为某个对象实例,并在catch块中,让程序员自己处理这个异常。如果catch不到,就不执行异常处理操作。很容易理解吧。
那么这也就意味着我们可以自定义异常类或者调用java自己的异常类。
我们先看看Java自己的异常处理类是什么结构:
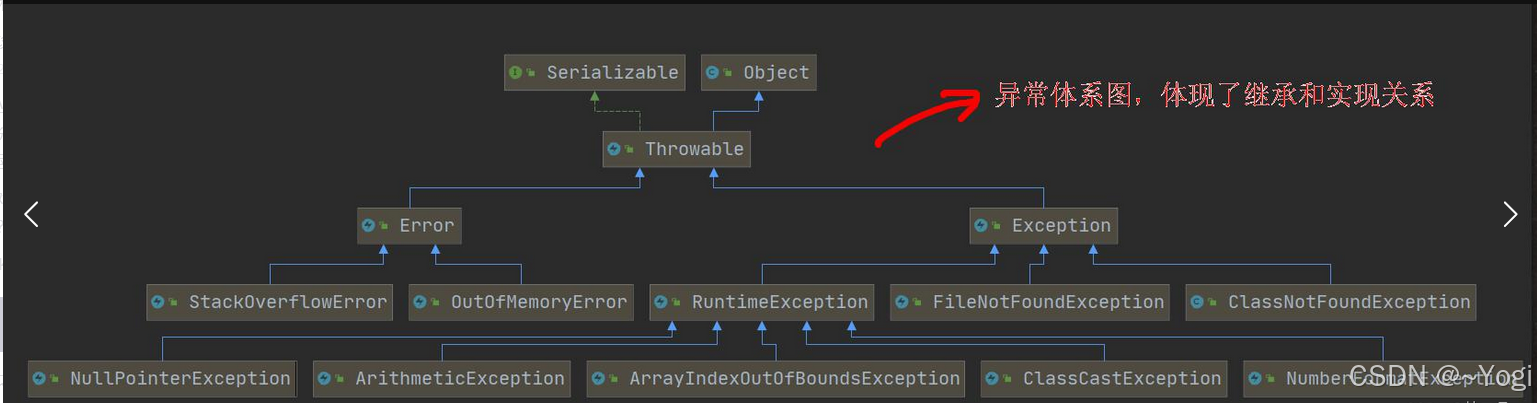 继承关系很容易理解,各位可以自己查一下对应异常类有哪些作用。
继承关系很容易理解,各位可以自己查一下对应异常类有哪些作用。
接下来我们来看第二种java异常处理机制-throws
public class Throws01 {public static void main(String[] args) {}public void f2() throws FileNotFoundException,NullPointerException,ArithmeticException {//创建了一个文件流对象//1. 这里的异常是一个FileNotFoundException 编译异常//2. 可以使用前面讲过的 try-catch-finally//3. 或者使用throws ,抛出异常, 让调用f2方法的调用者(方法)处理//4. throws后面的异常类型可以是方法中产生的异常类型,也可以是它的父类//5. throws 关键字后也可以是 异常列表, 即可以抛出多个异常FileInputStream fis = new FileInputStream("d://aa.txt");}
}不难发现,throws关键字是在参数列表后面,然后可以抛出一个异常列表。在throws中我们其实没有对异常进行处理。也就是说,try-catch是用来处理的,throws是表明该方法有异常。
2.自定义异常
public class CustomException {public static void main(String[] args) /*隐含:throws AgeException*/ {int age = 180;//要求范围在 18 – 120 之间,否则抛出一个自定义异常if(!(age >= 18 && age <= 120)) {//这里我们可以通过构造器,设置异常信息throw new AgeException("年龄需要在 18~120之间");// 此处抛出了一个自定义异常对象,使用默认的 throws 处理该异常;}System.out.println("你的年龄范围正确.");}
}//自定义一个异常类
//1. 一般情况下,我们自定义异常是继承 RuntimeException
//2. 即把自定义异常做成 运行时异常,好处是,我们可以使用默认的处理机制
class AgeException extends RuntimeException {//构造器public AgeException(String message) {super(message);}
}总结
无论是throws还是try-catch 都可以捕捉异常,有异常列表或者父类异常,try中,必须是子类在前(更细致的异常)。
多线程
1.是什么
一个进程代表一个应用程序比如JVM,一个线程代表一个执行基本单位。
2.怎么用
1.继承Thread类
public class ThreadTest {public static void main(String[] args) {//实例化3个线程类MyThread myThread1 = new MyThread();MyThread myThread2 = new MyThread();MyThread myThread3 = new MyThread();myThread1.start();myThread2.start();myThread3.start();//通过匿名内部类实例化一个线程Thread thread = new Thread(new Runnable() {@Overridepublic void run() {for (int i = 0; i < 100; i++) {System.out.println(Thread.currentThread().getName()+"-->"+i);}}},"线程4");thread.start();}
}//创建一个线程类继承Thread
class MyThread extends Thread{@Overridepublic void run() {for (int i = 0; i < 100; i++) {System.out.println(Thread.currentThread().getName()+"-->"+i);}}
}
2.实现Runnable接口
public class Demo02 {public static void main(String[] args) {MyRunnable myRun = new MyRunnable();//将一个任务提取出来,让多个线程共同去执行//封装线程对象Thread t01 = new Thread(myRun, "线程01");Thread t02 = new Thread(myRun, "线程02");Thread t03 = new Thread(myRun, "线程03");//开启线程t01.start();t02.start();t03.start();//通过匿名内部类的方式创建线程new Thread(new Runnable() {@Overridepublic void run() {for (int i = 0; i < 20; i++) {System.out.println(Thread.currentThread().getName() + " - " + i);}}},"线程04").start();}
}
//自定义线程类,实现Runnable接口
//这并不是一个线程类,是一个可运行的类,它还不是一个线程。
class MyRunnable implements Runnable{@Overridepublic void run() {for (int i = 0; i < 50; i++) {System.out.println(Thread.currentThread().getName() + " - " + i);}}
}
此处最重要的为start()方法。单纯调用run()方法不会启动线程,不会分配新的分支栈。
start()方法的作用是:启动一个分支线程,在JVM中开辟一个新的栈空间,这段代码任务完成之后,瞬间就结束了。线程就启动成功了。
启动成功的线程会自动调用run方法(由JVM线程调度机制来运作的),并且run方法在分支栈的栈底部(压栈)。
run方法在分支栈的栈底部,main方法在主栈的栈底部。run和main是平级的。
单纯使用run()方法是不能多线程并发的。
3.实现Callable接口
public class Demo04 {public static void main(String[] args) throws Exception {// 第一步:创建一个“未来任务类”对象。// 参数非常重要,需要给一个Callable接口实现类对象。FutureTask task = new FutureTask(new Callable() {@Overridepublic Object call() throws Exception { // call()方法就相当于run方法。只不过这个有返回值// 线程执行一个任务,执行之后可能会有一个执行结果// 模拟执行System.out.println("call method begin");Thread.sleep(1000 * 10);System.out.println("call method end!");int a = 100;int b = 200;return a + b; //自动装箱(300结果变成Integer)}});// 创建线程对象Thread t = new Thread(task);// 启动线程t.start();// 这里是main方法,这是在主线程中。// 在主线程中,怎么获取t线程的返回结果?// get()方法的执行会导致“当前线程阻塞”Object obj = task.get();System.out.println("线程执行结果:" + obj);// main方法这里的程序要想执行必须等待get()方法的结束// 而get()方法可能需要很久。因为get()方法是为了拿另一个线程的执行结果// 另一个线程执行是需要时间的。System.out.println("hello world!");}
}
线程方法比较少不写了
线程安全
File类
IO流文件
反射
1.是什么
java代码需要编译运行,在编译完成后,我们有一个.class文件,然后进行类加载,但是还没有运行,这个时候JVM堆内存就产生了一个class包含了对象的完整结构信息。如果一个对象,还没有被实例化,我们可以通过堆内存类加载的class获取对象的信息。这就是反射。
优点:可以动态地创建和使用对象,反射机制是 Java 框架的底层核心,其使用灵活,没有反射机制,底层框架就失去支撑。缺点:使用反射基本是解释执行,对程序执行速度有影响。
2.怎么用
设计模式
1.是什么
棋谱,主要用静态方法和静态变量去设计一些模板。
2.单例模式
单在哪儿?
- 1个对象实例
- 1个获取实例的方法
3.单例模式实现
1.饿汉式
public class SingleTon_1 {public static void main(String[] args) {GirlFriend gf = GirlFriend.getInstance();System.out.println(gf);}}// 女朋友对象,只能有一个
class GirlFriend{String name;private static GirlFriend gf = new GirlFriend("小红");//私有化构造器private GirlFriend(String name){System.out.println("创建了一个女朋友");this.name = name;}//提供一个静态方法获取创建的实例public static GirlFriend getInstance(){return gf;}@Overridepublic String toString() {return "GirlFriend{" +"name='" + name + '\'' +'}';}
}
观察代码,我们发现,饿汉式单例在对象中通过私有构造器创建了一个静态对象实例,并且对外提供了一个方法获取这个对象实例。缺点就是,有可能这个女朋友没有被使用。
2.懒汉式
class GirlFriend{String name;//先不谈,备用private static GirlFriend gf ;//构造器照样私有化private GirlFriend(String name){System.out.println("创建了一个女朋友");this.name = name;}//如果还不是女朋友,就表白,如果喊一下她public static GirlFriend getInstance(){if(gf == null){gf = new GirlFriend("小红");}return gf;}@Overridepublic String toString() {return "GirlFriend{" +"name='" + name + '\'' +'}';}
}
观察代码,懒汉式是在第一次获取对象实例的时候去创建。避免了系统资源的浪费。但存在线程安全的问题。